Character encoding issues may seem insignificant and are often ignored, but without a systematic and complete understanding of character encoding knowledge, we will encounter various “traps” in the actual encoding process. Today, we will look at character encoding in detail.
The origin of everything
Character encoding is mainly a solution to how to use the computer to express specific characters, but those who have basic computer theory knowledge know that all data inside the computer is based on binary, each binary bit (bit) has two states 0 and 1, we can combine multiple binary bits to express larger values, for example, eight binary bits can be combined to create 256 states, which is called a byte. This means that we can use one byte to map 256 different states, and if each state corresponds to one symbol, that is 256 symbols, from 00000000 to 11111111, thus establishing the most basic mapping relationship from the original computer values to natural language characters. In the 1960s, ANSI, the American National Standards Institute, developed a standard that specified the set of commonly used characters and the number corresponding to each character, which was the original form of character encoding, the ASCII character set, also known as ASCII code. ASCII code specifies the correspondence between English characters and binary bits.

ASCII code provides a total of 128 characters (including 32 control symbols that can not be printed out), such as spaces SPACE ASCII code is 32 (binary representation 00100000), the capital letter A ASCII code is 65 (binary representation 01000001). These 128 symbols only need to occupy the next 7 bits of a byte, the most preceding bit is uniformly specified as 0.
Encoding and decoding according to the ASCII character set is a simple table lookup process. For example, to encode a character sequence into a binary stream for writing to a storage device, you only need to find the byte corresponding to the character in the ASCII character set in order and then write the byte directly to the storage device, decoding the binary stream is the opposite process.
Derivation of various OEM encodings
As computers developed, people gradually found that the 128 characters in the ASCII character set did not meet their needs. In English-speaking countries, a 128-character code was sufficient, but for non-English-speaking countries, people could not find their basic characters in the ASCII character set. For example, in French, there are note symbols above the letters, and it cannot be represented in ASCII code. So some people were thinking that ASCII characters only use the first 128 transformations of a byte, and the next 128 bits are perfectly usable, so some European countries decided to use the highest unused bits of the byte to program new symbols. For example, the French é is encoded as 130 (binary 10000010). In this way, these European countries use a coding system that can represent up to 256 symbols.
However, a new problem arises here. Different countries have different alphabets, so even though they all use the 256-symbol encoding, the letters represented are not the same. For example, 130 represents é in the French encoding, but the letter Gimel (ג) in the Hebrew encoding, and will represent another symbol in the Russian encoding. The different OEM character sets result in people not being able to communicate across machines to exchange various messages. For example, A sends a resume résumés to B, but B sees rגsumגs because the é character corresponds to 0×82 bytes in the OEM character set on A’s machine, while on B’s machine, due to the different OEM character set used, the decoding of the 0×82 bytes The character obtained is ג.
But despite the different OEM encodings, the symbols represented by 0 to 127 are the same in all these encodings, and only the characters represented by the segment 128 to 255 are different.
As for the characters of Asian countries, there are more symbols used, and there are as many as 100,000 Chinese characters. One byte can only represent 256 kinds of symbols, which is definitely not enough, so multiple bytes must be used to express a symbol. For example, the common encoding method for simplified Chinese is GB2312, which uses two bytes to represent one Chinese character, so theoretically it can represent up to 256x256, which is 65536 Chinese characters.
Note: The issue of Chinese encoding is very complex and will not be discussed in depth in this note, but it should be pointed out that although multiple bytes are used to represent a symbol, the GB-like encoding of Chinese characters is not related to the later unicode and UTF-8 encoding schemes.
From ANSI standards to ISO standards
The emergence of different ASCII-derived character sets has made document communication very difficult, so various organizations have carried out the standardization process one after another. For example, the ANSI organization has developed the ANSI standard character encoding, the ISO organization has developed various ISO standard character encoding, and there are also national standard character sets developed by various countries, such as GBK, GB2312, GB18030, etc. in China.
Each computer’s operating system will be pre-installed with these standard character sets and platform-specific character sets, so that as long as the standard character sets are used to write documents, a high degree of versatility can be achieved. For example, a document written in GB2312 character set can be displayed correctly on any machine in mainland China. Of course, it is possible to read documents in multiple languages on a single computer, but only if the computer has the character set used for the document installed.
The advent of unicode
Although we could access documents in different languages on one computer by using different character sets, we still could not solve one problem: displaying all characters in one document. At that time, people thought that if there was an encoding that could map all the language symbols in the world, giving each one a non-binary encoding, the garbled code problem would disappear. This is the unicode character set, which is, as its name suggests, an encoding of all symbols.
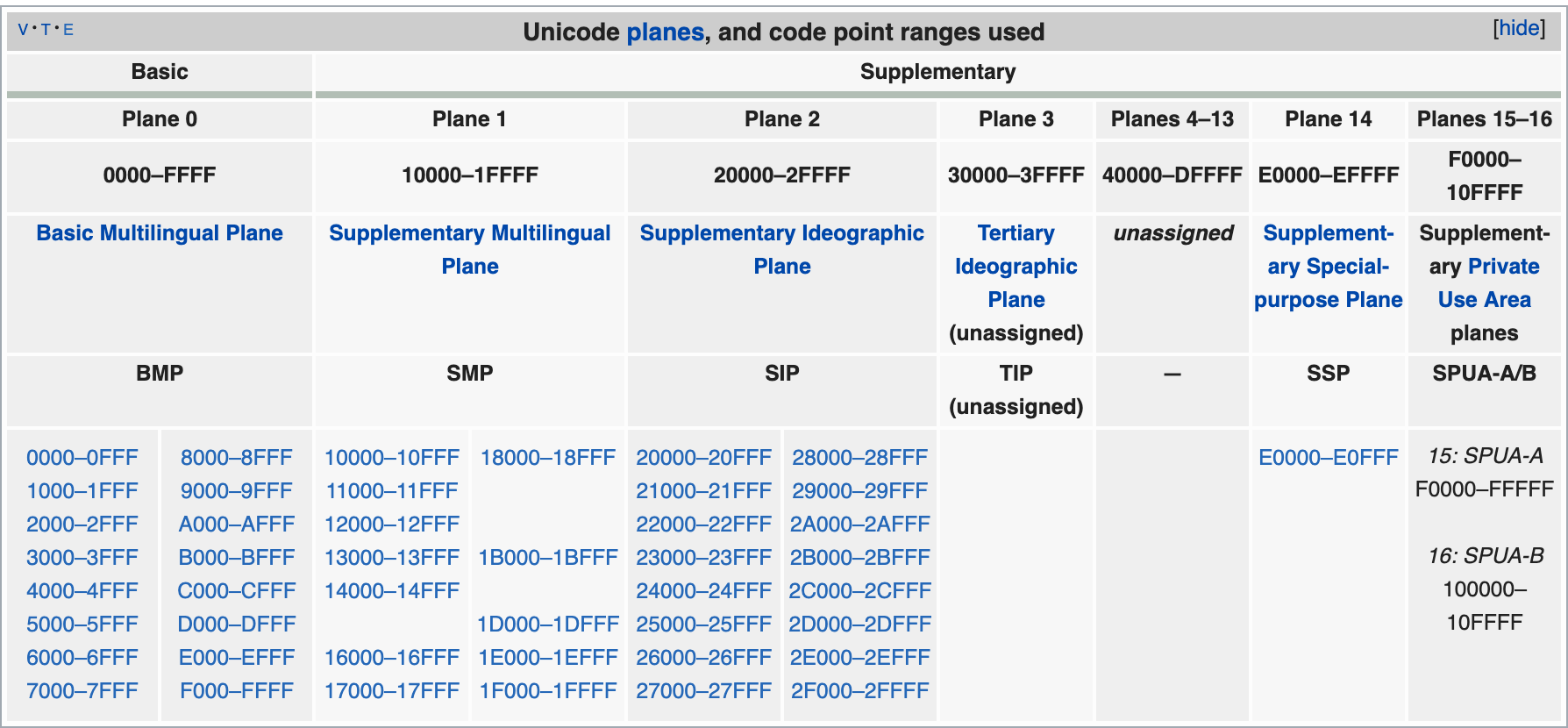
The unicode character set includes all characters currently used by humans, and is of course a very large collection, now sized to hold over a million symbols. Each symbol is encoded differently, for example, U+0639 for Arabic Ain, U+0041 for English uppercase A, and U+4E25 for Chinese character 严. unicode character set divides all characters into 17 levels according to their frequency of use, and each level has 2^16 or 65536 character spaces. For specific symbol correspondence tables, check the unicode official website, or the special Chinese character correspondence table.
The problem with unicode
With the unicode encoding scheme, people often ask the question: does unicode require two bytes for storage?
In fact, unicode only defines a large, global character set with a uniquely determined binary code for each character, but does not specify how this binary code should be stored.
For example, the unicode code for the Chinese character 严 is the hexadecimal number #4E25, which is converted to a binary number of 15 bits (100111000100101), which means that the representation of this symbol requires at least 2 bytes. Other larger symbols may require 3 bytes or 4 bytes or even more.
The first problem is how to distinguish between unicode and ASCII, since the computer cannot know whether three bytes represent one character or three characters each. The second problem is that it is enough to use only one byte for English letters, but if each symbol is represented by three or four bytes according to unicode, then each English letter must be preceded by two or three bytes full of 0s, which is a great waste of storage, and the size of the text file will be two or three times larger, which is unacceptable.
They result in the following.
- there are multiple ways of storing unicode, i.e. there are many different binary formats that can be used to represent unicode
- unicode could not be generalized for a long time, until the advent of the Internet.
Introduction of UTF-8
UTF-8 is one of the most widely used implementations of unicode on the Internet, and there is a strong need for a unified unicode encoding scheme as the Internet becomes more popular. Other implementations include UTF-16 (characters represented by two or four bytes) and UTF-32 (characters represented by four bytes), but they are largely unused on the Internet.
Since UCS-2/UTF-16 uses two bytes to encode ASCII characters, the storage and processing efficiency is relatively low, and since the high byte of the two bytes obtained from ASCII characters after UTF-16 encoding is always 0×00, many C language functions treat this byte as the end of the string and thus cannot parse the text correctly. Therefore, when UTF-16 was first introduced, it was resisted by many western countries, which greatly affected the implementation of unicode. The problem was solved by the invention of the UTF-8 encoding.
Note: Always remember that UTF-8 is one of the encoding implementations of unicode.
The most important feature of UTF-8 is that it is a “variable length” encoding. It can use 1 to 4 bytes to represent a symbol, and the byte length varies depending on the symbol.
UTF-8 encoding rules are simple and practical.
- For a single-byte symbol, the first bit of the byte is set to 0, and the next 7 bits are the unicode code of the symbol. So for English letters, UTF-8 encoding is exactly the same as ASCII encoding; 2.
- for n-byte symbols (n>1), the first n bits of the first byte are set to
1, the n+1 bits are set to0, and the first two bits of the following bytes are always set to10. The remaining binary bits that are not mentioned are all unicode codes for this symbol.
The following table summarizes the encoding rules, and the letter x indicates the bits available for encoding.
| Unicode symbol range | UTF-8 encoding method |
|---|---|
| Hex | Binary |
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Based on the above table, interpreting the UTF-8 encoding is very simple. If the first byte of a byte is 0, the byte alone is a character; if the first byte is 1, the number of consecutive 1s indicates the number of bytes occupied by the current character.
Let’s take the Chinese character 严 as an example to demonstrate how to implement UTF-8 encoding.
The unicode code of 严 is #4E25 (binary representation is 100111000100101), according to the above table, we can find that 4E25 is in the range of the third line (0000 0800 - 0000 FFFF), so the UTF-8 encoding of 严 needs three bytes, i.e. the format is 1110xxxx 10xxxxxx 10xxxxxx. Then, starting from the last binary bit of 严, fill in the x of the format in order from back to front, and the extra bits are complemented by 0. The UTF-8 code for 严 is 11100100 10111000 10100101, which is converted to hexadecimal as E4B8A5.
Analysis of garbled code problem
Garbled" means that the text displayed by the application cannot be interpreted in any language, and usually contains a lot of ? or �. The root cause of garbled text is the use of the wrong character encoding to decode the byte stream, so to solve the problem of garbled text, we must first figure out what character encoding the application is currently using.
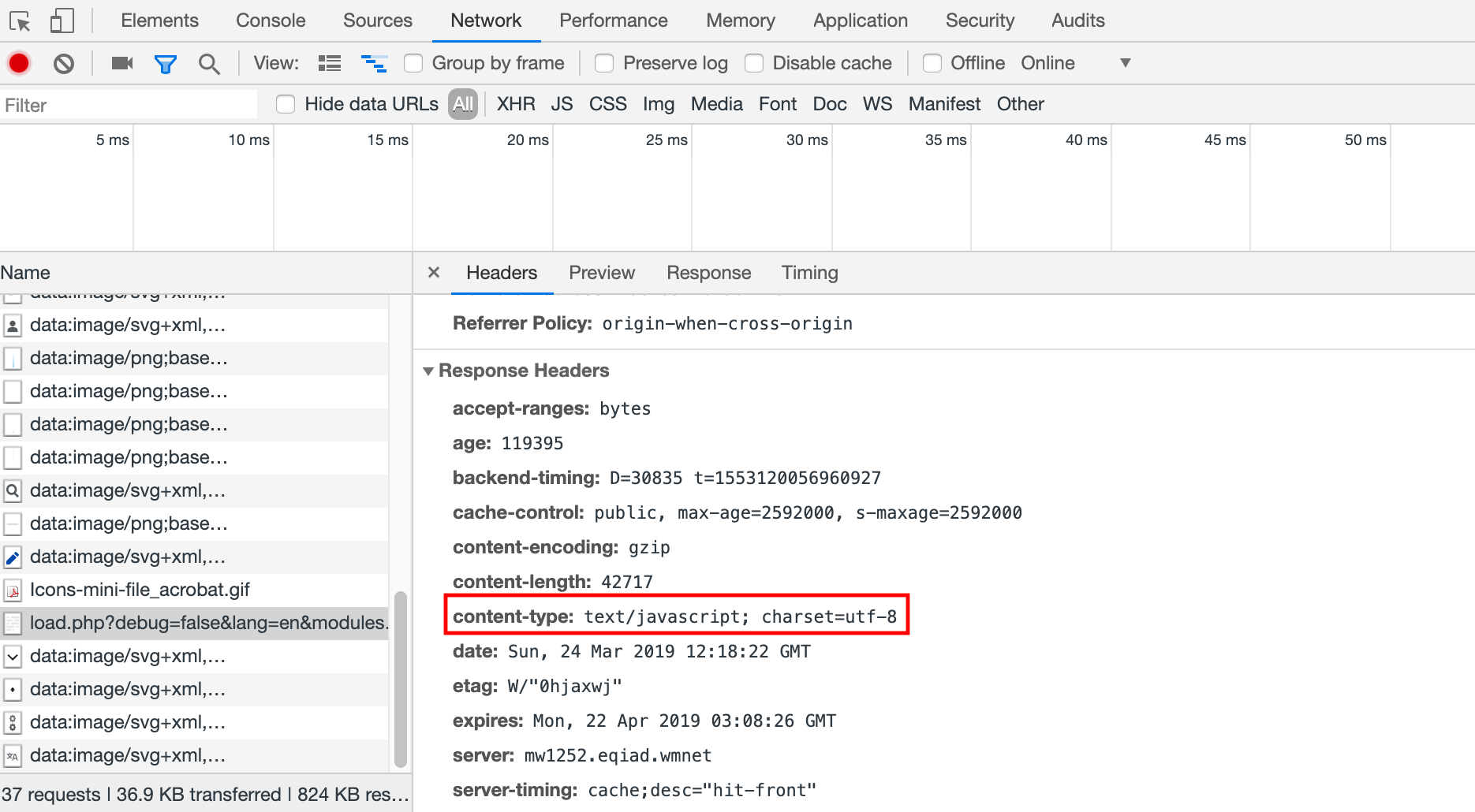
For example, the most common web page messy code problem. If we encounter such a problem, we need to check the following causes.
- The response header
Content-Typereturned by the server does not specify the character encoding - Whether the character encoding is specified in the web page using the
META HTTP-EQUIVtag - whether the character encoding used in the web page file itself is the same as the character encoding declared in the web page
Note:When an application decodes a byte stream using a specific character set, if it encounters a byte stream that cannot be parsed, it will use
?or�will be used instead. Therefore, if the final parsed text contains such a character garbled character, and the original byte stream is not available, it means that the correct information is completely lost, and no character encoding can restore the correct information from such a character text.
Refer
https://en.wikipedia.org/wiki/Universal_Coded_Character_Sethttp://www.joelonsoftware.com/printerFriendly/articles/Unicode.htmlhttps://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/