
1. Means of ensuring code quality
Since the birth of the world’s first computer high-level programming language Fortran since the 1950s, the profession of programming has gone through nearly 70 years. Although the years have been quite a few, one thing is undeniable:software production still can not be standardized like hardware, the same small function, each programmer’s has a different implementation method.
So how to ensure that the quality of the produced software meets our requirements? Programmers in different fields are making efforts, for example: those who do compilers make them stricter and try to eliminate memory safety problems completely (e.g. Rust); those who do Toolchain’s provide programmers with various single tests, integration tests, interface tests, fuzzing tests and other tools built into the language (e.g. Go toolchain), so that programmers can more easily test all aspects of the code they write in order to find more potential problems in the code…
Of course, there is another subjective approach to code quality assurance that is still the norm, and that is peer code review (code review, cr).
There are two main methods of code review: one is to sit in a conference room and “comment” on someone’s code; the other is to use a tool like gerrit to “comment” online on someone else’s code commit or a PR code. The other is to use a tool like gerrit to “comment” on someone else’s code submission or PR’s code online.
However, no matter which, initially everyone will be detailed from the syntax level to see the code structure design, and then to the business logic level, but the disadvantage of doing so is also very obvious, that is inefficient, not focus (focus).
So people thought: can we use tools to find as much as possible the syntax level, so that code review, human experts can focus on the code structure design and business logic level, the division of labor is clear, the efficiency of the natural increase (the following chart).
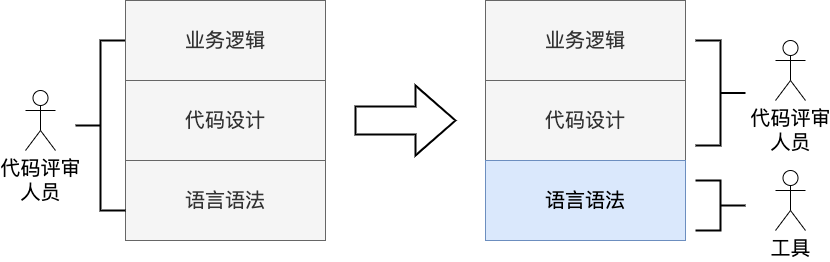
Currently most toolchains can only automatically help programmers solve syntax-level problems. In the future, as tools become more powerful, they can upgrade their level of focus and evolve to have the ability to find structural design problems in code and even business-level logic problems.
So there are tools like reviewdog that can call various linter tools to automatically scan the code and automatically submit the issue as a comment to the code repository.
Here many people will ask, even if you let the tools to focus on the syntax level, why use tools like reviewdog, git’s pre-commit hook, git server hooks, using tools like Make to do development phase checks and other means can also check the syntax of the code, they are no longer popular?
Here is a brief look at the “problems” with these methods (we assume that everyone is already using git as a code versioning tool).
git pre-commit-hook
The git pre-commit hook is a client-side git hook that is placed in the .git/hooks directory of the developer’s local copy of the code and is invoked when the developer executes a local git commit.
The problem with the pre-commot hook is that we can’t manage and maintain the script content of the pre-commit hook in a central repository. This is more suitable for developers to deploy in their own development environment according to their own preferences and code literacy.
In addition, some of the code is not necessarily committed on the developer’s own development machine, and the pre-commit hook will not be effective after changing the environment.
Do local checks with tools like Make
With the make tool, we can do various static checks on the code such as lint before building it locally, but like pre-commit-hook, although Makefile can be submitted to the code repository, the real tool used to check the code is still local to the developer, which makes it difficult to manage and maintain the tool version and set check rules, and may lead to This may lead to inconsistencies in different developers’ environments. In the same case, some code is not necessarily submitted on the developer’s own development machine, and the code checking tool that the Make tool relies on may not exist after changing the environment, so the checking process cannot be implemented effectively.
git server hooks
git supports server hooks. gitlab has also supported server hooks since version 12.8 (replacing the previous custom hooks).
Git server supports the following hooks.
- pre-receive
- post-receive
- update
I have not studied deeply whether these server hooks can meet our functional requirements, but the deployment characteristics of git server hooks determine that it is not suitable because it has to be executed on the gitlab server, which means that all the static code checking tools we need have to be deployed and configured in the same environment as the gitlab server, which is too coupled and does not facilitate our management and daily maintenance of these static code checking tools.
Okay, here comes reviewdog time!
We take the code repository for gitlab as an example, I have done a small survey, the current enterprise internal basically using gitlab to build a private git repository, except for those large companies that implement their own code repository platform.
2. What is reviewdog
What kind of tool is reviewdog? Let’s take a look at the following diagram.
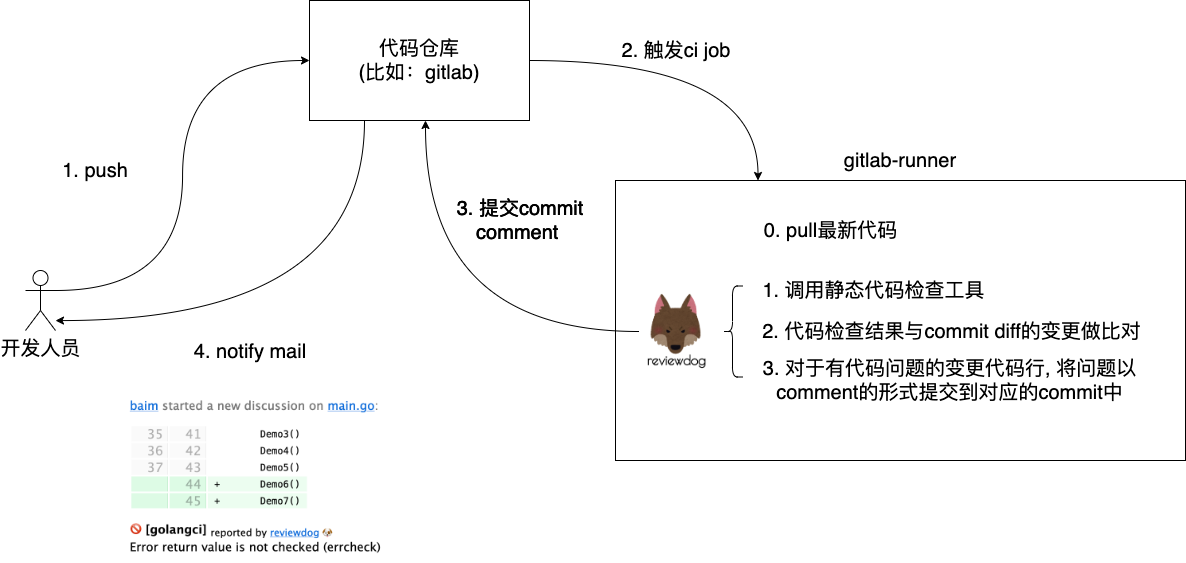
We see that this is a diagram of the gitlab-based ci execution flow, in which the reviewdog runs on the gitlab-runner node, the node responsible for actually executing the ci job. Whenever a developer executes a git push to sync a commit to the code repository, a ci job is triggered, and on the gitlab-runner node that hosts that ci job, reviewdog is invoked, which does three things.
- Calling the static code checking tool to check the newly pulled down code.
- Compare the code check result (which line is problematic) with the result of commit diff to get the intersection (i.e. the lines of code changed (add and update) in commit diff that match the lines of code check result are put into the intersection).
- Post the code check result information in the intersection set to the gitlab repository in the form of a gitlab commit comment.
This allows developers to see these comments through the commit page and respond to them and, if necessary, fix them.
The biggest difference we see between reviewdog and other tools is that you can find the intersections in the commit diff and lint results, and interact with the code repository to put the results of those intersections into the commit page as comments, just like peers add comments directly to your commit page during peer code reviews just like peers add comments directly to your commit page during peer code review.
However, the current version of reviewdog does not support checking and committing comments directly on gitlab-push-commit, probably because this is a rare scenario, as open source projects currently use more pr (pull request) based workflows. So reviewdog has built-in code review for workflows like github-pr-check, github-pr-review, gitlab-mr-commit, etc. It is probably not uncommon to use gitlab-push-commit like we do (although we do use this internally with a specific context).
So how do we get reviewdog to support gitlab-push-commit, which is a static code check for commits in a push action and puts the result as a comment on the commit page? We can only fork the reviewdog project and add support for gitlab-push-commit mode to the forked project itself.
3. Modifying reviewdog to support gitlab-push-commit mode
reviewdog is a command-line tool, usually a one-time execution, so its code structure is relatively clear. We can simply figure out how to add support for gitlab-push-commit mode around the several reporter modes it supports.
To explain what gitlab-push-commit mode means, firstly it applies to the ci job triggered when a developer pushes code to gitlab via git push. in this ci job, reviewdog runs the configured static code analysis tool (e.g. golangci-lint, etc.) to scan the latest code scan and get the set of issues. Then it gets the sha value of the latest commit (CI_COMMIT_SHA) and the sha value of the previous latest commit (CI_COMMIT_BEFORE_SHA) and compares the diffs between the two versions.
Finally, we find the “intersection” between the set of issues and the set of diffs by file name and line number. And the result is submitted as a comment to the latest commit page of this push via the gitlab client api.
One “flaw” in this pattern is that if there are multiple commits in a push, then the gitlab-push-commit pattern will not diff and comment on each commit, but will just use the latest commit in the push is compared to the latest commit before the push.
Once we’ve defined what gitlab-push-commit mode means, we can add support for this mode to reviewdog “by the book”!
In main.go, we mainly add a reporter case branch to the run function.
|
|
In this case, we are mainly preparing the gitlab client object, PushCommitsCommenter(located in service/gitlab/gitlab_push_commits.go) object, PushCommitsDiff(Located in service/gitlab/gitlab_push_commits_diff.go) object, etc. for the project.Run or reviewdog.Run methods that follow.
gitlab_push_commits.go and gitlab_push_commits_diff.go are two new go source files, which are also rewritten with reference to gitlab_mr_commit.go and gitlab_mr_diff.go in the same directory. The specific code is not listed here, so you can read it yourself if you are interested.
4. Deploying gitlab-runner to validate the new version of reviewdog
Let’s verify the above-modified reviewdog.
1. Installing gitlab-runner
Let’s first create an experimental project on gitlab and then configure ci for that project. if your gitlab is not yet registered with gitlab-runner, you can install and register the runner node as follows (you can create it under the top-level group so that runner can be shared within the group: settings => CI/ CD => Runners => Show runner installation instructions has detailed command instructions for deploying runner).
|
|
The above command will create a runner self-configuration file under /etc/gitlab-runner: config.toml.
|
|
Here I chose shell executor, which is based on the host shell to execute the commands in ci job.
The environment under runners sets the environment variables of the shell, and the settings here will override the values of the environment variables under the corresponding account (e.g. gitlab-runner).
After gitlab-runner is successfully deployed, we can see the following available runners under the group’s runners.
When I created the runner, I set two tags for the runner: ard and ci.
Make sure that the commands executed by the runner are available under the PATH of the host.
2. Creating a personal access token
reviewdog needs to access the gitlab repository through the gitlab client API to get information and commit comments, which requires us to provide access tokens for the commands runner executes.
gitlab has multiple access tokens, such as: personal access token, project access token, etc. We create personal access token, I also tested project access token, using project access token can submit comments successfully, but notify mail cannot be sent out in nine cases out of ten.
The access token should be saved, because it is displayed only once.
We configure the personal access token into the variable of the experimental project (Settings => CI/CD => variables), the key of the variable is REVIEWDOG_GITLAB_API_TOKEN, and the value is the token just created.
Each time a CI job is executed, the variable will be used as a predefined environment variable for the job. Our reviewdog can then use this token to access gitlab.
3. Configuring the ci pipeline for the experimental project
We can configure the ci pipeline for the experimental project in the form of code. We create the .gitlab-ci.yml file in the project root directory with the following contents.
The specific field meanings of .gitlab-ci.yml can be found in the gitlab documentation. There are a few points worth noting in this configuration.
- Use tags to associate with runner (here the tag ard is used).
- script section is the list of commands executed by job specifically, here first set CI_REPO_OWNER and CI_REPO_NAME two environment variables for reviewdog; then execute reviewdog.
- only section describes the push event triggering ci job only for master branch.
4. configure.reviewdog.yml
Finally, let’s configure the configuration file of reviewdog to fit the experimental project. Again, we create the .reviewdog.yml file in the project root directory with the following contents.
Here we see that we use golangci-lint, a static checking tool, to check the code of the experimental project. The meaning of -max-same-issues=0 here is that there is no limit to the number of identical errors. As for the specific format of .reviewdog.yml, the reviewdog project’s own .reviewdog.yml is very informative, and you can study it carefully if you need to.
5. Push the code and verify the execution result of reviewdog
We can intentionally write down some problematic code in the code that is guaranteed to be scanned by the golangci-lint tool, e.g.
|
|
Here there is no error handling for Demo function calls, errcheck in golangci-lint can detect this problem. Commit and push the code to the repository, wait a moment, we will receive notify mail, open the commit page, you will see the following commit comments.
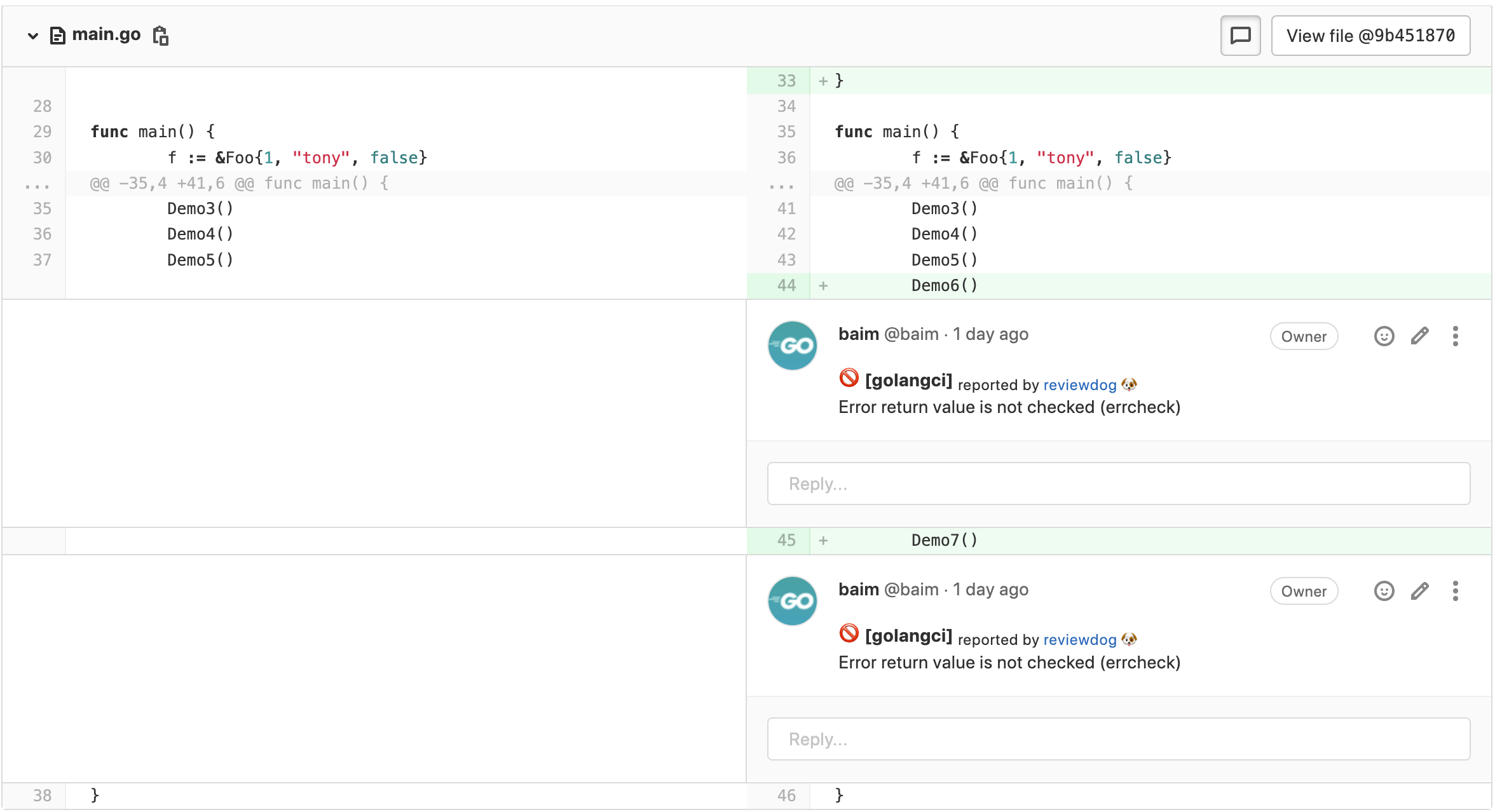
Seeing results like this means reviewdog is working as expected!
5. Summary
This article describes how to perform a static code check on a push commit based on reviewdog and submit comments in the commit like a “peer”.
The purpose of this is to improve the efficiency of code review with tools that also keep a lower limit of code quality.
As mentioned at the beginning of this article, this reviewdog-based automated code checking solution can continue to improve in terms of code quality assurance as the capabilities of the checking tools increase.
Go open source go/ast and other tool chains, if you have the ability to develop their own “purpose-built” inspection tools based on go/ast and integrated into reviewdog, which will make the inspection more targeted and effective.
The source code for this article is available for download at here.
6. Reference
https://tonybai.com/2022/09/08/make-reviewdog-support-gitlab-push-commit-to-preserve-the-code-quality-floor/