Usage
The fork function is a system call function that is used to create a new process, as follows.
|
|
Let’s execute it.
The above example outputs the process number three times, and after calling the fork function, it returns the child process number if it is the parent process, and 0 if it is the child process. So you can determine the parent and child processes by the process number returned by fork. And the child process from fork will not start from the main function, but will continue from the fork function, as if it had called the fork function itself.
The reason why the parent process calls the wait function is to wait for the child process and synchronize the state of the child process, otherwise it may generate orphan processes or zombie processes, which we will talk about later.
Another point to note is that the scheduling of the parent and child processes is random, and there is no rule that the parent process must be scheduled before the child process.
fork function implementation process
Processes are created from other processes and each process has its own PID (process identification number). There is an inheritance relationship between processes on Linux systems, and all processes are descendants of the init process (process #1). You can see the genealogy of processes by using the pstree command. All processes in Linux are described by task_struct, which maintains a parent-child process tree structure with parent and children fields.
The fork function is a way to create a child process, and it is a system call function, so let’s look at system_call before we look at the fork system call.
The system call handler function system_call is linked to the int 0x80 interrupt descriptor table. system_call is the general entry point for system call soft interrupts in the entire operating system. After all user programs use system calls that generate int 0x80 soft interrupts, the operating system finds the specific system call function through this general entry point.
System call functions are the basic support of the operating system for user programs. In an operating system, things like reading disks, creating subprocesses, and so on need to be implemented through system calls. When the system call is called, it triggers an int 0x80 soft interrupt, then switches from the user state to the kernel state (flips from privilege level 3 of the user process to privilege level 0 of the kernel), finds the system call port through the IDT, calls the specific system call function to process things, and then returns to the user state by the iret instruction to continue executing the original logic after processing.
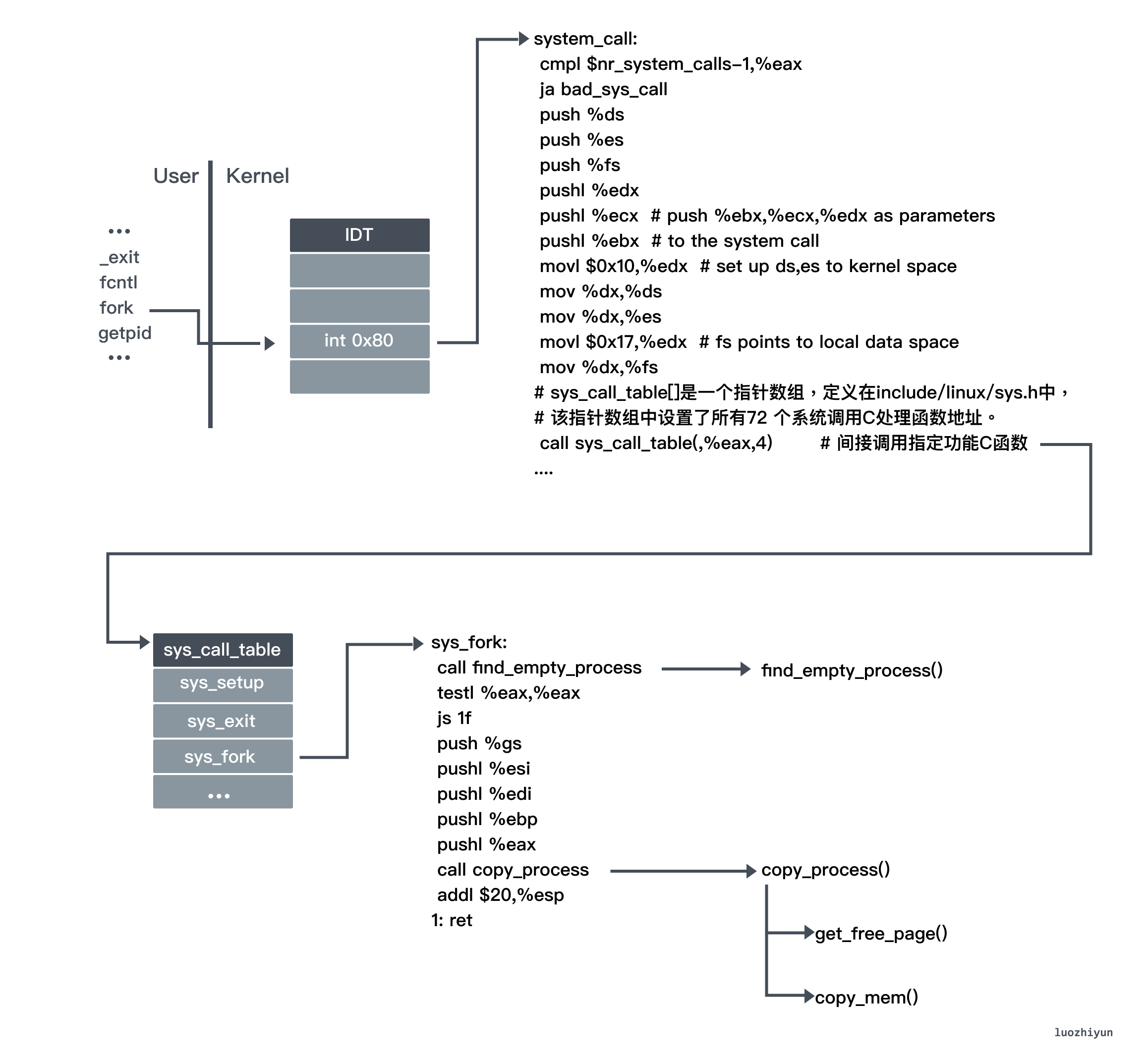
The fork function is also triggered by the int 0x80 soft interrupt, since it is one of the system calls. After triggering the int 0x80 soft interrupt, it switches to the kernel state and finds the corresponding function in the sys_call_table according to the index of fork (i.e. 2).
Then we get the corresponding C function sys_fork, which jumps to _sys_fork because the name of the corresponding C function is preceded by an underscore.
In _sys_fork, the first call is to find_empty_process to request a free position and get a new process number pid. The free position is determined by the task[64] array, which means that there can only be a maximum of 64 processes running at the same time, and the global variable last_pid is used to store the cumulative number of processes since the system was started. If there is a free position, then ++last_pid is the process number of the new process, and the index of the free position found in task[64] is the task number.
_sys_fork next calls copy_process for process copying.
- copy the
task_struct, which is used to define the process structure and contains all the information about the process, to the child process. - The contents of the copied process structure are then modified and initialized with 0. For example, the status, process number, parent process number, runtime, etc., and some statistics are initialized, while the rest remains mostly unchanged.
- Then copy_mem is called to copy the page table of the process, but since the Linux system uses copy on write technology, only its own page directory table entries and page table entries are set for the new process here, and no physical memory pages are actually allocated for the new process, which shares all physical memory pages with its parent process.
- Finally, the TSS (Task State Segment) segment and LDT (Local Descriptor Table) segment descriptor items of the child process are set in the GDT table, and the child process number is returned. The TSS segment is used to store process-related information, such as some registers, current privilege level, etc.
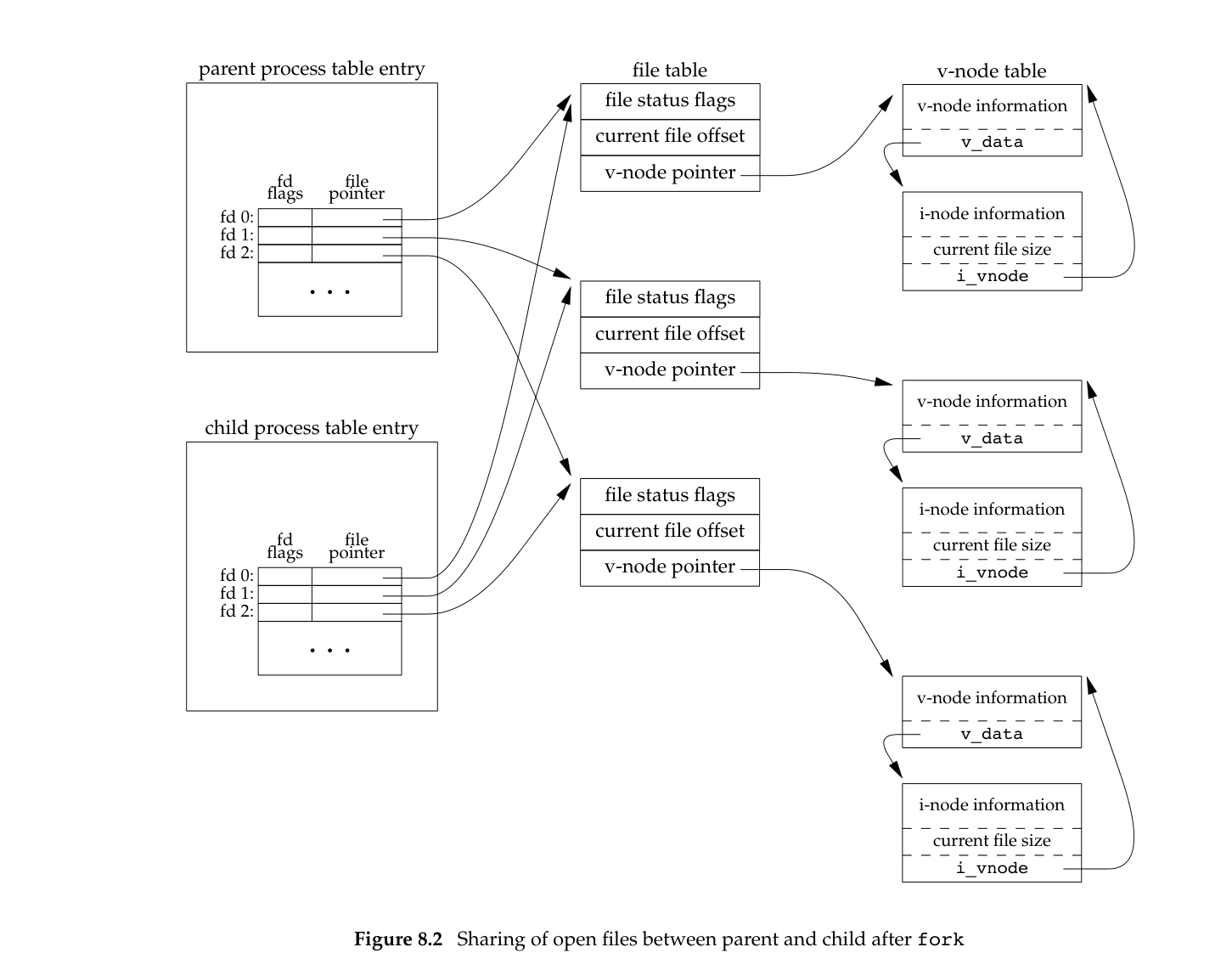
Note that the child process also inherits the file descriptors of the parent process, which means that the child process will make a copy of all the file descriptor table entries of the parent process, which means that if the parent process and the child process write a file at the same time, there may be concurrent write problems, resulting in miswritten data.
Copy-On-Write
Copy-on-write (COW ), sometimes referred to as implicit sharing [1] or shadowing ,[2] is a resource-management technique used in computer programming to efficiently implement a “duplicate” or “copy” operation on modifiable resources.[3] If a resource is duplicated but not modified, it is not necessary to create a new resource; the resource can be shared between the copy and the original. Modifications must still create a copy, hence the technique: the copy operation is deferred until the first write.
As defined in COW above, it is a delayed copy resource optimization strategy, usually used in copy-copy operations, where if a resource is only copied but not modified, then the resource is not really created, but shared with the original data. Therefore, this technique can defer the copy operation until after the first write.
After the fork function is called, the parent and child processes actually share physical memory because of Copy-On-Write (COW), and do not make a copy directly. kernel sets read-only permissions to all memory pages that will be shared. When the parent and child processes both read memory only, the exec function can then be executed without a lot of data copying overhead.
When one of the processes writes memory, the memory management unit MMU detects that the memory page is read-only and triggers a page-fault, the processor gets the corresponding handler from the interrupt descriptor table (IDT). In the interrupt procedure, the kernel makes a copy of the page that triggered the exception, so the parent and child processes each hold a separate copy, and then the process modifies the corresponding data.
The benefits of COW are obvious, but there is also a corresponding disadvantage. If both parent and child processes need to perform a large number of write operations, a large number of page-fault exceptions can be generated. A page-fault is not without cost, as the processor will stop executing the current program or task and instead execute a program dedicated to handling interrupts or exceptions. The processor will fetch the corresponding handler from the interrupt descriptor table (IDT), and when the exception or interrupt has been executed, it will continue back to the interrupted program or task to continue execution.
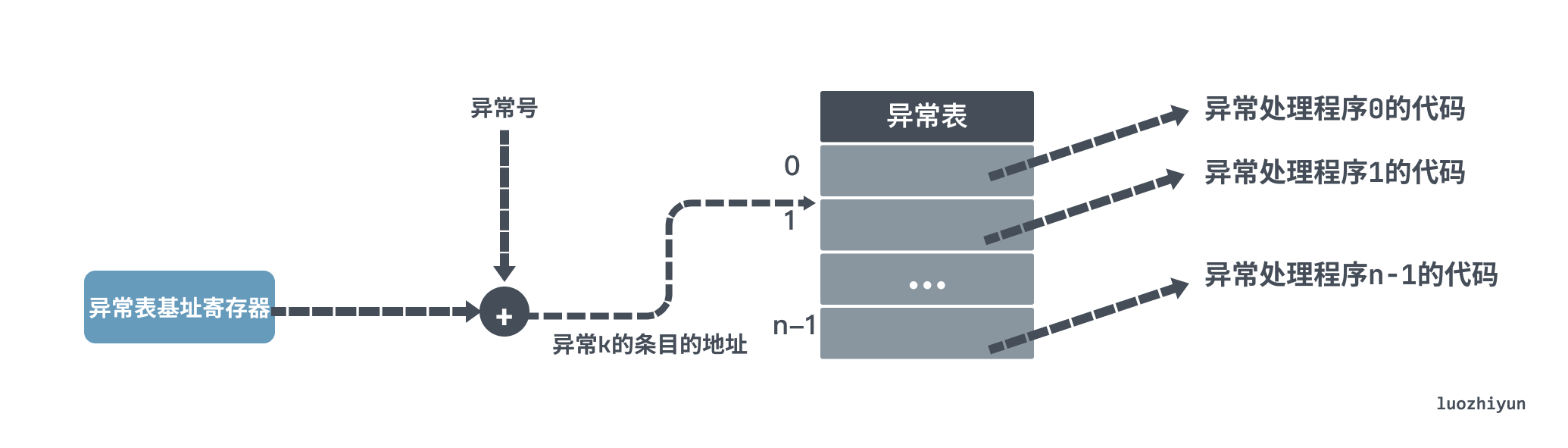
This means that a page-fault exception causes a context switch and then a query to copy the data to a new physical page. If there is not enough memory when a new physical page is allocated, then a swap needs to be performed, the corresponding elimination strategy implemented, and then the new page is replaced. So after fork, avoid a lot of write operations.
Orphan processes & zombie processes
Because Linux provides a mechanism to ensure that whenever the parent process wants to know the status of the child process when it finishes, it can get it. So even if the child process is finished running, it will still be hanging there, and the parent process can get some status information until it is released when the parent process fetches it via wait / waitpid.
If a process does not call wait / waitpid, the reserved information will not be released and its process number will be occupied all the time, which is how zombie processes are born. If a large number of zombie processes are created, the system will not be able to create new processes because there are no available process numbers, so it is harmful.
An orphan process is a parent process that quits while one or more of its children are still running, so those children will become orphan processes. The orphan process will be hooked up to the init process (process #1), which will wait cyclically for its exiting children, so the orphan process is not a problem.
Summary
This article is still relatively clear, there is no big concept. First of all, before understanding fork, you need to understand the exception & interrupt mechanism of the operating system, fork will trigger a soft interrupt, get caught in the system call function, and finally find the corresponding processing function according to the system function call table to create a child process and copy some data from the parent process. At this time the virtual page table is copied, due to the existence of COW does not immediately copy the physical memory, but will be delayed until the time of writing, through the page fault interrupt to copy the physical memory data, and finally added a little knowledge of orphan processes & zombie processes.