Overview
Generally speaking, turning a C source file into an executable requires compiling to generate a target file, and then linking multiple target files to create the final executable.
Write source code -> Compile to generate target file -> Link to generate executable file
Because the code in our projects is often scattered in different files, we need to synthesize multiple target files into one executable, and as for how to do that, that’s what linking is going to do. As shown in the following diagram, the linker combines two target files into one executable.
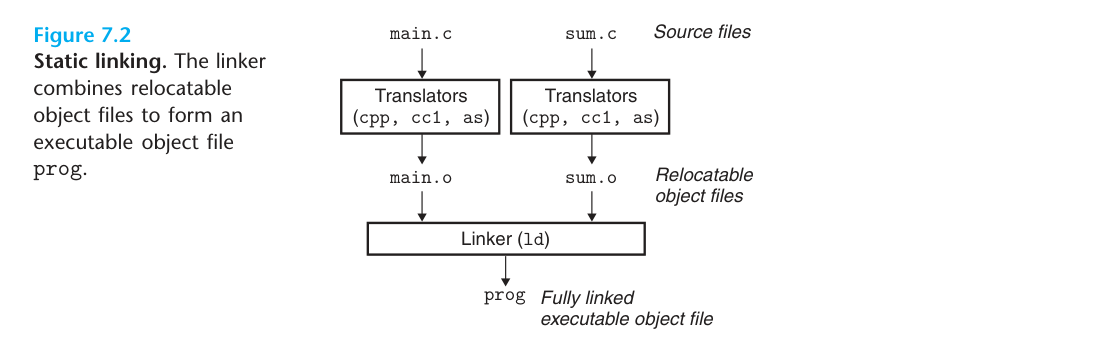
On Linux platform, target files and executable files are similar in content and structure, so generally target files and executable files are stored in ELF (Executable Linkable Format).
ELF is a format for object files that defines what is put in different types of object files and in what format they are put. We group ELF files into the following categories.
- relocatable files, which are .o files generated by the assembler and can be used to link to executable files or shared target files.
- executable object files (Executable file), which represent ELF executable files, generally without extensions.
- a shared object file, a dynamic library file, or a .so file.
So let’s start by looking at the file structure, what is contained in the ELF file, and then how the linker will merge the target file.
ELF file structure
|
|
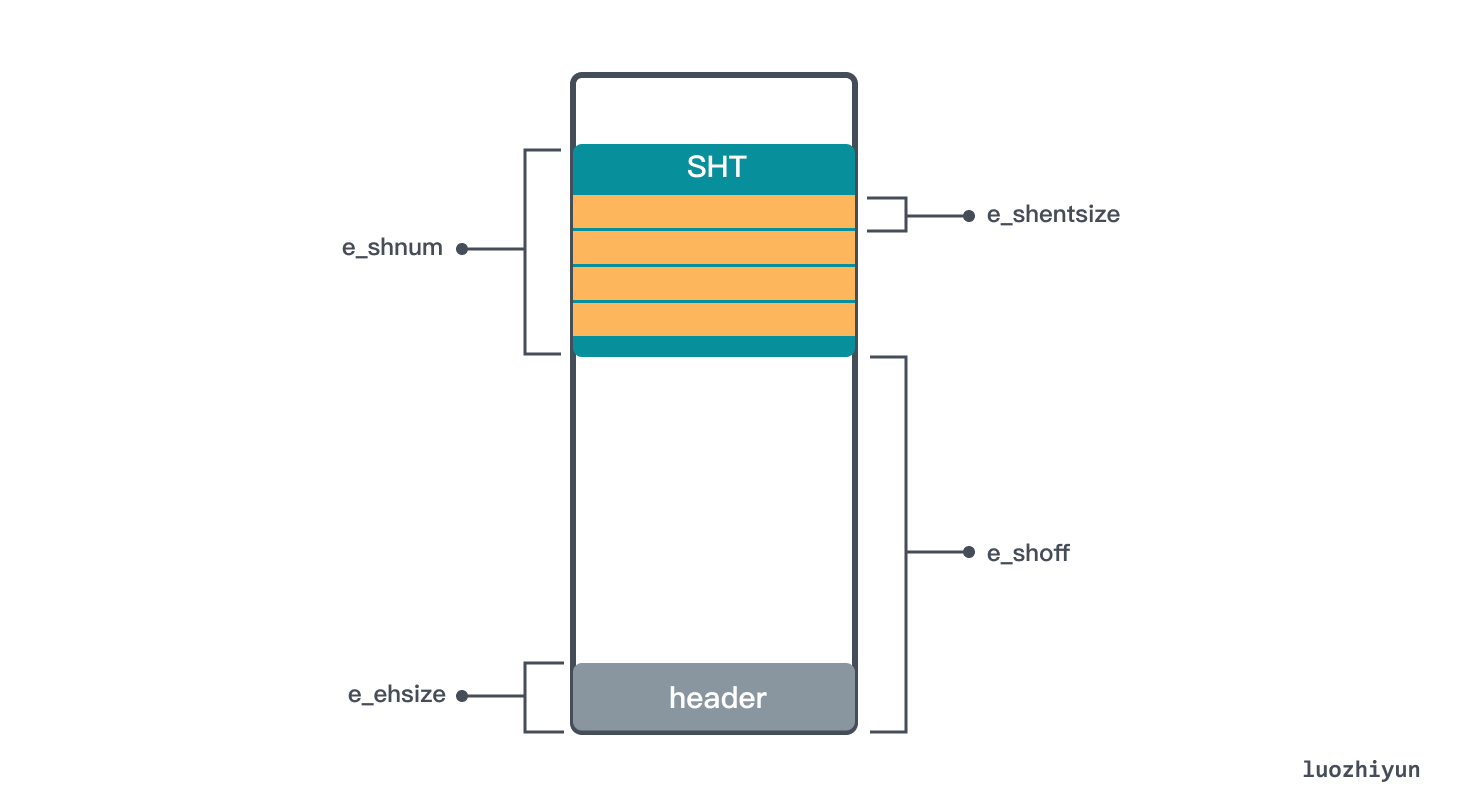
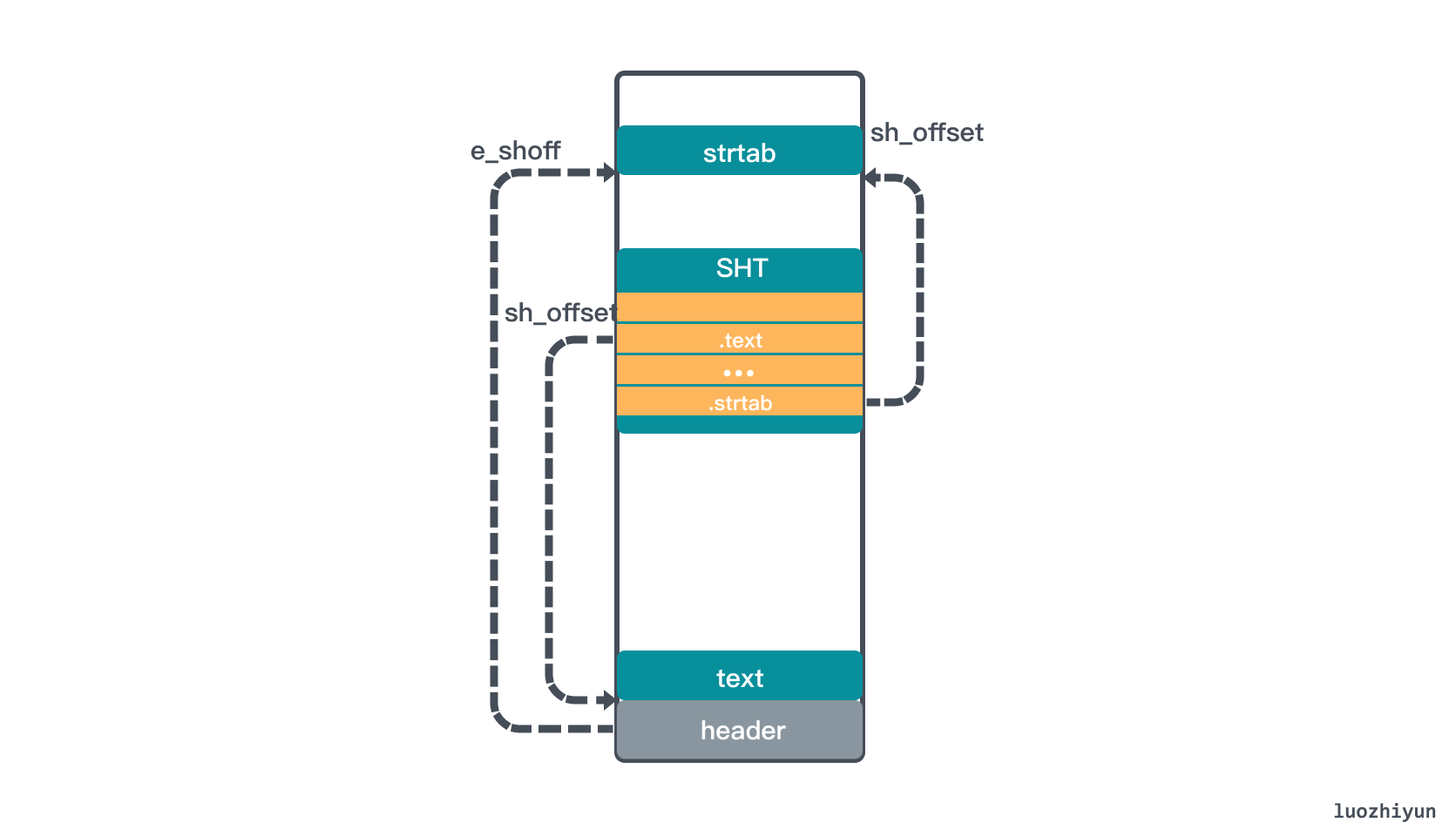
Let’s first see how to locate the Section Header Table (SHT) with header information, which holds a set of Sections, such as .text, .bss, .data, .bss, etc. To locate the SHT, we need to know the starting position, the size of the Section inside the Table, and the number of Sections in the Table.
In the above header data structure, e_shoff is the offset position of SHT at the ELF start address, through which the SHT start position can be calculated; e_shentsize is the size of Section in SHT; e_shnum is the number of entries in SHT.
Another noteworthy thing in the header data structure is the e_shstrndx field, which is the index of the string table and can help locate the string table.
I will take you through the manual parsing of the hexadecimal ELF file structure to get a clearer understanding of the ELF file structure, if you are interested, you can follow along and verify it.
Let’s start with an example to illustrate.
Compile the above file with gcc -c testelf.c -o testelf.o command, and then check the compiled testelf.o content with hexdump testelf.o. According to the structure format of Elf64_Ehdr, we can decode the ELF Header information.

According to the above markers, we can find e_shoff means the SHT offset is 0x0140 (320 bytes), e_ehsize means the ELF header size is 0x0040 (64 bytes), e_shentsize means the size of Section in SHT is 0x0040 (64 bytes), e_shnum means SHT Section number 0x000b (11 bytes), and e_shstrndx string table offset 0x0008 (8 bytes).
Section table
So according to e_shoff we can find the offset position of the corresponding SHT, and from e_shentsize we can know that the size of each Section is 64 bytes, total 11 items, then we can find the corresponding SHT corresponding data. The Section in the SHT is described by the structure Elf64_Shdr.
|
|
Then we can go on to parse the structure based on the above question and the character information output from hexdump testelf.o.
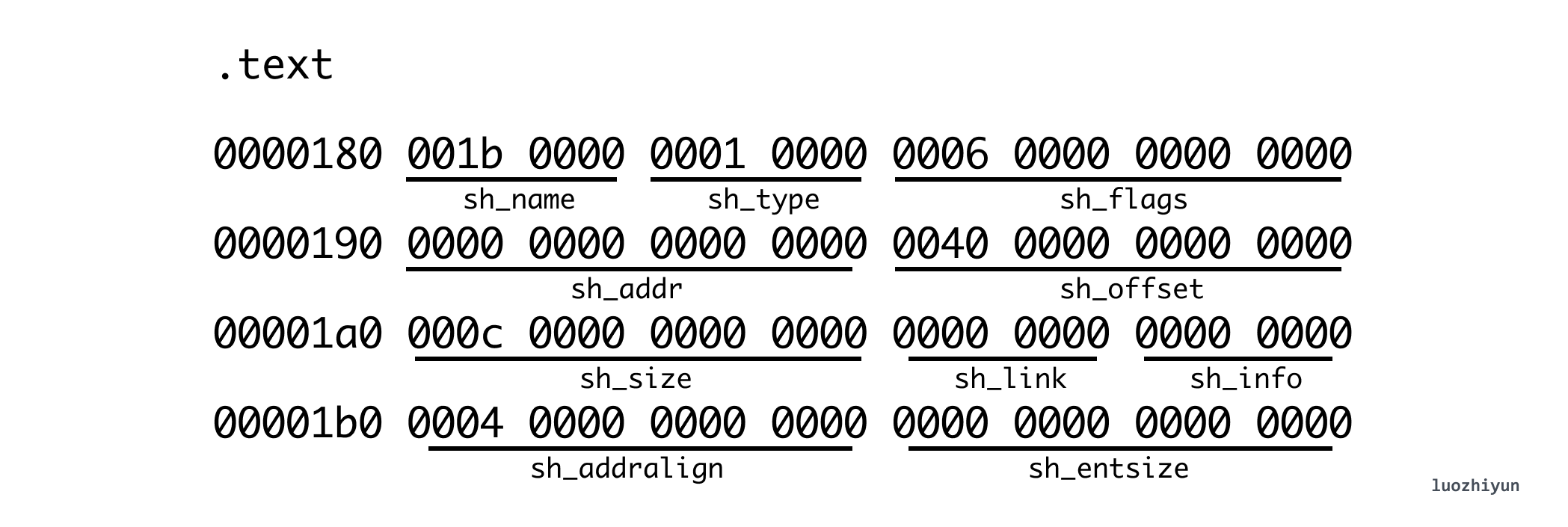
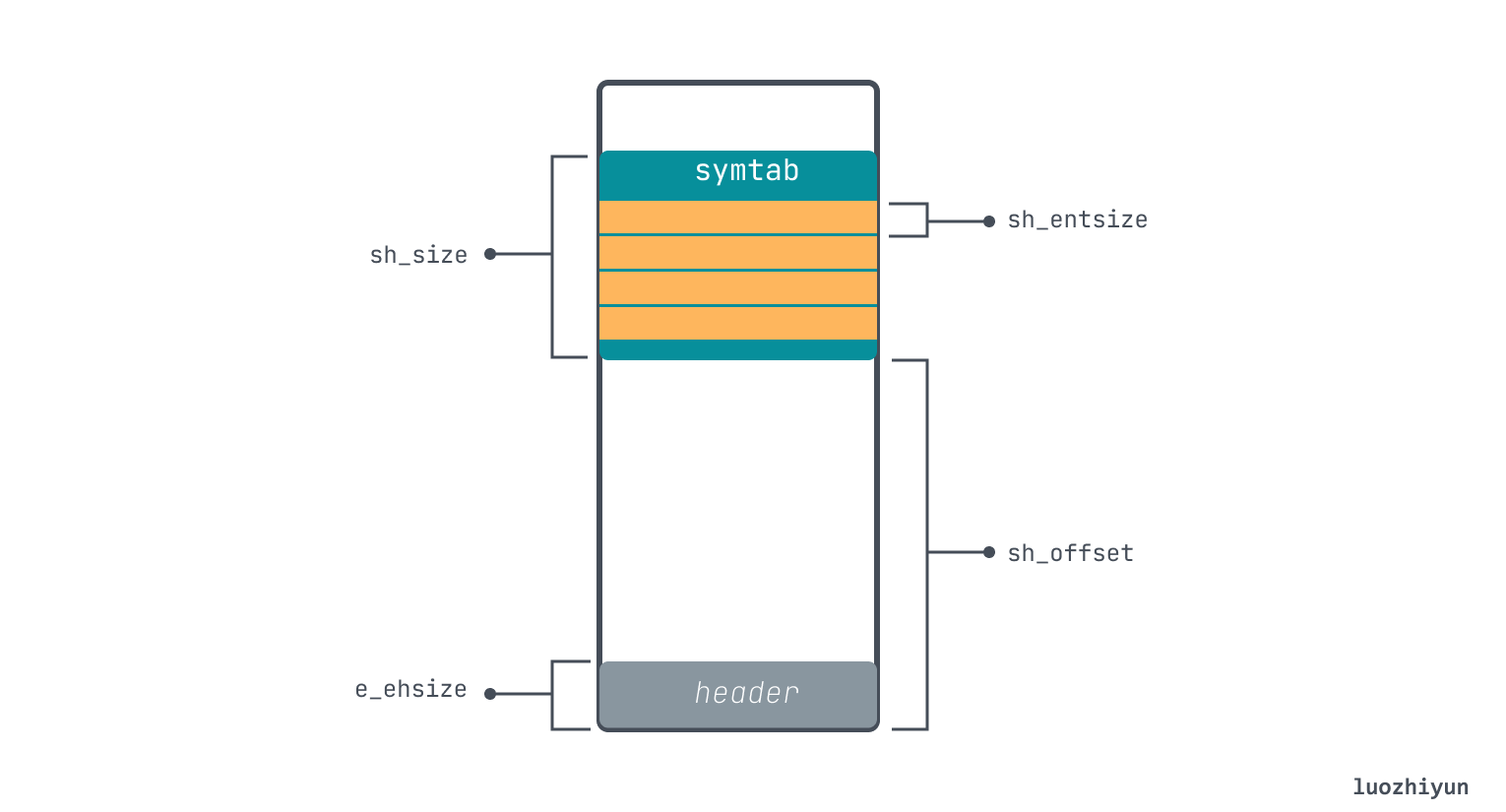
I only parsed the text Section here, from which we can see that sh_offset is 0x0040 (64 bytes), which means it directly points to the memory block behind the ELF header. sh_size is 0x00c (12 bytes), which means that func1 and func2, two empty functions, occupy 12 bytes. Note that Section[0] is only a placeholder, it is all zeros.
In other words, we can find the specific data information of the corresponding Section by the above Section description information. Another example is the strtab Section below.
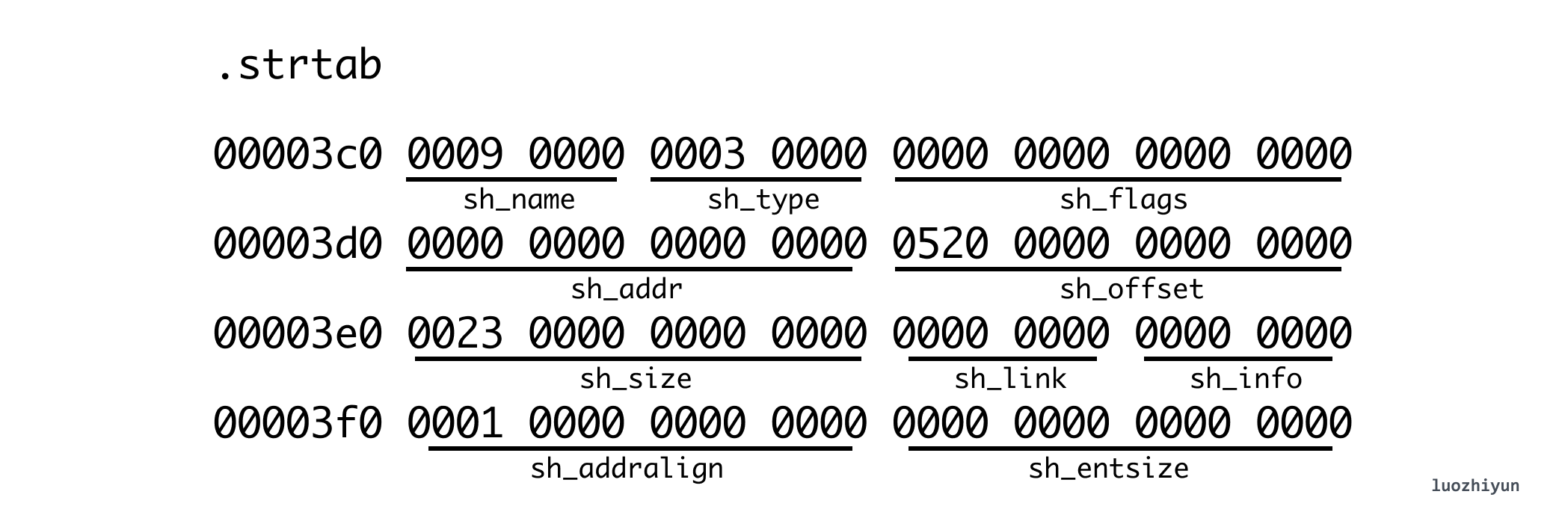
From the sh_offset above, we can know that its offset position in the ELF file is 0x520 and its size is 0x0023 (35 bytes). Then we can use this information to find the data of the corresponding string table (the right side is the character corresponding to hex ascii), and we can output the string ascii by hexdump -C on the right side.
It is worth mentioning that Elf64_Shdr.sh_name stores the offset pointed to by .shstrtab, so you can find it yourself. From the above analysis, we can roughly see that the ELF file is structured as follows.
Symbol table
One of the Sections in the SHT we talked about above is .symtab, which is the symbol table. In the context of the linker, there are three different kinds of symbols.
- global symbols, which can be referenced by other modules, i.e. ordinary C functions and global variables.
- External symbols, which are defined and referenced in other modules. For example, functions or variables that are modified by extern in C.
- local symbols, symbols that can only be referenced by this module, i.e. C functions and global variables with static attributes, which can be referenced in this module, but not in other modules.
In the above example, we can find the symbol table .symtab in the SHT.
The .symtab Section points to another piece of memory, the symbol table, which consists of several table entries, and corresponds to the symtab file like this.
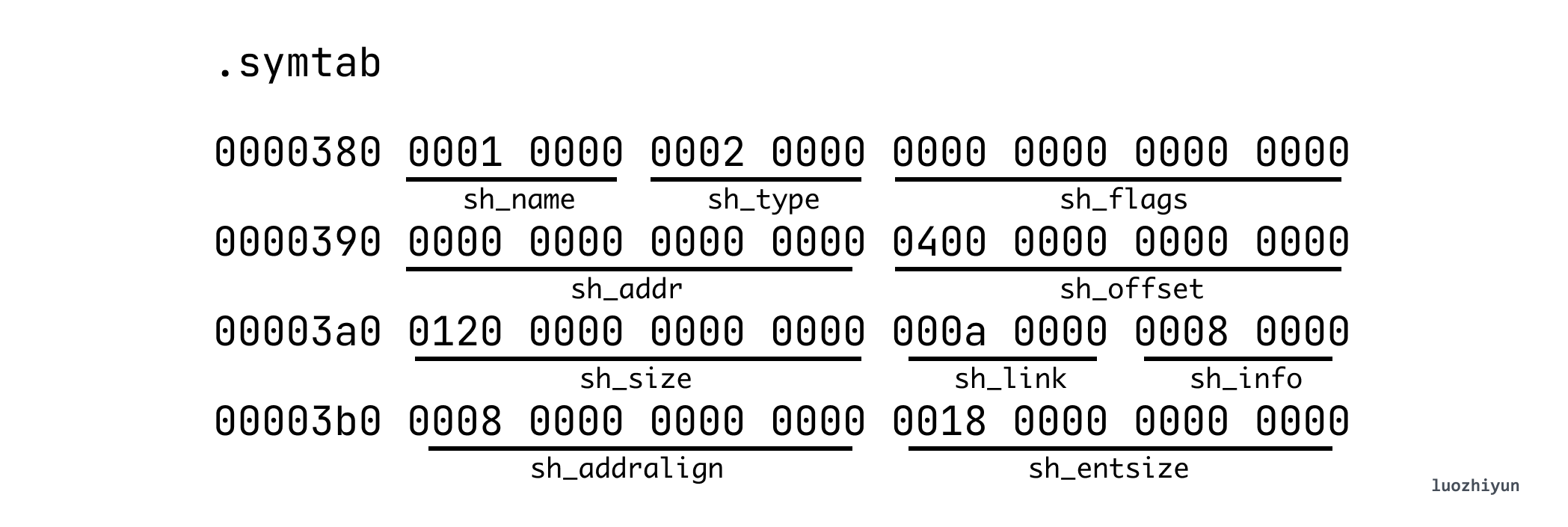
According to the way we look at Section above, we know that its offset is 0x400, the total size is 0x120 (288 bytes), and each item of .symtab has a fixed size of sh_entsize 0x18 (24 bytes), so we can know that it has a total of 12 items. symtab table items have the following data structure.
|
|
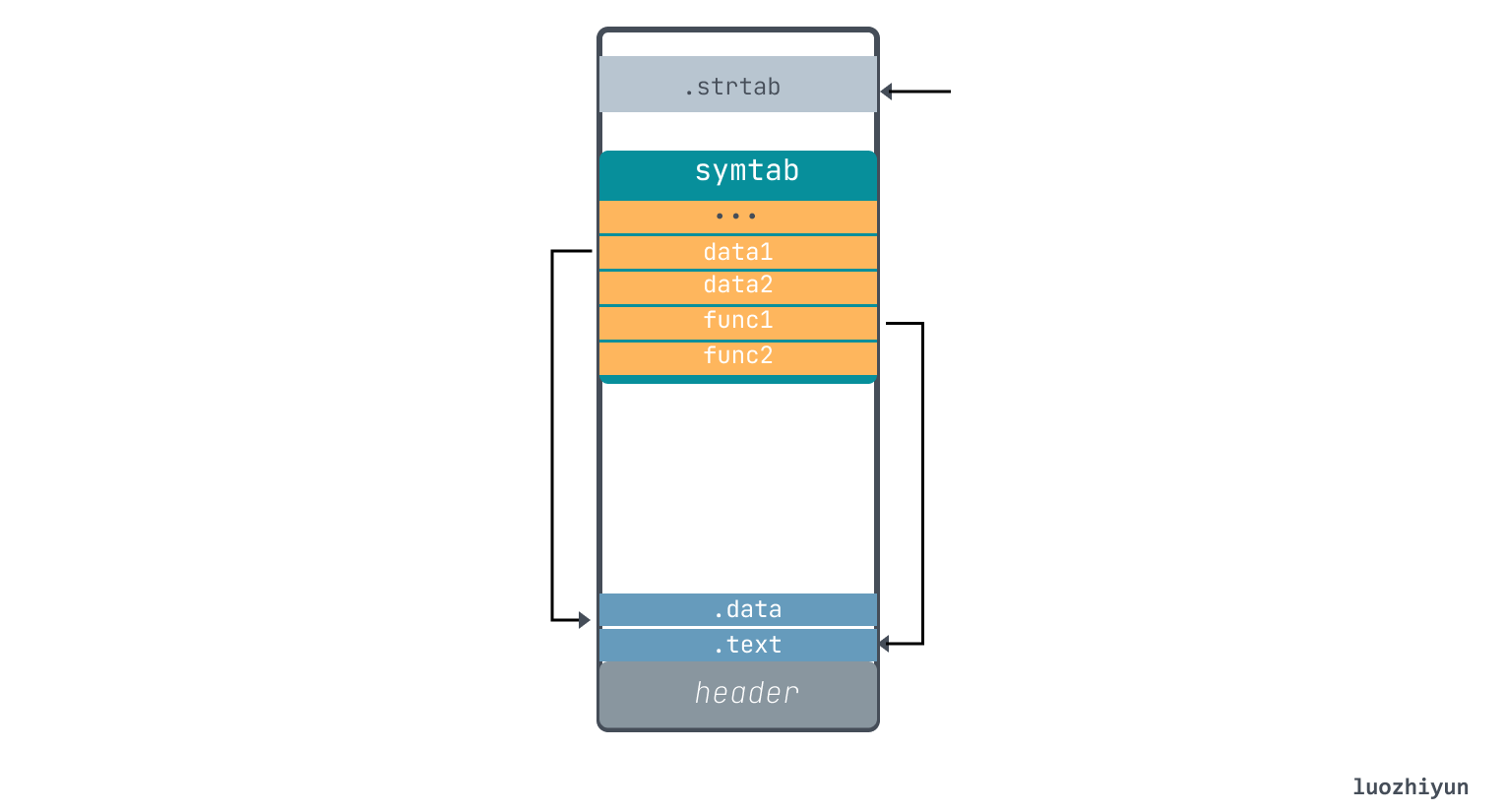
According to the offset position of symtab, we can find the corresponding table entry, from which we retrieve the table entry we defined.

data1.st_name 0x0b (11 bytes) means that the .strtab table starts from offset 0x0b and ends at 00 (’\0’), and the hexadecimal code obtained is 64 61 74 61 31, which corresponds to ascii is d a t a 1.
st_shndx indicates the SHT index location, data1.st_shndx is 0x02 which means that the data is in SHT[2], that is, in the .data Section.
st_value is the address represented by each symbol, in the target file, the symbol address is relative to the Section where the symbol is located, in the executable file, this value represents the virtual address, currently we are parsing the target file, so data1.st_value is 0x00, corresponding to the offset in the .data Section is 0;
st_size is the size occupied by the symbol, data1.st_size is 0x08 (8 bytes), so according to this information you can take out the value in data is 0x0012d617, convert to decimal is we fill in 1234455. so you can also find data2 is 0x03faf713 convert to decimal is 66778899.

Then, based on the description of the table entry in symtab, we can determine the following location.
The lower four bits of this field are the type of the symbol (Type) and the upper four bits are the association of the symbol in the source file (Bind).
The Type mainly indicates whether the symbol is defined as a variable or a function, etc. We will mainly look at the following.
In the above example, data1 and data2 Type are both 0x1, indicating an Object object. func1 and func2 are both 0x2, indicating a func function.
Bind mainly describes the type of this symbol and defines 9 types, let’s look at the first two.
data1, data2, func1, func2 are all global symbols, so they are all 0x1 for STB_GLOBAL.
Here we can look at the variables and functions modified by static again, for example, we declare the following again.
In addition to finding the symbol table based on hex above, we can also use readelf -s to quickly see.
As we can see above, the static variables data3 and func3 are still in .data and .text respectively compared to the global variables. Since they are still variables and functions, the Type remains the same, but since they are modified by static, the Bind type becomes STB_LOCAL, which is the main difference between static and global symbols.
For external symbols, they are generally modified with extern, but extern can be omitted from the modification, so they are discussed separately for functions and variables. For functions, the same symbols are generated whether or not they are modified by extern, as long as they are not defined. Note, however, that the compiler will optimize this useless declaration if it is not referenced in the current file. Only if it is referenced will it appear in the symbol table.
For the two functions above, which are not defined and therefore do not take up space in the .text Section, their table entries look like this.
st_shndx are UND, that is, SHT[0], which means no definition. Also their Type is NOTYPE for no type. However, since they are not modified by static, Bind is still GLOBAL for global symbols.
For variables, the situation is a bit more complicated, because if extern is omitted, it is not necessarily of type extern, but may just define a global variable. We define these three variables below.
Here we look at the corresponding symbol table.
For data4, it is shown as extern, so it behaves the same way as the extern-modified functions above. data4 can be represented as an extern variable as well as data5, but data5 is initialized by default assignment and its address is located in the .comment Section of the SHT, which is a weak symbol that is further processed in the It is a weak symbol that is further processed in symbol resolution. The .comment is a temporary section in the ELF and does not exist in the executable. The variable stored in the .comment will decide its destination in the link, if the link finds its definition, then the address is in the .data Segment of the executable, otherwise it is initialized to 0 and the address is directed to the .bss Segment.
For data6 it is shown as initialized to 0. ELF will put all variables initialized to 0 in the .bss section, so there is no need to define them multiple times in .data. The .bss section is used to save space by storing uninitialized global and static variables.
We can also see from the above that the difference between .comment and .bss is very subtle. The current version of GCC assigns symbols in relocatable target files to .comment and .bss according to the following rules.
- .comment: uninitialized global variables.
- .bss: uninitialized static variables, and global or static variables initialized to zero.
Relocation table
When the assembler generates an ELF target file, it encounters references that it cannot handle, perhaps a function or variable defined in another ELF file is referenced by the current ELF file code. So for these unknown target references, it generates a relocation entry that tells the linker how to modify this reference when merging the target file into an executable.
The relocation entries for code are stored in .rel.text, and the relocation entries for initialized data are stored in .rel.data. The following is the format of relocation entries.
r_offset records the referenced position, which is the byte offset relative to the current section; r_info is a composite structure with the lower 4 bytes of the relocation type, which tells the linker what to do with the relocation item, and the upper 4 bytes is the serial number of the referenced symbol in the symbol table .symtab; r_addend is the offset value, which is used to correct the final computed position.
Let’s take the following example.
By checking the table we can know that:

Then we execute the disassembly objdump -d test_rel.o and we can see that the text section corresponds to the hexadecimal system and the assembly can find the corresponding code based on the r_offset offset.
|
|
For the symbol index we can also find the corresponding symbols in the symbols.
There is a type field in Elf64_Rela that is not spoken about, because it involves a specific strategy for calculating the location of the referenced object, and different strategies have different calculations. These strategies are actually accomplishing one thing, that is, when the program accesses the referenced object, it will calculate the location of the referee based on the current location of the referenced object, and these strategies are not talked about in detail here.
Static Linking
Because our code is stored in separate files in the actual development process, there will be a dependency between different files, so what static linking has to do is to process multiple input target files and merge them into one executable file.
Let’s assume that there are only these two files in the program.
|
|
Then the target file is processed and merged into an executable by using gcc a.o b.o -o ab, or of course we can use gcc a.c b.c -o ab to generate an executable file directly from the source file.
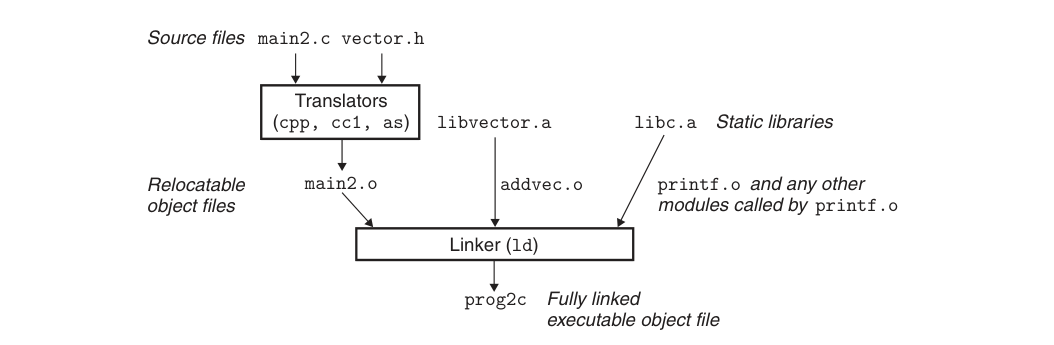
The whole linking process is divided into the following steps.
- symbol resolution, after all the ELF files are read into memory, different files may declare the same symbols, this step mainly resolves conflicts.
- section merging, different files will have the same section, then the same section needs to be put into the same section.
- relocation, when the assembler generates an ELF target file, it will encounter references that cannot be handled, maybe a function or variable defined in another ELF file is referenced by the current ELF file code, then the reference location needs to be reset.
Symbol resolution
This step mainly solves the symbol conflicts between different files, so we need to use the symbol table, which also mainly looks at global symbols, because only global symbols can be referenced in different files. As mentioned in the symbol table above, st_shndx in .symtab indicates the index of the symbol in SHT, and the number means that it is defined, besides there are several special pseudosection types: ABS, COM, UND.
ABS means a symbol that should not be relocated, so we can ignore it here; COM means an uninitialized data target that has not yet been assigned a location, and since it does not exist in the executable, it represents a temporary defined symbol; UND means an undefined symbol, that is, a symbol that is referenced in this target module but defined in other files.
In addition to those mentioned above, there is also a symbol modified by __attribbute__((weak)), which is also a weak reference.
So the summary is: defined symbols are strong symbols, COM, UND, and __attribbute__((weak)) are weak symbols. Then according to the rules in CSAPP is:
- multiple strong symbols with the same name are not allowed.
- if there is a strong symbol and multiple if symbols with the same name, then choose the strong symbol.
- if there are multiple weak symbols with the same name, then choose any one of these if symbols.
Section Merging
After our compiler converts our code text into multiple target files ending in .o, the linker will merge the target files into a single executable object file. From the above analysis we know that each target file will contain sections, so we need to merge sections of the same type.
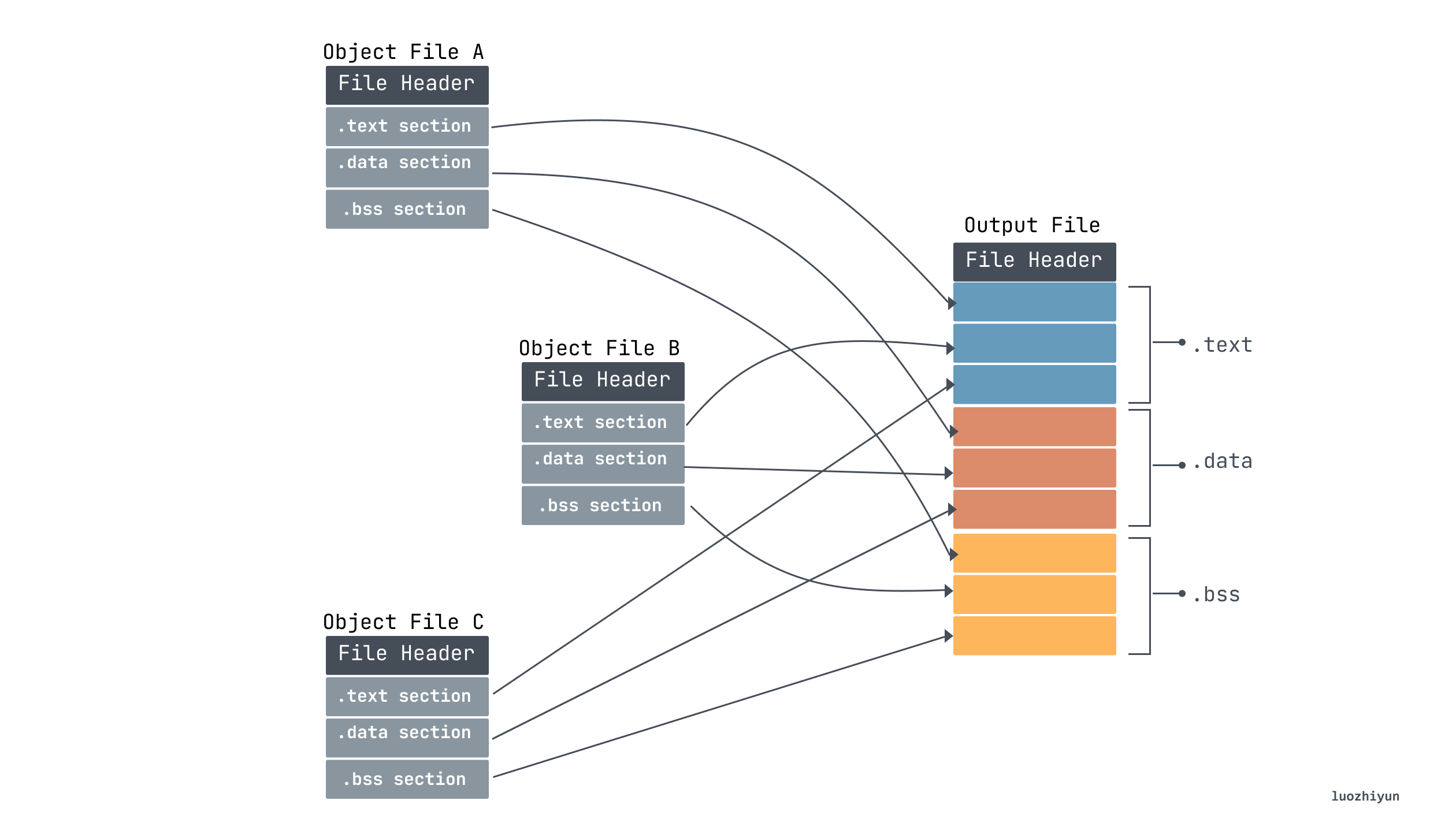
Also, after the merge is completed, multiple sections are merged into segments. The Program Header Table in the ELF Header is used to describe the segment information. Because the Program Header Table is not used in the linking process, it does not exist in the target file, and the segment is only used when loading. The loader loads and runs the program based on the Segment information in the executable, so it is present when the executable is generated.
After linking the a and b files above, we can use readelf -l to see the corresponding segment information.
|
|
The segment information above clearly shows the mapping to section. segment is defined in the Elf64_Phdr structure in /usr/include/elf.h. The type LOAD in the segment table indicates that it is a loadable segment, and the contents of the segment will be copied from the file into memory.
Relocation
After completing symbol resolution and section and merging, we also need to relocate symbols and references, and the relocation process will calculate a virtual address based on their location, according to which the program can find the corresponding implementation at runtime.
Let’s take a look at the main function reference location objdump -d ab
|
|
Let’s see how the relocation is calculated. First, let’s look at the relocation term of a.o.
|
|
The Type item indicates the addressing method, we know there are the following by looking up Relocation Types, and Calculation indicates the calculation method as follows.
| Name | Value | Field | Calculation |
|---|---|---|---|
R_X86_64_NONE |
0 | none | none |
R_X86_64_64 |
1 | word64 | S + A |
R_X86_64_PC32 |
2 | word32 | S + A - P |
R_X86_64_GOT32 |
3 | word32 | G + A |
R_X86_64_PLT32 |
4 | word32 | L + A - P |
R_X86_64_COPY |
5 | none | none |
R_X86_64_GLOB_DAT |
6 | word64 | S |
R_X86_64_JUMP_SLOT |
7 | word64 | S |
R_X86_64_RELATIVE |
8 | word64 | B + A |
R_X86_64_GOTPCREL |
9 | word32 | G + GOT + A - P |
R_X86_64_32 |
10 | word32 | S + A |
R_X86_64_32S |
11 | word32 | S + A |
R_X86_64_16 |
12 | word16 | S + A |
R_X86_64_PC16 |
13 | word16 | S + A - P |
R_X86_64_8 |
14 | word8 | S + A |
R_X86_64_PC8 |
15 | word8 | S + A - P |
A: indicates the Addend value of the relocated item. GOT: indicates the address of the Global Offset Table. L: the segment offset or address of the process link table entry of symbol. P: the segment offset or address of the memory cell being relocated, calculated using r_offset. S: the value of the symbol whose index is located in the relocated item.
For the location marked reference<1>, the call is undef_func and the corresponding Type is R_X86_64_PLT32, so it is calculated as L + A - P. L is 0x1152 by checking the symbol table here, A is 4 by checking the .rela.text table above. - P is equal to the current main function address + r_offset, we know that the main address is 0x1129, r_offset is 0xe, so P is 0x1137. So the final result is 0x17, which translates to the assembly instruction e8 17 00 00 00 callq 1152 < undef_func> .

Let’s look at the undef_array reference in the reference<2> position, its Type is R_X86_64_PC32, it is the relative addressing of the program counter, the relative object is %rip, that is, when the program runs to this line, you need to use the %rip pointer to find the referenced location, that is, the location of the undef_array symbol which is the location of the undef_array symbol. It is calculated as S + A - P. S is 0x4010, A is - 8, P is the main address value + r_offset of 0x113D, and the final result is 0x4010 + (- 8) - 0x113D of 0x2ECB, which is the result of The corresponding designation is the offset of %rip movl $0x1,0x2ecb(%rip).

Dynamic linking of shared libraries
According to static linking, each time static linking is completed, the .text and .data sections of all ELF files are copied to the executable. If there are n executable files, then the .text and .data data will be copied to memory several times, which is a waste of memory. It is also a waste of time to compile the link again every time the module is updated due to static linking as the size of the program grows.
Shared library is a product born to solve the problem of static linking. It is a target module that can be loaded to an arbitrary memory address and linked to an in-memory program at runtime or load time, a process called dynamic linking, which is performed by a dynamic linker. Shared libraries are also called shared objects and are usually represented by the .so suffix in Linux systems.
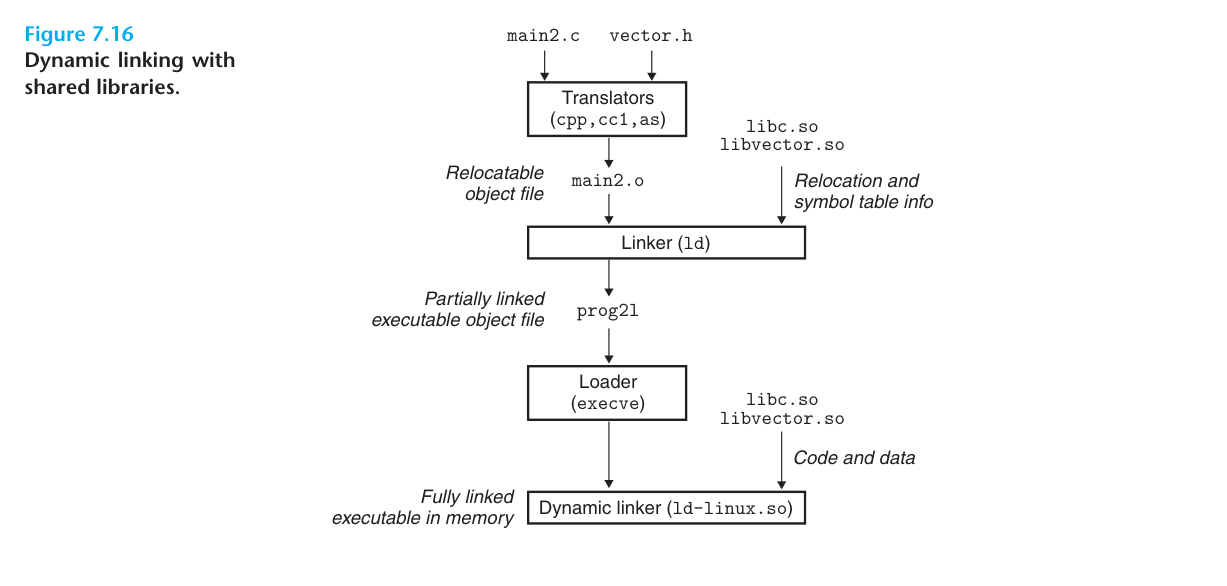
The diagram above shows the process of linking a shared library. First we create a shared library libvector.so using the following command.
|
|
The -fpic indicates the generation of address-independent code (PIC, Position-independent Code will be discussed below), and the -shared option indicates the creation of a shared target file.
The libvector.so library is then dynamically linked to our main2.c file to create the executable prog21.
|
|
The above step will compile main2.c to main2.o and then link it to a file called prog21 executable. Unlike static linking, dynamic linking compiles main2.o without the compiler knowing the address of the vector-related function, which in the case of static linking will relocate main.o to the vector-related function address reference according to the static linking rules, but for dynamic linking, the linker will mark this reference as a dynamic link symbol and does not relocate it, leaving this process until load time.
When the loader loads and runs the executable prog21, the loader runs the dynamic linker and then completes the relocation of libvector.so and its symbolic reference.
Note that sharing does not share the entire contents of libvector.so, but only the .text readable code section, the data is still separate.
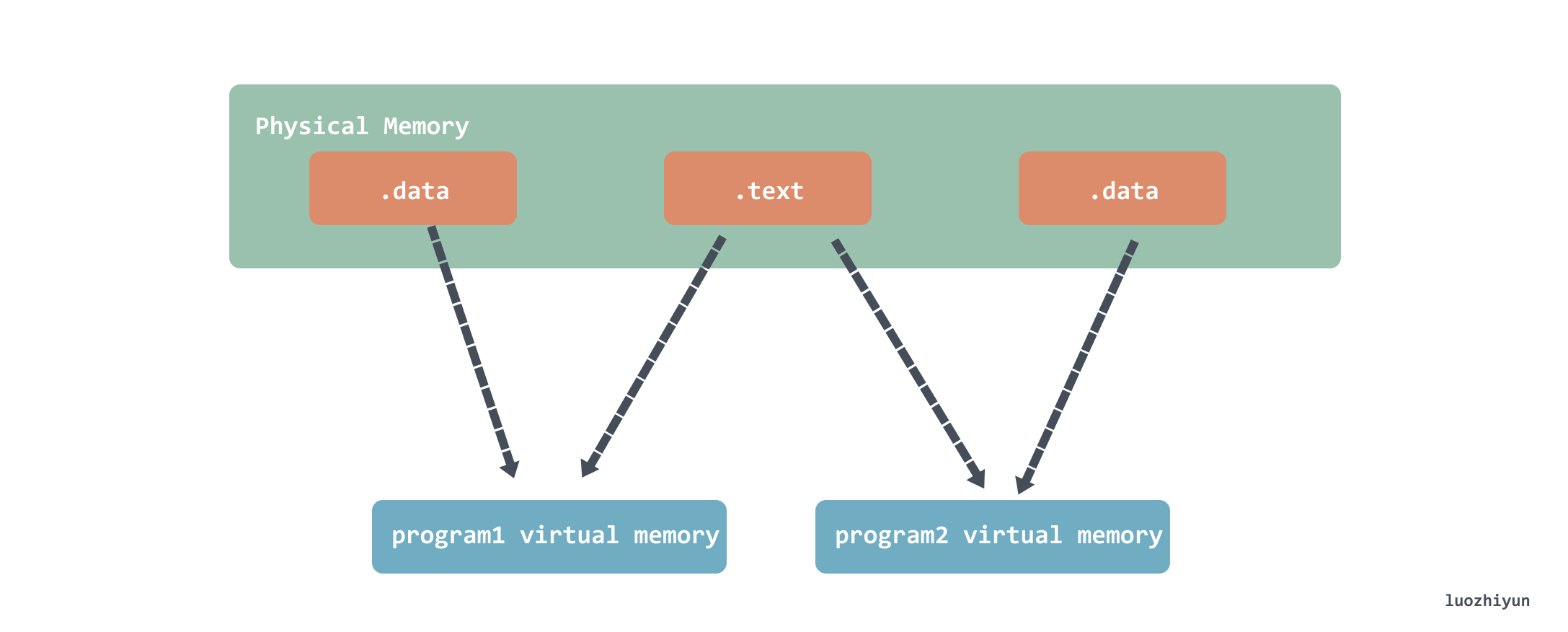
Address-independent code (PIC, Position-independent Code)
Because dynamic links share code, but the instruction part, the .text part, is unchanged, it is necessary to enable the instruction to access data or functions of other modules at runtime.
PIC Data References
To allow instructions to access data or functions in other modules, the compiler creates a global offset table (GOT) at the beginning of the .data segment. Each table entry in the GOT is 8 bytes in size and holds the absolute runtime address of the referenced symbol in the shared library.
For example, the following example.
We compile the shared library test.so:
|
|
The global variable b in the other shared library referenced here is actually address-independent and requires a GOT with a dynamic linker to determine the address of b.
Here the table entry with GOT address 0x3fd8 is found using the relative addressing of the PC 0x2ed0(%rip).
The runtime then writes the real value from GOT to %rax and copies the value of the address in (%rax) memory to register %eax, thus getting the value of b at runtime.
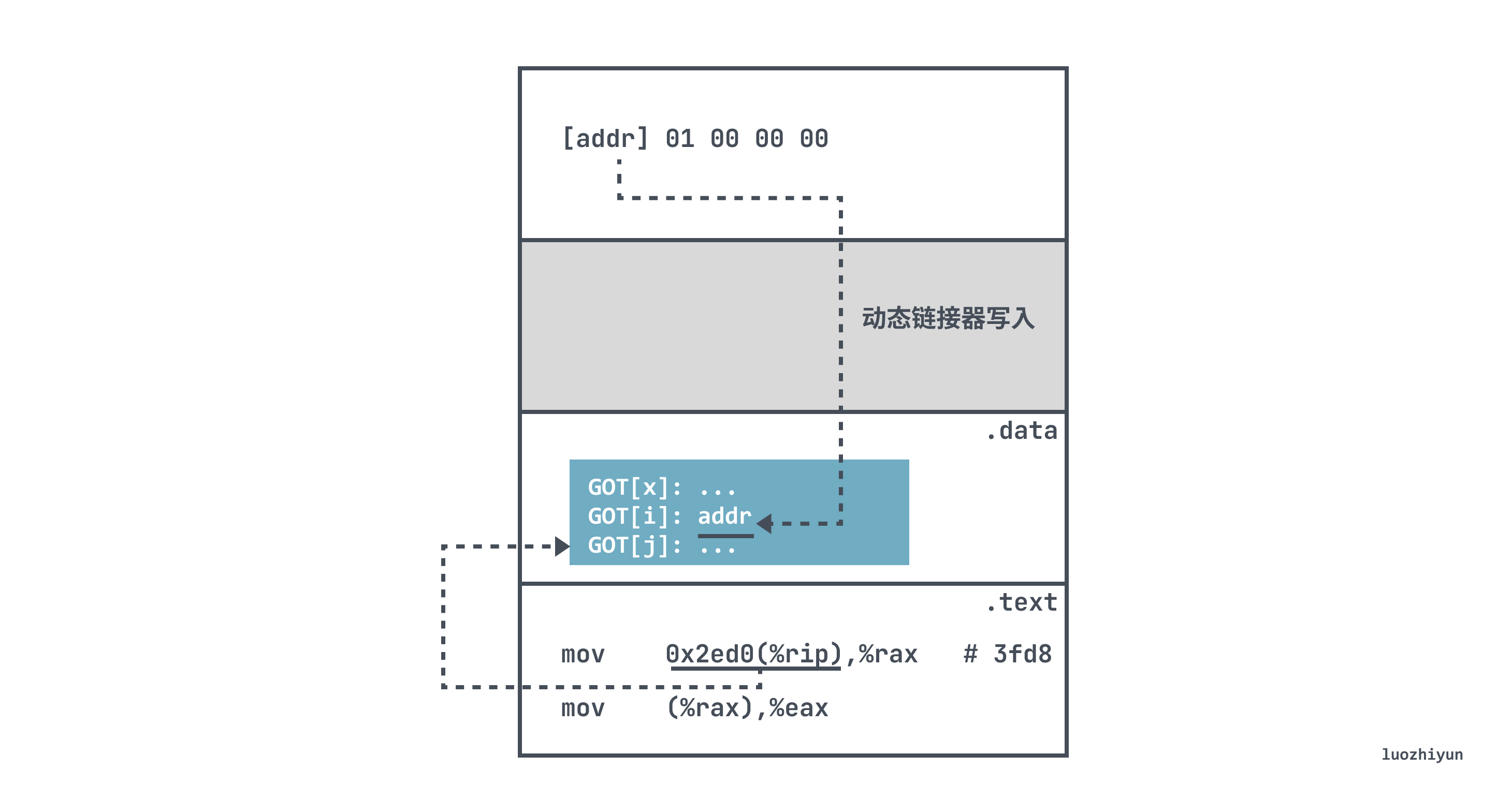
where 0x2ed0 is the fixed distance between the GOT[2] and mov instructions at runtime, so that the compiler can use the constant distance between .text and .data to generate a relative reference to the variable a to the PC, and at load time, the dynamic linker relocates each entry in the GOT so that it contains the correct absolute address of the target.
PIC function reference
For function references and data references are slightly different, function references use a practice called delayed binding, the basic idea is to bind when the function is used for the first time (symbolic lookup, relocation, etc.), and not to bind if not used.
This is because the program contains a large number of function references between modules under dynamic linking (global variables tend to be less, because a large number of global variables can lead to greater coupling between modules), so the dynamic linking of functions before the program starts to execute symbolic lookup and relocation of the number of too large will take a lot of time. Another reason is that in the process of running a program, many functions may not be used after the execution of the program, so it is actually very wasteful to link all the functions at the beginning.
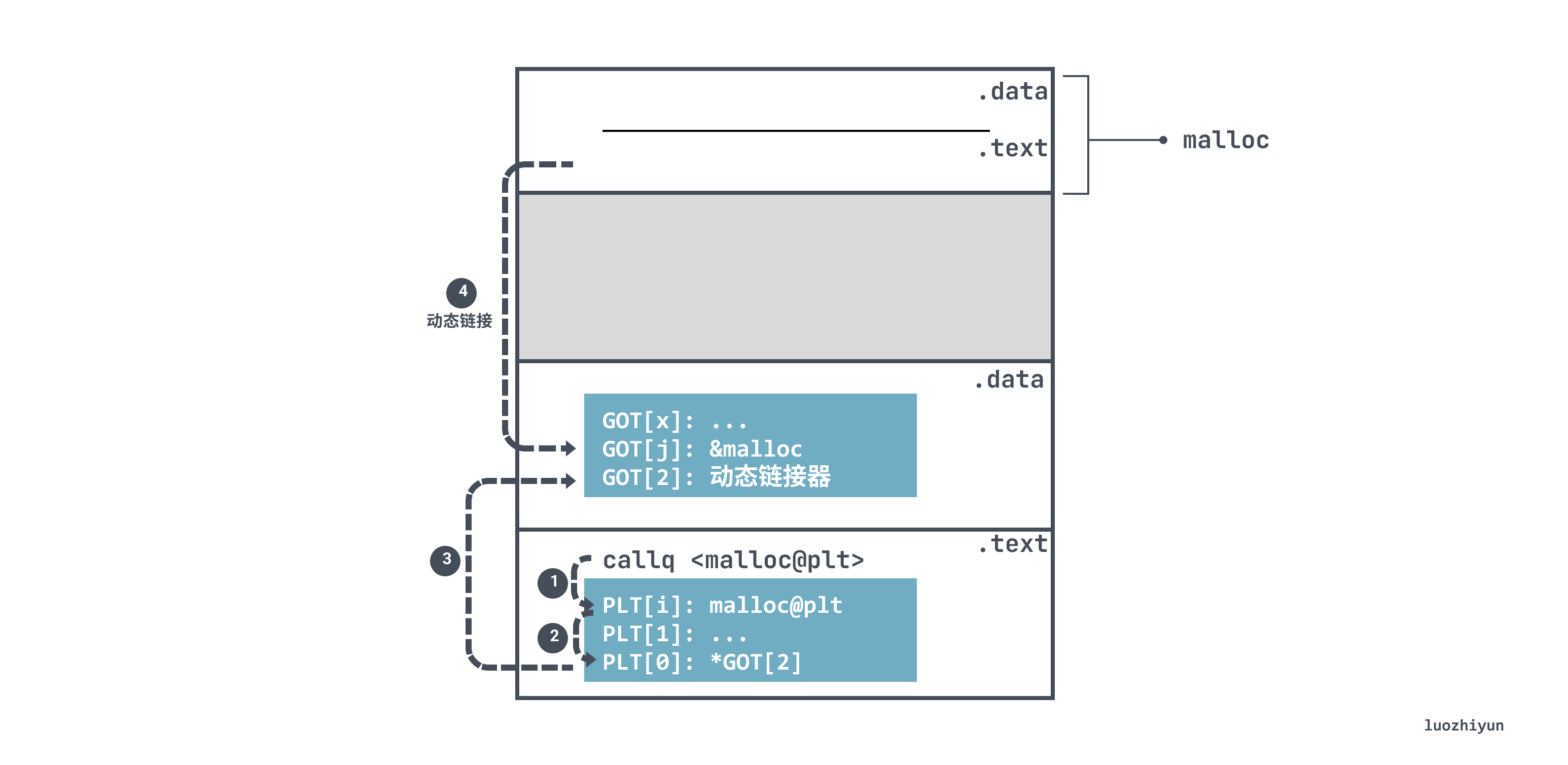
The function reference is implemented for delayed binding by means of a Procedure Linkage Table (PLT), which is an array of 16 bytes per entry, implemented in a .text segment with a number of goto-like tags, to which rip can jump.
Let’s make a simple example to illustrate.
Take the malloc function call above as an example, since the code in the .text segment does not know the address of malloc, it will jump to the PLT table entry malloc@plt corresponding to malloc when executing the call instruction.
|
|
malloc@plt takes advantage of address-independence by using relative offsets to obtain the malloc address 0x3fd0 of the cache in the GOT table.
However, because of the delayed binding, the value in the GOT table entry that is jumped to on the first run is actually the location of the dynamic linker in <.plt>, which then jumps to the dynamic linker code segment.
When the dynamic linker gets the runtime address of malloc, it fills the GOT table entry with the corresponding address value. If malloc@plt is called again, the value in jmpq *0x2f75(%rip) will be the real address of malloc, and you can jump to malloc directly without going through the dynamic linker in <.plt>.
Summary
This article actually contains three parts in general:
- explains the ELF file structure to help us understand the linking process that follows.
- a description of several processes that linking generally entails through static linking.
- finally, what are the disadvantages of static links, why there are dynamic links, and how it is done.
Through these parts of the explanation can clearly see what the linker does in the linking process.