The term “zero copy” has different meanings in some contexts. In this article, zero copy is what we often say, through this technology to free the CPU not to perform the function of data copy in memory, or to avoid unnecessary copies, so that zero copy is not no data copy (copy), but in a broad sense to reduce and avoid unnecessary data copy, can be used to save CPU use and internal bandwidth, such as high-speed transfer of files through the network, the implementation of network proxy, etc. Zero-copy technology can greatly improve the performance of the program.
This article summarizes the various techniques of zero-copy, and the next article introduces the common zero-copy techniques in Golang.
Zero-copy technology
In fact, zero-copy has been used for a long time to improve the performance of the program, such as nginx, kafka, etc. And many articles also detail the problems to be solved by zero-copy, I am still here to summarize, if you already know the zero-copy technology, you may wish to review.
Let’s analyze a scenario where a file is read from the network. The server reads a file from disk and writes it to a socket to return it to the client. Let’s look at the data copy on the server side.
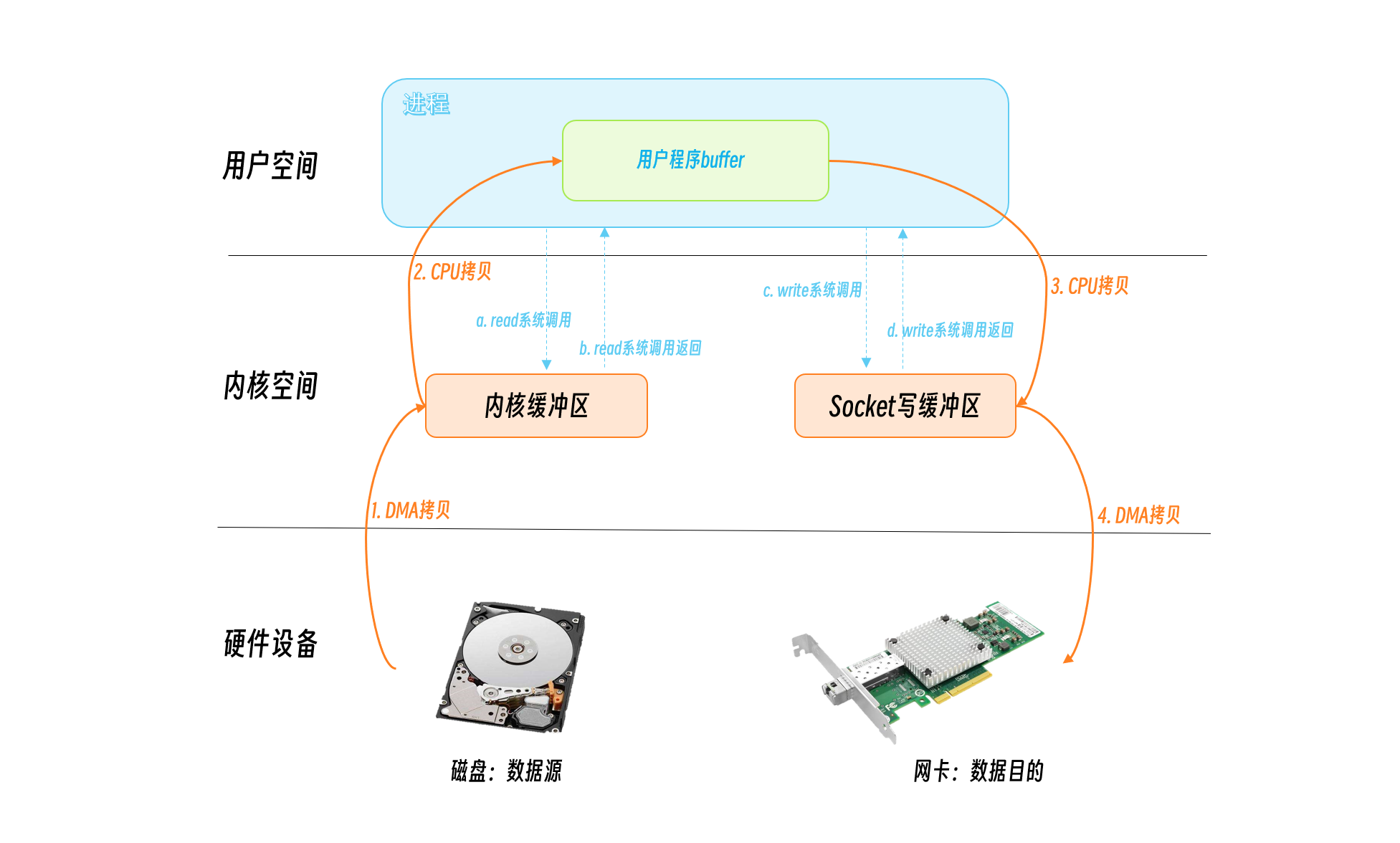
The program starts to use the system call read to tell the OS to read data from the disk file, it first switches from user state to kernel state, this switch is costly, the OS needs to save the state of user state, some register addresses, etc., after the read system call finishes and returns, the program needs to switch from kernel state to user state again to restore the saved state of user state, so one So one system call requires two user/kernel state switches. Similarly, when writing the contents of the file to the socket, the program calls the write system call and makes two more user/kernel state switches.
Looking at the data of the operation, this data was copied four more times. In the read system call, the data is copied from the disk to the kernel buffer by DMA, and then copied from the kernel buffer to the user’s program buffer by CPU copy, so two copies occur here. When writing to the socket, the data is first written from the user program buffer to the socket buffer, and then written from the socket buffer to the NIC via DMA. The data is also copied four times.
DMA (Direct Memory Access) is a memory access technique in computer science. It allows certain hardware subsystems (computer peripherals) within a computer to read and write directly to system memory independently, allowing hardware devices of different speeds to communicate without the need for a large interrupt load dependent on the central processor.
As you can see, the traditional IO read/write method includes four user/kernel context switches and four data copies, which has a significant impact on performance. The generalized zero-copy technology is to minimize the number of user/kernel context switches and data copies, for which the operating system provides several methods.
mmap + write
The mmap system call maps the virtual address in user space and the virtual address in kernel space to the same physical address to reduce the number of data copies between kernel space and kernel space.
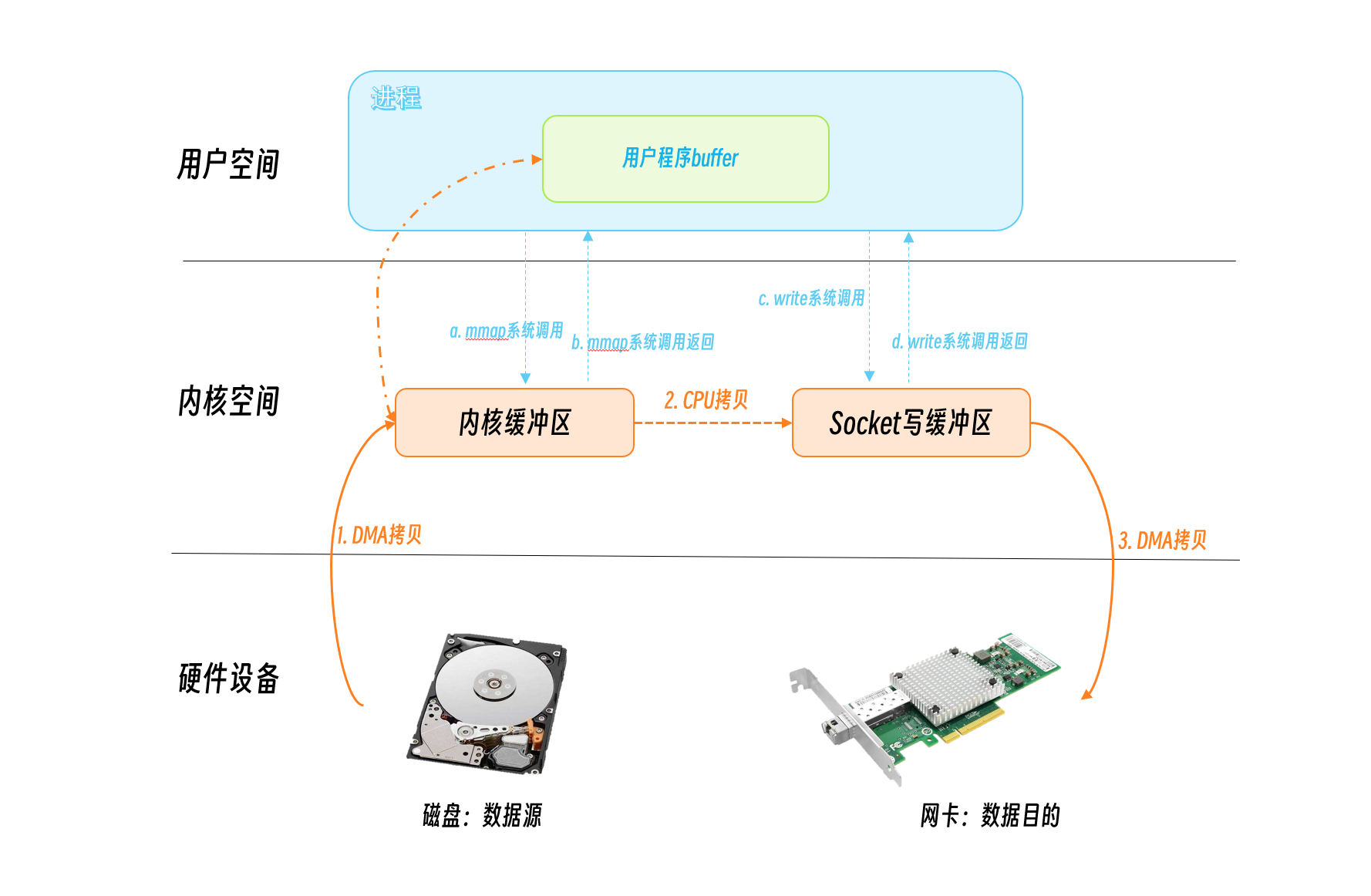
The IO read is initiated by the mmap system call, and the DMA writes the disk data to the kernel buffer, at which point the mmap system call returns. The program calls the write system call, the CPU writes the data from the kernel buffer to the socket buffer, and the DMA in turn writes the data from the socket buffer to the NIC.
As you can see, the mmap+write method has two system calls, four user/kernel state switches occur, and three data copies.
Compared with the traditional IO method, there is one less data copy, but there should be room for optimization.
sendfile
sendfile is a system call function introduced after Linux 2.1 kernel version to optimize data transfer. It can pass data between file descriptors, which is very efficient because it is all passed between kernels.
Before Linux 2.6.33 the destination file descriptor must be a file, later versions have no restrictions and can be any file.
But the source file descriptor requirement must be a file descriptor that supports mmap operations, which is fine for ordinary files, but not for sockets. So sendfile is suitable for reading data from files to write socket scenarios, so the name sendfile is still very apt for sending files.
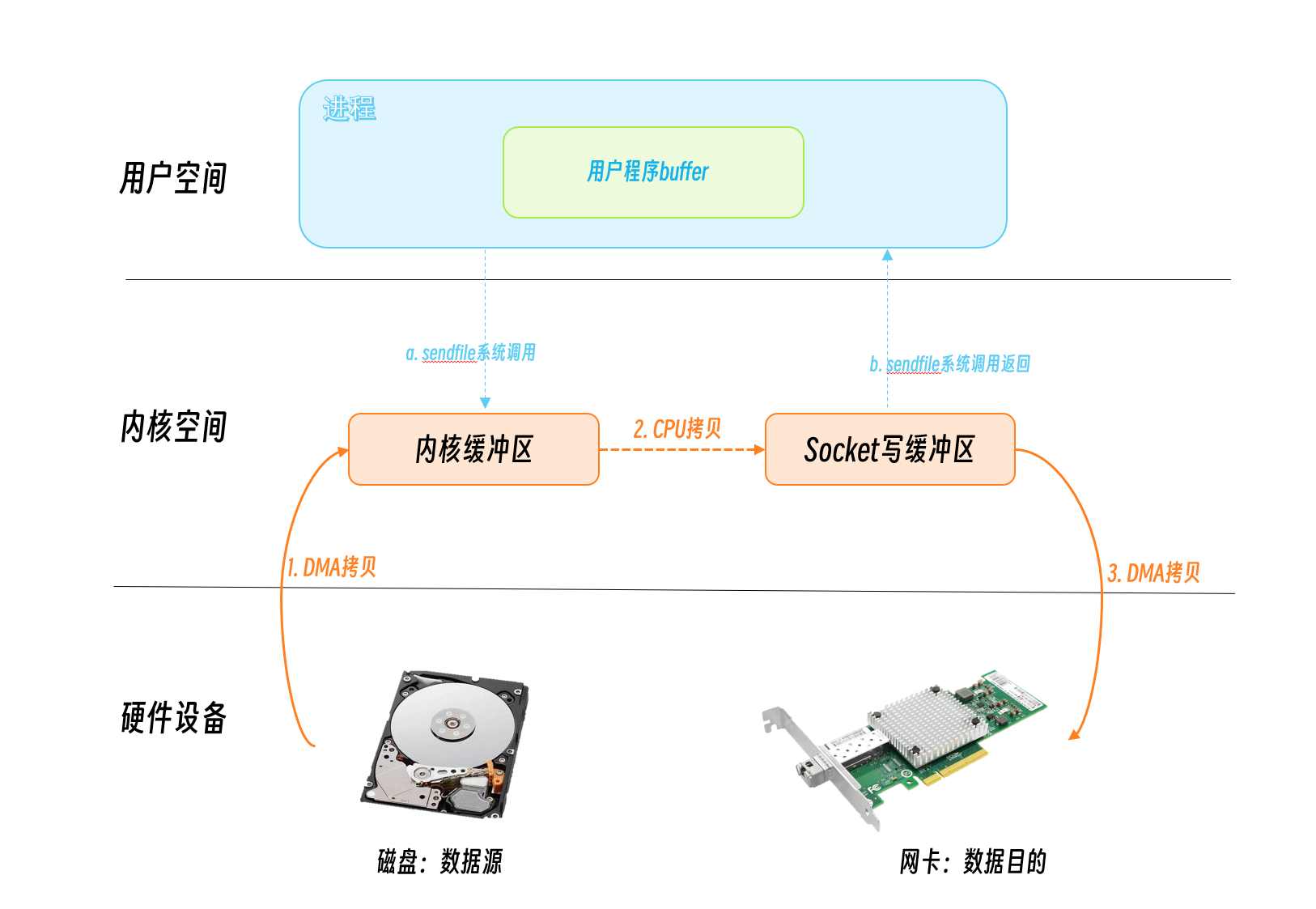
The user calls the sendfile system call, the data is copied to the kernel buffer via DMA, the CPU writes the data from the kernel buffer to the socket buffer again, the DMA writes the socket buffer data to the NIC, and then the sendfile system call returns.
As you can see, there is only one system call here, which means two user/kernel state switches and three data copies.
Relatively speaking, this approach has been a performance improvement.
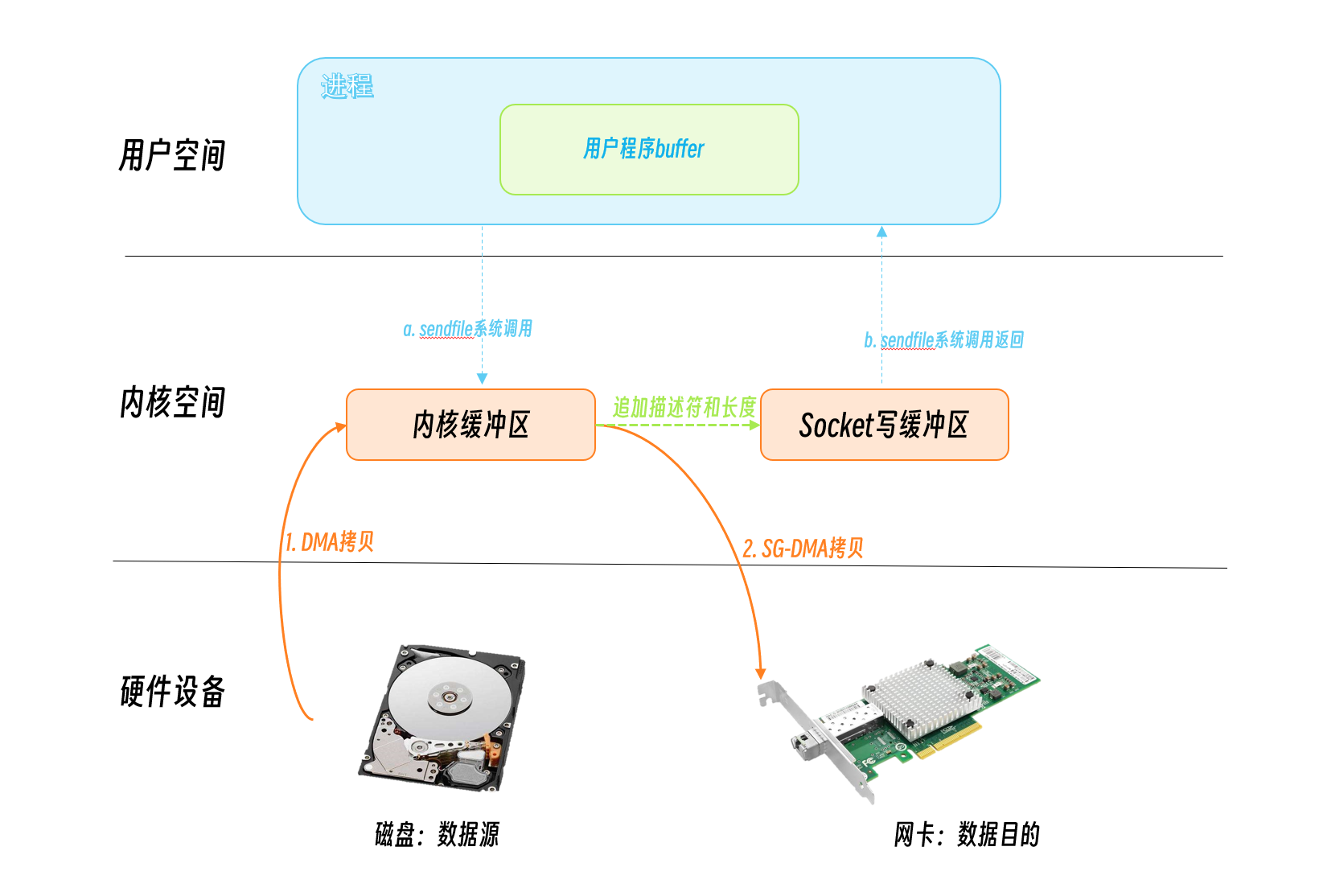
After linux 2.4, the sendfile was optimized again, and for NICs that support the dms scatter/gather feature, only the descriptors with information about the location and length of the data are appended to the socket buffer. the DMA engine transfers the data directly from the kernel buffer to the NIC (protocol engine), thus eliminating the need for a single CPU copy.
splice, tee, vmsplice
For example, if we want to make a socket proxy, the source and destination are both sockets, so we can’t use sendfile directly. This time we can consider splice.
Prior to Linux version 2.6.30, only one of the sources and destinations could be a pipe. Since 2.6.31, both the source and the destination can be pipes.
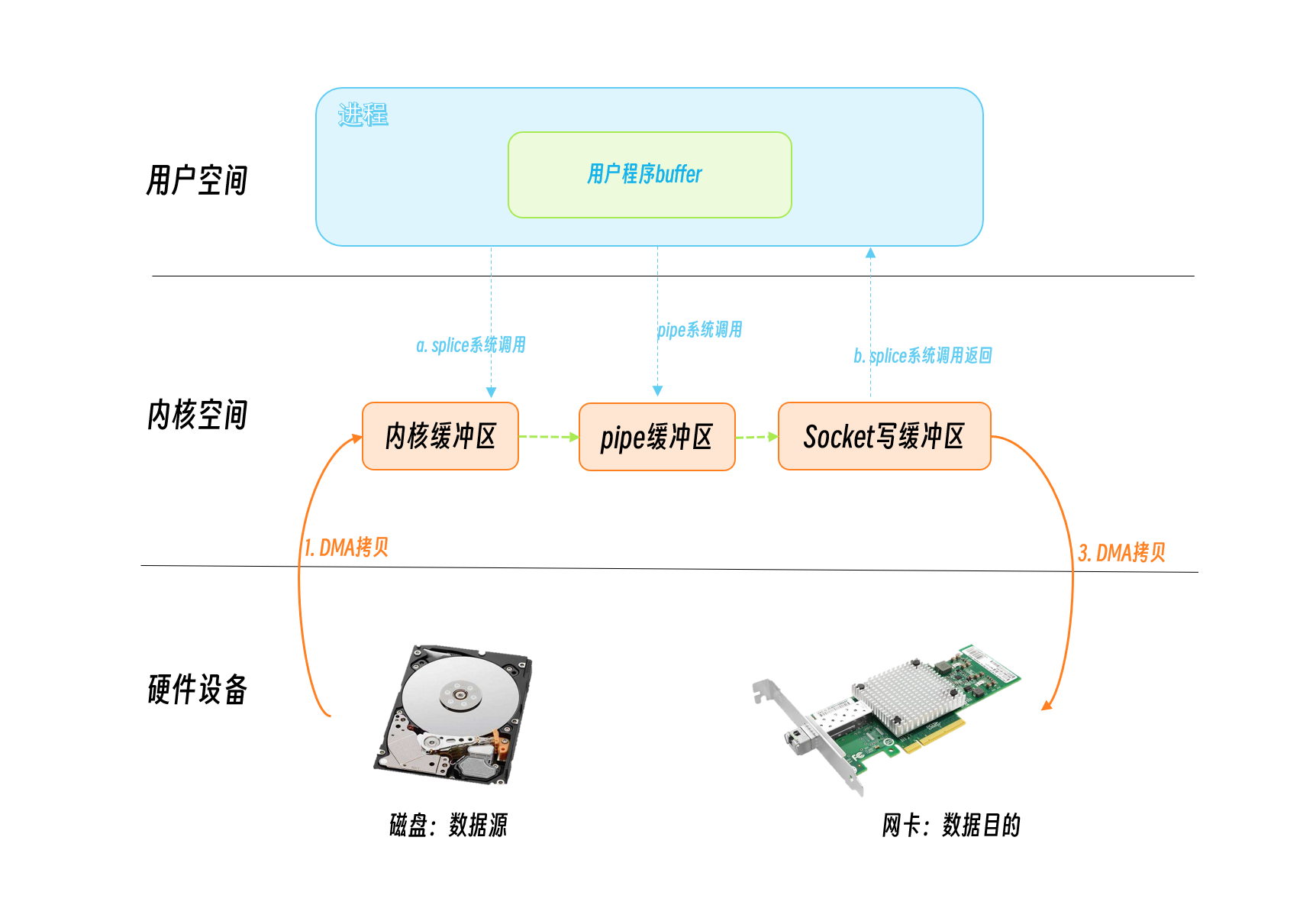
Of course, if we are dealing with a source and destination that is not a pipe, we can create a pipe first so that we can use the splice system call to achieve zero copies.
However, if you create a pipe each time, you will find one more system call each time, which means two user/kernel state switches, so you can create a pipeline pool if you copy data frequently.
The tee system call is used to copy data between the two pipes.
The vmsplice system call pipe points to a copy of data between the kernel buffer and the user program’s buffer.
MSG_ZERO_COPY
Linux v4.14 accepts a patched support for zero-copy (MSG_ZEROCOPY) in the TCP send system call, which allows user processes to send data from the user buffer through the kernel space to the network sockets via zero-copy. UDP is supported in 5.0, and Willem de Bruijn’s paper gives a 39% performance improvement for large packet sends using netperf, and a 5%-8% performance improvement for data sends in an online environment, which the official documentation states is usually only significant for sending large packets of about 10KB. This feature was initially only supported for TCP, and UDP was only supported after kernel v5.0. Here is also an official document: Zero-copy networking
First you need to set the socket options:
The send system call is then called by passing in the MSG_ZEROCOPY parameter.
|
|
Here we pass in buf, but when is buf reusable? The kernel notifies the program process of this. It puts the completion notification in the socket error queue, so you need to read this queue to know when the copy is finished and the buf is ready to be released or reused.
Because it may send data asynchronously, you need to check when the buf is released, increasing code complexity as well as causing multiple user and kernel state context switches.
The receive MSG_ZEROCOPY mechanism (Zero-copy TCP receive) is also supported in Linux 4.18.
copy_file_range
Linux 4.5 adds a new API: copy_file_range, which does the file copying in kernel state without switching user space, which will improve performance in some scenarios.
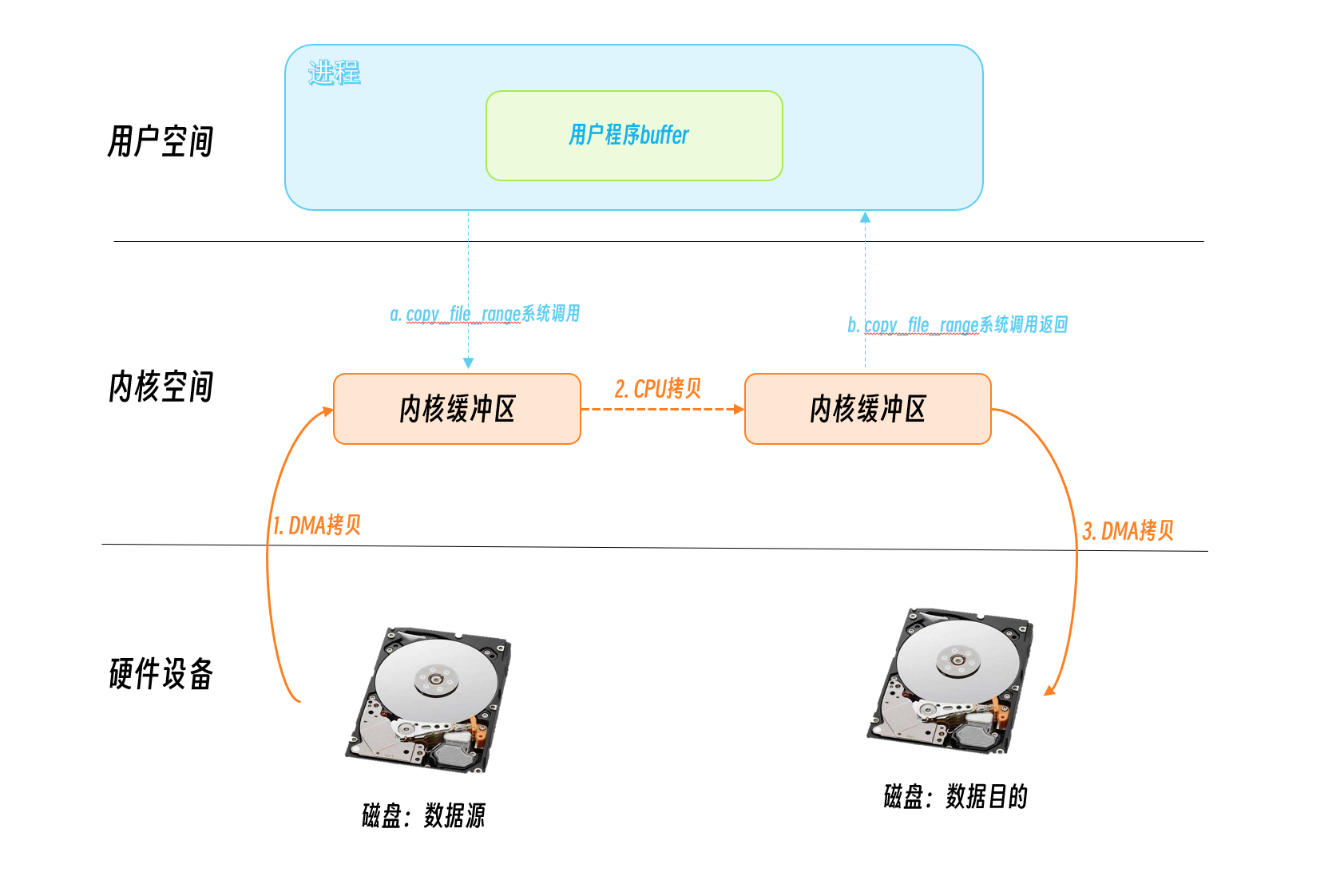
Other
AF_XDP, a new feature added to Linux 4.18 and formerly known as AF_PACKETv4 (never included in the mainline kernel), is a raw socket optimized for high-performance packet processing and allows zero-copy between the kernel and the application. Since the socket can be used for both receive and send, it only supports high performance network applications in user space.
Of course zero-copy technology and data copy optimization has been one of the ways to pursue performance optimization, and related technologies are under continuous research.