Preface
Storage is one of the core components of a computer. In a completely ideal state, memory should have the following three characteristics at the same time: first, fast enough: memory should be accessed faster than the CPU can execute an instruction so that the CPU’s efficiency is not limited by the memory; second, large enough: the capacity can store all the data the computer needs; third, cheap enough: it is inexpensive The memory should be cheap enough for all types of computers to be equipped.
But reality is often harsh, and our current computer technology cannot meet all three of these conditions at the same time, so modern computer storage design uses a hierarchical structure.
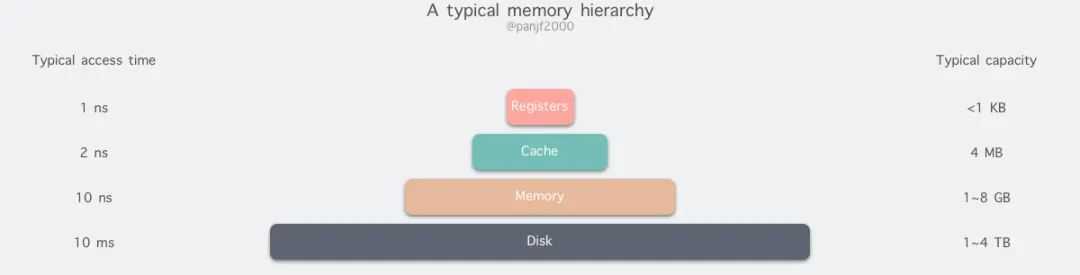
From top to bottom, the types of memory in a modern computer are:registers, cache, main memory and disk , which are decreasing in speed and increasing in capacity.
The fastest access speed is register , because the register is made of the same material as the CPU, so the speed is as fast as the CPU, the CPU access to the register is no time delay, however, because of the expensive, so the capacity is also extremely small, generally 32-bit CPU is equipped with a register capacity of 32 ✖️32Bit, 64-bit CPU is 64 ✖️64Bit, regardless of 32-bit or 64-bit, the register capacity is less than 1KB, and registers must also be managed by software itself.
The second layer is the cache, which we usually know as CPU cache L1, L2, and L3. Generally, L1 is exclusive to each CPU, L3 is shared by all CPUs, and L2 is designed to be either exclusive or shared depending on the architecture design. For example, Intel’s multicore chips use a shared L2 mode while AMD’s multicore chips use an exclusive L2 mode.
The third layer is the Main Memory, also known as the main memory, often called Random Access Memory (RAM). It is the internal memory that exchanges data directly with the CPU. It can be read and written to at any time (except when refreshed) and is very fast, and is often used as a temporary data storage medium for the operating system or other running programs.
As for disk, it is the furthest layer from the user in the diagram, and the read/write speed differs by hundreds of times from memory; on the other hand, there are naturally many optimizations for disk operations, such as zero-copy, direct I/O, asynchronous I/O, etc. The purpose of these optimizations is to improve system throughput. In addition there are also disk cache areas, PageCache, TLB, etc. in the OS kernel, which can effectively reduce the number of disk accesses.
In reality, the first bottleneck in the process of most systems going from small to large is I/O. Especially in the context of modern web applications moving from CPU-intensive to I/O-intensive, I/O is becoming more and more of a performance bottleneck for most applications.
The standard I/O interface of the traditional Linux operating system is based on data copy operations, i.e. I/O operations result in data being transferred between buffers in the operating system kernel address space and buffers defined in the user process address space. The biggest benefit of having buffers is that it reduces the number of disk I/O operations, and if the requested data is already stored in the operating system’s cache memory, then there is no need to perform the actual physical disk I/O operation; however, traditional Linux I/O is deeply CPU dependent for data copy operations during data transfer, meaning that the I/O process requires the CPU to perform data copy This results in significant system overhead and limits the ability of the operating system to perform data transfer operations efficiently.
This article explores the development, optimisation and practical application of zero-copy technology and Linux I/O using file transfer as a scenario.
Terms to know
DMA: DMA, full name Direct Memory Access, is designed to avoid the CPU from taking too much interrupt load during disk operations. In disk operation, the CPU can hand over the bus control to the DMA controller, and the DMA outputs read and write commands to directly control the RAM and I/O interface for DMA transfer, without the CPU directly controlling the transfer, and without the process of retaining the site and restoring the site as in the interrupt processing method, making the CPU much more efficient.
MMU: Memory Management Unit Main.
Competitive access protection management requirements: strict access protection is required to dynamically manage which memory pages/segments or zones are used by which applications. This is a competing access management requirement for resources.
Efficient translation conversion management requirements: the need to implement fast and efficient translation conversion of mappings, without which the system would operate inefficiently.
Efficient virtual and real memory swapping requirements: the need to be fast and efficient in the process of swapping memory pages/segments between actual virtual memory and physical memory.
Page Cache: To avoid the need to read and write to the hard disk each time a file is read or written, the Linux kernel uses the Page Cache mechanism to cache the data in a file.
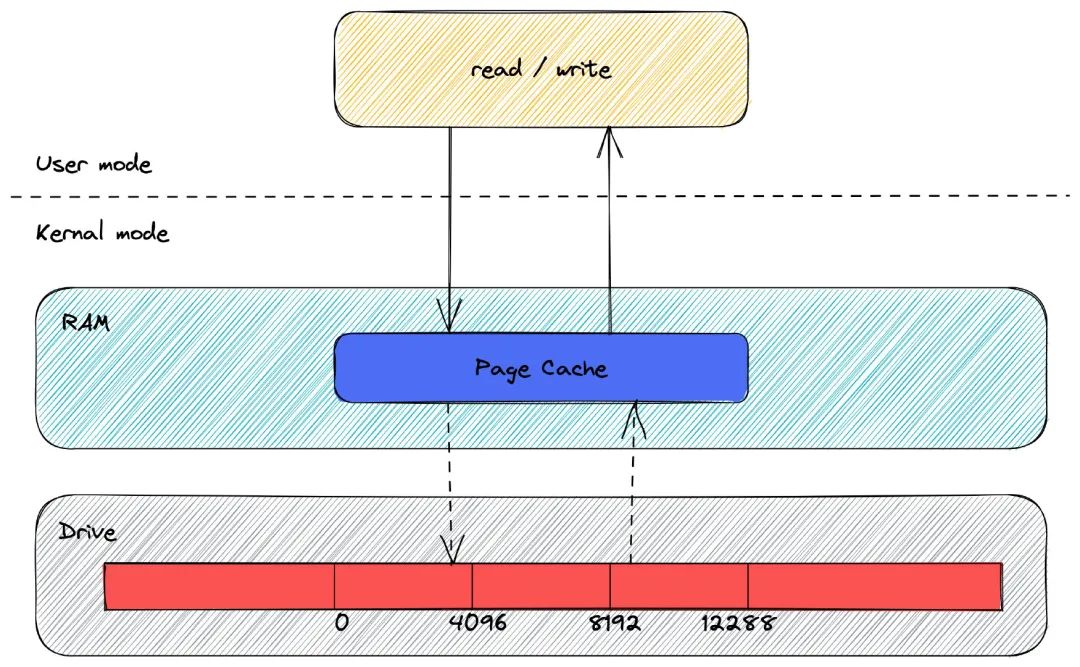
In addition, since reading data from a disk requires finding the location of the data, but for mechanical disks this is done by rotating the head to the sector where the data is located and then starting to read the data ‘sequentially’, the physical act of rotating the head is very time consuming and to reduce its impact PageCache uses a ‘pre-read function’ .
For example, suppose the read method will only read 32KB of bytes at a time, although read will only read 0-32KB of bytes at first, the kernel will read the next 32-64KB into the PageCache, so that the cost of reading the next 32-64KB is very low, and if a process reads the 32-64KB before it is eliminated from the PageCache, the gain is very large.
Virtual Memory: There is a philosophy in computing as sacred as the Ten Commandments of Moses: “Any problem in computer science can be solved by adding an indirect middle layer”, and this philosophy can be seen shining through in everything from memory management, network models, concurrent scheduling and even hardware architectures, and virtual memory is one of the perfect practices of this philosophy.
Virtual memory provides a consistent, private and contiguous complete memory space for each process; all modern operating systems use virtual memory, and the use of virtual addresses instead of physical addresses has the following main benefits.
The first point, which can be optimized using the first feature above, is that virtual addresses in kernel space and user space can be mapped to the same physical address so that they do not need to be copied back and forth during I/O operations.
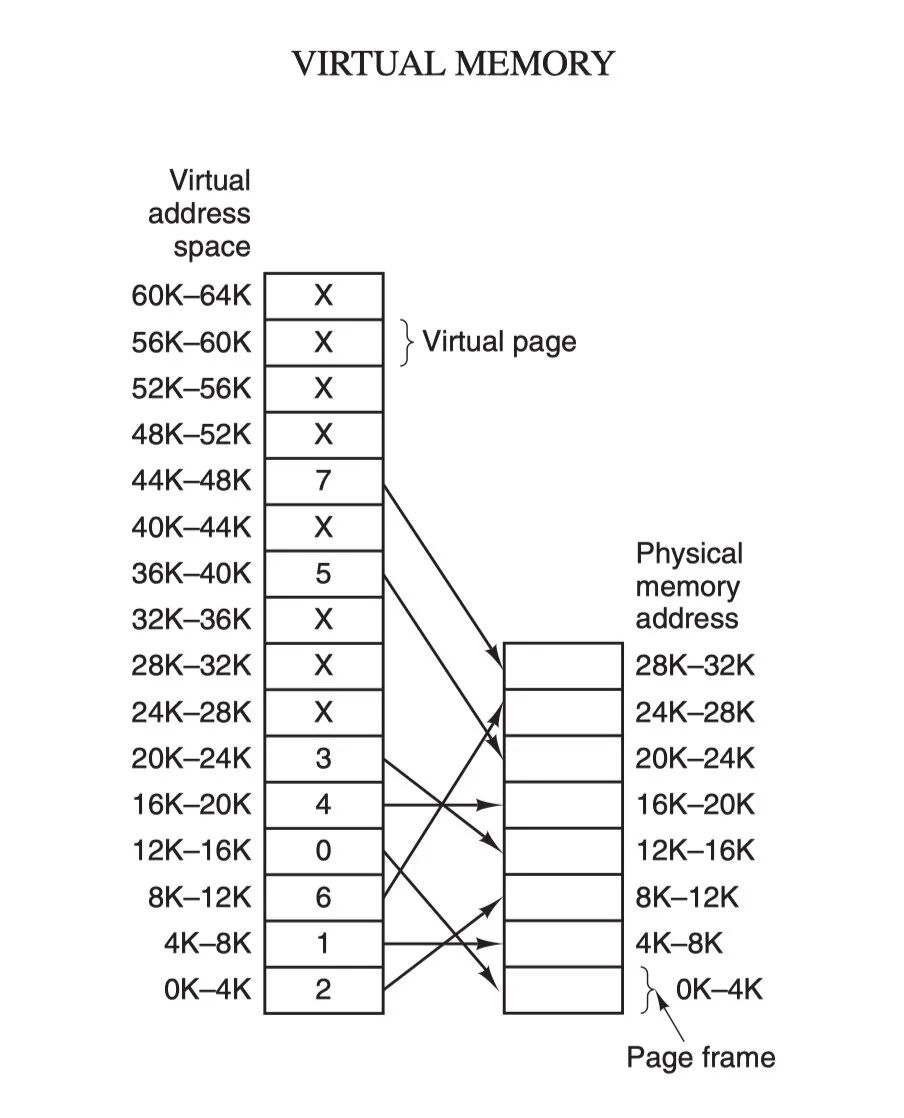
The second point is that multiple virtual memories can point to the same physical address; the third point is that the virtual memory space can be much larger than the physical memory space; and the fourth point is that contiguous memory spaces can be managed at the application level, reducing errors.
NFS File System: The Network File System is one of the file systems supported by FreeBSD, also known as NFS; NFS allows a system to share directories and files with others on a network, and by using NFS, users and programs can access files on a remote system as if they were local files.
Copy-on-write Copy-on-write (COW) is an optimisation strategy in the field of computer programming. The core idea is that if multiple callers request the same resource (e.g. memory or data storage on disk) at the same time, they will collectively get the same pointer to the same resource, and it is not until one caller tries to modify the content of the resource that the system actually copies a private copy to that caller, while the original resource seen by the other callers remains unchanged. This process is transparent to all other callers. The main advantage of this approach is that if the caller does not modify the resource, no private copy is created, so that multiple callers can share the same resource for read-only operations.
Why do we need DMA
Before there was DMA technology, the I/O process went like this: firstly, the CPU issued the corresponding command to the disk controller and returned it; secondly, the disk controller received the command and then started preparing the data, which would be put into the disk controller’s internal buffer and then an interrupt would be generated. Finally, the CPU receives the interrupt signal, stops the task at hand, then reads the data from the disk controller’s buffer into its own registers one byte at a time, and then writes the data from the registers to memory, while the CPU is blocked during the data transfer and cannot perform other tasks.
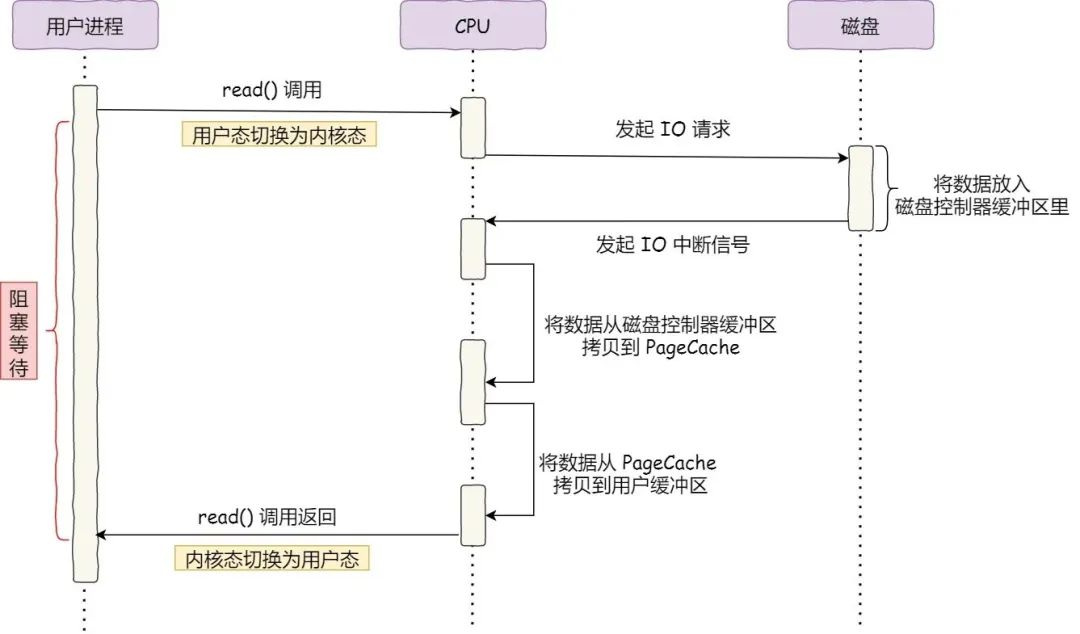
The entire data transfer process requires the CPU to be involved in copying the data itself, and the CPU is blocked at this point; a simple transfer of a few characters is fine, but if we use a gigabit NIC or a hard disk to transfer a large amount of data, the CPU will be too busy to do so.
When computer scientists realized the seriousness of the situation, they invented DMA technology, also known as Direct Memory Access (DMA) technology. Simply understood, when transferring data between I/O devices and memory, the data handling is all handed over to the DMA controller, and the CPU is no longer involved in anything related to data handling so that the CPU can attend to other matters .
The process is shown below.
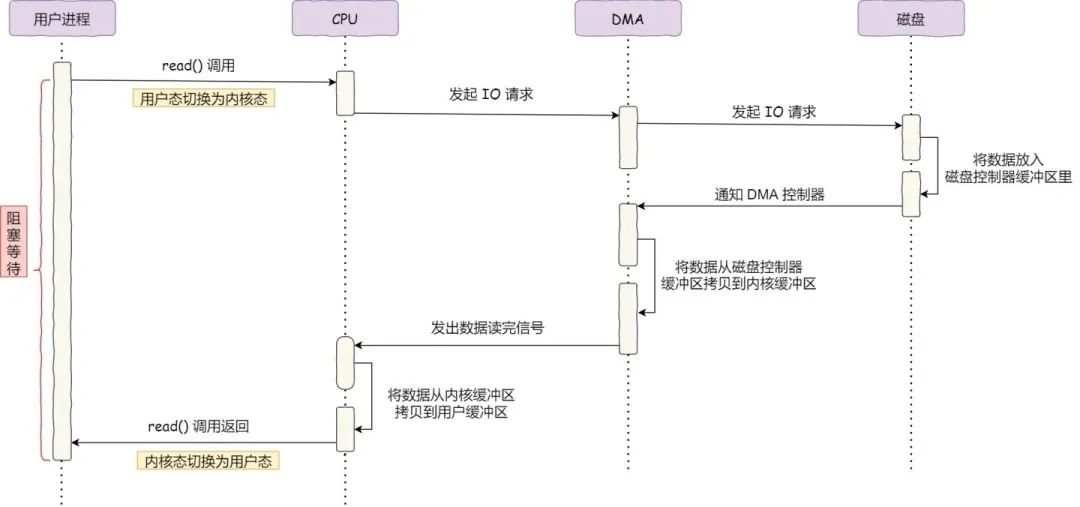
First, the user process calls the read method and sends an I/O request to the operating system, requesting to read data into its own memory buffer, and the process enters a blocking state; second, the operating system receives the request and further sends the I/O request to the DMA, releasing the CPU; again, the DMA further sends the I/O request to the disk; next, the disk receives the I/O request from the DMA and reads the data from the disk to the buffer of the disk controller; when the buffer of the disk controller is read full, it sends an interrupt signal to the DMA to inform itself that the buffer is full; finally, the DMA receives the signal from the disk and copies the data in the buffer of the disk controller to the kernel buffer, which does not occupy the CPU at this time, and the CPU can still execute other transactions; in addition, when the DMA has read enough data it sends an interrupt signal to the CPU; in addition to this, the CPU receives the interrupt signal, copies the data from the kernel to user space and the system call returns.
With DMA, the whole process of data transfer, the CPU is no longer involved in the data handling work of interacting with the disk, but the whole process is done by DMA, but the CPU is also essential in this process, because the CPU is needed to tell the DMA controller what data to transfer and from where to where.
In the early days DMA only existed on the motherboard, nowadays each I/O device has its own DMA controller inside due to the increasing number of I/O devices and the different data transfer requirements.
The flaws of traditional file transfers
With DMA, is our disk I/O a done deal? Not really; take the more familiar example of downloading files. The more intuitive way for the server to provide this functionality is to read the files from the disk into memory and then send them to the client via the network protocol.
The specific way I/O works is that data reads and writes are copied back and forth from user space to kernel space, while data in kernel space is read from or written to disk via the I/O interface at the operating system level.
The code is usually as follows and will typically require two system calls.
The code is simple, it’s just two lines of code, but there’s quite a lot going on here.
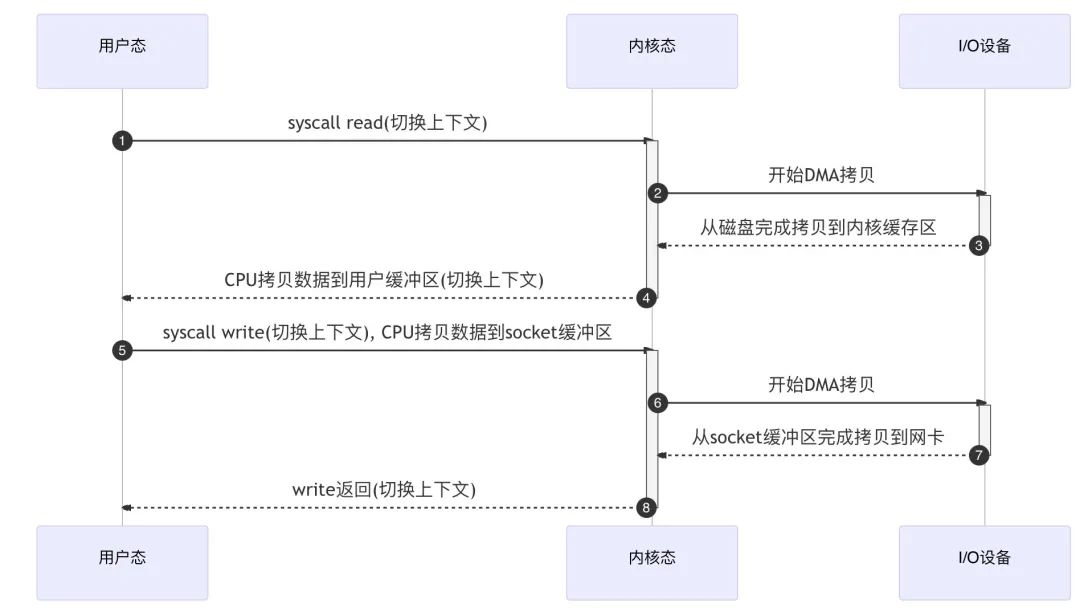
This includes: 4 context switches between user and kernel state twice in the system calls read() and write(), where each system call has to switch from user state to kernel state first, and then switch back from kernel state to user state after the kernel has completed its task; the cost of context switches is not small, taking several tens of nanoseconds to a few microseconds per switch, and can easily become a performance bottleneck in high concurrency scenarios. (See the cost difference between thread switching and coroutine switching)
Two of the four data copies are made by the DMA and the other two are made by the CPU; we are only moving one copy of data, but we end up moving it four times. Too many data copies will undoubtedly consume extra resources and greatly reduce system performance.
So, to improve the performance of file transfers, you need to reduce the number of context switches and memory copies between user and kernel states.
How to optimise traditional file transfers - reduce “context switching between user state and kernel state”: When reading disk data, context switching occurs because the user space does not have permission to operate the disk or the NIC, the kernel has the highest permission, and these processes of operating the device need to be left to the operating system kernel, so To perform certain tasks via the kernel, you need to use the system call functions provided by the operating system.
A system call necessarily involves two context switches: first from the user state to the kernel state, then back to the user state when the kernel has finished executing its task, and then to the process code.
Reducing the number of ‘data copies’: as mentioned earlier, traditional file transfer methods involve four data copies; however, it is clear that the ‘copy from the kernel’s read buffer to the user’s buffer and from the user’s buffer to the socket’s buffer’ steps are unnecessary.
Because in a download file, or in a broad file transfer scenario, we don’t need to reprocess the data in user space, the data doesn’t need to go back into user space.
Zero-copy
Then Zero-copy technology was created to address the scenario we mentioned above - moving data directly from the file system to the network interface across the process of interacting with the user state.
Zero-copy implementation principles
There are usually 3 ways to implement zero-copy technology: mmap + write, sendfile, and splice.
mmap + write
We know from earlier that the read() system call copies data from the kernel buffer to the user buffer, so to save this step we can replace the read() system call function with mmap(), with the following pseudo code.
The function prototype for mmap is as follows.
|
|
The mmap() system call function creates a new map in the virtual address space of the calling process, “mapping” the data in the kernel buffer directly to user space, so that there is no need for any data copying between the operating system kernel and user space.
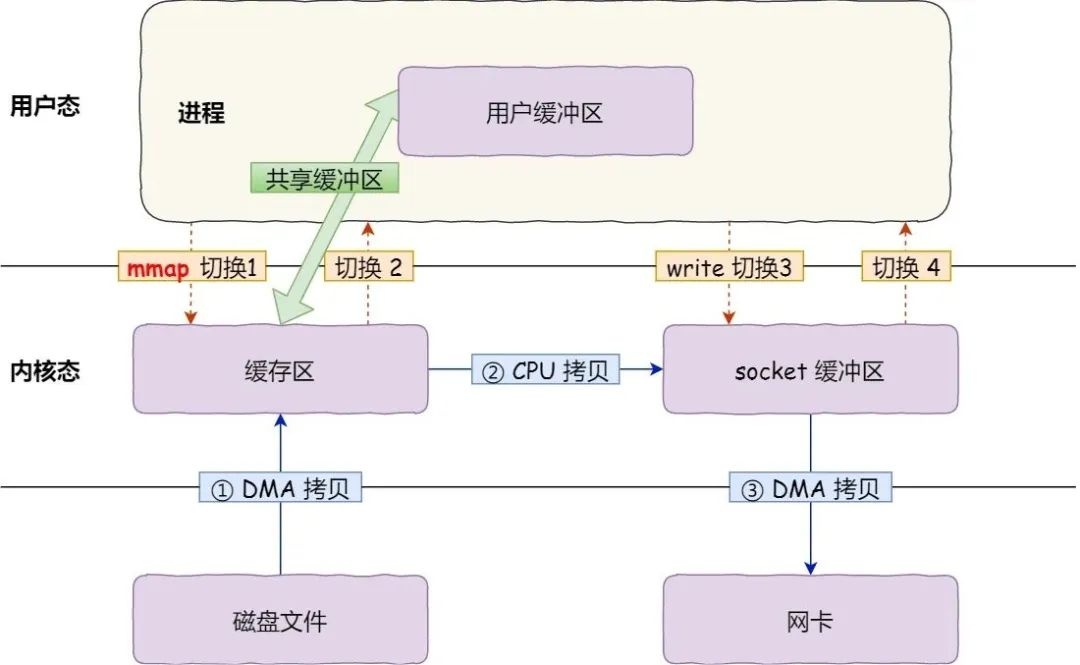
The specific process is as follows: firstly, after the application process calls mmap(), the DMA copies the data from the disk to the kernel buffer, and the application process “shares” this buffer with the OS kernel; secondly, the application process then calls write(), and the OS directly copies the data from the kernel buffer to the socket buffer, all this happens in the kernel state, and the CPU carries the data; finally, the data from the kernel socket buffer is copied to the NIC buffer, and this process is carried by the DMA.
We can see that by using mmap() instead of read(), we can reduce the data copy process by one. However, this is not the optimal Zero-Copy, as it still requires a copy of the data from the kernel buffer to the socket buffer via the CPU, and still requires 4 context switches, as the system call is still 2.
sendfile
In Linux kernel version 2.1, a system call function sendfile() is provided specifically to send files as follows.
Its first two parameters are the file descriptors of the destination and source respectively, the next two parameters are the offset of the source and the length of the copied data, and the return value is the length of the actual copied data.
Firstly, it replaces the previous read() and write() system calls, thus reducing one system call and the overhead of 2 context switches. Secondly, the system call copies the data from the kernel buffer directly to the socket buffer and not to the user state, so there are only 2 context switches and 3 data copies. The following diagram shows this.
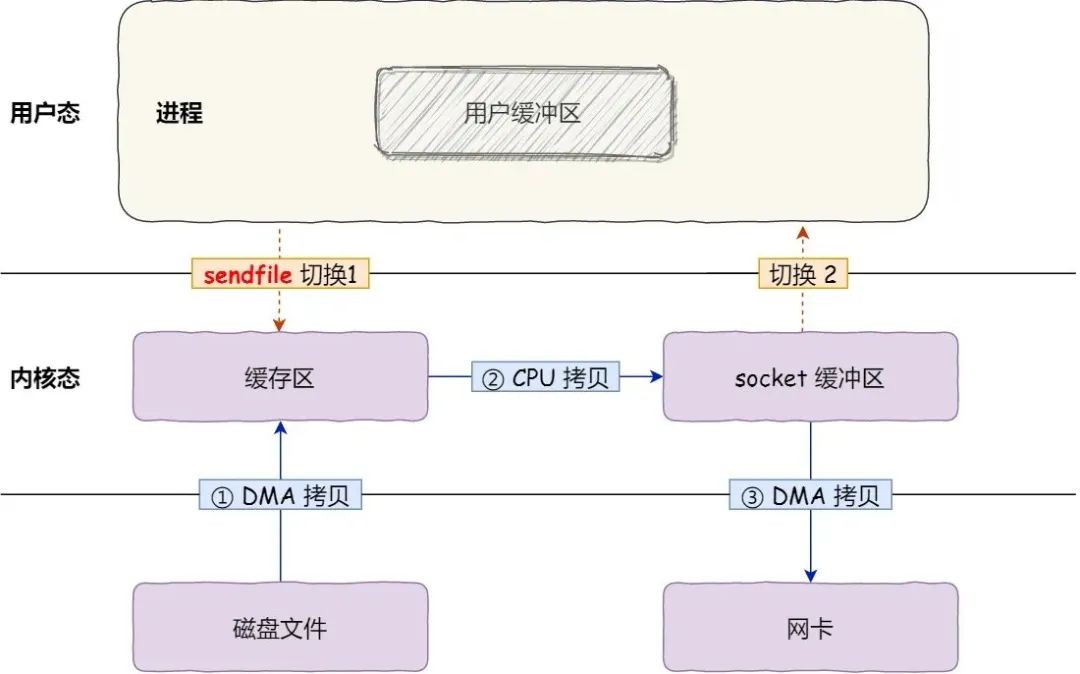
The sendfile method with scatter/gather: The Linux 2.4 kernel has been optimised to provide a sendfile operation with scatter/gather, an operation that removes the last CPU COPY. The principle is that instead of making a copy of the data in the kernel space Read BUffer and Socket Buffer, the memory address and offset of the Read Buffer are recorded in the corresponding Socket Buffer, so that no copy is needed. The essence of this is the same idea as the virtual memory solution, which is the recording of memory addresses.
You can check if your NIC supports the scatter-gather feature on your Linux system by using this command.
So, starting with version 2.4 of the Linux kernel, the process of the sendfile() system call has changed a bit for NICs that support SG-DMA technology, as follows.
In the first step, the data from the disk is copied to the kernel buffer via DMA; in the second step, the buffer descriptor and data length are passed to the socket buffer. This allows the NIC’s SG-DMA controller to copy the data from the kernel cache directly into the NIC’s buffer, eliminating the need to copy data from the OS kernel buffer to the socket buffer, thus reducing one data copy. Therefore, only two data copies are made in this process, as shown in the figure below.
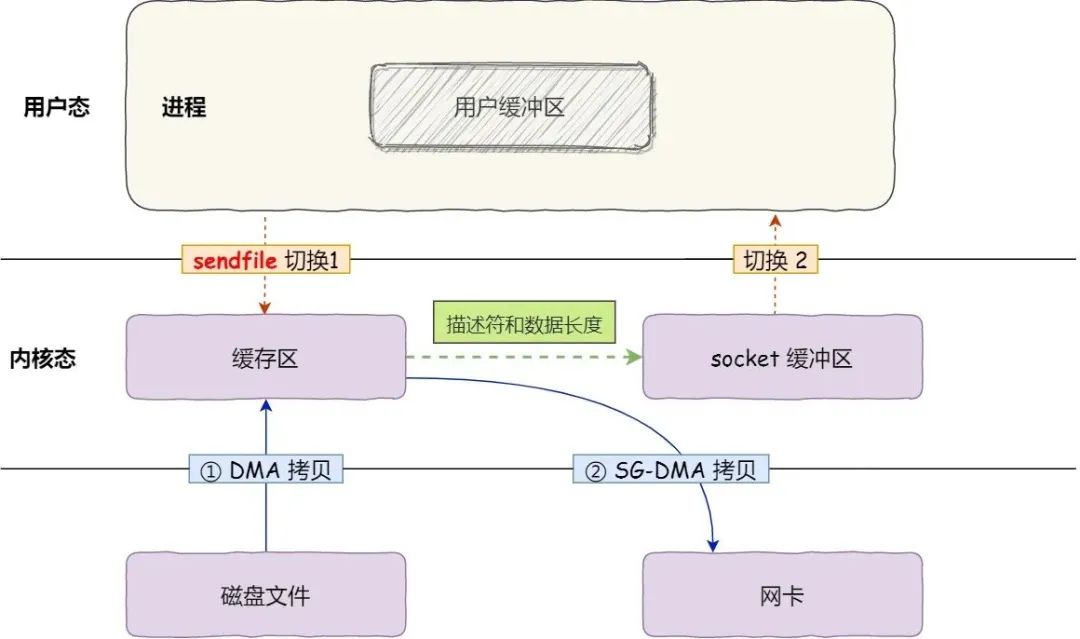
splice
The splice call is very similar to sendfile in that the user application must have two file descriptors already open, one for the input device and one for the output device. Unlike sendfile, splice allows any two files to be connected to each other, not just files and sockets for data transfer. For the special case of sending data from a file descriptor to a socket, the sendfile system call has always been used, whereas splice has always been just a mechanism that is not limited to the function of sendfile. That is, sendfile is a subset of splice.
splice() is based on Linux’s pipe buffer mechanism, so one of the two incoming file descriptors for splice() must be a pipe device.
The process of completing a read/write from a disk file to a NIC using splice() is as follows.
First, the user process calls pipe(), which plunges from the user state into the kernel state; an anonymous one-way pipe is created, pipe() returns, and the context switches from the kernel state back to the user state; second, the user process calls splice(), which plunges from the user state into the kernel state; again, the DMA controller copies the data from the hard disk to the kernel buffer, “copies” it into the pipe from the write side of the pipe, and splice() returns and the context returns from the kernel state to the user state; from there, the user process calls splice() again and falls from the user state to the kernel state; finally, the kernel copies the data from the read side of the pipe to the socket buffer and the DMA controller copies the data from the socket buffer to the NIC; in addition, splice() returns and the context switches from the kernel state to the user state. back to the user state.
The process of completing a read/write from a disk file to a NIC using splice() is as follows.
First, the user process calls pipe(), which plunges from the user state into the kernel state; an anonymous one-way pipe is created, pipe() returns, and the context switches from the kernel state back to the user state; second, the user process calls splice(), which plunges from the user state into the kernel state; again, the DMA controller copies the data from the hard disk to the kernel buffer, “copies” it into the pipe from the write side of the pipe, and splice() returns and the context returns from the kernel state to the user state; then, the user process calls splice() again and falls from the user state to the kernel state; finally, the kernel copies the data from the read side of the pipe to the socket buffer and the DMA controller copies the data from the socket buffer to the NIC; in addition, splice() returns and the context switches from the kernel state to the user state.
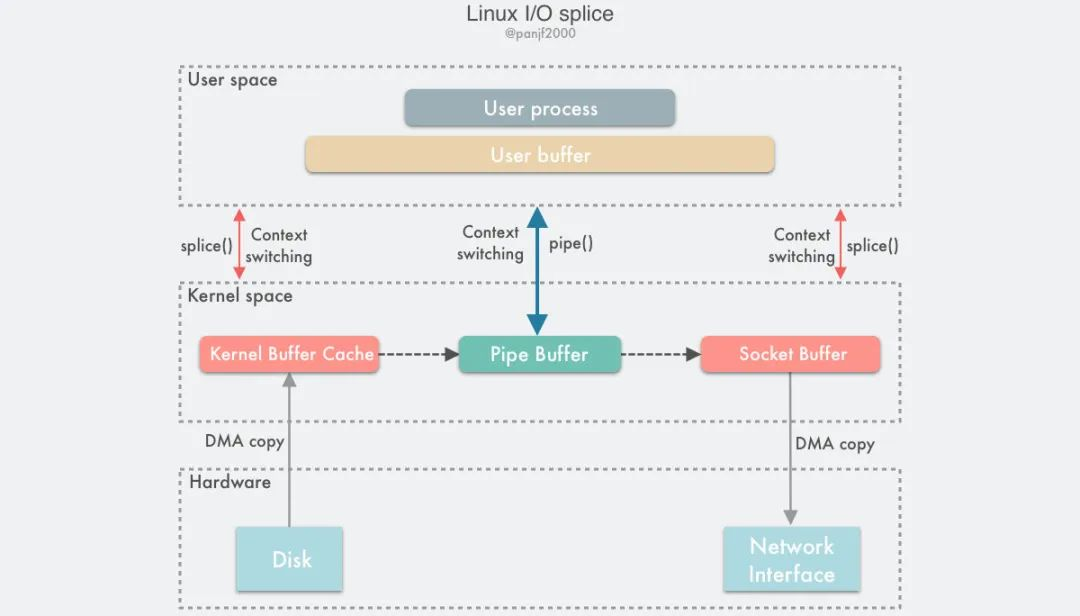
In Linux 2.6.17 the splice mechanism was introduced and in Linux 2.6.23 the implementation of the sendfile mechanism is no longer available, but the API and the corresponding functions are still there, except that the API and the corresponding functions are implemented using the splice mechanism. Unlike sendfile, splice does not require hardware support.
Practical application of zero-copy
Kafka
In fact, Kafka, the open source project, makes use of the ‘zero-copy’ technique, which results in a significant increase in I/O throughput, which is one of the reasons why Kafka is so fast at handling large amounts of data. If you trace back the Kafka file transfer code, you’ll see that it ultimately calls the transferTo method in the Java NIO library.
If the Linux system supports the sendfile() system call, then transferTo() will actually end up using the sendfile() system call function.
Nginx
Nginx also supports zero-copy technology, which is generally turned on by default to help improve the efficiency of file transfers. The configuration of whether to turn on zero-copy technology is as follows.
File transfer scenarios
Is Zero-Copy still the best option?
In large file transfer scenarios, zero-copy technology is not optimal; because in any implementation of zero-copy, there is a step of “DMA copies data from disk to kernel cache - Page Cache”, but when transferring large files (GB level files), the PageCache will not work, and then the extra data copy made by the DMA will be wasted, resulting in performance degradation, even if zero-copy with PageCache is used.
This is because in a large file transfer scenario, whenever the user accesses these large files, the kernel will load them into the PageCache, and the PageCache space is quickly filled up by these large files; and because the files are so large, there may be certain parts of the file data that have a lower probability of being accessed again, which brings about two problems: the PageCache is occupied by large As the PageCache is occupied by large files for a long time, other “hot” small files may not be able to fully use the PageCache, so the performance of the disk read and write will be reduced; the large file data in the PageCache, because they do not enjoy the benefits of caching, but consume the DMA to copy to the PageCache once more.
Asynchronous I/O + Direct I/O
So what option should we choose for large file transfer scenarios? Let’s start by reviewing the synchronous I/O that we first mentioned at the beginning of this article when we introduced DMA.
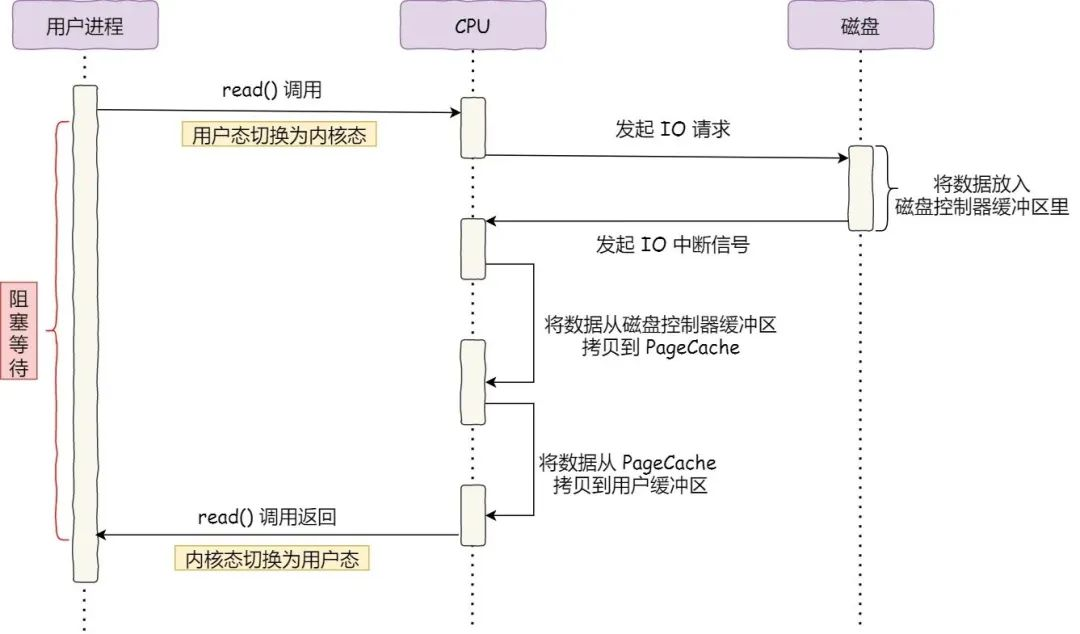
The synchronization here is reflected in the fact that when a process calls the read method to read a file, the process actually blocks on the read method call because it has to wait for the return of the disk data, and we certainly don’t want the process to be blocked while reading a large file, for which the blocking problem can be solved with asynchronous I/O, i.e.
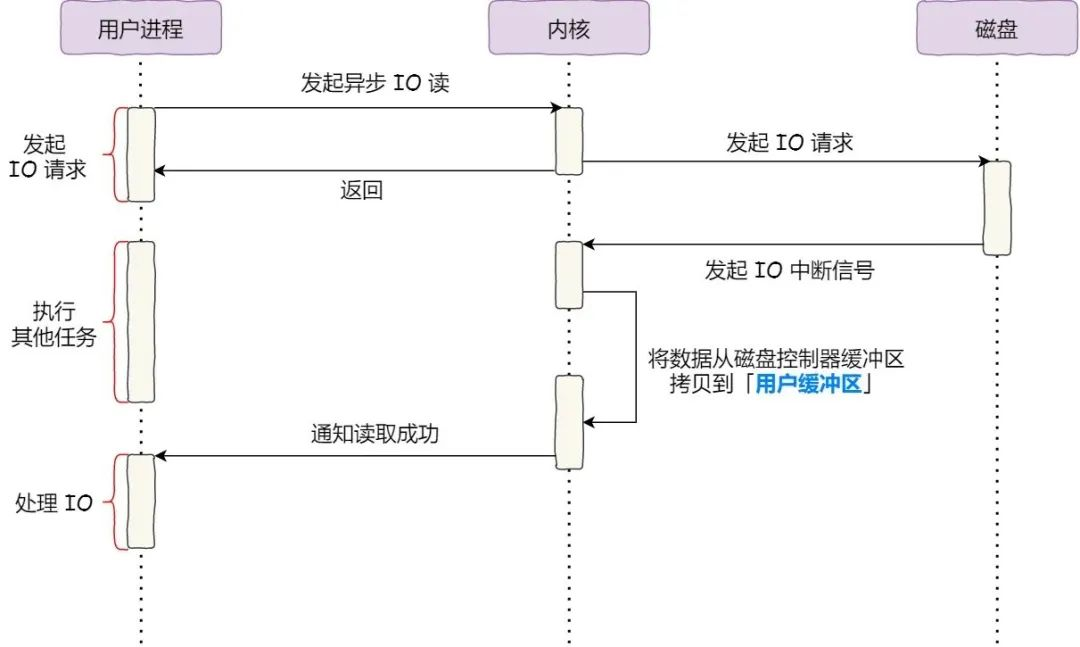
It divides the read operation into two parts: in the first half, the kernel initiates a read request to the disk, but can return without waiting for the data to be in place, so the process can then work on other tasks; in the second half, once the kernel has copied the data from the disk to the process buffer, the process will receive a notification from the kernel to work on the data.
Furthermore, we can see that asynchronous I/O does not involve PageCache; using asynchronous I/O would mean bypassing PageCache because the process of filling PageCache must block in the kernel. So direct I/O (as opposed to buffer I/O using PageCache) is used in asynchronous I/O so as not to block the process and to return immediately.
Two common types of direct I/O application scenarios.
The first, where the application has already implemented caching of disk data, then PageCache can be cached again without PageCache to reduce additional performance loss. In MySQL databases, direct I/O can be turned on through parameter settings, but by default it is not turned on; the second is when transferring large files, as it is difficult for large files to hit the PageCache cache and will fill up the PageCache causing “hot” files to not take full advantage of the cache, thus increasing the performance overhead, so direct I/O should be used in this case.
Of course, since direct I/O bypasses the PageCache, it does not benefit from the kernel’s optimisation of these two points: the kernel’s I/O scheduling algorithm caches as many I/O requests as possible in the PageCache and finally ‘merges’ them into one larger I/O request before sending it to disk, in order to reduce disk addressing operations; the kernel also ‘pre-reads’ subsequent I/O requests in the PageCache, again to reduce the number of operations on disk.
A similar configuration is used in practice. In nginx, we can use the following configuration to transfer files in different ways depending on their size.
Use “Asynchronous I/O + Direct I/O” when the file size is larger than the directio value, otherwise use “Zero-Copy Technique”.
What to look for when using direct I/O
First, post a comment from Linus (Linus Torvalds) on O_DIRECT:
“The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid, and was probably designed by a deranged monkey on some serious mind-controlling substances.” —Linus
Generally speaking anything that can draw Linus to open a can of worms, that is bound to have a lot of pitfalls. In the Linux man page we can see a Note under O_DIRECT, which I won’t post here.
A summary of the points to note is as follows.
The first point, address alignment limits. o_DIRECT imposes mandatory address alignment limits, the size of this alignment is also related to the file system/storage media, and there is currently no interface that does not rely on the file system itself to provide information on whether or not a specified file/file system has these limits.
Before Linux 2.6, the total transfer size, the user’s alignment buffer start address, and the file offset must all be multiples of the logical file system’s data block size. The data block (block) spoken of here is a logical concept that comes from the file system bundling a certain number of contiguous sectors, and is therefore often referred to as the “logical file system block “, which can be obtained by the following command.
|
|
Linux 2.6 onwards the alignment base becomes the physical storage media’s sector size, which corresponds to the minimum storage granularity of the physical storage media and can be obtained by the following command.
|
|
The reason for this limitation is also simple: the small matter of memory alignment is usually handled by the kernel, and since O_DIRECT bypasses the kernel space, everything that the kernel handles needs to be handled by the user.
The second point is that O_DIRECT is platform incompatible. This should be a point that most cross-platform applications need to be aware of. O_DIRECT itself is something that is only available in Linux and needs to be considered at the language level/application level to ensure compatibility here, for example under Windows there is actually a similar mechanism FILE_FLAG_NO_BUFFERIN used in a similar way. Another example is F_NOCACHE under macOS which, although similar to O_DIRECT, has a gap in actual usage.
Thirdly, do not run fork and O_DIRECT I/O concurrently; if the memory buffer used in O_DIRECT I/O is a private map (virtual memory), such as any virtual memory that uses the mmap mentioned above and is declared with the MAP_PRIVATE flag, then the associated O_DIRECT I/O (whether it is asynchronous I/O / I/O in other sub-threads) must be executed before the fork system call is called; otherwise data pollution or undefined behaviour will result.
This restriction does not exist if the relevant memory buffer is allocated using shmat or declared with the MAP_SHARED flag using mmap, or if the relevant memory buffer is declared with MADV_DONTFORK using madvise (note that in this case the memory buffer is not available in the child process).
The fourth point is to avoid mixing O_DIRECT and normal I/O for the same file; at the application level we need to avoid mixing O_DIRECT and normal I/O for the same file (especially for the same offset interval); even if our file system can handle and ensure consistency here, the overall I/O throughput will be lower than if we use one of the I/O methods alone. Similarly, the application layer should avoid using a mix of direct I/O and mmap for the same file.
The fifth point is O_DIRECT under the NFS protocol. although the NFS file system is designed to allow users to access network files as if they were local files, O_DIRECT does not behave like a local file system and older kernels or modified kernels may not support this combination.
This is because passing flag parameters to the server is not supported in the NFS protocol, so O_DIRECT I/O actually only bypasses the local client’s Page Cache, but the server/sync client will still cache these I/Os.
Some servers perform poorly when the client requests I/O synchronisation from the server to guarantee the synchronisation semantics of O_DIRECT (especially when these I/Os are small). Other servers are simply set to spoof the client by returning “data has been written to the storage media” directly to the client, which avoids the performance loss of I/O synchronisation to some extent, but does not guarantee data integrity for data that has not completed I/O synchronisation when the server is powered down. the NFS client for Linux also does not have the address alignment restrictions mentioned above.
Using direct I/O in Golang
Direct io must satisfy three alignment rules: io offset sector alignment, length sector alignment, and memory buffer address sector alignment; the first two are relatively easy to satisfy, but allocated memory addresses cannot be achieved directly by native means alone.
First, let’s compare it to c. The libc library calls posix_memalign to allocate a block of memory that meets the requirements directly, but how do you do it in Golang? In Golang, the buffer of io is actually an array of bytes, which is naturally allocated using make, as follows.
|
|
However, the first address of the data byte array in the buffer is not necessarily aligned. The way to do this is simply to allocate a larger block of memory than expected and then find the alignment in that block; this is a common method in any language and is also available in Go.
For example, if I need a 4096 size block of memory and require the address to be aligned to 512, I can do this: first allocate a 4096+512 size block of memory, assuming that the first address of the resulting block is p1; then look in the address range [p1, p1+512] and I am sure to find the 512 aligned address p2; return p2 and the user can use the [p2, p2+ 4096] range without going out of bounds. The above is the basic principle, which is implemented as follows.
|
|
Therefore, the memory allocated by the AlignedBlock function above must be 512 address aligned, the only drawback being that the extra overhead of alignment appears to be greater when allocating smaller blocks of memory.
Open source implementation: There is an open source Golang direct I/O implementation on Github: ncw/directio. It is also very simple to use, O_DIRECT mode to open files.
Read data.
Transfer optimization between kernel buffers and user buffers
So far, the zero-copy techniques we have discussed are based on reducing or even avoiding CPU data copies between user space and kernel space. Although there are some techniques that are very efficient, most of them have the problem of narrow applicability, such as sendfile() and splice(), which are very efficient, but are only applicable to those scenarios where the user process does not need to process further scenarios, such as static file servers or proxy servers that forward data directly.
The virtual memory mechanisms and mmap mentioned earlier show that virtual copying and sharing of memory between the user process and the kernel can be achieved by remapping pages on different virtual addresses; therefore, if data is to be processed within the user process (a more common scenario than forwarding data directly) and then sent out, the transfer of data between user and kernel space is inevitable. Since this is unavoidable, the only option is to optimise.
Two techniques for optimising the transfer of data between user and kernel space: dynamic remapping and Copy-on-Write, and Buffer Sharing.
Copy-on-Write
As mentioned earlier, memory mapping (mmap) is used to reduce the copying of data between user space and kernel space, and usually user processes read and write to the shared buffers synchronously and blocking, so that there is no thread safety problem. One way to improve efficiency is to read and write to shared buffers asynchronously, in which case protection mechanisms must be introduced to avoid data conflicts, and COW (Copy on Write) is one such technique.
COW is a technology based on virtual memory remapping and therefore requires hardware support from the MMU, which keeps track of which memory pages are currently marked as read-only and throws an exception to the operating system kernel when a process tries to write to those pages. The kernel handles the exception by allocating a copy of physical memory to the process, copying the data to this memory address, and retransmitting a write operation to the MMU to execute the process.
The following diagram shows one of the applications of COW in Linux: fork/clone, forked child processes share the physical space of the parent process, and when the parent and child processes have memory write operations, the read-only memory page is interrupted and a copy of the memory page triggered by the exception is made (the rest of the page is still shared with the parent process).

Limitations: The zero-copy technique of COW is more suitable for scenarios where more reads and fewer writes result in fewer COW events, while in other scenarios it may result in negative optimization because the system overhead from COW events is much higher than that from a single CPU copy.
In addition, during practical applications, the same memory buffer can be used repeatedly to avoid frequent memory mapping, so you don’t need to unmap the memory pages after using the shared buffer only once, but to recycle them repeatedly to improve performance.
However, this persistence of the memory page map does not reduce the system overhead due to page table movement/changing and TLB flush, because the read-only flag of the memory page is changed to write-only every time a COW event is received and the memory page is locked or unlocked.
Practical application of COW - Redis persistence mechanism: Redis, as a typical memory-based application, must have transfer optimization between kernel buffers and user buffers.
The Redis persistence mechanism uses the bgsave or bgrewriteaof command to fork a subprocess to save the data to disk. In general Redis has more read operations than write operations (in the right usage scenario), so using COW in this case reduces the blocking time of fork() operations.
Language level applications
The idea of copy-on-write is also used in many languages and can bring significant performance gains over traditional deep copy; for example, std::string under the C++98 standard uses a copy-on-write implementation.
Golang’s string,slice also use a similar idea, when copying / slicing and other operations do not change the underlying array pointing, variables share the same underlying array, only when append / modify and other operations may be a real copy (append when the current slice exceeds the capacity, you need to allocate new memory).
Buffer Sharing
As you can see from the previous introduction, the traditional Linux I/O interface, is based on copy/copy: data needs to be copied between the operating system kernel space and a buffer in user space. Before performing I/O operations, the user process needs to pre-allocate a memory buffer. When using the read() system call, the kernel copies the data read from memory or a device such as a NIC into this user buffer. When using the write() system call, the kernel copies the data from the user memory buffer to the kernel buffer.
To implement this traditional I/O model, Linux has to perform memory virtual mapping and unmapping at every I/O operation. The efficiency of this memory page remapping mechanism is severely limited by the cache architecture, MMU address translation speed, and TLB hit rate. It is possible to greatly improve I/O performance if the overhead caused by virtual address translation and TLB flushing for handling I/O requests can be avoided. Buffer sharing is one of the techniques used to solve the above problems (to be honest I think there is some nesting).
OS kernel developers have implemented a framework for buffer sharing called fbufs, or Fast Buffers, which uses an fbuf buffer as the smallest unit of data transfer. Using this technique requires calls to a new operating system API, and data between user and kernel areas and between kernel areas must be communicated strictly under the fbufs system.
fbufs allocates a buffer pool for each user process, which stores pre-allocated (or reallocated when used) buffers that are mapped to both user memory space and kernel memory space.
fbufs creates buffers in a single virtual memory mapping operation, effectively eliminating most of the performance loss caused by storage consistency maintenance.
The implementation of shared buffer technology relies on the user process, the OS kernel, and the I/O subsystem (device drivers, file system, etc.) working together. For example, a poorly designed user process can easily modify the fbuf that has been sent out and thus contaminate the data, and even worse, this problem is hard to debug.
Although the design of this technology is wonderful, its threshold and limitations are no less than the other technologies introduced earlier: first, it will cause changes to the operating system API, requiring the use of some new API calls, second, it also requires device drivers to cooperate with the changes, and because it is a memory share, the kernel needs to be very careful to implement a mechanism for data protection and synchronization of this shared memory, and This concurrent synchronization mechanism is very bug-prone and thus increases the complexity of the kernel code, etc. Therefore, this type of technology is far from being mature and widely used, and most implementations are still in the experimental stage.
Summary
From early I/O to DMA, the problem of blocking CPU was solved; and in order to eliminate the unnecessary context switching and data copying process during I/O, Zero-copy technology emerged. The so-called Zero-copy technology is to completely eliminate the need to copy data at the memory level, eliminating the process of CPU handling data.
The file transfer method of zero-copy technology reduces 2 context switches and data copy times compared to the traditional file transfer method, only 2 context switches and data copy times are needed to complete the file transfer, and the data copy process of both times do not need to pass through the CPU, both times are carried by DMA. Overall, zero-copy technology can at least double the performance of file transfer.
Zero-copy technology is based on PageCache, which caches the most recently accessed data, improving the performance of accessing cached data. At the same time, to solve the problem of slow addressing of mechanical hard drives, it also assists I/O scheduling algorithms to achieve I/O merging and pre-reading, which is one of the reasons why sequential reads have better performance than random reads; these advantages further improve the performance of zero-copy.
However, when faced with large file transfers, Zero-Copy cannot be used because the PageCache may be occupied by large files, resulting in “hotspots” where small files cannot utilize the PageCache, and the cache hit rate of large files is not high, so it is necessary to use the “asynchronous I/O + direct I/O” method; when using direct I/O, it is also necessary to pay attention to many When using direct I/O, you need to pay attention to many pitfalls, after all, even Linus will be O_DIRECT ‘disturbed’ to.
I/O related optimization has naturally penetrated into all aspects of languages, middleware and databases that we come across everyday. By understanding and learning these techniques and ideas, we can also inspire our own programming and performance optimization in the future.