Objective
- This article is intended for developers who usually use Kubernetes in their work but don’t know much about it.
- This article is only a brief introduction to the common concepts that you will encounter in using Kubernetes, and will not elaborate too much on the architecture principles.
- I hope that after reading this article, you will have an understanding of kubernetes concepts and some simple operations and maintenance operations.
What is Kubernetes?
-
Kubernetes is a portable, scalable open source platform for managing containerized workloads and services that facilitates declarative configuration and automation.
-
What Kubernetes can do:
- service discovery and load balancing
- Storage orchestration
- Automated deployment and rollback
- Automatic completion of packing calculation
- Self-healing
- Key and configuration management
-
Kubernetes Architecture
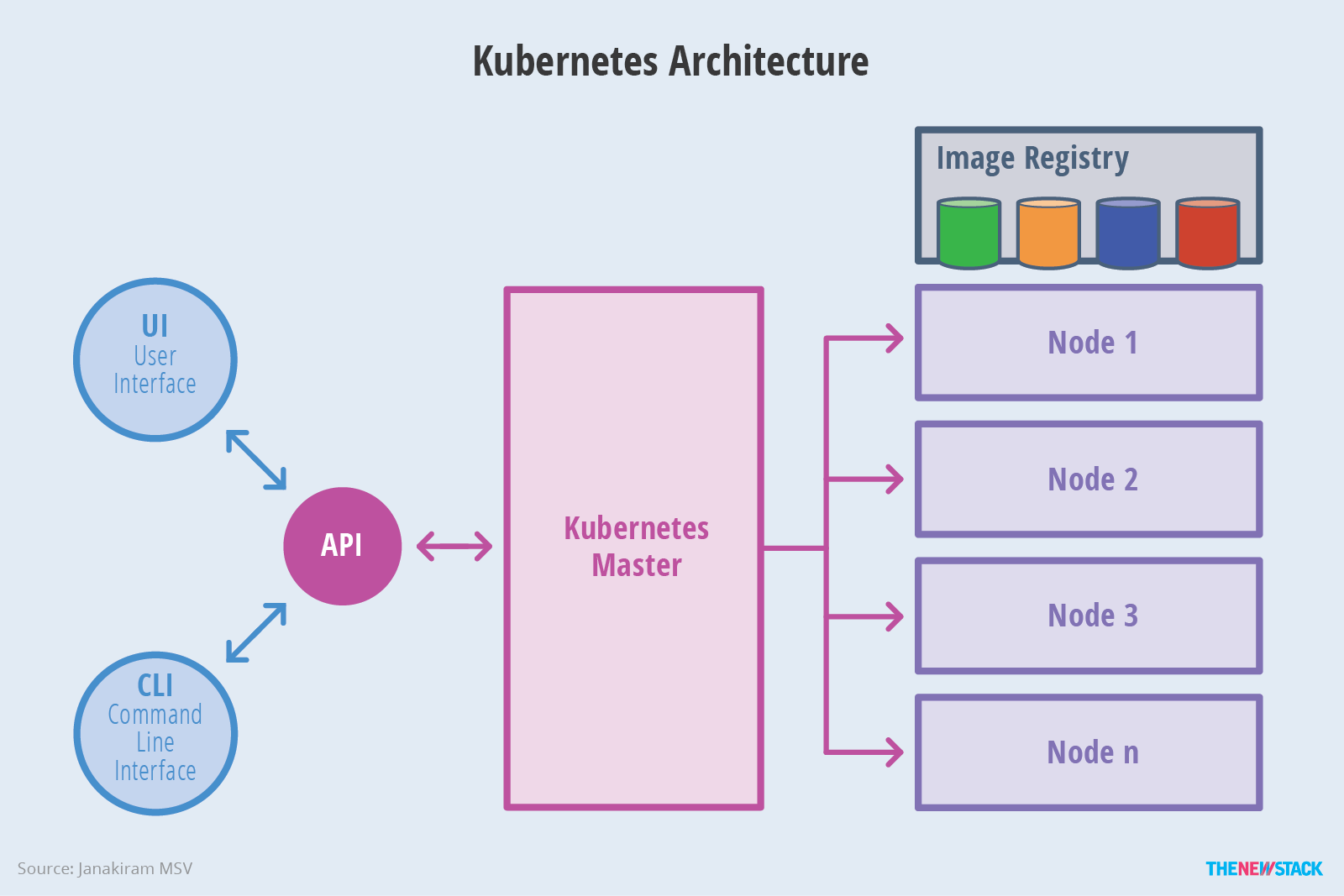
Kubernetes is a typical master-slave architecture, and for users it’s all about dealing with the Kubernetes Master API. This is true whether you are developing through a cli tool like kubectl, through a UI interface like the Kubernetes Dashboard, or through the client-go sdk.
Common Kubernetes Objects
Kubernetes objects
-
apiVersionobject version -
kindobject type -
metadataobject metadata-
namespaceNamespace for objects- Objects can be isolated by namespace
- We can also authorize users to access only some objects in a specific namespace to achieve some multi-tenancy features
- Of course not all objects have namespace, there are some objects that are cluster level
-
namethe name of the object, the name of the object is unique within a namespace, we can get to a specific object by namespace + name -
labelslabels- We can categorize Kubernetes objects by labels, and we can also quickly filter objects by labels when using
kubectlkubectl get pods -l a=b - Likewise, other objects can be associated with objects via the
labelSelector, for example Deployment is associated with the corresponding Pod via the label selector
- We can categorize Kubernetes objects by labels, and we can also quickly filter objects by labels when using
-
-
specThe specification of an object (Spec) describes the desired state of a given entity- The Spec of each object is basically specified by the engineer who developed or maintains the current object
- This is the main manifestation of Kubernetes declarative configuration, where the user submits the desired configuration and the corresponding Controller within Kubernetes will try to achieve the desired state as much as possible
-
The status information of the
statusobject describes the current state of the object- Similar to spec, the status of each object is defined by the engineer, so each object has a different status object
Pods
-
Pods are the smallest deployable units of compute that can be created and managed in Kubernetes.
-
Pod is a set (one or more) of containers; these containers share storage, network, and a declaration of how to run these containers. The contents of a Pod are always juxtaposed (colocated) and scheduled together, running in a shared context.
-
In addition to the application container, a Pod can also contain an Init container that runs during Pod startup
- The Init container will be completed before the Pod’s application container is started
- So we usually use the Init container to do some initialization operations, such as performing DB Migrate, downloading the required configuration files, etc.
-
As shown in the figure below, Pods can share network and storage, so multiple containers within a Pod can access each other directly through 127.0.0.1.

-
A brief description of Pod YAML
1kubectl --context bcs-test -n develop get podsTake our api-svc service as an example.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101apiVersion: v1 kind: Pod metadata: labels: app.kubernetes.io/chart: trpc app.kubernetes.io/name: api-service name: api-service-deploy-6b8cdb5dc8-rzg6m namespace: develop spec: # Affinity configuration that constrains which nodes the pod can be dispatched to. # This configuration enables pod scheduling to the specified node. # It is also possible to have some Pods with the same tags and other fields scheduled together or not together as much as possible. # One of the more common practices is to keep Pods in different availability zones as much as possible, so that even if one of the cloud provider's availability zones is down we can still provide services to the public. affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchLabels: a: "b" topologyKey: kubernetes.io/hostname # Storage volume declaration # Here we declare an empty dir storage volume, which can be understood as a temporary empty directory # This volume will be automatically destroyed when the pod is destroyed volumes: - emptyDir: {} name: config-cache # Initializing the container initContainers: - image: init:20220401221741 imagePullPolicy: IfNotPresent name: init-trpc-go-config # This initialization container and the following application container both mount this empty dir # So both containers can read and write to this same directory volumeMounts: - mountPath: /app/config/ name: config-cache # Container Configuration containers: - command: - /app/api_service # Environment variables, in addition to specifying kv # You can also inject some of the pod's own fields into the container by way of environment variables like this env: - name: env value: develop - name: pod_ip valueFrom: fieldRef: apiVersion: v1 fieldPath: status.podIP image: api-service:master-5f05c18a # How to download container images imagePullPolicy: IfNotPresent # Life cycle hook # The following example sleeps 120s before the container exits # This is to give our registry time to kick the service offline so that we don't break it during the release lifecycle: preStop: exec: command: - /bin/sh - -c - sleep 120 # Survival check # If the following health checks are not met, the pod will be automatically terminated livenessProbe: failureThreshold: 1 httpGet: path: /cmds port: 8000 scheme: HTTP periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 name: api-service # Port Mapping ports: - containerPort: 8001 hostPort: 29131 protocol: TCP # Resource limitations resources: limits: cpu: "1" memory: 2Gi requests: cpu: 50m memory: 50Mi volumeMounts: - mountPath: /app/config/ name: config-cache status:
Deployment
-
Deployment is often used to manage stateless services, such as common web backend services that are almost always stateless. deployment starts pods in no particular order, and the name of each pod is random.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44apiVersion: apps/v1 kind: Deployment metadata: annotations: meta.helm.sh/release-name: api-service meta.helm.sh/release-namespace: develop labels: app.kubernetes.io/managed-by: Helm app.kubernetes.io/name: api-service name: api-service-deploy namespace: develop spec: # Number of Replicas replicas: 2 # tag selector, indicating that this Deployment controls these pods selector: matchLabels: app.kubernetes.io/name: api-service # Update Strategy strategy: rollingUpdate: maxSurge: 100% maxUnavailable: 0% type: RollingUpdate # pod template, in fact, is the definition of the pod, except that there is no difference between apiVersion and kind template: metadata: labels: app.kubernetes.io/name: api-service spec: # pod spec status: availableReplicas: 2 conditions: - lastTransitionTime: "2022-11-02T04:52:37Z" lastUpdateTime: "2022-11-02T09:56:06Z" message: ReplicaSet "api-service-deploy-6b8cdb5dc8" has successfully progressed. reason: NewReplicaSetAvailable status: "True" type: Progressing observedGeneration: 290 readyReplicas: 2 replicas: 2 updatedReplicas: 2
Statefulset
-
StatefulSet is a workload API object used to manage stateful applications, StatefulSet maintains a sticky ID for each of their pods.
- StatefulSet always starts pods in order, and pod names are fixed, so pods can be accessed directly by pod name as domain name.
-
StatefulSet YAML is not very different from Deployment.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx # Must match .spec.template.metadata.labels serviceName: "nginx" replicas: 3 # The default value is 1 minReadySeconds: 10 #The default value is 0 template: metadata: labels: app: nginx # Must match .spec.selector.matchLabels spec: # pod spec
Job
-
Job will create one or more Pods and will continue to retry Pod execution until the specified number of Pods have successfully terminated. As Pods successfully terminate, Job tracks the number of successfully completed Pods. When the number reaches the specified threshold of successful completions, the task (i.e. Job) ends. The Delete Job action clears all the Pods created. The Hang Job action deletes all active Pods of the Job until the Job is resumed again.
-
Jobs are commonly used for one-time tasks.
-
Job YAML.
Helm Introduction
-
When deploying a kubernetes application, there are often many objects involved, and often only a limited number of fields need to be modified when deploying many applications. If all deployments were done using yaml, there would be a lot of duplicate fields and a very inefficient way to maintain them.
-
helm is one of the solutions, it can be used to manage chart, chart is easy to use k8s application package management method, mainly is a lot of yaml template file plus a
values.yamlfile for defining input fields -
The basic structure of a chart
1 2 3 4 5 6 7 8 9 10 11 12 13mychart ├── Chart.yaml ├── charts # This directory holds the charts (sub-charts) of other dependencies ├── templates # chart configuration template for rendering the final Kubernetes YAML file │ ├── NOTES.txt # Prompt message when user runs helm install │ ├── _helpers.tpl # Help classes for creating templates │ ├── deployment.yaml # Kubernetes deployment configuration │ ├── ingress.yaml # Kubernetes ingress configuration │ ├── service.yaml # Kubernetes service configuration │ ├── serviceaccount.yaml # Kubernetes serviceaccount configuration │ └── tests │ └── test-connection.yaml └── values.yaml # Define the default values for custom configurations in the chart template, which can be overridden when executing helm install or helm update -
With the
helm installcommand we can install the chart into the k8s cluster by specifying thevalues.yamlfile instead of the default parameters. After installation, the application is called release in helm.