Go implements a goroutine scheduler in its own runtime for the efficiency of its goroutine execution and scheduling. The following is a simple code to show the goroutine of a Go application at runtime for better understanding.
The Go scheduler is part of the Go runtime, and the Go runtime is built into your application
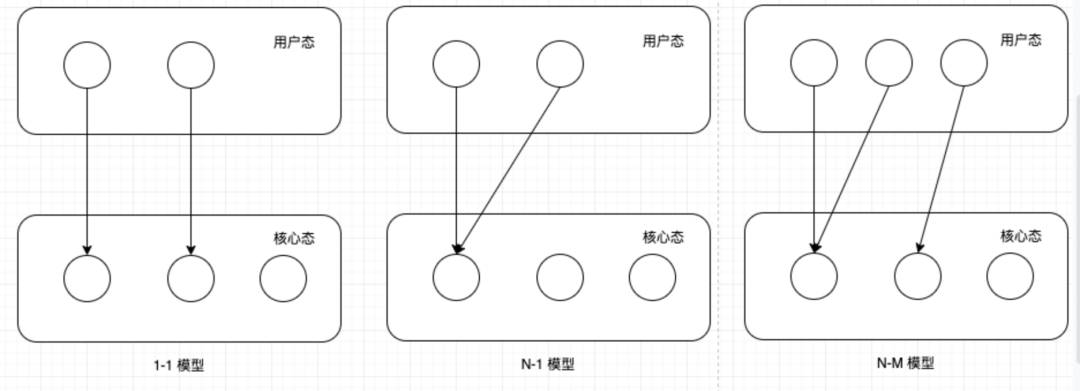
The output of the above code is 5. This means that the number of goroutines present in the application is 5, which is in fact what we expected. The problem is that these 5 goroutines, as the basic scheduling unit of the user state of the operating system, cannot directly occupy the resources of the operating system and must be distributed through the kernel-level threads, which is the basic model of thread scheduling within the operating system. According to the correspondence between user-level threads and kernel-level threads, there are three models: 1-to-1, N-to-1, and M-to-N. How are the above 5 goroutines distributed on the kernel-level threads? This is determined by the Go’s goroutine scheduler.
GMP Model
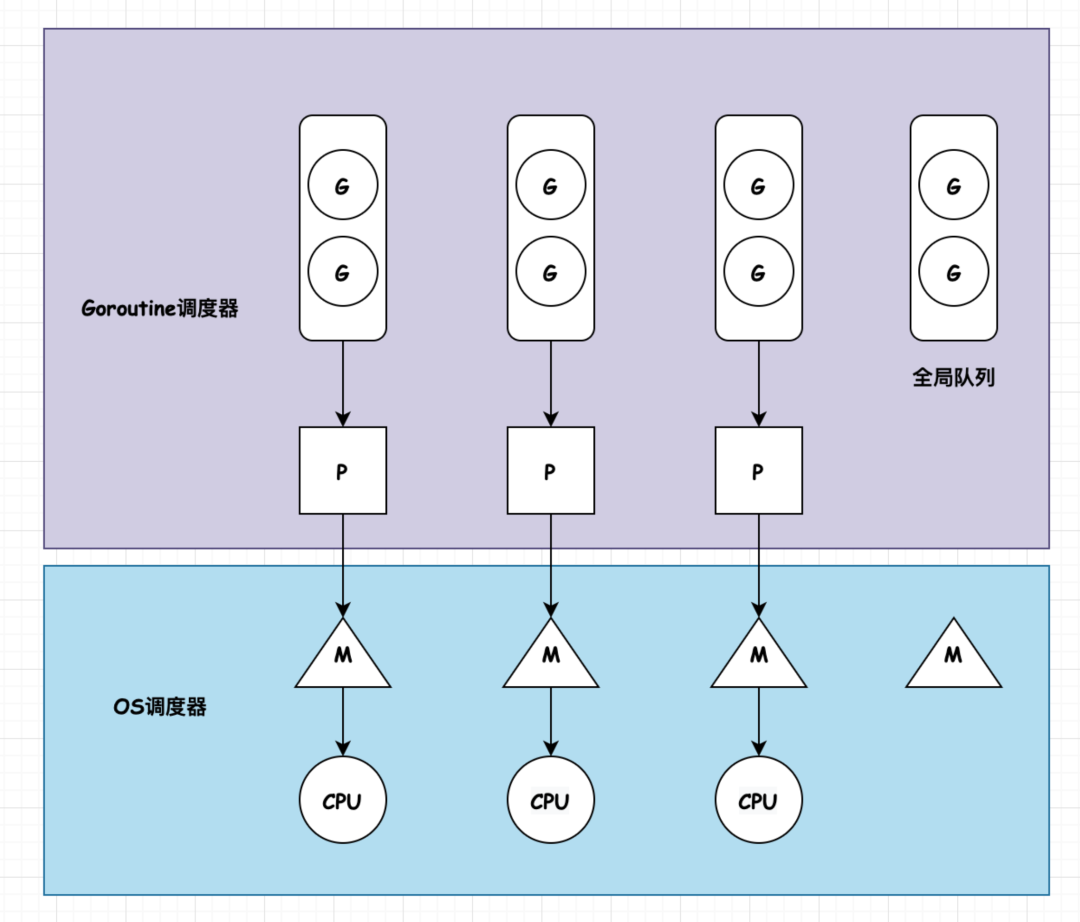
The entire implementation of the goroutine scheduler is based on the three-level model of GMP.
- G: goroutine
- M: kernel-level threads, which run in the core state of the operating system. The maximum number of M’s supported in Go is 10000, but it is not usually possible to create this many threads in the OS.
- P: processor, understood as a queue of goroutines waiting to be distributed to M. The number of P’s is determined by the runtime’s GOMAXPROCS.
There is a one-to-one binding relationship between M and P. The general structure diagram is shown below.
goroutine tour
How does the GMP model normally work after we execute go func(){} in our code? A detailed diagram shows it.
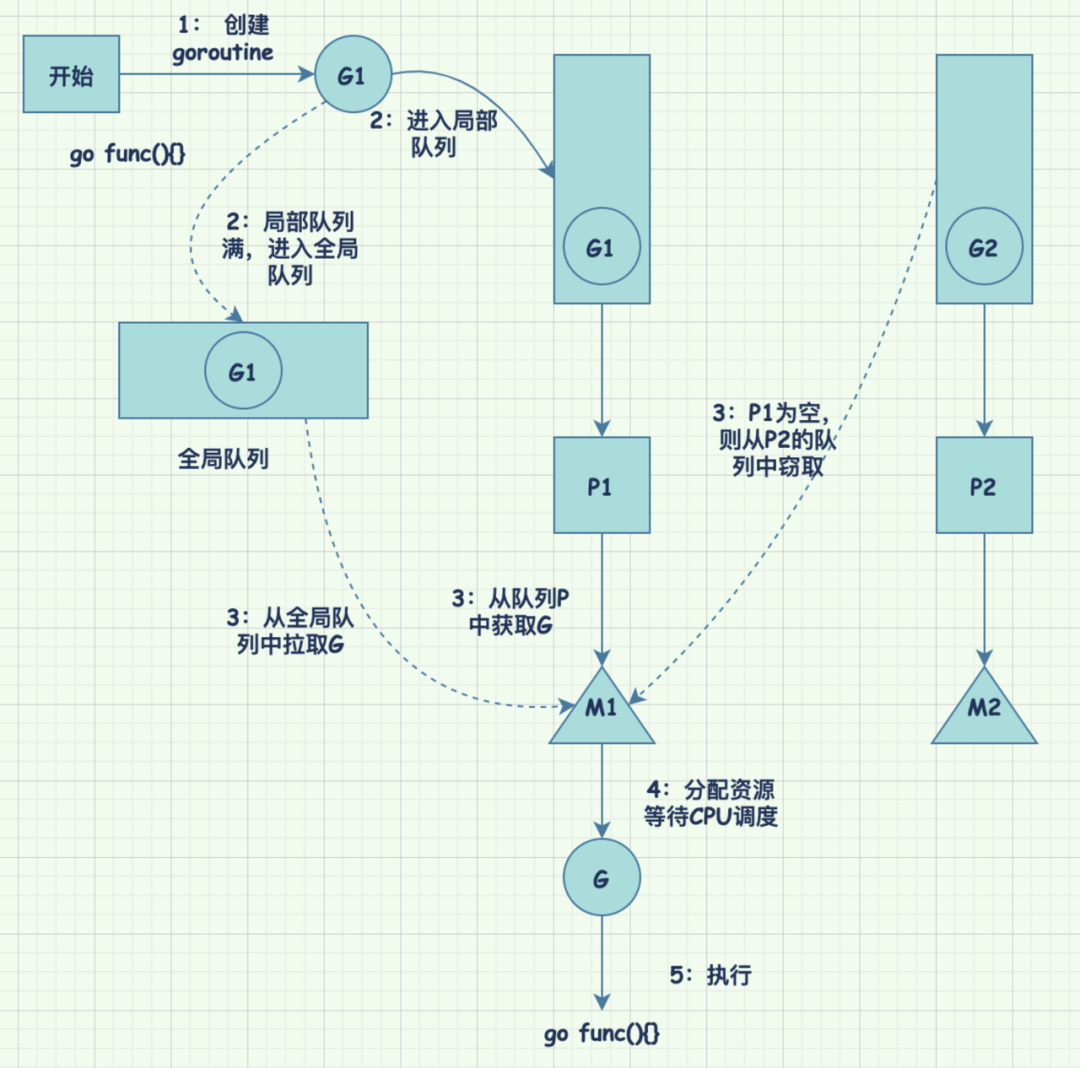
- first create a new goroutine
- if there is enough space in the local queue, put it into the local queue; if the local queue is full, put it into a global queue (all M can pull G from the global queue to execute)
- all G must be executed on M, M and P have a one-to-one binding relationship, if there is a G that can be executed in P bound by M, then pull G from P to execute; if P is empty and there is no executable G, then M pulls G from the global queue; if the global queue is also empty, then pull G from the other P
- allocate the necessary resources for G to run and wait for the CPU to schedule it
- allocate the CPU and execute func(){}
Scheduling Strategy
The most important scheduling strategy for the entire goroutine scheduler is: reuse, avoiding frequent resource creation and destruction, and maximizing system throughput and concurrency. This is the ultimate goal of thread scheduling by the operating system. Reuse is also the basis of many “pooling techniques”.
Around this principle, the goroutine scheduler optimizes the scheduling policy in the following ways.
- The work queue stealing mechanism: This is the same principle as the Java ForkJoin Pool stealing mechanism, which “steals” task G from other busy queue P to execute when thread M is idle, instead of destroying the idle M. Because thread creation and destruction consume system resources, avoiding frequent thread creation and destruction can greatly improve the concurrency of the system. This is because thread creation and destruction consume system resources.
- Handover mechanism: When a thread M is blocked, M will actively hand over P to another idle M.
Also, in version 1.14 of go, the go language technical team tried to add preemptable techniques to the scheduler, see https://github.com/golang/go/issues/24543
- On the one hand, the emergence of preemption solves the “starvation phenomenon” caused by other G’s on the P bound to thread M that occupy the CPU for a long time while executing computationally intensive tasks.
- On the other hand, the emergence of the preemption technique solves the possible deadLock during GC, see the related issue: Discussion on tight loops should be preempted during GC (https://github.com/golang/go/issues/10958)
The original MG model
In the early days of go, the goroutine scheduler model was not GMP, but GM. the entire scheduler maintained a global waiting queue G, and all Ms pulled G from this global queue for execution. this model was simply deprecated in go1.1, and replaced by the current GMP model, which adds the P local queue to the GM model. The official reasons for doing this are as follows.
- global G waiting queue, different M fetch G from the queue need to lock synchronization, lock granularity is very large, seriously limit the system concurrency ability to improve.
- Without local queues, when threads perform IO-intensive operations, M blocks on IO operations, and the corresponding G cannot be executed (GMP can hand off G to other M for execution), so the GM model has low performance when dealing with IO-intensive tasks