I was looking through the Cilium Release Blog and found a kernel technology called Big TCP, which was just merged into the kernel around February this year. The introduction said that it is specially designed for high-speed networks with more than 100Gbit, and it can significantly reduce the latency while increasing the throughput by 50%, so I went to learn more about this technology.
High-speed network performance bottlenecks and misconceptions
When it comes to network performance, many people will naturally associate it with NIC performance, but those who have done network performance optimisation will know that the bottleneck is more on the CPU. Generally using iperf3, qperf such pressure testing software for testing, especially in the case of small packets is basically unable to play the full bandwidth of the network card, this time the CPU will be preceded by the network card to reach the bottleneck.
Therefore, network performance optimisation is usually done by CPUU-related optimisation, no matter DPDK, Offload, XDP acceleration principle is either bypassing the kernel stack, or offloading part of the work to the NIC, which is essentially to save CPU resources to process more packets.
Taking a 100G NIC as an example, the MTU of Ethernet is 1500 bytes, so if the CPU wants to fully use the NIC without any optimisation, it has to process nearly 8 million packets per second, and if each packet has to go through the complete network stack, a modern CPU single core is far from being able to deal with packets of this order of magnitude.
In order to get the best possible network performance from a single core, it is necessary for the kernel and the NIC driver to work together to Offload some of the work to the NIC, which is also known as GRO (Generic Receive Offload) and TSO (TCP Segment Offload) related techniques.
GRO and TSO
One of the reasons why the CPU can’t handle so much data is that it wastes a lot of resources to encapsulate the protocol header for each packet, calculate the checksum and so on, and 1500 MTUs at 100G bandwidth is just too small to have to split up so many small packets. If the packet splitting and assembling is left to the NIC, then the size of the packets that the kernel needs to process will be reduced, which is the basic principle of GRO and TSO to improve performance.
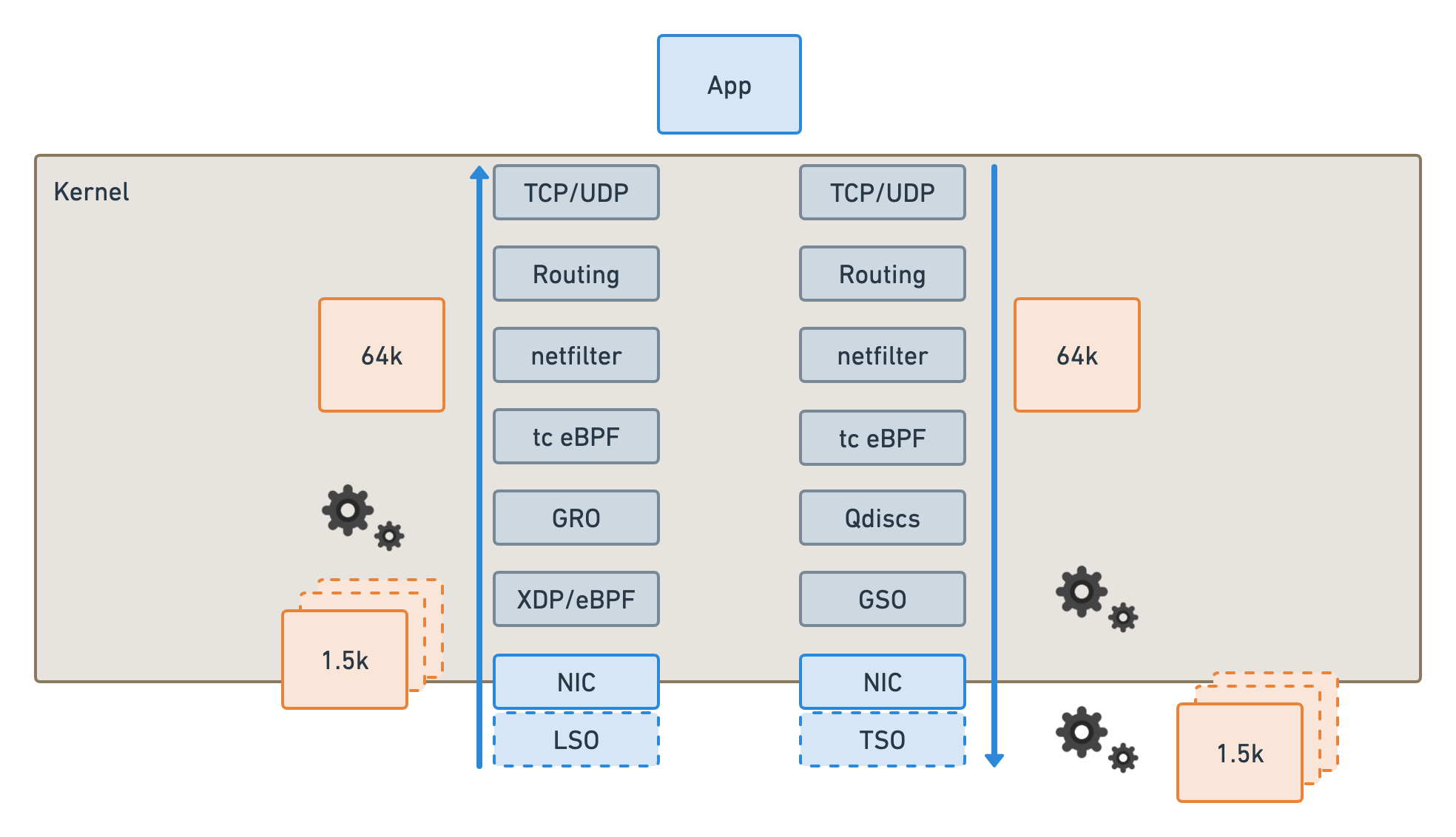
As shown in the figure above, when sending packets, the kernel can handle packets in accordance with 64K, the NIC through the TSO split into 1.5K small packets for transmission, the receiving end of the NIC through the GRO will be small packets aggregated into 64K large packets in the kernel to send processing. In this way, the number of packets the kernel needs to process is reduced to one-fortieth of the original. Therefore, theoretically, the throughput of the network with these two Offloads on will increase by tens of times in the case of large packets, and in our previous tests this performance was about ten times worse.
Also, in the mainstream kernel and NIC drivers only support TCP Offload, so it’s not intuitive to see that the TCP performance of iperf3 is much better than the UDP performance, and the difference is about ten times.
What does Big TCP do?
Now that we have this Offload, what Big TCP does is to make the packets processed in the kernel bigger, so that the overall number of packets to be processed will be further reduced to improve performance. The main limitation of the 64K packet size handled by the kernel is that there is a length field in the header of the IP packet, which is 16 bits long, so the theoretical maximum length of an IP packet is 64K.
How can we break this length limit? The author of the kernel used some very hacky methods here, in the IPv6 packet there is a hop-by-hop 32-bit field that can store some additional information, then the kernel can set the length of the IP packet to 0, and then get the real length of the packet from the hop-by-hop field, so that the maximum size of a packet can be up to 4GB. However, to be on the safe side, the maximum size can only be set to 512K, and even then the packets to be processed will be one-eighth of the original size, which is nearly one-third of what it would have been if there was no offloading.
According to developer tests, throughput has increased by nearly 50 per cent and latency has dropped by nearly 30 per cent, which is quite remarkable.
|
|
Big TCP’s IPv4 support is a bit later, mainly because there is no optional hop-by-hop information field in IPv4 like in IPv6, so the real length information can’t be saved in the IP header. However, the authors went the other way and calculated the true length of the packet directly from the kernel’s skb->len, which is fine as long as the packet is of the correct length after it is sent out anyway, and actually relies entirely on the skb to keep the state information inside the machine, thus enabling TCP packets longer than 64K. In theory, the IPv4 approach would be more general, but IPv6 has been implemented first, so there are two different approaches to implementing Big TCP.
Summary
This technology requires both kernel and hardware drivers, with the kernel requiring 6.3 for official support and the NIC driver requiring a contact with the hardware vendor. However, Big TCP is still a promising technology that can significantly improve network performance without requiring application tuning, which can be very beneficial in certain scenarios.