In the latest instalment of the Go dev team’s weekly meeting, they discuss Google3 re-evaluating the performance of SwissTable, and that it might be worth following up with a replacement for the standard library map.
- SwissTable
- [MichaelP]: Google3 may want to do some benchmarking on this. Maps are used heavily in google3. This may be of value to us.
- So this may be worth investing in.
Some people may not understand SwissTable (or called Swiss Tables) is what Google3 and what?
Google3 may be familiar to people inside Google, but the concept is rarely introduced outside. Google3 refers to Google’s large code repository (monorepo), 95% of Google’s code is in this large repository, except for Chrome and Android and other special projects.
SwissTable is a Google open source implementation of a hash table (hash table, map), announced out at cppcon 2017, which is heavily used internally by Google to replace std::unordered_map , which is very efficient due to its compact design, and it has also been ported to other languages, for example, Rust has a library hashbrown based on the SwissTable implementation, and in Rust 1.36 started to replace the standard library HashMap.
The official documentation and some developers’ notes describe the benefits of SwissTable, such as
- Swiss Tables Design Notes
- Swisstable, a Quick and Dirty Description
- Swisstable: a faster hash table than std::unordered_map in C++.
So Go development team also began to focus on SwissTable, perhaps in a future version to implement it and replace the standard library map, after all, these basic data types and algorithms will help millions of people use Go to do the development of the project, such as sorting algorithms, for example, last year bytedance developers submitted a pdqsort algorithm, replacing the standard library sorting algorithms, now again! Someone proposed dual-pivot quicksort, according to the test performance is better and more concise, we have been using for decades these people have been the basic algorithms and data structures or tireless optimisation.
Although the Go development team is currently only focusing on and discussing SwissTable, and may not implement it in the future, the community has recently implemented SwissTable: swiss.
I introduced this author’s maphash in a post last year, and it looks like the author has been preparing for his SwissTable, and this year he submitted a Go implementation of SwissTable, which calculates hashes using his maphash.
The author has written an article about his swiss design, we can at least understand from this library how the Go language design SwissTable, but also in some optimisation scenarios you can privately use this library to replace the built-in map, as the author did.
The built-in map uses the open addressing method (open-hashing , also called zip method), key-value pairs with conflicting hash values (hash values are the same) will be placed in a bucket, when looking up, first find the corresponding bucket according to the hash value, and then traverse the elements in the bucket to find the corresponding value, of course, there are still some optimisations in this, by extra bits to do faster checking, the built-in map details can refer to the sharing of 2016 GopherCon conference: Inside the Map Implementation.
SwissTable uses a different hashing scheme called Closed Hashing (also known as open address method). Each hash value has its own slot, and the choice of slot is determined by the hash value, the simplest way is to start from the hash(key) mod size slot, and keep searching backward until it reaches the corresponding key or an empty slot (non-existent key), which is also a common way of using the open-address method. SwissTable also uses short hash like the built-in map to support fast checking, but its metadata is stored separately from the hash.
Using this method is more friendly to the CPU cache, and more importantly, it is possible to compare 16 short hashes in parallel with the SSE instruction.
Since the find method is the basis for the other methods Get(), Has(), Put(), Delete(), which look for the corresponding slots, let’s look at the library swiss and see how it implements the above logic (pseudo-code).
|
|
The library also provides code for benchmark, and we tested its performance against the built-in map on an Apple M2 and a dummy machine, respectively.
|
|
|
|
As you can see, when the number of keys is relatively small, swiss can’t take advantage of its SSE instruction, but in the case of a very large number of key values, swiss has an obvious advantage.
The author’s maphash library, introduced earlier, can take advantage of the hardware’s ability to compute hashes faster on some platforms that support the AES instruction.
Not only that, swiss also has its advantages in terms of memory consumption. According to the author’s test, swiss can save more memory.
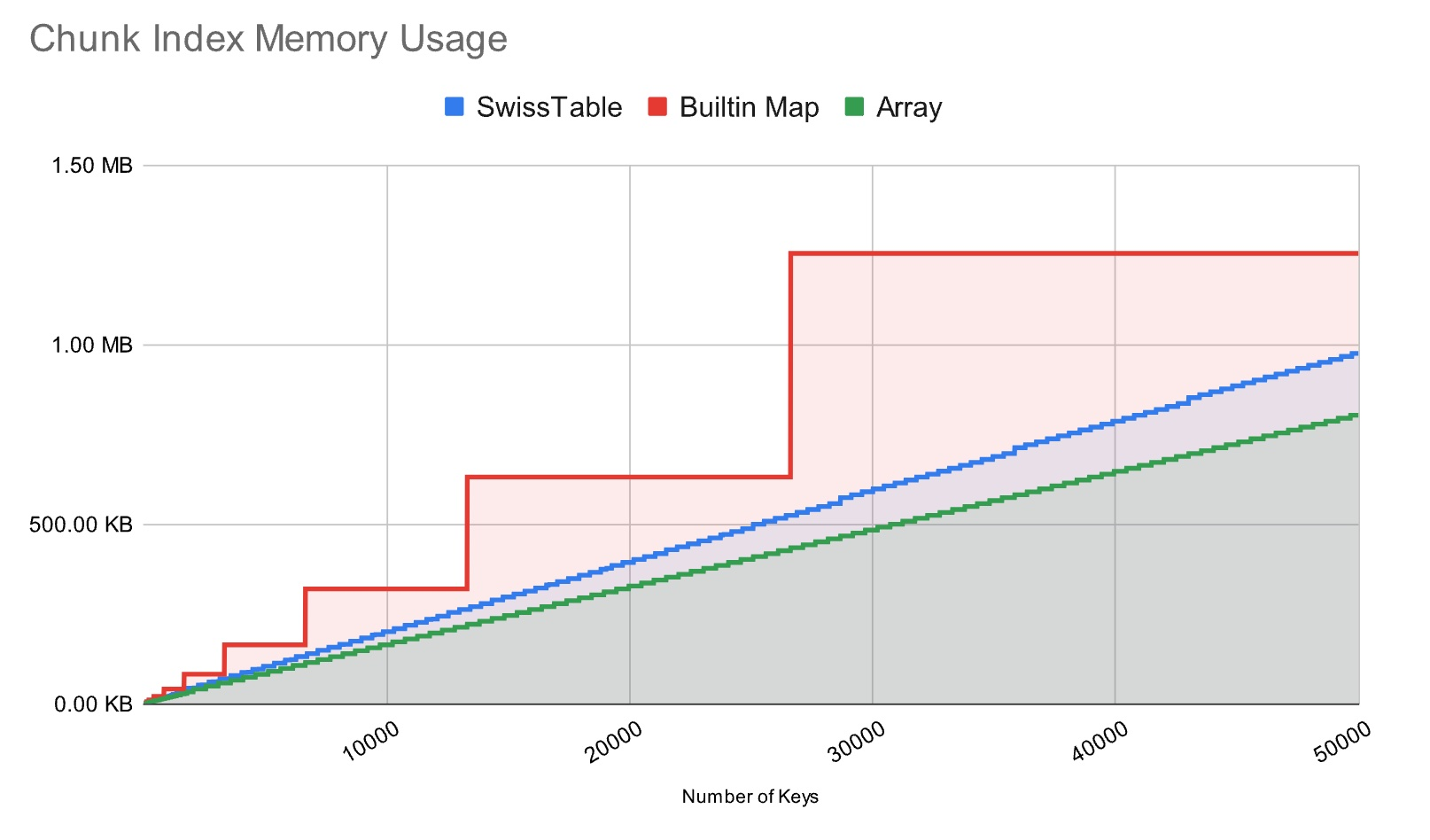
The reason why the built-in map’s memory will step up when the number of keys increases is because of the bit-hacking optimisation model that is commonly used, which generally uses an exponent of 2 for division in order to improve the method of finding the remainder, so when you need to expand the memory when the number of keys increases, the memory allocated will double. So you see the memory of Go’s built-in maps increasing in steps, which is sometimes very wasteful.
The swiss library uses an algorithm proposed by Daniel Lemire for fast summation (more accurately, modulo reduction), an idea that seems simple but is actually very clever (x * N) / 232:
This method restricts the type of n to uint32 and supports a maximum of 2 ^ 32, and since each bucket has 16 elements, the swiss library supports a maximum of 2 ^ 36 elements, which is sufficient for most scenarios.
Ref: https://colobu.com/2023/06/29/replace-std-map-faster/