Let’s start with a brief introduction to Protocol Buffers (protobuf), which is a data serialization protocol developed by Google (similar to XML, JSON). It has many advantages, but also has some disadvantages that need to be noted:
Advantages:
- High efficiency: Protobuf stores data in binary format, which is more compact and faster than text formats such as XML and JSON. Serialization and deserialization are also fast.
- Cross-language support: Protobuf supports a variety of programming languages, including C++, Java, Python and so on.
- Clear Structure Definition: With protobuf, the structure of the data can be clearly defined, which helps in maintenance and understanding.
- Backwards compatibility: You can add or remove fields without breaking old applications. This is valuable for projects that require long-term maintenance.
Disadvantages:
- Unintuitive: Since protobuf is in binary format, a person cannot read and modify it directly. This can be a bit difficult for debugging and testing.
- Lacks some data types: for example, there is no built-in date and time types, for which one needs to manually convert to a type that can be supported, such as string or int.
- Requires extra compilation step: you need to define the data structure first, and then use protobuf’s compiler to compile it into the target language code, which is an extra step and may affect the development process.
In general, Protobuf is a powerful and efficient data serialization tool, we value its performance and compatibility on the one hand, in addition to its mandatory requirements clearly defined, presented in the form of a file to facilitate our maintenance and management. Here we mainly look at its coding principles, as well as in the use of what need to pay attention to the place.
Principles of coding
Overview
The encoding of protobuf is very compact. Let’s take a look at the structure of a message for a simple example:
A message is a series of key-value pairs encoded as a tag with a sequence number and a corresponding value, which is very different from the familiar json, so it’s impossible for protobuf to decode it without a .proto file:
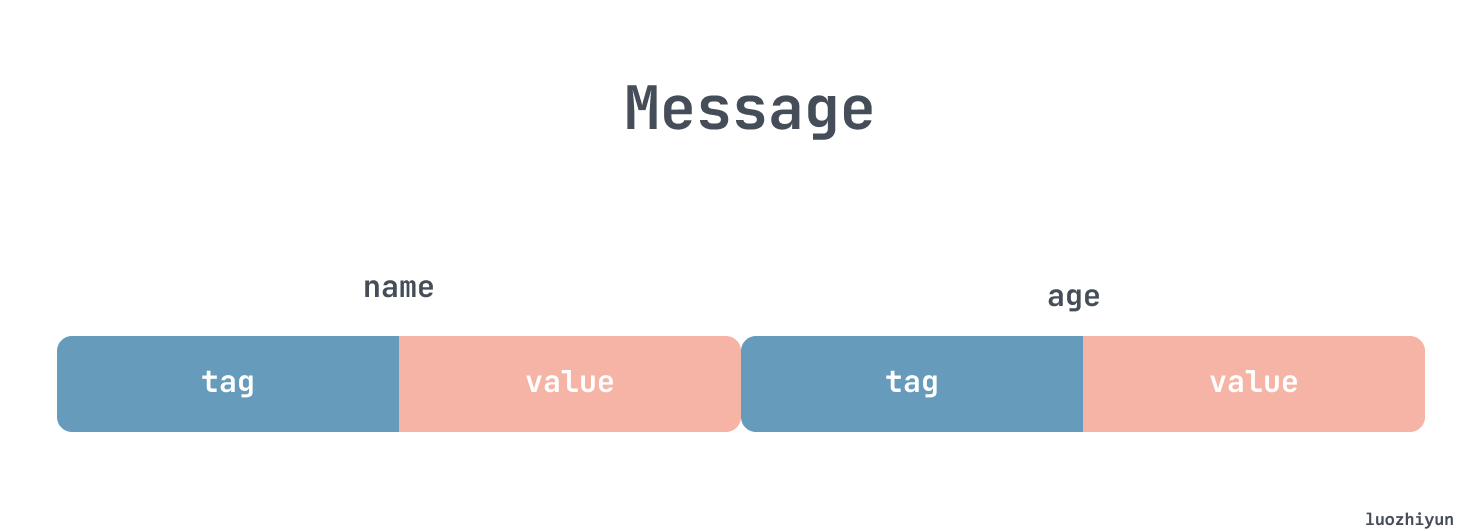
For a tag, it holds the number and type of the message field. We can experiment by printing out the encoded binary version of the name tag.
The printout is as follows.
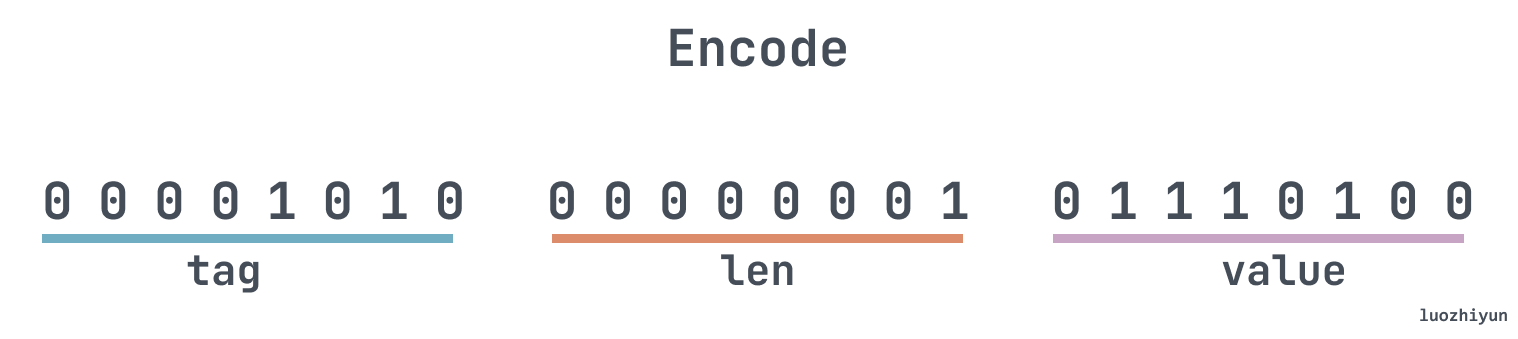
In the image above, since name is of type string, the first byte is the tag, the second byte is the length of the string, and the third byte is the value, which is the “t” we set above. Let’s take a look at tag below:
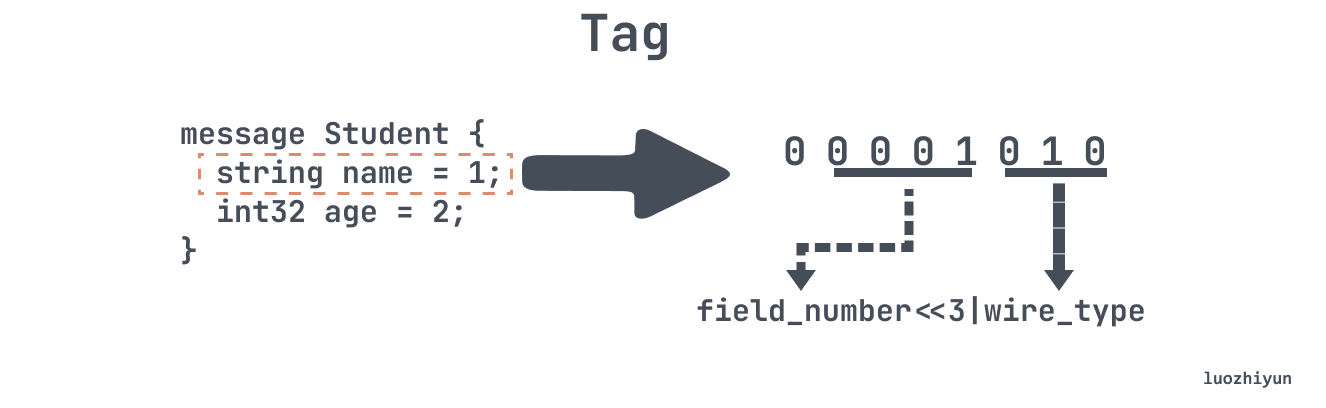
tag will contain two parts of information: field number, field type, the calculation is the formula in the above figure. The above figure will be name this field serialized into binary we can see that the first bit is the mark bit, that is, whether the end of the field, here is 0 that tag has been the end of the tag takes up 1byte; the next 4 bit that is the number of the field serial number, so the range of 1 to 15 in the number of the field only needs 1 bit to encode, we can do an experiment to see that will tag change the tag to 16.
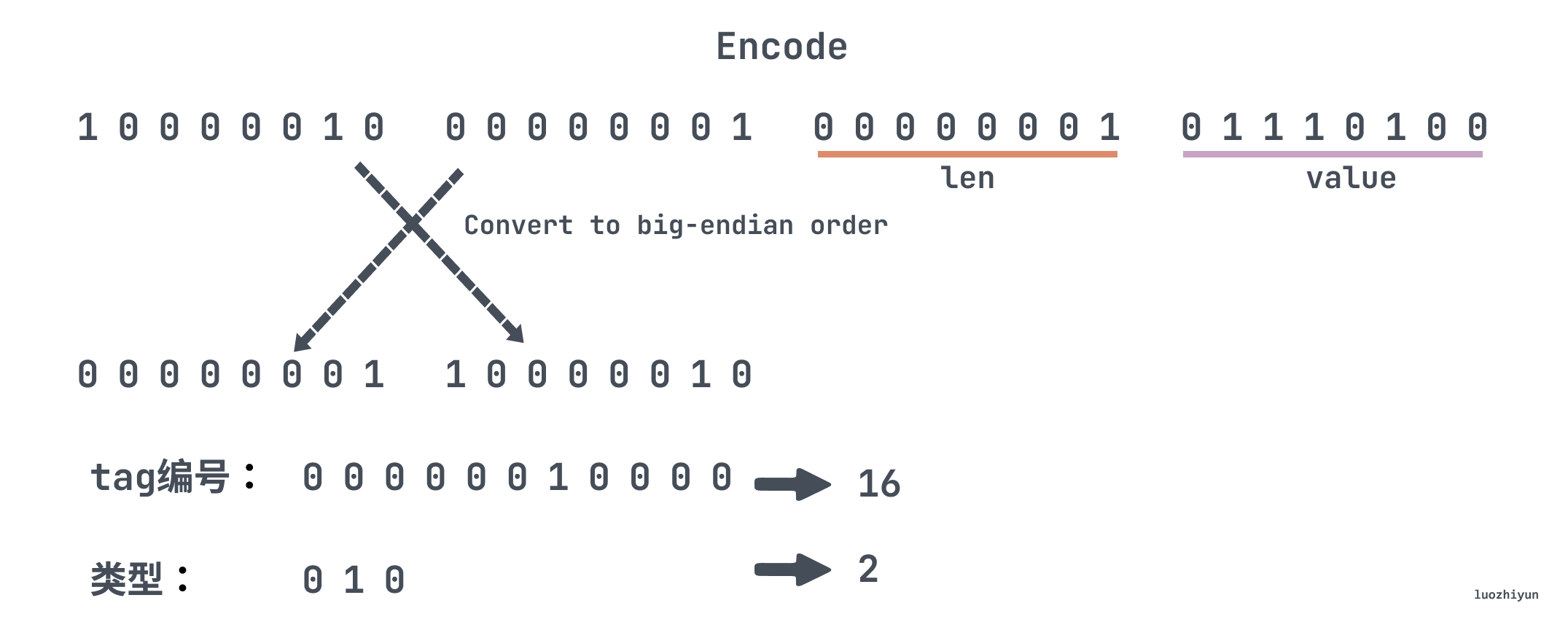
As shown in the figure above, the first bit of each byte indicates whether the end, 0 means the end, so the above tag with two byte, and protobuf is Little-Endia, in order to facilitate the reading of the need to be converted to Big-Endian, so we can know that the tag after removing the first bit of each byte, after the first three bits indicate the type, is 3, the rest of the bits are numbered to indicate that the 16.
So from the above coding rules we can also know that the field as much as possible to streamline some of the field as much as possible not more than 16, so that it can be expressed in a byte.
At the same time, we can also know that protobuf serialization is not with the field name, so if the client proto file only modified the field name, the request server is safe, the server continues to use according to the sequence number or to solve out the original field. But you need to be careful not to modify the field type.
Next, let’s look at the types. protobuf defines six types, two of which are deprecated:
| ID | Name | Used For |
|---|---|---|
| 0 | VARINT | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | I64 | fixed64, sfixed64, double |
| 2 | LEN | string, bytes, embedded messages, packed repeated fields |
| 3 | SGROUP | group start (deprecated) |
| 4 | EGROUP | group end (deprecated) |
| 5 | I32 | fixed32, sfixed32, float |
In the above example, Name is of string type, so the above tag type is 010, that is 2.
Varints encoding
For protobuf, the number type is compressed, normally an int32 type takes 4 bytes, while protobuf only takes 2 bytes for numbers up to 127, because for a normal int32 type number, if the number is very small, there are actually very few valid bits, for example, to represent a number of 1, the binary might be like this:
|
|
The first 3 bytes are 0 without any information, protobuf removes all these 0s, and uses 1 byte to represent the number 1, and another 1 byte to represent the number and type of the tag, so it takes up 2 bytes.
For example, we set age equal to 150 for student above:
The binary printout above is as follows, because 150 is more than 127, so it needs to be represented by two bytes:
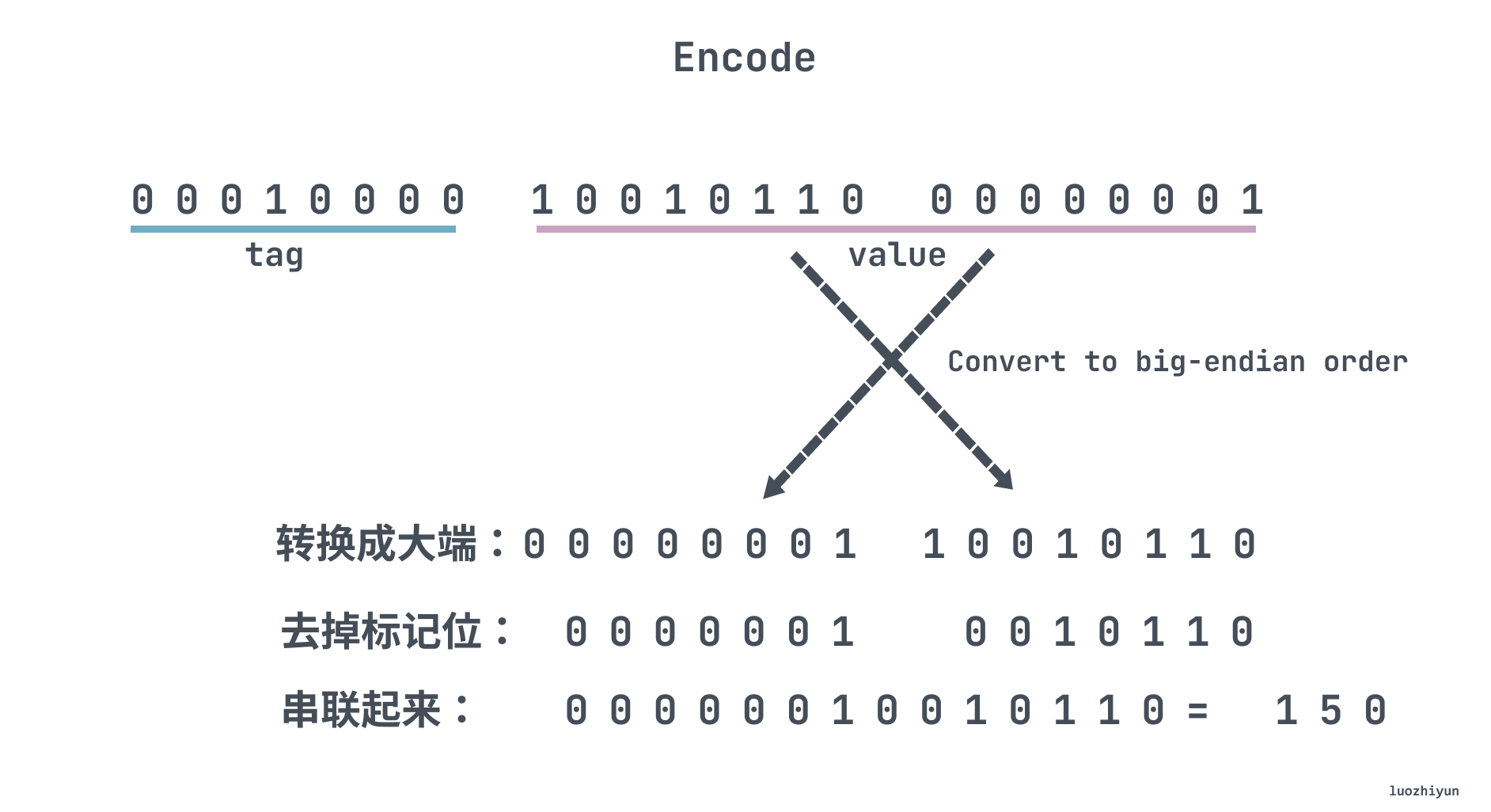
The first byte is the tag, so I won’t repeat it here. The next two bytes are the real value, and the highest bit of each byte is a tag bit, indicating whether it is over or not. Then we convert it to big endian representation and concatenate it to get the value of 150.
ZigZag encoding
The Varints encoding reduces the number of bytes stored because it removes the 0’s, but not for negative numbers, which have a sign bit of 1 and are converted to 64-bit unsigned for 32-bit signed numbers.
For example, -1, encoded in Varints, would look like this in binary.
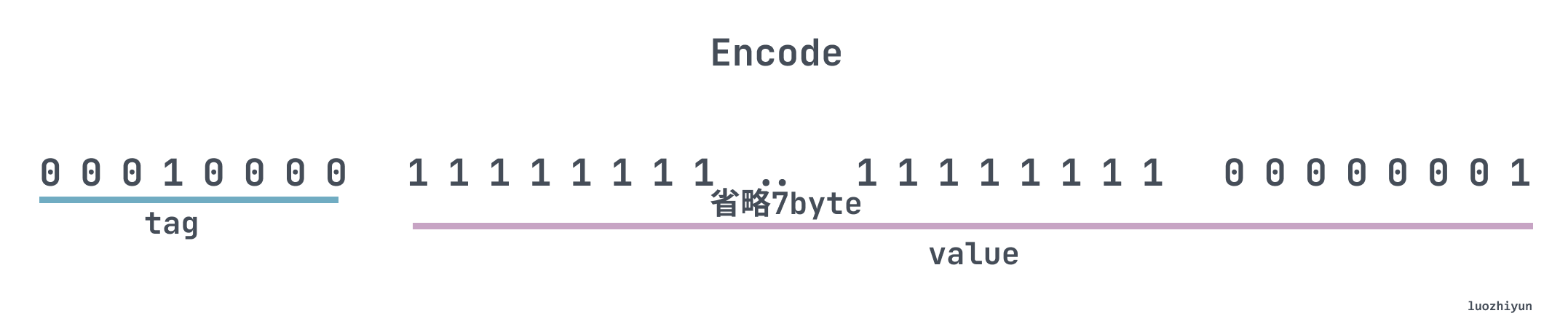
So Varints encoding negative numbers will always take up a total of 11 bytes, one byte for the tag and 10 bytes for the value.
For this reason Google Protocol Buffer defines the type sint32, which is zigzag encoded. All integers are mapped to unsigned integers and then encoded using varint encoding. For example:
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| … | … |
| 0x7fffffff | 0xfffffffe |
| -0x80000000 | 0xffffffff |
Referring to the table above, that is, encoding -1 into 1 and 1 into 2, all of which are mapped, the actual Zigzag mapping function is:
For use, only the encoding method is changed, the use is not affected, so for if there is a high proportion of negative data, you can try to use the sint type to save some space.
embedded messages & repeated
Let’s say we define a proto like this:
The value of scores is [1,2,3], and after encoding it, we realize that it is actually very similar to the string type mentioned above. The first byte is the tag; the second byte is len, which is 3; and the last three bytes are all values, which we set to 1, 2, and 3.

Next, take a look at the embedded messages type and have Lecture’s price set to 150, which looks like this after encoding:

The structure is very simple, the left one is Student type and the right one is Lecture type. The difference is that for embedded messages, the size is calculated.
Best Practices
Field Numbering
Note that field numbers in the range 1 through 15 require one byte to encode, including the field number and field type; field numbers in the range 16 through 2047 require two bytes. So you should reserve the numbers 1 through 15 for very frequent message elements.
Because VarInts are used, the highest bit of a single byte is zero, and the lowest three bits indicate the type, leaving only four bits available. This means that when you have more than 16 fields, they need to be represented by more than two bytes.
Reserved fields
In general, we don’t remove fields easily to prevent protocol inconsistency between client and server, if you update the message type by removing a field completely or commenting it out, then others in the future don’t know that the tag or field has been removed, we can use reserved to mark the removed field, for example:
In addition to message, of course, reserved can also be used in enumeration types.
Don’t change field tag numbers or field types
protobuf serialization does not come with field names, so if the client’s proto file only modifies the field names, it is safe to request the server to continue to parse out the original fields according to the sequence number, but it is important to note that you should not modify the field type and sequence number, as you may find the wrong type according to the number after you have modified it.
Don’t use the required keyword
required means that the field must be included in the message and its value must be set. If the field is not set during serialization or deserialization, the protobuf library throws an error.
This can cause problems if you define a required field early on, but in a later version you want to remove it, because older code will expect the field to always be there. To ensure compatibility, Google no longer supports the required qualifier in the latest version of protobuf (protobuf 3).
Try to use small integers
Varints encoding for numbers up to 127 only takes 2 bytes, 1 byte for the tag and 1 byte for the value, which is good for compression. But if you want to represent a very big number like 1<<31 - 1, you need 5 bytes excluding tag, which is 1 byte more than normal int 32, because protobuf has an identifier in the highest bit of each byte which takes up 1 bit.
If you need to transmit negative numbers, try sint32 or sint64
Because negative numbers have a sign bit of 1, and Varints encodes negative numbers as 64-bit unsigned if they are 32-bit signed numbers. So Varints encodes negative numbers with a constant total of 11 bytes, one byte for the tag and 10 bytes for the value.
The sint32 and sint64 maps all integers to unsigned integers and then encodes them with varint encoding, which saves some space.
Ref
https://www.luozhiyun.com/archives/800https://sunyunqiang.com/blog/protobuf_encode/https://halfrost.com/protobuf_encode/- h
ttps://protobuf.dev/programming-guides/encoding/ https://protobuf.dev/programming-guides/dos-donts/