Apache Parquet is a columnar storage format that can be used by any project in the Hadoop ecosystem.Parquet is language- and platform-agnostic.Parquet was originally developed and open-sourced in collaboration with Twitter and Cloudera, and graduated from Apache’s incubator as an Apache top-level project in May 2015 .
In the Spark project, Parquet is also its default data source. The default data source configuration can be modified via spark.sql.sources.default.
What is column-oriented Storage Format
In a relational database, the practical use of columnar storage is little different from row storage. Both column and row databases can use traditional database query languages, such as SQL, to load data and execute queries. Both row and column databases can be the backbone in a system, serving data for common extract, transform, load (ETL) and data visualization tools. However, by storing data in columns rather than rows, databases can access the data needed to answer queries more accurately, rather than scanning and discarding data in rows that are not needed.
For example, the following is a relational database management system providing data from a two-dimensional table representing columns and rows.
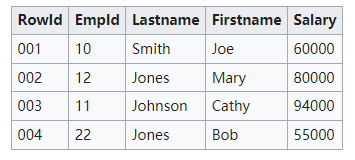
This two-dimensional format above is an abstraction. In practical implementations, the storage hardware requires data to be serialized into one form or another.
The most expensive operation involving the hard disk is searching. To improve overall performance, relevant data should be stored in such a way as to minimize the number of searches. This is called referential locality, and the basic concept appears in many different contexts. The hard disk is organized into a series of fixed-size blocks, usually large enough to store a few rows of a table. By organizing the table’s data so that rows fit into these blocks and grouping related rows onto sequential blocks, the number of blocks that need to be read or looked up, as well as the number of lookups, is minimized in many cases.
Row-oriented systems
A common way to store a table is to serialize each row of data, as follows.
When data is inserted into a table, it is assigned an internal ID, the Rowid used internally by the system to reference the data. in this case, the record has a sequential Rowid that is independent of the user-assigned Empid.
Row-oriented systems are designed to efficiently return data for an entire row or record with as few operations as possible. This matches a common use case where the system is trying to retrieve information about a specific object. By storing the record’s data with related records in a single block on disk, the system can retrieve records quickly with minimal disk operations.
Row-oriented systems are not as efficient at operating on whole-table collections compared to a small number of specific records. For example, in order to find all records in the example table with salaries between 40,000 and 50,000, the DBMS must completely scan the entire table for matching records. While the example table shown above may be suitable for a single disk block, even tables with several hundred rows are not, and multiple disk operations are required to retrieve the data and examine it.
To improve the performance of such operations (which are very common and often the point of using a DBMS), most DBMSs support the use of database indexes that store all the values of a set of columns along with a Rowid pointer back to the original table. The index on the payroll column is shown below.
Because indexes store only a single piece of data, not an entire row, they are typically much smaller than the main table storage. Scanning this smaller set of data can reduce the number of disk operations. If an index is used heavily, it can significantly reduce the time spent on common operations. However, maintaining indexes can add overhead to the system, especially when new data is written to the database. Not only do records need to be stored in the main table, but any additional indexes must also be updated.
The main reason indexes significantly improve performance on large data sets is that database indexes on one or more columns are usually sorted by value, which makes range query operations (such as the “Find all records with salaries between 40,000 and 50,000” example above) very fast (low time complexity).
Many row-oriented databases are designed to fit perfectly into RAM, which is an in-memory database. These systems do not rely on disk operations and have equal time access to the entire data set. This reduces the need for indexes, since for typical aggregation purposes it requires the same number of operations to fully scan the raw data as a complete index. As a result, such systems may be simpler and smaller, but can only manage databases that fit in memory.
Column-oriented systems
A column-oriented database serializes all the values of a column together, then serializes the values of the next column together, and so on. For our example table, the data would be stored in this manner.
Any of the above columns match more closely the structure of the indexes in a row-oriented system. This can lead to confusion, leading to the false belief that column-oriented storage is “really just” row storage with indexes on each column. However, the mapping of data is very different. In a row-oriented indexing system, the primary key is the Rowid mapped from the indexed data, while in a column-oriented system, the primary key is the data mapped from the Rowid. Let’s understand the difference from an example where the two “Jones” data items above are compressed into one data item with two Rowid’s.
|
|
Whether a column-oriented system will be more efficient in operation depends to a large extent on the automation workload. The operation to retrieve all data for a given object (the entire row) is slower. Row-oriented systems can retrieve rows in a single disk read, whereas collecting data from a columnar database requires a large number of disk operations. However, these whole-row operations are usually rare. In most cases, only a limited subset of data is retrieved. For example, in an address book application, it is much more common to collect names from many rows to build a list of contacts than to read all the data. This is more true for writing data to a database, especially if the data tends to be “sparse” with many optional columns. Thus, despite the many theoretical drawbacks, columnar storage exhibits excellent real-world performance.
In row storage, multiple columns of a row are written together consecutively, while in column storage, data is stored separately by column. Since the data types in the same column are the same, further storage space can be saved using more efficient compression coding.
Choose row or column oriented
Partitions, indexes, caches, views, OLAP multidimensional datasets, and transactional systems such as pre-written logging or multi-version concurrency control can significantly affect the physical organization of either system. This means that online transaction processing (OLTP)-centric RDBMS systems are more row-oriented, while online analytical processing (OLAP)-centric systems are a balance of row-oriented and column-oriented.
Background of the creation of Parquet
Parquet is inspired by the Dremel paper (Dremel: Interactive Analysis of Web-Scale Datasets) published by Google in 2010, which introduces a storage format that supports nested structures and uses columnar storage to improve query performance. The Dremel paper also describes how Google uses this storage format to achieve parallel queries, if interested in this can refer to the paper and open source implementation of Apache Drill (https://drill.apache.org/).
Parquet file format
Parquet files are stored in binary format, so they are not directly readable. The file includes the data and metadata of that file, so Parquet format files are self-resolving. There are several concepts in HDFS file system and Parquet files as follows.
- HDFS Block: It is the smallest copy unit on HDFS. HDFS stores a block in a local file and maintains multiple copies scattered on different machines, usually the size of a block is 256M, 512M, etc.
- HDFS File: An HDFS file, including data and metadata, which is stored in multiple blocks.
- Row Group (Row Group): according to the line will be physically divided into multiple units of data, each row group contains a certain number of lines, at least one row group is stored in an HDFS file, Parquet read and write will cache the entire row group in memory, so if the size of each row group is determined by the memory of the large small, for example, records occupy less space Schema can store more lines in each row group.
- Column Chunk: Each column in a row group is stored in a column chunk, and all the columns in the row group are stored in this row group file continuously. The values in a column chunk are of the same type, and different column chunks may use different algorithms for compression.
- Page: Each column block is divided into multiple pages, a page is the smallest encoding unit, different pages in the same column block may use different encoding methods.
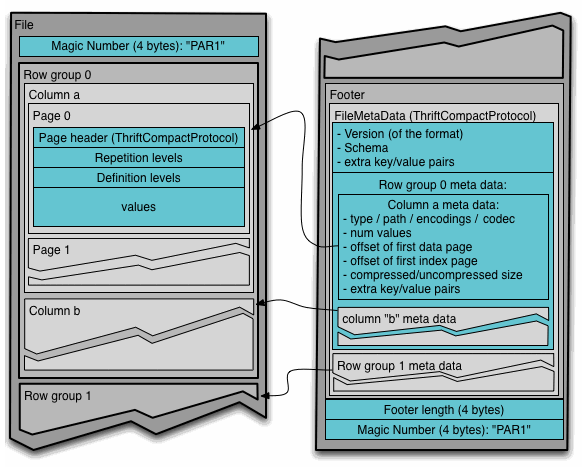
The content of a Parquet file consists of three parts: Header, Data Block and Footer. Header is the Magic Number at the beginning and the end of the file.
Data Block is a specific area for storing data, consisting of multiple Row Groups, each of which contains a batch of data. For example, suppose a file has 1000 rows of data, which is divided into two Row Groups of 500 rows each according to the corresponding size. In each Row Group, the data is stored in columns, and all the data in each column is combined into a Column Chunk, so a Row Group consists of multiple Column Chunks, and the number of Column Chunks is equal to the number of columns. The purpose of this layer-by-layer design is to.
- Multiple Row Groups can achieve parallel loading of data
- Different Column Chunk is used to achieve column storage
- further partitioning into Pages to achieve more fine-grained data access
The Footer section consists of File Metadata, Footer Length and Magic Number. The File Metada contains very important information, including Schema and Metadata of each Row Group, which is composed of Metadata of each Column, and each Column Metadata contains its Encoding, Offset, Statistic information, etc. Statistic information, etc.
Normally, when storing Parquet data, the size of the row group is set according to the Block size. Since the smallest unit of data processed by each Mapper task is one Block in general, this allows each row group to be processed by one Mapper task, increasing the task execution parallelism.
The format of the Parquet file is shown in the following figure.
Reference https://waylau.com/about-apache-parquet/