On August 10, local time, artificial intelligence research company OpenAI announced that its AI encoder Codex has been upgraded and launched internal testing. The biggest highlight of Codex is understood to be its ability to translate English directly into code.
In the Codex Demo, OpenAI shows how the software can build simple websites and basic games using natural language, and how it can flexibly translate between different programming languages and even handle data science queries.
That is, users can simply enter English commands into the software, such as “create a web page with a menu on the side and a title at the top,” and Codex will translate them into code.
Greg Brockman, CTO and co-founder of OpenAI, said in an interview, “We think this is going to be an important tool that will amplify the power of programmers. Programming is divided into two main problems, the first of which is thinking carefully about the problem and trying to understand it, and the second of which is mapping those little pieces to existing code, including libraries, functions, and APIs.” In his view, this second problem is tedious, but it’s exactly what Codex is good at. “It’s come along and taken a lot of the headache and drudgery out of professional programmers’ hands.”
OpenAI is quite confident in Codex’s potential to change the way programming and computing are done across the board; Brockman sees the emergence of Codex as promising a solution to the shortage of programmers within the U.S., while Codex project leader Wojciech Zaremba sees it as the next stage in the evolution of coding history.
In late June, Microsoft, OpenAI, and GitHub jointly produced Copilot, an automated code-generation AI that provides suggestions for completing lines of code at any time during the user’s input. Compared with Copilot, Codex has more obvious advantages, as it can not only complete the code, but also generate new code.
However, there are still some problems with Codex, such as it requires a certain degree of patience to produce results, because sometimes Codex does not understand the user’s instructions.
How does Codex feel in practice?
As exciting as Codex sounds, it’s still hard to judge the full scope of its capabilities until it’s put to the actual test by a wide range of programmers.
According to TheVerge, Brockman and Zaremba demonstrated Codex online, created a simple website with Codex, and developed a base game.
In the game demo, Brockman first found a portrait silhouette on Google Photos, then asked Codex to “add a portrait to the page” and then pasted the URL. “command, and then Brockman set up position control with the “Use left and right arrow keys to control image position” command.
The process was so silky smooth that the portrait began to wiggle around on the screen, but soon encountered a new problem: the image would slip off the screen and disappear completely. To stop this, Brockman gave the computer an additional command to “double-check that the portrait is not sticking out of the page, and if it is, put the image back in the page.” This does keep the image from sticking out of the page. This means, however, that for more complex functions, the specification must be very precise to avoid errors.
Although the image is back on the page, Codex also changes the width of the image so that the silhouette is squashed on the screen, and Brockman and Zermba can’t explain why Codex does this, saying, “Sometimes Codex doesn’t quite understand the user’s instructions. " He tried a few more times and finally figured out a way to get the image neither out of the screen nor distorted.
The whole demonstration worked well, but it also revealed the program’s limitations. Currently, Codex has no way to read humans directly and translate each command into perfect code. Instead, it takes a lot of thought and trial and error to get it to work properly.
In other words, Codex cannot turn amateurs into professional programmers overnight, but it does have a lower barrier to use than other programming languages.
Using GPT-3 to create Codex
Codex is known to be based on OpenAI’s own language generation model, GPT-3, which was trained using a large amount of Internet material to have some text generation and parsing capabilities.
Earlier, OpenAI researchers revealed details of Codex in a paper explaining how OpenAI scientists managed to reuse their flagship language model GPT-3 to create Codex.
The “no free lunch” theorem
Codex is the next generation of GPT-3. In general, the learning power of a model increases with the number of parameters. 175 billion parameters, two orders of magnitude more than its predecessor GPT-2 (1.5 billion parameters), and a training dataset of over 600GB, more than 50 times larger than the GPT-2 training dataset.
In addition to the increase in size, the main innovation of GPT-3 is “new-shot learning,” the ability to perform untrained tasks.
According to the new OpenAI paper, none of the various versions of GPT-3 can solve the encoding problem used to evaluate Codex. That is, GPT-3 has no coded samples in its training dataset, and we cannot expect it to be able to encode.
However, OpenAI scientists also tested GPT-J, a model with 6 billion parameters trained on the Pile, an 800GB dataset that includes 95GB of GitHub and 32GB of StackExchange data. GPT-J solved 11.4% of the coding problem. codex is Codex is a version of GPT-3 with 12 billion parameters, fine-tuned on the 159GB GitHub code example to solve 28.8% of the problem. another version of Codex, Codex- s, was optimized with supervised learning to improve performance to 37.7% (all other GPT and Codex models were trained with unsupervised learning).
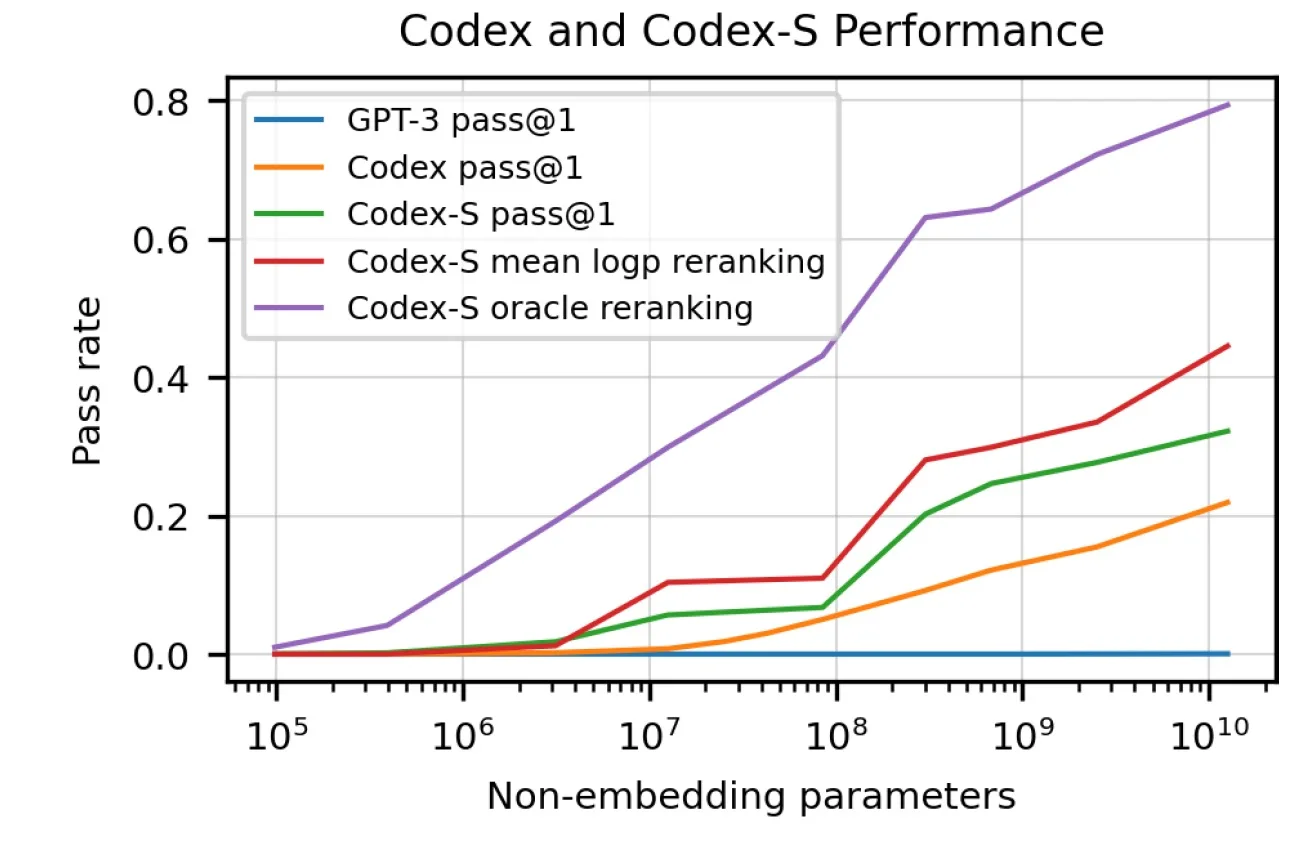
Codex demonstrates that machine learning is still subject to the No Free Lunch Theorem (NFL), which means that generalization comes at the expense of performance. In other words, machine learning models are more accurate when they are designed to solve a specific problem; on the other hand, their performance decreases when their problem domain is expanded.
Codex can perform a specialized task (converting functional descriptions and signatures into source code) with high accuracy at the cost of poor natural language processing power. On the other hand, GPT-3 is a general-purpose language model that can generate decent text on many topics (including complex programming concepts), but cannot write a single line of code.
Generating and understanding code
In their paper, the OpenAI scientists say that Codex is “inefficient in training samples” and that “even experienced developers do not encounter this much code in their careers.
They further add that “a good student who has completed an introductory computer science course is expected to be able to solve a much larger percentage of problems than Codex-12B.” “We sample tokens from Codex until we encounter one of the following stop sequences: ’ \nclass ‘, ’ \ndef ‘, ’ \n# ‘, ’ \nif ‘, or ’ \nprint ‘, because the model will continue to generate other functions or statements.”
This means that Codex will blindly continue to generate code even though it has already completed the part that solves the problem described in the hint.
This scenario works very well when you want to solve simple problems that recur. But when you narrow down and try to write a large program to solve a problem that must be solved in multiple steps, the limitations of Codex become apparent.
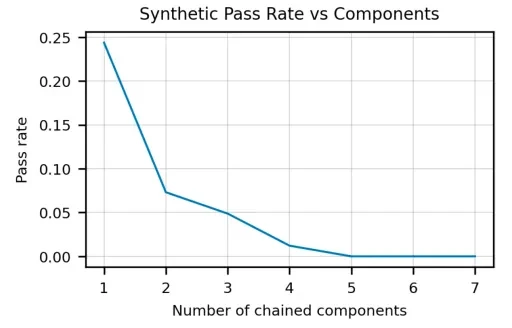
Scientists at OpenAI found that the performance of the model decreases exponentially as the number of components in the functional description increases.
In their paper, the researchers write, “This behavior is not characteristic of human programmers, and if a person can correctly execute a program for a chain of length 2, then he should be able to correctly execute a program for a chain of arbitrary length.”
The paper also further exposes Codex’s lack of understanding of program structure and code. “Codex can recommend syntactically incorrect or undefined code, and can call functions, variables, and properties that are undefined or out of the scope of the codebase.” In practice, this means that in some cases machine learning models will stitch together different pieces of code that they have seen before, even if they don’t fit together.
In the paper, the researchers also discuss the “misalignment” problem in Codex, where the model can solve a particular problem but can’t do so because of various errors. The researchers warn that if your code contains subtle errors, Codex may “deliberately” suggest that the code looks good on the surface, but is actually incorrect.
OpenAI scientists observe that in its current state, Codex “may reduce the cost of producing software somewhat by increasing programmer productivity,” but it will not replace other tasks that software developers often do, such as “consulting with colleagues, writing design specifications, and upgrading existing software stacks.”
Mistaking Codex for programmers can also lead to “over-reliance,” where programmers blindly approve any code generated by the model without modifying it. Given the obvious and subtle mistakes Codex can make, ignoring this threat can pose quality and security risks. “Safe use of code generation systems such as Codex requires human oversight and vigilance,” the OpenAI researchers warn in their paper.
It’s worth noting that if successful, Codex will not only be a great help to programmers, but also promises to be a whole new interface between users and computers.
OpenAI notes that their tests have determined that Codex can control not only Word, but also other programs such as Spotify and Google Calendar.
Brockman concluded that while the current Word demo is only a proof of concept, Microsoft has taken a keen interest in how Codex will perform. “In general, Microsoft is quite interested in this model, and there should be more Codex use cases for everyone to look at in the future.”