I am temporarily unemployed, so this article does not represent the views of any employer.
By 2021, most companies have decided to embrace cloud-native, but many programmers’ understanding of cloud-native is limited to “native k8s-based applications”. If a company goes to the cloud (k8s), it’s embracing cloud-native. Those with a little more understanding think that if we go to service mesh in addition to k8s, we are embracing cloud-native.
The cncf’s definition of cloud-native is in fact very complex.
Cloud-native technologies enable organisations to build and run elastic and scalable applications in new dynamic environments such as public, private and hybrid clouds. Representative cloud-native technologies include containers, service grids, microservices, immutable infrastructure and declarative APIs.
These technologies enable the construction of loosely coupled systems that are fault-tolerant, easy to manage and easy to observe. Combined with reliable automation, cloud-native technologies enable engineers to make frequent and predictable major changes to systems with ease.
The Cloud Native Computing Foundation (CNCF) is committed to fostering and maintaining a vendor-neutral, open source ecosystem to promote cloud-native technologies. We make these innovations available to the masses by democratising cutting-edge models.
The above description is taken from the cncf toc, which should be more authoritative.
The first article covers most of the infrastructure technologies involved in back-end development. It covers docker, service mesh, microservice, k8s and yaml-style declarative APIs.
In addition to the system design level, this principle also requires us to have platforms and tools that can support automated delivery, nowadays there are many open source CI/CD products, it is not difficult for a company to customize its own delivery pipeline based on open source products (jenkins, argo, etc.).
The third principle is vendor neutrality, which means that the infrastructure software within cncf can no longer be vendor-locked by users in the way that it used to be. With this principle in place, it will be very difficult for cloud vendors to kidnap users with special APIs as they did in the past.
Taken together, these three principles cover all of our daily development techniques and workflows, from development to delivery across the lifecycle. For the uninitiated, cloud-native outsider, it’s downright confusing - what are these guys trying to do?
For the purposes of this article, we’ll focus on just one thread, the architectural changes to the back-end business modules themselves.
Internet applications were cut from monoliths to microservices, solving the previous problem of everyone cramming into one warehouse to iterate and go live, leading to delivery bottlenecks. The splitting of services created many challenges for infrastructure, so previously almost every company had to build their own service frameworks, monitoring systems, link tracing, log collection, log retrieval and other systems that had little to do with the business.
In this process, a large number of infrastructure jobs were created, because these requirements were common to every company, and in the early days everyone had just switched to microservices architecture, and not every area had good open source products. So you had to do it yourself.
Microservices evangelists claim that with microservices split, everyone is loosely coupled based on APIs or domain events, and we can switch the language of our online services at will, based on domain characteristics or team strengths (since the logic of microservices is that each service has a small amount of code). This has led to many credulous companies using multiple languages internally to write their online services. For example, one company’s five languages and eight frameworks, or one company’s 197 RPC frameworks (emphasis, this is not a paragraph), are all absurd realities born during this period.
For example, if I want to support the retry routine I learned in the SRE book in a business framework, then as a developer in a framework group I need to write it in Go, write it in Java, write it in javascript, write it in C++, write it in PHP, write it in Rust and write it until I die suddenly.

The framework features in the diagram above are implemented for each language used in the company. If a problem is encountered (such as a 0day vulnerability in tls), it has to be fixed in the SDK for each language.
The framework upgrade is also a major problem in the company. According to one company, thousands of hours are spent on upgrading the framework throughout the year because of frequent vulnerabilities in one of the base libraries.
The service mesh solves this problem to some extent by moving the framework’s functionality out of the business process and into sidecar processes such as istio and envoy/mosn.
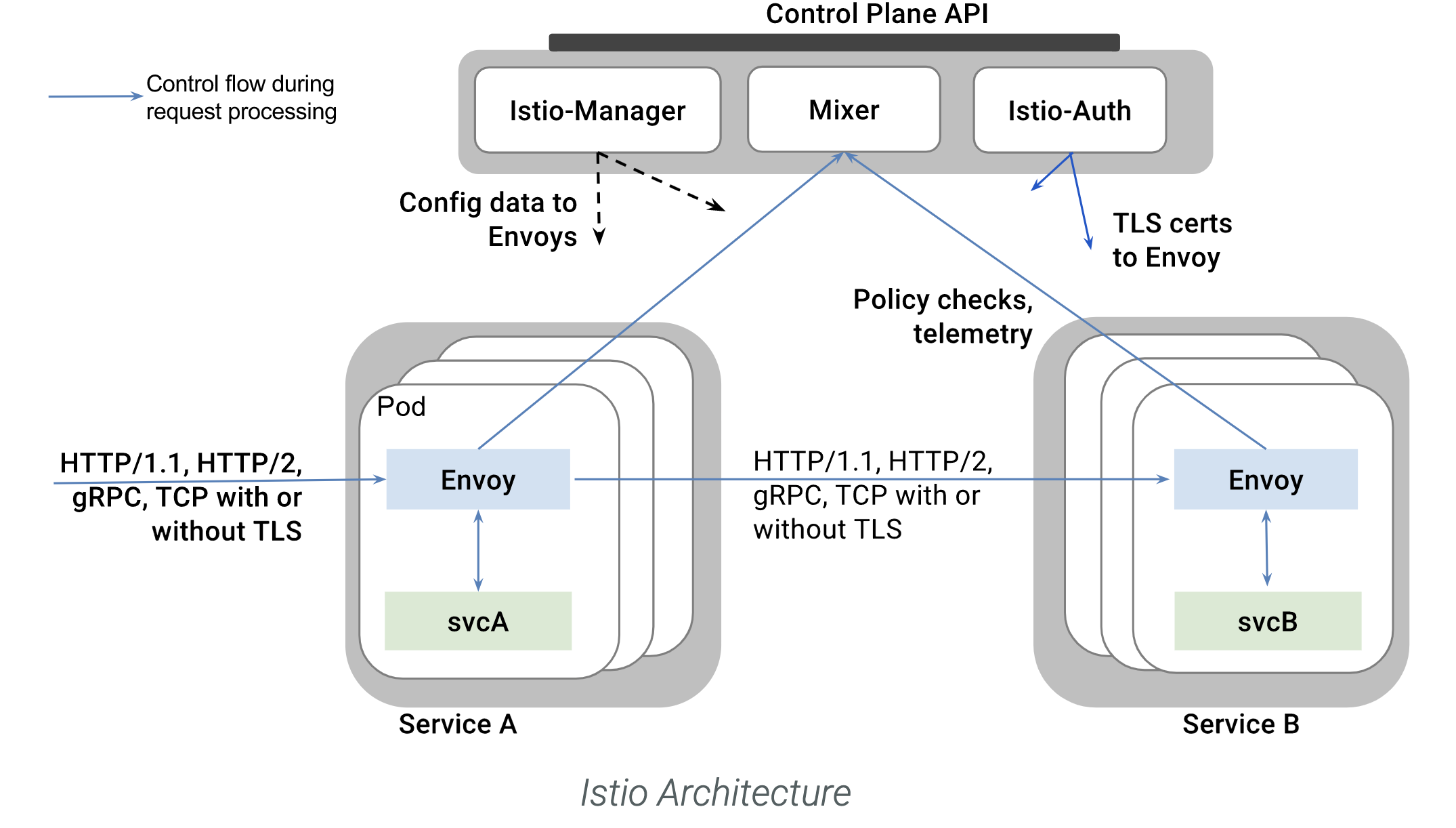
The control plane is responsible for managing and distributing the various configurations required by the data plane and ensuring the consistency of the configuration information; the data plane (envoy, mosn) is responsible for the forwarding of requests and everything related to stability.
The service mesh is designed for zero/low intrusion into the business and is accepted by some companies. With service mesh, flow limiting, degradation, fusing, retries, routing, encryption all become language-independent standard features within a company.
Because the data side of the service mesh works as a sidecar with different containers in the same pod as the business, the mesh and the business can be upgraded separately. Maintaining the mesh is similar to maintaining a project of your own, and can be done in a few days by following the company-wide project upgrade process.
The decentralisation of non-business functions reduces the workload at the framework level and, specifically for the framework group, there’s not as much to do for the in-company framework group.
While the sidecar format is widely accepted, we also need to be aware of the new wave of thinking that does not seek to be less intrusive on business modules, as seen in the multi runtime microservice architecture in 2020 runtime-microservice-architecture/), the authors distil the requirements for microservices into four areas of State, Binding, Networking, Lifecycle.
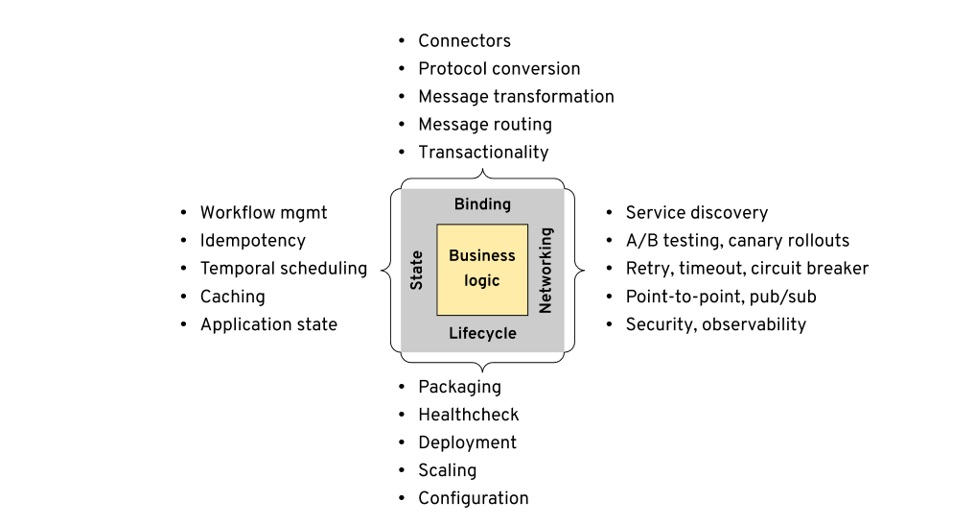
The Lifecycle has been taken over by k8s and CI/CD systems, and Networking has been well practiced in service mesh. Later on Dapr took the abstraction a step further and included Binding and State as well.
If we read the Dapr documentation, we will see that if we use Dapr, whether we are accessing MySQL/Redis, subscribing to publish messages, or communicating with external services. It communicates with them either as HTTP or gRPC.
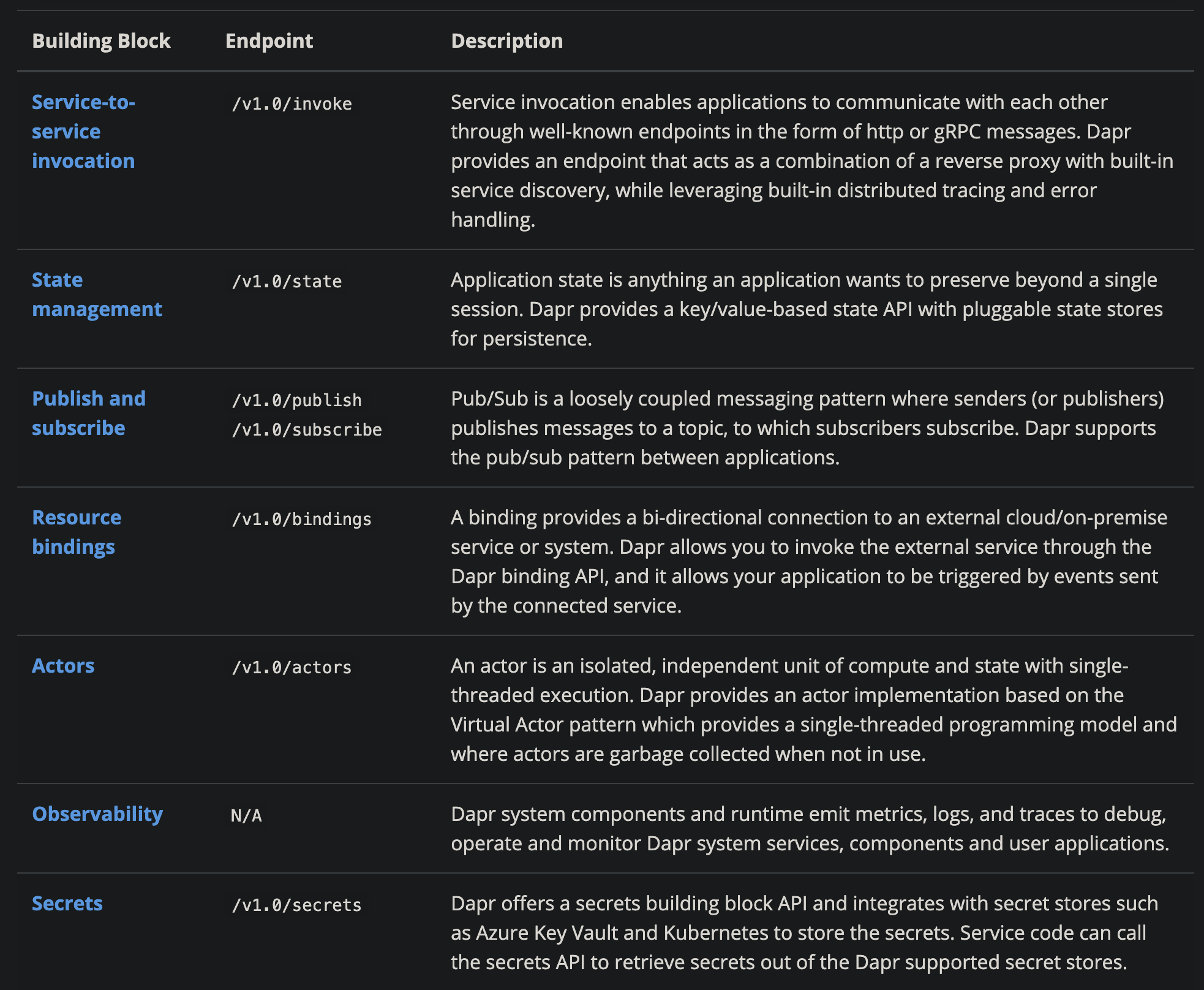
If this form of abstraction is accepted, the chances are that framework development jobs will simply disappear. Traffic replay functionality that would require all sorts of hacking in a big company is just a matter of adding a few if else in Dapr.
If you’ve read this far, I’m sure you’ve pretty much got it. The essence of cloud-native is decoupling the infrastructure from the business, and standardising the infrastructure itself.
If we want to learn about stability, we now don’t need to join a big company or read Google’s SRE - much of it is already implemented in standardised modules like service mesh, and we can figure it out by simply reading the code.
As engineers in a large company, we may pride ourselves on having built up a sound stability solution for a while, but much of our previous knowledge of high availability, high concurrency and high scalability will probably be devalued very quickly as cloud-native becomes generally accepted. Think carefully, does anyone take pride in the fact that they can recite a catalogue of Lego instructions?
The creation of the earlier k8s went some way to erasing the infrastructure gap between second tier companies and first tier companies, enabling each company to have self-healing failures and automatic scaling in a cost effective manner. For Internet companies, this has been a huge step forward in productivity. But this advancement actually eliminated a lot of traditional Ops positions, and some of those willing to learn and write code later moved to SREs to work on k8s and other infrastructure secondary development within the company. But the overall number of jobs must have been reduced.
The standardisation of service architectures today will further cut the size of framework developers across companies, and as the head software in each area within cncf solves the performance problems of mass deployment, it will probably be difficult for new entrants, software and related developers to have a good chance.
Reference https://xargin.com/cloud-native-and-future-of-developer/