MySQL Version: 5.7.18
Problem
Assuming that the field category is not indexed and has duplicate values, the combination of order by category and limit will not work as expected.
Scene Reproduction
Table structure (reproduce the problem, two fields are enough ~)
|
|
Sort all data by the category field: select * from ratings order by category ;
| id | category |
|---|---|
| 1 | 1 |
| 5 | 1 |
| 10 | 1 |
| 3 | 2 |
| 4 | 2 |
| 6 | 2 |
| 9 | 2 |
| 2 | 3 |
| 7 | 3 |
| 8 | 3 |
When we want to paginate the first 5 items use select * from ratings order by category limit 5 ;
The expected order of ID is 1 5 10 3 4.
But the actual result is as follows.
| id | category |
|---|---|
| 1 | 1 |
| 10 | 1 |
| 5 | 1 |
| 3 | 2 |
| 4 | 2 |
Maybe some friends have encountered this problem, through the search engine to solve a little, have you ever thought, you find the solution is the optimal solution? How did others arrive at this solution? MySQL Why would they do this, is it related to the version?
First throw the conclusion.
- The optimal solution is to add a sort field with a unique column value after it, such as:
order by category,id - Why does MySQL do this? The answer is for speed! (This optimization is available in
MySQL 5.6and later) - The suboptimal solution is to index the
categoryafterorder by(why is it suboptimal?). You will have the answer after reading this article)
Finding the optimal solution
The scenario is described in the MySQL documentation 8.2.1.19 LIMIT Query Optimization as follows.
If multiple rows have identical values in the
ORDER BYcolumns, the server is free to return those rows in any order, and may do so differently depending on the overall execution plan. In other words, the sort order of those rows is nondeterministic with respect to the nonordered columns.One factor that affects the execution plan is
LIMIT, so anORDER BYquery with and withoutLIMITmay return rows in different orders.
To summarize, when there are duplicate field values in the ORDER BY column, the order of the data returned by the ORDER BY statement will be different due to the presence of LIMIT.
This is the default MySQL optimization for this scenario, but if you need to ensure that the order is consistent with or without LIMIT, there is an official way to do this.
If it is important to ensure the same row order with and without
LIMIT, include additional columns in theORDER BYclause to make the order deterministic.
This is where an additional sort field (such as an ID field) is added after ORDER BY.
The above description first appeared in the MySQL 5.6 documentation, and this optimization for ORDER BY LIMIT has been introduced since this version.
Well, for the scenario in the article, we just need select * from ratings order by category,id; to solve it.
So the question is, why did MySQL make such a seemingly buggy optimization?
MySQL’s ORDER BY Logic
ORDER BY is the sort.
Do an explain select * from ratings order by category limit 5 ;
|
|
You can see that Extra: Using filesort indicates that sorting is required.
Under normal circumstances, MySQL will have both in-memory and external sorting.
If the amount of data to be sorted is less than the sort buffer size, the sort is done in memory ( quick sort)
If the amount of data to be sorted is larger than the sort buffer size, the sort is done externally using a temporary file ( combine sort)
Obviously, these two kinds of sorting are to sort all the results, and reasonably, regardless of whether there is LIMIT or not, the number of items needed is taken from the sorted results in order, and whether there is LIMIT or not will not affect the order of the returned results.
However, MySQL 5.6 has a small optimization for ORDER BY LIMIT (when the sorted field is not indexed and the column value is not unique): the optimizer uses priority queue when it encounters an ORDER BY LIMIT statement.
The optimization is described by the following pseudo-code in filesort.cc.
|
|
The optimization logic is described in WL#1393: Optimizing filesort with small limit:
|
|
The result of the optimization is documented in the WorkLog: 10 to 20 times faster than a quicksort (for those interested, go read the original article).
So, it’s all about speed!
MySQL thinks this scenario is a TOP N problem, which can be solved by using priority queue.
priority queue
priority queue is actually a heap, Java has java.util.PriorityQueue class, the essence of which is heap this data structure.
A brief explanation of what a heap is.
A heap is a complete binary tree.
Each node in the heap must have a value greater than or equal to (big top heap) or less than or equal to (little top heap) the value of each node in its subtree.
If MySQL uses merge or fast-ranking, you need to sort all the data and then take the first few entries of LIMIT, and the remaining sorted data will be wasted.
If you use priority queue, you can maintain a heap based on the number of LIMIT items, and you only need to go through all the data in this heap to get the result.
You can verify that MySQL is using priority queue by using the following statement.
You can see that filesort_priority_queue_optimization.chosen = true.
Here is a flowchart to restore the execution logic of the priority queue (using LIMIT 5 as an example):
tip: the small top heap in the diagram is sorted by the size of the category value
-
Take the first five data items to form a small top stack.
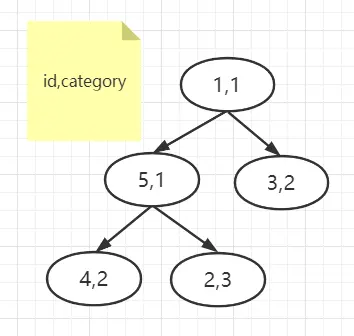
-
Take the next row of data (6,2) and find that 2 is smaller than the largest
category3 in the current heap, so delete (2,3) from the heap and add (6,2) to the heap.
-
Repeat step 2 until all the data that meet the query criteria have been compared into the heap, and the final data in the heap is as shown in the figure.
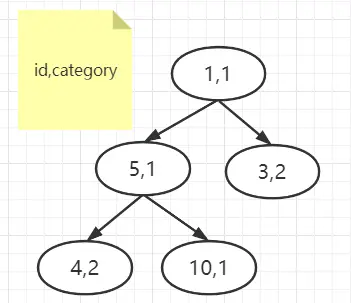
The above is the process of finding the smallest 5 rows of category data by priority queue.
Finally, we can get the result by taking it out of the heap and putting the last element into the top of the heap each time after the smallest element is taken out, and re-stacking it according to the small top heap.

As you can see, this result is consistent with the output of select * from ratings order by category limit 5;
Why indexing is a suboptimal solution
Obviously, according to the logic of ORDER BY, adding indexes to sorted fields directly can also eliminate the in-memory sorting step, thus solving the problem.
But indexing is not a silver bullet, and the extra category index will increase the maintenance cost of the table. If there is no obvious business need to add indexes simply to bypass the optimization of this priority queue, it is not worth the loss.
Especially when the table data volume is very large, the volume of indexes can be substantial. Moreover, for the scenario in the article, category as a category field, the duplication rate will be relatively high, even if there is a business SQL query by category, MySQL will not necessarily pick this index.
To sum up, I think order by category,id is the optimal solution for this scenario.