Business Background
A large number of messages are currently used in mobile usage scenarios. Push messages can help operators achieve operational goals more efficiently (such as pushing marketing campaigns to users or alerting new APP features).
For the push system needs to have the following two characteristics.
-
Messages are delivered to users in seconds with no latency, support for millions of pushes per second, and millions of long connections on a single machine.
-
Support for notifications, text, custom message transmissions and other forms of presentation. It is for these reasons that the development and maintenance of the system poses a challenge. The following figure is a brief description of the push system (API->Push Module->Mobile).
Problem Background
Push system in the long connection cluster in the stability test, stress test stage after running for a period of time sometimes a process will hang, the probability is small (frequency of about once a month), which will affect the timeliness of some client messages delivered.
The long connection node (Broker system) in the push system is based on Netty development, this node maintains a long connection between the server and the cell phone terminal, after the online problem, add Netty memory leak monitoring parameters to troubleshoot the problem, observe for many days but did not troubleshoot the problem.
Since the long connection node is developed by Netty, the following is a brief introduction of Netty for the reader’s understanding.
Introduction to Netty
Netty is a high-performance , asynchronous event-driven NIO framework , based on the API implementation provided by Java NIO . It provides support for TCP, UDP and file transfer. As the most popular NIO framework, Netty is widely used in the Internet field, big data distributed computing, the game industry, the communications industry, etc. Open source components such as HBase, Hadoop, Bees, Dubbo, etc. are also built on Netty’s NIO framework.
Problem Analysis
Guessing
Initially, I guessed that it was caused by the number of long connections, but after troubleshooting the logs and analyzing the code, I found that it was not caused by this reason.
The number of long connections: 390,000, as follows.

Each channel byte size 1456, based on 400,000 long connections, does not result in memory overload.
View GC Log
Checking the GC logs, I found that the process hangs before frequent full GC (frequency 5 minutes once), but the memory is not reduced, suspecting an off-heap memory leak.
Analyzing the heap memory situation
ChannelOutboundBuffer object accounts for nearly 5G memory, the cause of the leak can basically be determined: ChannelOutboundBuffer entry number is too much caused by viewing the source code of ChannelOutboundBuffer can be analyzed, is the data in ChannelOutboundBuffer.
Not written out, resulting in a backlog all the time.
ChannelOutboundBuffer internal is a linked table structure.

Analysis of the data from the chart above is not written out, why does this happen?
The code actually has a determination of whether the connection is available or not (Channel.isActive) and will close the connection for timeouts. From historical experience, this happens more often when the connection is half open (abnormally closed by the client) - both sides do not communicate data without problems.
The test environment is reproduced and tested as guessed above.
-
Simulate a client cluster and establish a connection with a long-connected server, set the firewall of the client node, and simulate a scenario where the server and client networks are abnormal (i.e., to simulate a situation where the Channel.isActive call is successful, but the data is not actually sent out).
-
Tune down the out-of-heap memory and keep sending test messages to the previous client. Message size (1K or so).
-
Based on 128M memory, it actually comes up with 9W multiple calls.

Problem Solving
Enable autoRead mechanism
Turn off autoRead when the channel is not writable.
|
|
Enable autoRead when data is writable.
|
|
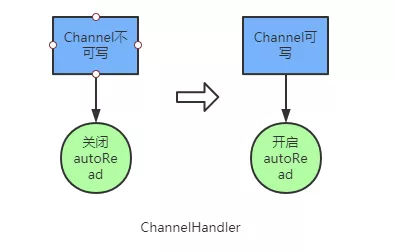
The purpose of autoRead is more precise rate control, and Netty will register read events for us if it is turned on. When the read event is registered, Netty will read the data from the channel if the network is readable. If autoread is turned off, then Netty will not register read events.
This way, even if the other side sends data over, the read event will not be triggered and thus no data will be read from the channel. When the recv_buffer is full, no more data will be received.
Set high and low water level
|
|
High and low water levels are used in conjunction with isWritable later
Add the channel.isWritable() judgment
isActive() also needs to be added to channel.isWrite() to determine if the channel is available. isActive only ensures that the connection is active, while isWrite determines if the connection is writable.
|
|
isWritable can be used to control the ChannelOutboundBuffer from expanding indefinitely. The mechanism is to use the set channel high and low water levels to make a determination.
Question Validation
Modified and then tested and sent to 27W times without reporting an error.

Analysis of solution ideas
The general Netty data processing flow is as follows: the read data is handed over to the business thread for processing and then sent out (the whole process is asynchronous), Netty adds a ChannelOutboundBuffer between the business layer and the socket in order to improve the network throughput.
When channel.write is called, all the data written is not actually written to the socket, but to the ChannelOutboundBuffer first, and only when channel.flush is called is it actually written to the socket. Because there is a buffer in the middle, there is a rate match, and this buffer is still unbounded (chained), that is, if you do not control the speed of channel.write, there will be a lot of data piled up in this buffer, and if you encounter the socket can not write data (isActive judgment is invalid at this time) or write is slow.
The likely result is to run out of resources, and if the ChannelOutboundBuffer is a
DirectByteBuffer, this will make the problem even more difficult to troubleshoot.
The process can be abstracted as follows.
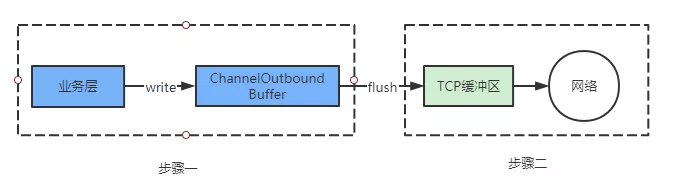
From the above analysis, we can see that step one is written too fast (too fast to process) or the data is not sent downstream can cause problems, which is actually a rate matching problem.
Netty source code description
Above high water level
When the capacity of ChannelOutboundBuffer exceeds the high water level setting threshold, isWritable() returns false, sets channelUnwritable, and triggers fireChannelWritabilityChanged().
|
|
Lower than low water level
When the capacity of ChannelOutboundBuffer falls below the low water level setting threshold, isWritable() returns true, setting the channel writable and triggering fireChannelWritabilityChanged().
|
|
Summary
When the capacity of ChannelOutboundBuffer exceeds the high water level setting threshold, isWritable() returns false, indicating that the messages are creating a buildup and the write speed needs to be reduced.
When the capacity of ChannelOutboundBuffer is below the low water level threshold, isWritable() returns true, indicating that there are too few messages and the write speed needs to be increased. After the above three steps were modified, the problem was observed on the deployment line for six months without occurrence.