Righting software is a book published by Pearson in 2020 by Juval Löwy, and it was introduced in China this year.
I finished reading the part of the book that I cared about during the mid-autumn festival, and this article extracts some core ideas from it.
The author first summed up his decades of experience (first expressing his envy), and proposed a reliable software design method, called The Method (translated into Chinese as meta-method).
The Method = System Design + Project Design
The book is also divided into these two parts, System Design and Project Design.
First of all, Project Design, which is actually project planning, this part of most companies in project management training have science, is to split the project work tasks, draw a network diagram, find the critical path of iteration, and allocate different development resources for different stages. Take a look at this diagram and you’ll basically understand.
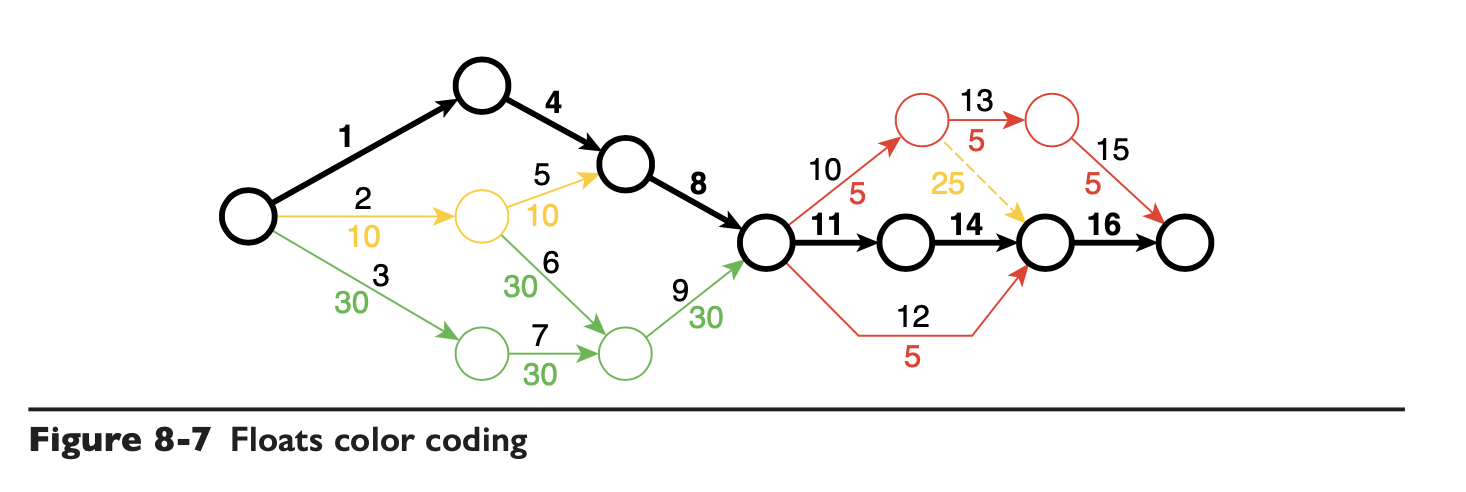
Although the authors also put project management within the responsibilities of the architect, but these things are generally the project manager to do (many projects into the middle and late stages, the daily iterations actually do not need to do any analysis, are heaps of well), the authors also did not put forward a bright point of view, this article will first ignore should not be much interest in this part, most of the company’s project management approach is also relatively sloppy, routine to do based on the network scheduling companies are very few and far between.
System Design is more important to us, the daily work of front-line software developers and architects will more or less involve a little design. The section on System Design is the first half of the book, and the Chinese version is 102 pages long, so it’s a quick read.
The microservice model is already the premise of the backend architecture model, and the most familiar view of microservice modeling is generally “function-based” or “domain-based” split microservices. The actual situation is that most front-line engineers are still clamoring for DDD, because the books on DDD are too hard to read. After that, I have the opportunity to write a popular article on DDD, it should not be so difficult.
This book is amazing, the author neither disagrees with splitting based on functionality nor domain splitting.
Why do you disagree with feature-based splitting?
Five reasons are given here.
Services are difficult to reuse
For example, if you split three services A, B, and C, they look like three separate services, but when executing B, you actually need the client to access A first to get the parameters needed by B. To access C, you need to get some parameters from B first .
So A, B, and C are not independent services, they are a set of services, and you can’t reuse any of them individually.
Excessive numbers or excessive size
We see this more in large companies, such as several large companies in China, the number of services are more than 10 w, like the scale of the people will be more happy to see these numbers . Some services are only a few thousand lines of code in total, to achieve a single function of simple logic.
There are also those who have not split, a single service of hundreds of thousands of lines ~ 100w lines of code, I have actually seen the service.
Client-side bloat coupling
The explosion in the number of services will make integration more difficult, and the client will become more complex as the number of services expands. The author doesn’t mention BFF here, but BFF doesn’t actually reduce the integration complexity, it just moves the part from client to BFF.
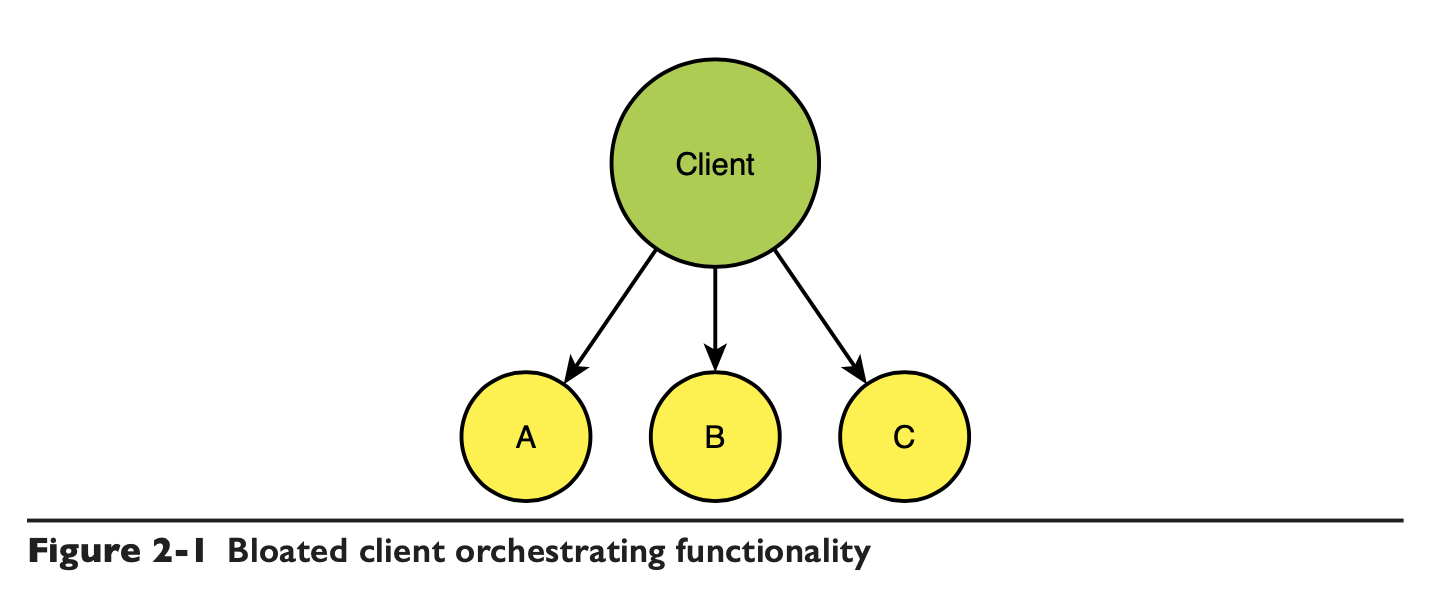
The following graph shows the combined statistics of the lap complexity on the client side of a system based on functional splitting, after a period of iteration.
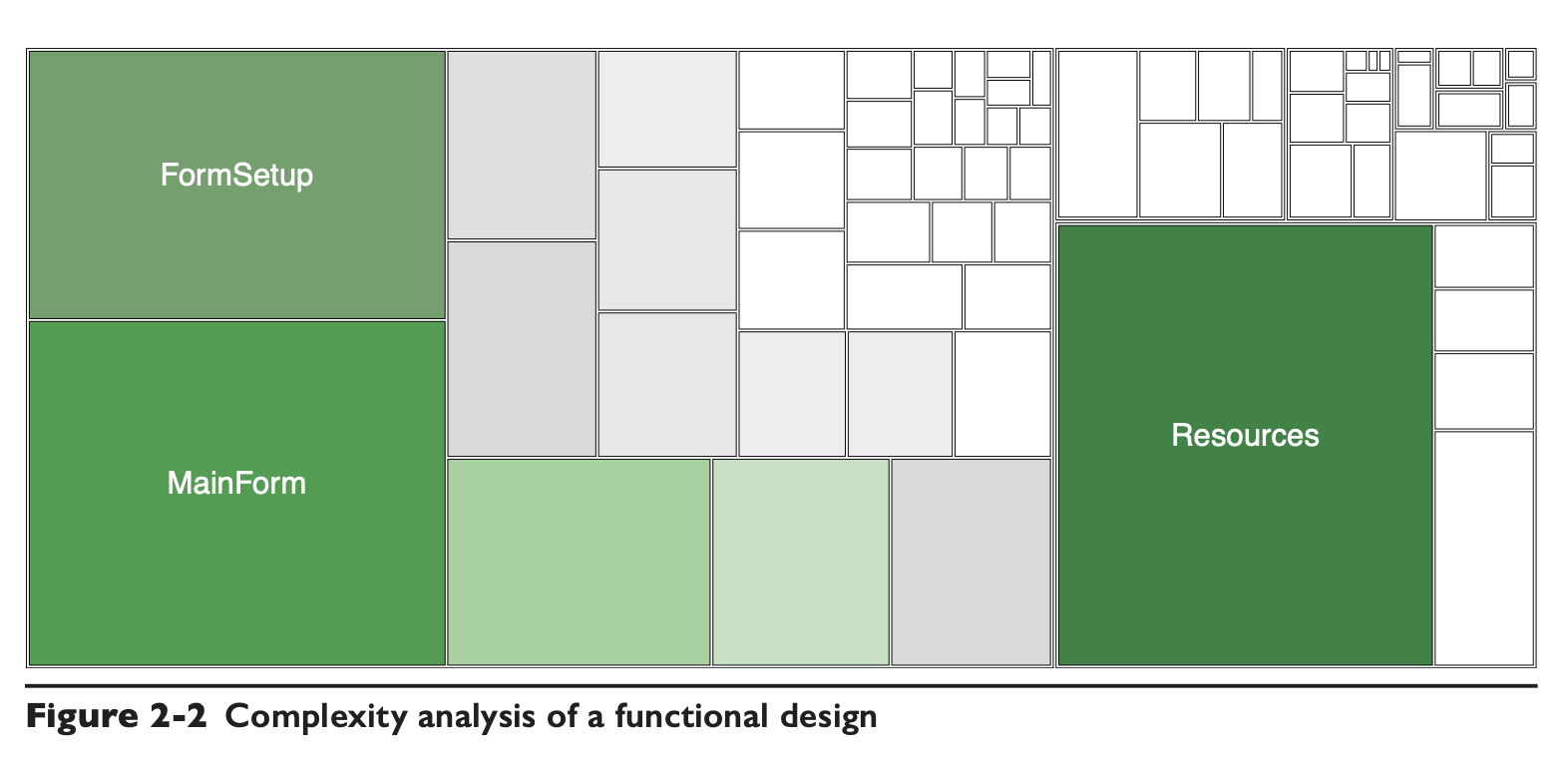
The complexity of the modules is extremely unevenly distributed and there are many components, the Resources module here becomes large because of the number of back-end services.
Logical redundancy due to high number of services
The above exposes many services directly to the client, resulting in the need for each service to integrate authentication, authorization, scalability, transaction propagation, and so on and so forth.
This article actually has a BFF will be fine.
Service bloat coupling
If you don’t want the client to access each service to implement the business, then you can have the client call only A, but A, B and C have to integrate themselves, such as this chain.
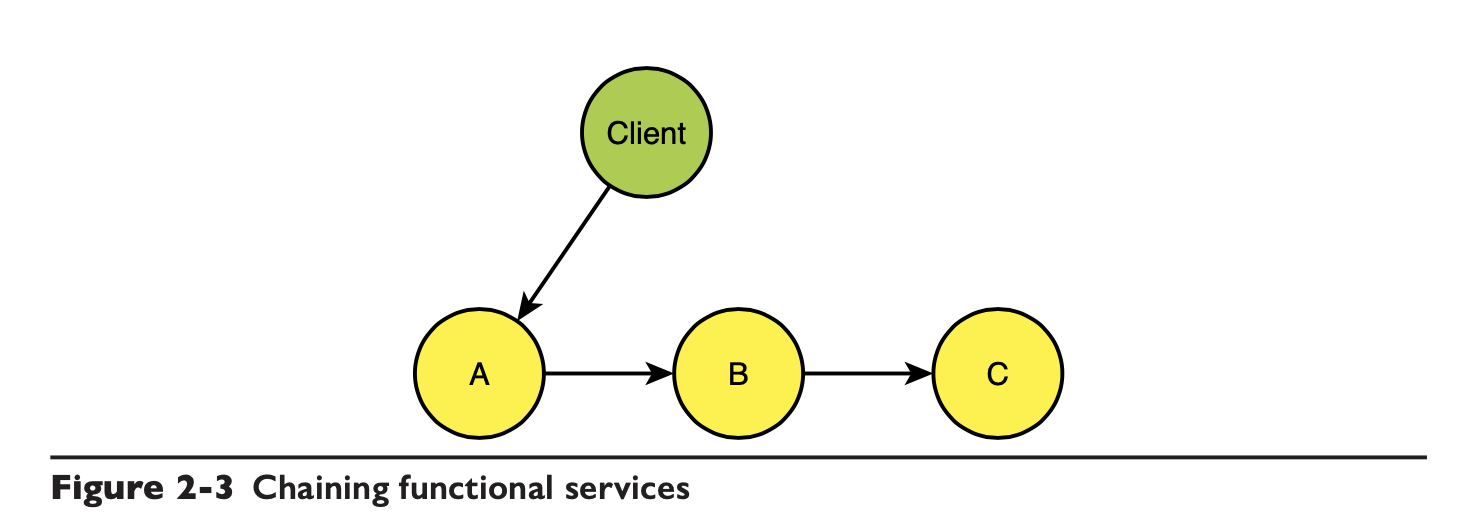
This actually allows A to fulfill the integration role, which needs to prepare all the parameters needed for subsequent services, and the complexity of the integration falls on A.
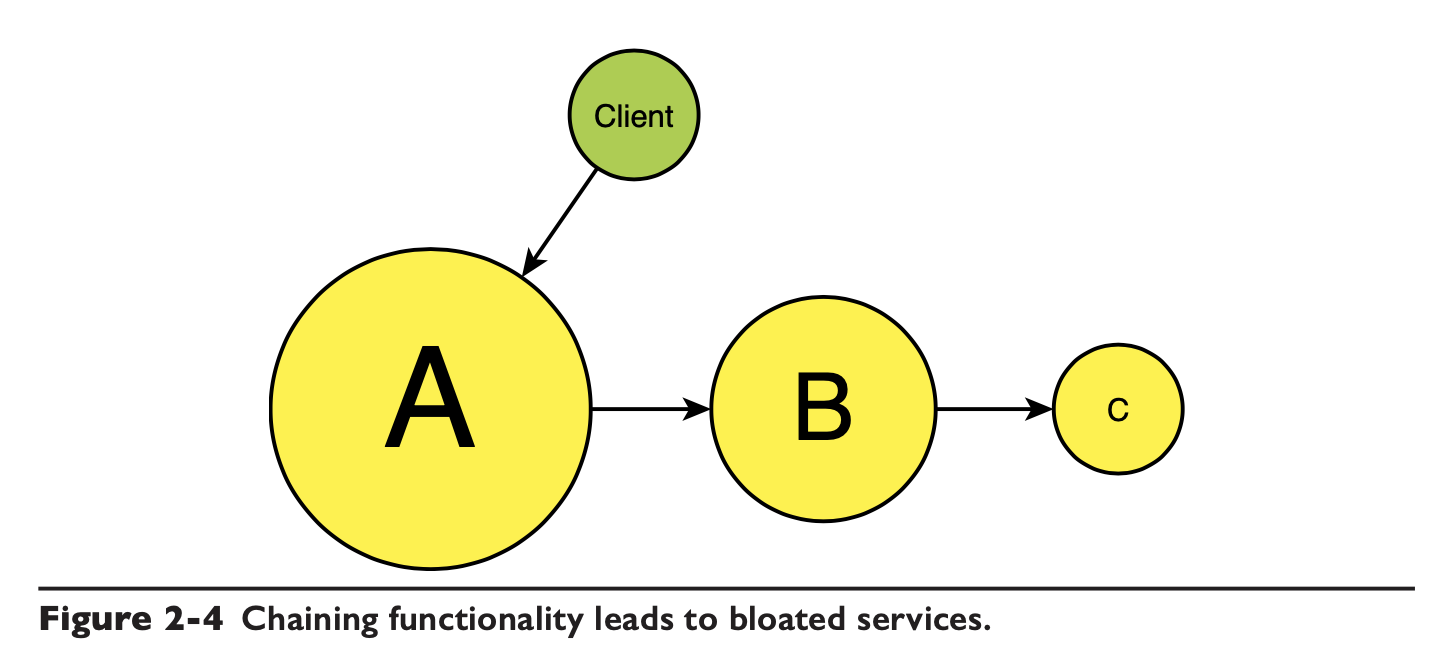
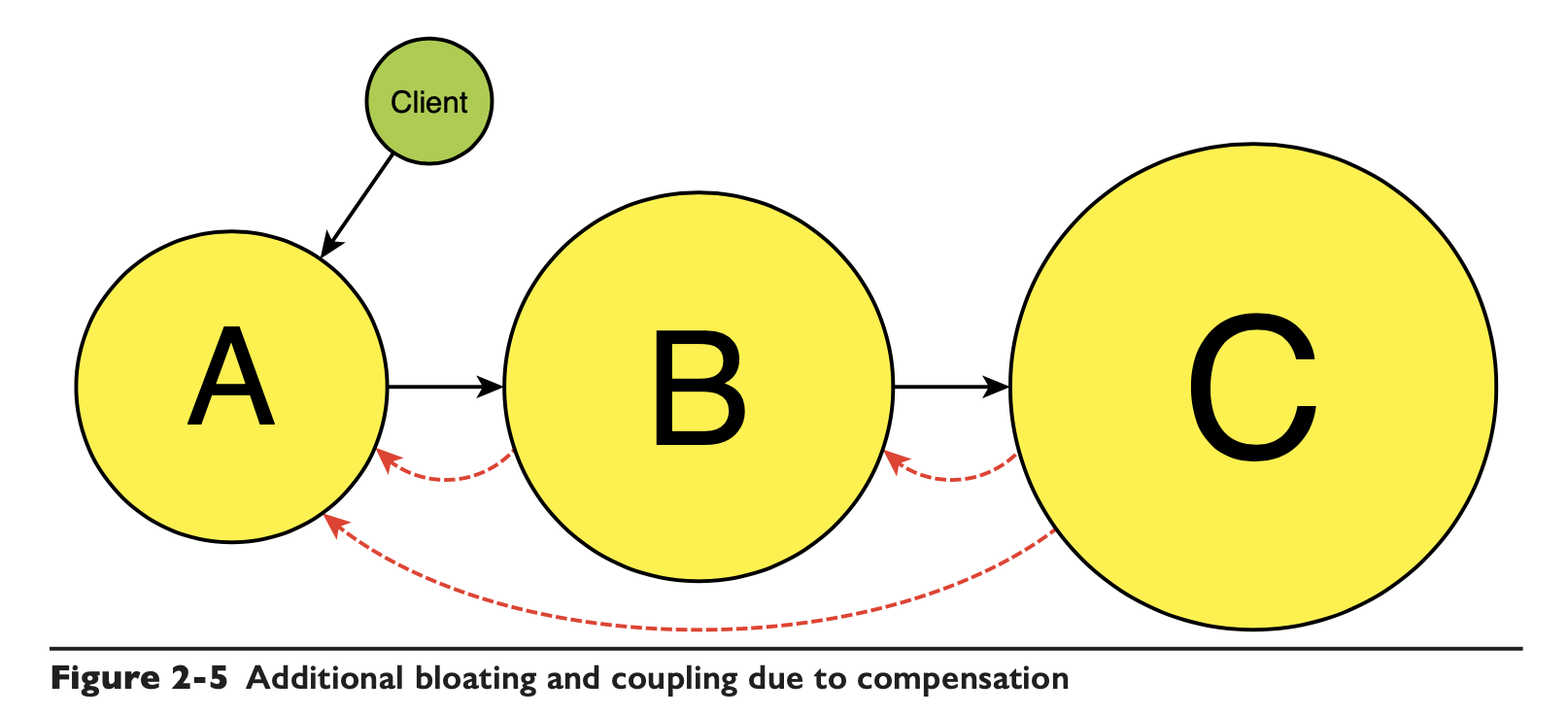
If a workflow, transactional nature of the business is involved, then perhaps C will also be concerned with whether or not to call back for logical compensation when the process in A and B fails to execute.
The author gives another real-life example that if we were to build a house from the point of view of its function, then maybe the house would end up looking like this.
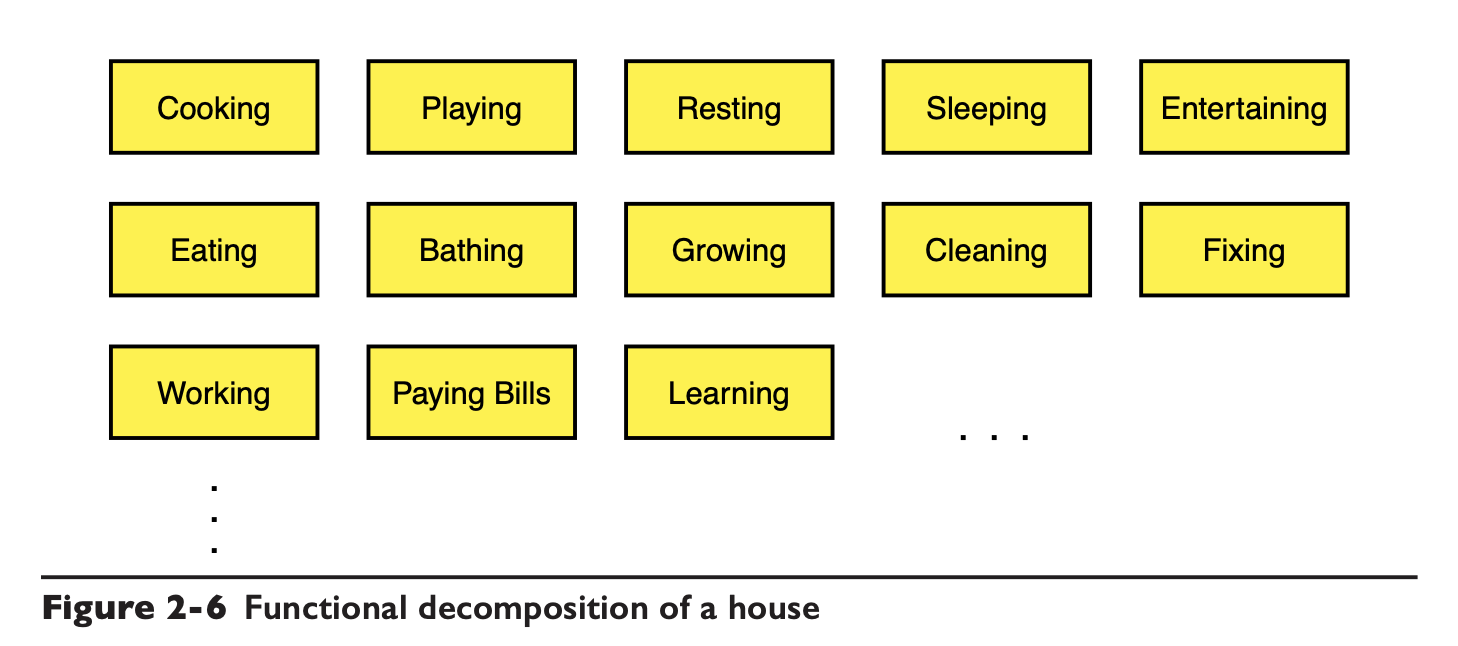
Create a module for each functional requirement. Just compare the real-world house design with the diagram here to see how ridiculous this design is.
Why do you disagree with domain splitting?
Still the example of the house, if split by domain, then the probability will be divided into the following structure.
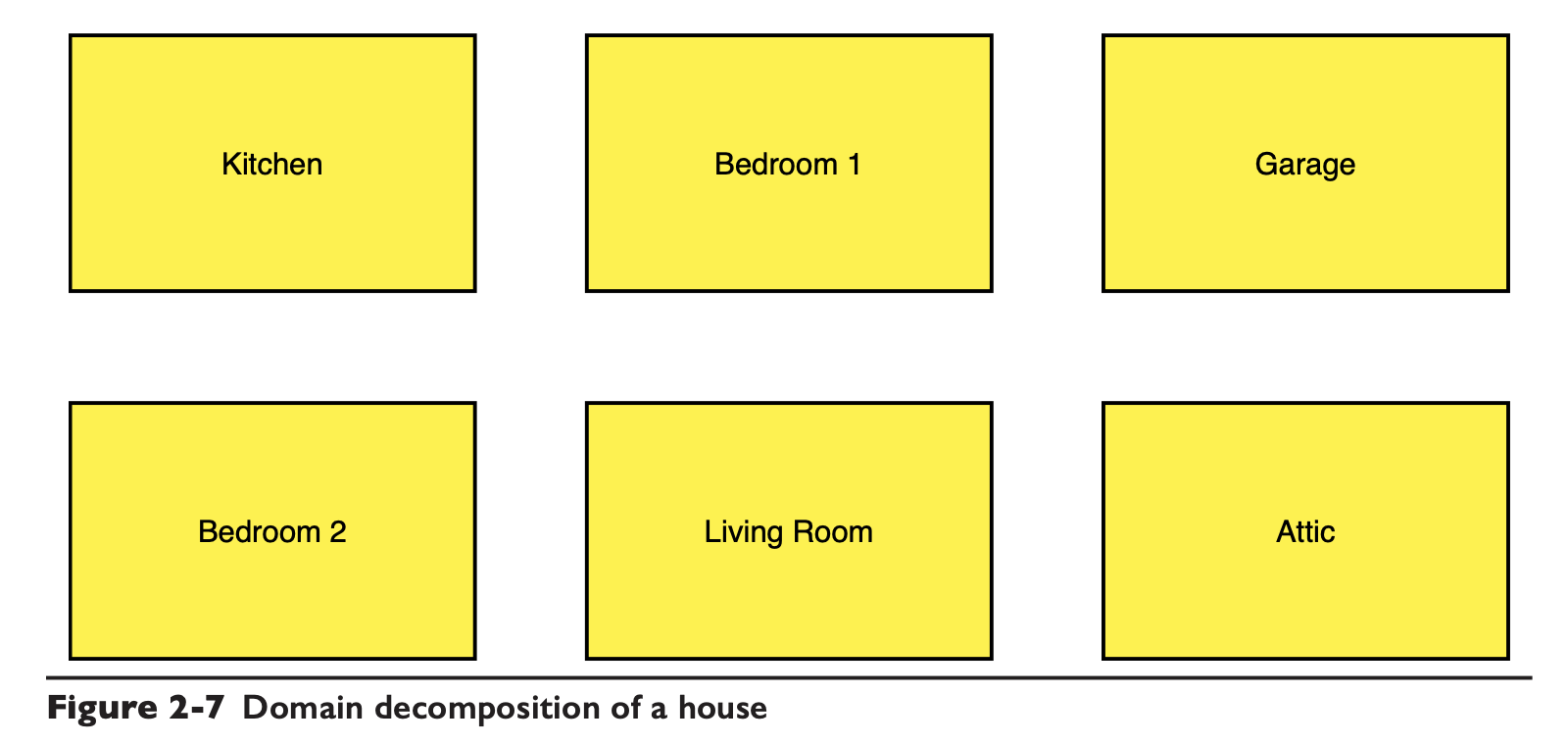
The authors argue that if we were to implement sleep as a function under such modeling, then we would need to implement it all over again in each domain . (Here I actually think the analogy with software domains is slightly far-fetched)
The domain itself cannot operate independently, and to deliver it must be delivered in its entirety, so if you start with domain modeling, it will result in part of the domain being rebuilt over and over again . For example, if you get the kitchen done first, and later on when you do other modules, you find that there is a problem with the drain, then the kitchen needs to be torn down and rebuilt. And then later found that the electrical wiring problems, again need to tear down and rebuild. This will produce a lot of waste of resources, and this waste is hidden (this makes sense, if it is a relatively large project, the development phase of a few modules because of integration problems, repeatedly rework is indeed very common).
In addition ** unit testing in the field is basically useless, business requirements are the result of the joint action of different areas, even if a certain area of unit testing 100% pass**, ** can not guarantee that the business logic can run properly **. (Another point of view not quite the same as the conventional idea)
Volatility-based decomposition
The 6-page paper criteria for modularization by David Parnas in 1972 already contains most of the elements of modern software engineering, including encapsulation, information hiding, cohesion, modules, and loose coupling. This article points out that finding points of change is the key criterion for decomposition, and that functionality itself is not the key criterion for decomposition.
This is also the core point of the book “righting software”, a decomposition based on volatility (volatility). There is also a counter-intuitive point here: our architecture should not be designed according to requirements, because requirements are generally requirements for functionality, and following a step-by-step approach will only produce a “function-based decomposition” of the system.
Consider volatility from two perspectives.
- the requirements of the same customer, which change over time
- the difference between the needs of different customers at the same moment
In the book, these two aspects are called two separate axes, but I personally think it is more appropriate to say that the impact of time and space may be more appropriate ~
For example, the following is the same house over time, may produce changes in some elements, the

Furniture gets old to be replaced, appliances get old to be replaced, subsequent sale to someone else if the owner wants to change, one day the owner is unhappy may want to paint a wall appearance will change, and so on.
The following are the possible differences between different houses at the same moment.

As in the case of the fickleness of the housing structure, the neighbors of different houses are certainly different, and different houses may be in different cities.
Any kind of fallibility can be classified into the first aspect (time) or the second aspect (space), and we analyze the project according to these two aspects (or axes). If not, then encapsulate that fallibility into module B; and then perhaps go on to ask ourselves, at the same moment, do all users have access to the same B? If not, then you need to continue to encapsulate that variability, forming A, B, C.

When you receive the list of requirements, you should also note that some requirements describe not a requirement, but a solution, such as cooking is not a requirement, eating is a requirement, cooking is just a solution, when doing variability analysis to convert these solutions, to find the root cause of the requirements, in order to analyze the variability to , such as cooking will be encapsulated into the eating component, the component is responsible for handling a variety of variability in eating (you can also not cook yourself, order take-out well).
The project design phase should list all the future variability of the project, such as a trading system, which has the following variability
- user volatility
- Client program variability
- Security volatility
- Notification volatility
- Storage volatility
- Connection and synchronization variability
- Duration and Device Volatility
- Transaction Item Variability
- Workflow Variability
- Regional and Regulatory Volatility
- Market information source variability
Once you have the variables, you can design the system based on these variables, making sure that each variability is encapsulated in a module as much as possible, such as the structure given in the book.

When designing the architecture, pay attention to the nature of the business itself is not supposed to be encapsulated , for example, you are engaged in the taxi business, you still want to do a set of microblogging in the same architecture, this is unlikely, the cost of iterating on the old architecture may be higher than the new set of all. The book also gives two criteria to judge.
- If a change is extremely rare and has a low probability of occurring, then it does not necessarily have to be encapsulated
- If the attempt to encapsulate the change has a huge economic cost (that is, you design a system that costs the company a lot of money), then it should not be encapsulated either
Be a little more specific
The example structure given earlier is a very typical hierarchy given in this book.

It goes without saying that the client, the business logic layer is divided into Manager and Engine layer, Manager is responsible for managing the process class volatility, Engine is responsible for the volatility of an activity node itself.
Process variability is well understood, that is, workflow (the author of this book should have a connection with the early WCF).

The two processes below are identical, except that the activities used in the second step are different. If B and D are doing the same thing, then B and D should be encapsulated in the same Engine.
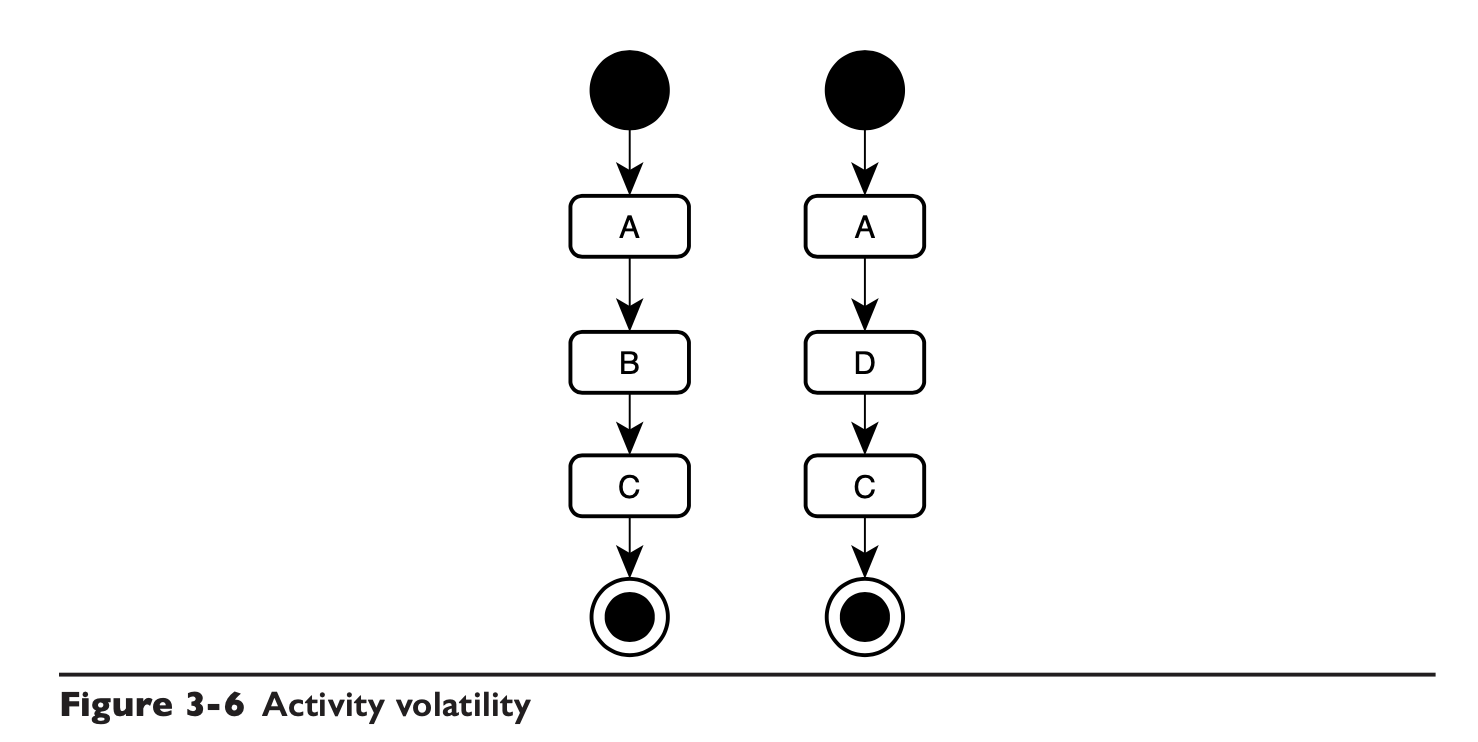
Of course, if the functions of B and D are not the same, then the two processes are not the same, another discussion.
Resource Access This layer is the resource access layer, responsible for some storage resource encapsulation, that is to say, when the company’s infrastructure to change, should not affect the upper layer of business, this kind of DDD community also has Repo Pattern and so on, relatively good understanding.
Utilities, those purple components, are generally some common non-functional SDKs, also better understood.
Most of the modules in the architecture diagram are services.

Each of these stratifications addresses the four questions of Who, What, How, and Where.

From top to bottom, the ease of change is gradually decreasing , we can think about, the company most often modified are some of the business logic above, the underlying infrastructure changes once every few years is good.
top-down reusability is gradually increasing, Manager often do changes, refactoring, completely rewritten, are quite normal.
The authors here again critique hard the decomposition of microservices by function, leading to the problem of functional decomposition and service-oriented complexity without gaining any benefit from modularity. This double whammy is more than many enterprises can afford. The authors express concern that microservices will be the biggest failure in the history of software.
Open vs. closed architectures
Open Architecture
Any component can call any other component, regardless of the layer the component is on. Calls can be made upwards and downwards.
The development architecture has a lot of flexibility, but it obviously leads to coupling between layers, and lateral calls within layers lead to coupling within layers, which makes the project unmaintainable.
The authors believe that lateral calls are one of the consequences of the decomposition of the architecture by function.
Closed Architecture
Closed architectures prohibit horizontal calls within layers and prohibit lower layers from calling higher layer systems. This takes the advantage of layering and decouples layers from each other. A closed architecture only allows components in one layer to call components in a lower adjacent layer. Components in lower layers encapsulate logic from lower layers.
Semi-closed and semi-development architecture
It is sometimes difficult to avoid calling each other for critical parts of the infrastructure. Because infrastructure has performance issues to consider, maximum optimization must be performed, and sometimes down conversion can cause performance problems.
There are also systems that basically don’t change much, and the coupling is coupled, so what do you care. The author here gives an example of a network stack is basically not much change in the code.
But most systems do not need to be half open and half closed, just closed.
Relaxing the rules of closed architecture a bit
Because the requirements of the closed architecture are so demanding, problems do occur in actual development, and can be relaxed as appropriate in the following cases.
- Calling utilities
- accessing resource access by business logic, i.e., the manager layer calls the resource access layer directly
- manager components calling less adjacent engines
- manager component communicates with other manager components via MQ, in which case the manager component does not need to know about the other components, just send a message.
Design taboos
The following actions are not allowed.
- client should not call multiple managers in a single use case
- client should not call the engine directly
- a manager should not wait for the return of multiple managers in the same use case, in which case the pub/sub model should be used
- the engine should not subscribe to message queues
- the resource access layer should not subscribe to message queues
- client should not publish messages to the message queue
- the engine should not publish messages
- resource access should not publish messages
- resource should also not publish messages
- engines should not call each other
- managers should not call each other
Composable architecture and architecture validation
Here again, the counter-intuitive point is made, Must not design based on requirements, but rather on fallibility .
When designing a system, find the core requirements from the list of requirements, and after the design is complete, use the core use cases to validate the architecture first. For example, in the Trade system described in the book, the core use case is transaction aggregation.
When new requirements are added, there should be less need to change the architecture, which shows that the architecture is designed correctly.
The functionality in the system is the result of integration, not implementation. (A little abstract, want to see understand here or read the good).
Cases
The last part of the system design gives the process of validating the relatively complete core use cases of the Trade system as described earlier on the design according to the fallibility.
First, the relevant concepts are listed according to the analytical framework of the previous four questions.
Who
-
Technician
-
Contractor
-
TradeMe customer representative
-
Education Center
-
Back office program (i.e., scheduler for payment)
-
What
-
Tradesmen and Contractor Memberships
-
Construction projects marketplace
-
Education certificates and training
-
How
-
Search
-
Compliance
-
Access Resources
-
Where
-
Local Database
-
Cloud
-
Other systems
The vulnerability is then analyzed and a list of vulnerabilities is made.
- Client applications
- Managing members
- Costs
- Projects
- Dispute Handling
- Matching and Approval
- Education
- Regulations
- Reporting
- Localization
- Resources
- Resource Access
- Deployment Model
- Authentication and authorization
In addition there are two relatively weak vulnerabilities.
- Notifications
- Data analysis
A reasonable mapping of the fallibilities results in a static architecture designed as follows.
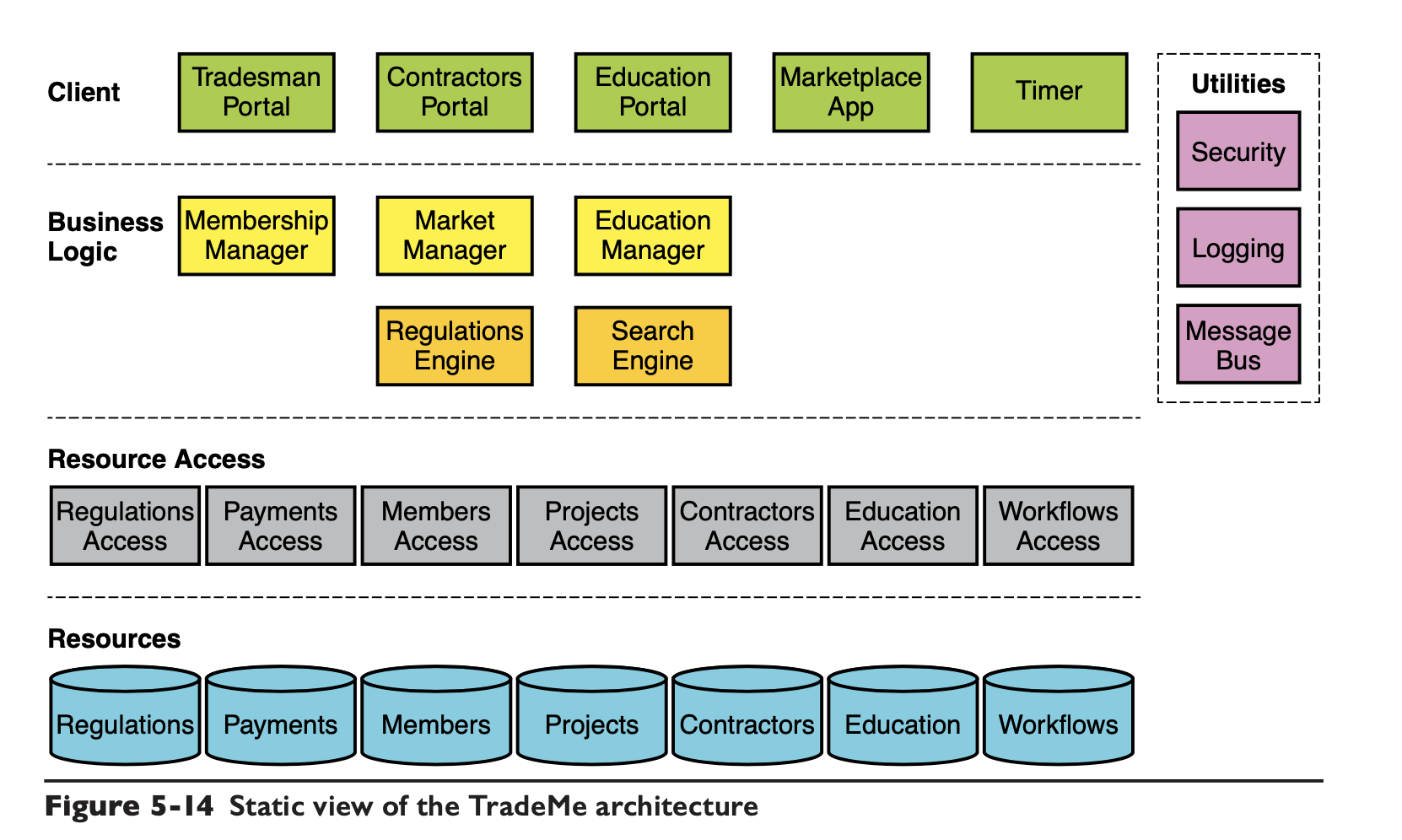
Then identify the core use cases from the requirements, which are.
- Adding a mechanic/contractor use case
- Request Mechanic use case
- Matching mechanic use cases
- Assign a mechanic use case
- Terminate a mechanic use case
- Pay for a mechanic use case
With the swim lane diagram, it is possible to verify the core use cases one by one.
Summary
The book “righting software” gives us a new way of thinking about designing system architecture, just by reading the author’s description is more reliable than the previous functional decomposition and DDD, but considering the actual situation that domestic Internet companies even use or not to use DDD, the design method based on variability may be more difficult to be accepted.
The author did not pull a bunch of big brothers on board like the DDD community, despite decades of experience, but compared to those big brothers in the DDD community who can shout, this methodology should not be particularly well known, and the relevant practice cases should be relatively small. There is only one case in the book, and the second half of the book is about project management, which is a bit unfortunate.
During the reading process, I also combined with my previous development experience in the company and kept thinking about it, I can see that the author’s theory should be able to be self-consistent without political influence.
There is one key problem with this theory, however, the possibility of architects missing variability in the process of fallibility analysis. This has happened in countless projects I’ve seen before, where the architect has walked away and the front-line engineers are complaining about the architect’s inability to design something to meet the new requirements.
If you are doing innovative business, you may be doing something disruptive all the time, it is still quite difficult to make a stable architecture through analysis.
The above is not mentioned first, the new point of view is still worth learning.