A computer’s file system is a method of storing and organizing computer data, which makes it easy to access and find. A file system uses the abstract logical concept of files and tree directories instead of using the concept of data blocks for physical devices such as hard disks and CD-ROMs, so that users using a file system to save data do not have to care about how much data is actually saved on the hard disk (or CD-ROM) at the address of the data block, but only need to You only need to remember the directory and file name of the file. Before writing new data, the user does not have to care about which block address on the hard disk is not used, the storage space management (allocation and release) function on the hard disk is done automatically by the file system, the user only needs to remember which file the data is written to.
Strictly speaking, a file system is a set of abstract data type that implements operations such as storage, hierarchical organization, access and retrieval of data.

Linux file system
The basic components of Linux I/O: everything is a file
Things in Linux like documents, directories (called folders under Mac OS X and Windows), keyboards, monitors, hard disks, removable media devices, printers, modems, virtual terminals, and input/output resources like inter-process communication (IPC) and network communication are all streams of bytes defined in file system space. The most significant benefit of everything being considered a file is that for the input/output resources listed above, only the same set of Linux tools, utilities and APIs are required. you can use the same set of api’s (read, write) and tools (cat , redirect, pipe) for most resources in unix.
Everything is a file means that for all file (directories, character devices, block devices, sockets, printers, etc.) operations, reading and writing can be handled with functions like fopen()/fclose()/fwrite()/fread(). The hardware distinction is masked, and all devices are abstracted into files, providing a unified interface to the user. Although the types are different, the same set of interface is provided for them. Further, operations on files can also be performed across file systems.

The disadvantage of everything being a file is that to use any hardware device you have to perform a mount operation with a directory in the root directory, otherwise you can’t use it. We know that Linux itself has a file directory structure with the root directory as the root of the tree, and so does each device, which is independent of each other. If we want to find the directory structure of the device files through the root directory on Linux, we have to merge these two file system directories into one, and that is what mounting really means.
File System
VFS, a software layer in the Linux kernel, is used to provide a file system interface to user-space programs; it also provides an abstraction in the kernel that allows different file systems to coexist. All file systems in the system not only rely on VFS to coexist, but also to work together. In addition to the standard Linux file systems Ext2/Ext3/Ext4, Windows’ vfat NTFS, etc., there are many other file systems such as reiserfs, xfs, and the network file system nfs. Linux provides support for these file systems through VFS, an intermediate layer.
VFS, upwards, provides a standard file manipulation interface to the application layer. Downward, it provides a standard interface to file systems so that file systems from other operating systems can be easily ported to Linux.

VFS provides as large a generic model of the underlying file system as possible, making this model contain an ensemble of all file system functions. Thus VFS encapsulates all the functionality and abstractions of the underlying file system, and VFS is responsible for forwarding requests from the application layer to a specific file system.
Most current Linux filesystems use the ext4 filesystem by default, just as previous Linux distributions used ext3, ext2, and the older ext by default.
Disks
Disk refers to the system’s storage device, commonly mechanical hard drives, solid state drives, etc. If it is found that the data the application wants to read is not in the page cache, it is time to actually initiate an I/O request to the disk. The process of disk I/O goes through the generic block layer of the kernel, the I/O scheduling layer, the device driver layer, and finally to the specific hardware device for processing.

- Generic block layer. Receives disk requests from the upper layer and eventually issues I/O requests. It is similar to the role of VPS.
- I/O Scheduling Layer. Merges and sequences requests according to the set scheduling algorithm. Disk requests that cannot be received are immediately handed off to the driver layer for processing.
- Block device driver layer. Depending on the specific physical device, the corresponding driver is selected to complete the final I/O request by manipulating the hardware device.
A Brief History of EXT
MINIX File System
Before ext was available, the MINIX file system was used. If you are not familiar with the history of Linux, it is understood that MINIX was a very small Unix-like system for IBM PC/AT microcomputers. Andrew Tannenbaum developed it for educational purposes and released the source code (in print format!) in 1987. .
Although you can read the source code of MINIX in detail, it is not actually free and open source software (FOSS). The publisher of Tannebaum’s book required you to pay a $69 license fee to run MINIX, which was included in the cost of the book. Nevertheless, it was very inexpensive for the time, and the use of MINIX grew rapidly, quickly outstripping Tannebaum’s original intent to use it to teach operating system coding. Throughout the 1990s, you could find MINIX installations in universities all over the world. At this time, a young Linus Torvalds used MINIX to develop the original Linux kernel, which was first announced in 1991 and then released under the GPL open source agreement in December 1992.
MINIX had its own filesystem, which early versions of Linux relied on. Like MINIX, the Linux file system was as small as a toy; the MINIX file system could handle file names of up to 14 characters and only 64 MB of storage space. By 1991, the average hard drive size had reached 40-140 MB, and it was clear that Linux needed a better file system.
ext
While Linus was developing the fledgling Linux kernel, Rémy Card worked on the first generation of the ext file system. ext was first implemented and released in 1992, and ext used the new Virtual File System (VFS) abstraction layer in the Linux kernel. Unlike the previous MINIX file system, ext could handle up to 2 GB of storage and handle 255 character file names, solving the worst problems of the MINIX file system. But ext did not dominate for long, mainly due to its primitive timestamps (only one timestamp per file, rather than the familiar timestamp with inode, most recent file access time, and latest file modification time we are familiar with today.) Just a year later, ext2 replaced it.
ext2
Rémy soon realized the limitations of ext, so a year later he designed ext2 to replace it. While ext was still rooted in a “toy” operating system, ext2 was designed from the start as a commercial-grade filesystem, following the design principles of BSD’s Berkeley filesystem. ext2 offered a maximum file size at the GB level and a filesystem size at the TB level, putting it firmly in the big league of filesystems in the 1990s. ext2 was firmly entrenched in the file system league in the 1990s. It was soon widely used, both in the Linux kernel and eventually in MINIX, and third-party modules were used to make it available for MacOS and Windows.
But there were still some problems to be solved here: the ext2 file system, like most file systems of the 1990s, was prone to catastrophic data corruption if the system crashed or lost power while writing data to disk. Over time, they also suffered severe performance losses due to fragmentation (a single file stored in multiple locations, physically its scattered across a spinning disk). Despite these problems, today ext2 is used in some special cases. Most commonly, as a file system format for portable USB drives
ext3
In 1998, six years after ext2 was adopted, Stephen Tweedie announced that he was working on improving ext2. This became ext3, and was adopted into the Linux kernel mainline in November 2001 in kernel version 2.4.15.
For the most part, ext2 worked well in Linux distributions, but like FAT, FAT32, HFS and other file systems of the time, it was prone to catastrophic damage in the event of a power failure. If a power failure occurs while writing data to a filesystem, it can be left in what is called an “inconsistent” state - where things are only half done and the other half is not. This can result in the loss or corruption of a large number of files that are unrelated to the file being saved or even cause the entire file system to be unmountable.
ext3 and other file systems from the late 1990s, such as Microsoft’s NTFS, use logs to solve this problem. A log is a special allocated area on disk whose writes are stored in a transaction; if that transaction completes a disk write, the data in the log is committed to the file system itself. If the system crashes before that operation is committed, the restarted system recognizes it as an incomplete transaction and rolls it back as if it had never happened. This means that the files being processed may still be lost, but the file system itself remains consistent and all other data is safe.
Three levels of logging are implemented in Linux kernels using the ext3 file system: journal, ordered, and writeback.
- journal: the lowest risk mode, writes data and metadata to the journal before committing it to the file system. This ensures that the file being written is consistent with the entire file system, but it significantly reduces performance.
- Sequential : The default mode for most Linux distributions; sequential mode writes metadata to the log and commits the data directly to the file system. As the name implies, the order of operations here is fixed: first, metadata is committed to the log; second, data is written to the file system before the metadata associated with the log is updated to the file system. This ensures that metadata associated with incomplete writes remains in the log in the event of a crash, and that the file system can clean up those incomplete write transactions when the log is rolled back. In sequential mode, a system crash may cause errors in files to be actively written during the crash, but the file system itself – and the files that were not actively written – are guaranteed to be safe.
- Write-back: The third mode – and the least secure – logging mode. In write-back mode, like sequential mode, metadata is recorded to the log, but data is not. Unlike sequential mode, both metadata and data can be written in any order that is conducive to getting the best performance. This can significantly improve performance, but is much less secure. While write-back mode still guarantees the security of the file system itself, files written before a crash or collapse can easily be lost or corrupted.
Similar to ext2 before it, ext3 uses 16-bit internal addressing. This means that ext3 can handle a maximum file size of 2 TiB on a file system with a maximum size of 16 TiB for a 4K block size.
ext4
Theodore Ts’o (who was the lead developer of ext3 at the time) published ext4 in 2006, which was added to the Linux mainline two years later in kernel version 2.6.28. Ts’o describes ext4 as an interim technology that significantly extends ext3 but still relies on older technologies. Ts’o describes ext4 as an interim technology that significantly extends ext3 but still relies on older technologies. He expects that ext4 will eventually be replaced by a true next-generation file system.
ext4 is functionally very similar to ext3 in terms of features, but supports large filesystems, improved resistance to fragmentation, higher performance, and better timestamps.
Differences between ext3 and ext4:
- Backward compatibility
- ext4 is specifically designed to be as backwards compatible with ext3 as possible. this not only allows ext3 filesystems to be upgraded to ext4 in-place; it also allows ext4 drivers to automatically mount ext3 filesystems in ext3 mode, thus making it unnecessary to maintain two separate codebases.
- Large file systems
- ext3 filesystem uses 32-bit addressing, which limits it to supporting only 2 TiB file sizes and 16 TiB filesystem system sizes (this assumes a block size of 4 KiB; some ext3 filesystems use smaller block sizes and are therefore further limited to them).
- ext4 uses 48-bit internal addressing and can theoretically allocate files up to 16 TiB in size on the filesystem, where the filesystem size can be up to 1,000,000 TiB (1 EiB).
- Allocation improvements
- ext4 makes significant improvements to the way blocks are allocated before they are written to disk, which can significantly improve read and write performance.
- Sections
- A segment (extent) is a series of contiguous physical blocks (up to 128 MiB, assuming a block size of 4 KiB) that can be reserved and addressed at once. Using sectors reduces the number of inodes required for a given file and significantly reduces fragmentation and improves performance when writing large files.
- Multiblock Allocation
- ext3 calls the block allocator once for each newly allocated block. When multiple writes open the allocator at the same time, it can easily lead to severe fragmentation. However, ext4 uses deferred allocation, which allows it to consolidate writes and better determine how to allocate blocks for writes that have not yet been committed.
- Persistent pre-allocation
- When pre-allocating disk space for a file, most file systems must write zeros to that file’s blocks at creation time. ext4 allows for the alternative use of fallocate(), which guarantees the availability of space (and tries to find contiguous space for it) without writing to it first. This significantly improves the performance of writing and future reading of written data from streams and database applications.
- Delayed allocation
- This is an intriguing and controversial feature. Deferred allocation allows ext4 to wait to allocate the actual block of data that will be written until it is ready to commit the data to disk. (By contrast, ext3 allocates blocks immediately even if data is still being written to the write cache.) Delaying block allocation allows the file system to make better choices about how to allocate blocks as data accumulates in the cache, reducing fragmentation (writes and, later, reads) and significantly improving performance. Unfortunately, however, it increases the possibility of data loss for programs that have not yet called the fsync() method specifically (when the programmer wants to ensure that the data is completely flushed to disk).
- Unlimited subdirectories
- ext3 is limited to 32,000 subdirectories; ext4 allows an unlimited number of subdirectories. Starting with the 6.23 kernel release, ext4 uses HTree indexing to reduce the performance loss of large numbers of subdirectories.
- Log validation
- ext3 does not perform checksumming of logs, which causes problems for controller devices with disks or self-contained caches that are outside the direct control of the kernel. If a controller or disk with its own cache is out of write order, it could break ext3’s journaling transaction order, potentially destroying files written during (or some time before) a crash. In theory, this problem could improve performance (and performance benchmarks against competitors) using write barriers, but increases the likelihood of data corruption that should be prevented.
- Checksumming the logs and allowing the file system to realize that some of its entries are invalid or out of order when it is first mounted after a crash. Thus, this avoids the error of rolling back partial entries or out-of-order log entries and further corrupting the file system – even if parts of the storage device falsely do or do not comply with write barriers.
- Fast filesystem checks
- Under ext3, the entire filesystem is checked when fsck is called – including deleted or empty files. In contrast, ext4 marks blocks and sectors in the inode table as unallocated, thus allowing fsck to skip them entirely. This greatly reduces the time it takes to run fsck on most file systems, and it was implemented in kernel 6.24.
- Improved timestamps
- ext3 provides timestamps at a granularity of one second. While sufficient for most purposes, mission-critical applications often require tighter time control. ext4 makes it possible to use it for those enterprise, scientific, and mission-critical applications by providing timestamps at the nanosecond level.
- The ext3 file system also does not provide enough bits to store dates after January 18, 2038. ext4 adds two bits here, extending the Unix epoch by 408 years. If you’re reading this in 2446 AD, you’ve probably moved to a better file system – if you’re still measuring time since January 1, 1970 at 00:00 (UTC), this will give me peace of mind when I die.
- Online defragmentation
- Neither ext2 nor ext3 directly support online defragmentation – that is, they defragment the filesystem when mounted. ext2 has an included utility, e2defrag, whose name implies – it needs to be run offline when the filesystem is not offline when the filesystem is unmounted. (Obviously, this is very problematic for the root filesystem.) The situation is even worse in ext3 – while ext3 is less susceptible to severe fragmentation than ext2, running e2defrag on ext3 filesystems can lead to catastrophic corruption and data loss.
- Although ext3 was initially considered “fragmentation free”, the use of massively parallel write processes for the same file (e.g. BitTorrent) clearly shows that this is not entirely the case. There are some user-space means and workarounds, but they are slower and less satisfactory in every way than a true, filesystem-aware, kernel-level defragmentation process.
- ext4 solves this problem with e4defrag and is an online, kernel-mode, filesystem-aware, block- and sector-level defragmentation utility.
On-going ext4 development
While the lead developers of ext consider it only a stopgap measure for a true next-generation file system, there are no likely candidates ready (due to technical or licensing issues) to be deployed as a root file system for some time. There are still some key features to be developed in future versions of ext4, including metadata checksums, first-class quota support, and large allocation blocks.
- Metadata checksums
- Since ext4 has redundant superblocks, it provides a way for the file system to checksum the metadata within them, determining for itself whether the primary superblock is corrupted and requires the use of a spare block. It is possible to recover from a corrupted superblock without a checksum – but the user first needs to realize that it is corrupted and then try to mount the filesystem manually using the alternate method. Since in some cases mounting a file system read/write with a corrupt primary superblock may cause further damage that even experienced users cannot avoid, this is not a perfect solution either!
- The metadata checksum of ext4 is very weak compared to the extremely powerful per-block checksums offered by next-generation file systems such as Btrfs or ZFS. But it’s better than nothing. While checksumming everything sounds simple! – in fact, there are some significant challenges in linking checksums to the filesystem.
- First-class quota support
- Quotas? We’ve had these since the day ext2 came along! Yes, but they’ve always been an afterthought to add things, and they’ve always been guilty of being silly. It’s probably not worth going into detail here, but the design docs list the ways in which quotas will move from user space to the kernel and can be implemented more correctly and efficiently.
- Large allocation blocks
- Those pesky storage systems keep getting bigger and bigger as time goes on. Since some SSDs already use 8K hardware block sizes, ext4’s current limit on 4K blocks is becoming increasingly restrictive. Larger blocks can significantly reduce fragmentation and improve performance at the cost of increased “slack” space (the space left over when you only need a portion of a block to store the last piece of a file or files).
ext4’s practical limitations
ext4 is a robust and stable filesystem. Most people today should be using it as a root filesystem, but it can’t handle all the demands. Let’s briefly touch on some things you shouldn’t expect – now or possibly in the future.
While ext4 can handle data up to 1 EiB in size (equivalent to 1,000,000 TiB), you really shouldn’t try to do so. In addition to being able to remember the addresses of many more blocks, there are issues with scale. And right now ext4 will not handle (and probably never will) more than 50-100 TiB of data.
ext4 is also insufficient to guarantee data integrity. With significant advances in logging it is back to a time when ext3 did not cover many of the common causes of data corruption. If data has been corrupted on disk – due to faulty hardware, the effects of cosmic rays (yes, really), or just data degradation over time – ext4 cannot detect or repair that corruption.
Based on the above two points, ext4 is just a pure file system, not a storage volume manager. This means that even if you have multiple disks – that is, parity or redundancy – you could theoretically recover corrupted data from ext4, but there is no way to know if using it would be to your advantage. While it is theoretically possible to separate the file system and storage volume management system in separate layers without losing automatic corruption detection and repair capabilities, this is not how current storage systems are designed, and it would present significant challenges for new designs.
Other file systems under Linux
XFS
XFS has the same status as a non-ext filesystem in the mainline in Linux. It is a 64-bit logging file system that has been built into the Linux kernel since 2001, providing high performance for large file systems and high concurrency (i.e., a large number of processes all writing to the file system immediately). Starting with RHEL 7, XFS became the default file system for Red Hat Enterprise Linux. For home or small business users, it still has some drawbacks: retooling an existing XFS file system is a huge pain, and it makes less sense to create another one and replicate the data.
While XFS is stable and high-performance, there are not enough specific end-use differences between it and ext4 to warrant recommending its use anywhere other than by default (e.g. RHEL7), unless it solves a specific problem for ext4, such as file systems larger than 50 TiB capacity. XFS is not in any way a “next generation” file system to ZFS, Btrfs, or even WAFL (a proprietary SAN file system). Like ext4, it should be seen as a stopgap for a better way.
ZFS
Developed by Sun Microsystems, ZFS is named after the zettabyte – the equivalent of 1 trillion gigabytes – because it can theoretically address large storage systems. As a true next-generation file system, ZFS offers volume management (the ability to handle multiple individual storage devices in a single file system), block-level cryptographic checksums (allowing for extremely accurate data corruption detection), automatic corruption repair (where redundant or parity-checked storage is available), fast asynchronous incremental replication, inline compression, and more.
The biggest problem with ZFS from the Linux user’s point of view is the license, which is a CDDL license, a semi-licensed license that conflicts with the GPL. There is a lot of controversy about the implications of using ZFS in the Linux kernel, ranging from “it’s a GPL violation” to “it’s a CDDL violation” to “it’s perfectly fine, it hasn’t been tested in court. It hasn’t been tested in court.” Most notably, Canonical has had ZFS code inlined in its default kernel since 2016, and there has been no legal challenge.
Btrfs
Btrfs is short for B-Tree Filesystem, often pronounced “butter” – released by Chris Mason in 2007 during his tenure at Oracle. Btrfs is intended to have most of the same goals as ZFS, providing multiple device management, per-block checksums, asynchronous replication, inline compression, and more.
As of 2018, Btrfs is fairly stable and can be used as a standard single-disk file system, but should probably not rely on a volume manager. It has serious performance issues compared to ext4, XFS, or ZFS in many common use cases, and its next-generation features – replication, multi-disk topology, and snapshot management – can be so numerous that the results can range from catastrophic performance degradation to actual data loss.
The maintenance status of Btrfs is controversial; SUSE Enterprise Linux adopted it as the default file system in 2015, and Red Hat announced in 2017 that it would no longer support Btrfs starting with RHEL 7.4. It may be worth noting that the product supports Btrfs deployments as single-disk file systems, rather than multi-disk volume managers as in ZFS. volume manager, even Synology uses Btrfs for its storage devices, but it manages disks in layers on top of traditional Linux kernel RAID (mdraid).
Mac OS file system
Mac OS has a long history of development and has gone through many different file systems. The more famous file systems: UFS, HFS+, and APFS.
UFS
In 1985, Steve Jobs left Apple and founded NeXT, which developed the NeXTSTEP operating system based on BSD, the predecessor of the now familiar Mac OS. This was the most advanced file system at the time, and had a huge impact on the design of later file systems.
UFS, or the Unix File System, also known as the Berkeley Fast File System, was not an Apple original, but was first published in 1984 by Marshall Kirk McKusick and William Joy (founders of Sun). UFS is arguably the progenitor of the modern file system, making it truly usable in production environments. While pre-UFS file systems used up to 5% of the disk bandwidth, UFS increased that number to 50%. This is primarily due to two design features in UFS.
- Increasing the base block size from 1024 bytes to 4096 bytes
- The addition of the Cylinder Group concept, which optimizes the distribution of data and metadata on the disk and reduces the number of head seeks when reading and writing files (reducing the number of head seeks is a major performance optimization direction for HDD-era file systems)

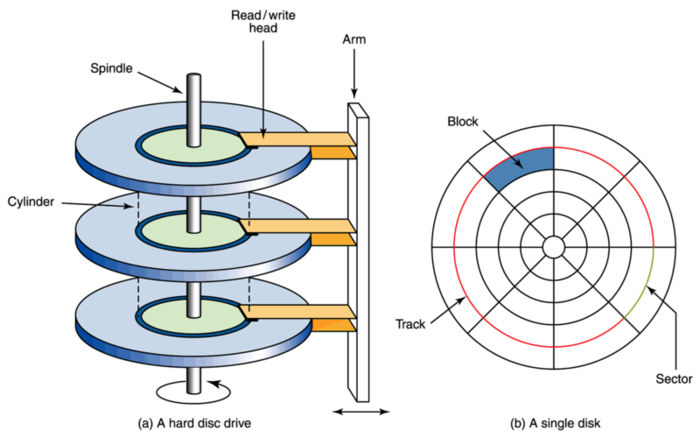
The disk layout for UFS is shown above. The disk is divided into multiple Cylinder Groups, each of which contains a copy of the Superblock and the meta-information inside the Cylinder Group. If the Inode and Data Block are placed next to each other on the disk, it means that no additional seek time is needed.
UFS was first implemented on BSD systems, and has since been ported to Unix operating systems such as Sun’s Solaris, IBM’s System V, and HP-UX, including many storage products from the current storage giant EMC, where the operating system is Unix and the file system is based on UFS. There is no UFS implementation on Linux, but the famous ext2 file system is heavily based on UFS in its design. Ext3 and ext4 were extensions of the ext2 design, and also inherited UFS ideas.
In February 1997, Apple completed its acquisition of NeXT, and Steve Jobs returned to Apple. UFS support remained in the Mac OS until Mac OS X Lion, when it was removed.
HFS+
UFS did not remain the default file system in Mac OS for long after Apple acquired NeXT. In January 1998, one year after Apple acquired NeXT, Mac OS 8.1 was released with the HFS Plus (HFS+) file system to replace UFS. By design, HFS+ had a number of improvements over its predecessor, including a 16-bit to 32-bit upgrade, Unicode support, maximum file support of 2^63 bytes, and more. The most attractive feature of HFS+ is Time Machine. Anyone who has used the Time Machine feature knows that it is a very cool and useful feature that can be used to roll back a file system to a previous point in time, to back up a file system, to retrieve historical versions of files, and to do system migrations.
Despite this, HFS+ is a controversial file system, and has even been denounced by Linus as the worst file system ever made. The main criticisms of HFS+ are the following.
- case insensitivity (the latest version supports case sensitivity, but the default configuration is still not case insensitive)
- no checksum verification of data content
- timestamp is only supported down to the second level
- concurrent access is not supported
- Snapshots are not supported
- sparse file is not supported
- Use big-endian for storage
From a technical point of view, HFS+ doesn’t look like a modern file system at all. Although it can do cool things like Time Machine, it is too backward and has too many hard parts compared to other file systems, such as case insensitivity and no support for Sparse File. So HFS+ can hardly be called a good file system.
APFS
In 2017, Apple officially released the Apple File System with the Mac OS High Sierra release, and at WWDC 2016, Apple already announced the APFS project. To distinguish it from AFS (Apple File Service), APFS is used as an acronym.
HFS is the predecessor of HFS+, which was designed in 1985, more than 30 years ago. With the development of CPU, memory, and storage media technologies, the hardware we use today has changed dramatically compared to 30 years ago. CPUs have evolved in the direction of multi-core, memory capacity has increased and single machines can now support terabytes of memory, and storage media has gradually shifted from HDDs to SSDs. After 30 years of development, HFS has reached the end of its technical life and it is very difficult to improve HFS anymore.
Starting in 2014, under Giampaolo’s leadership, Apple began designing and developing a new file system, APFS, which was not based on an existing file system, but rather built from the ground up and released and brought online in just three years, when it typically takes at least 10 years for a file system to go from development to stability.
Apple’s requirements for the new file system were as follows.
- Be adaptable to multiple application scenarios, from smartwatches, to smartphones, to laptops
- Secure and reliable data
- Ability to take advantage of multi-core CPUs and the concurrency of new hardware devices
At the same time, APFS offers more features than HFS+.
- Guaranteed crash safe
- 64-bit file system (HFS+ is a 32-bit file system)
- sparse file support (HFS+ does not support sparse file!)
- Scalable metadata design
- Snapshot and clone support
- Metadata support for checksum checksum
Mac OS users who upgrade to High Sierra will automatically upgrade their file system from HFS+ to APFS, which is possible because Apple has designed a clever upgrade process.
- Read the Inode from the disk in the HFS+ format
- Find a free space on the disk and write the new Inode to the free space in APFS format
- Modify the Superblock on disk, write the new Superblock to disk in APFS format, and the new Superblock will index the APFS Inode and free up the space occupied by the original HFS+ Inode
In terms of performance, although Apple claims that APFS is optimized for SSDs, a number of websites have tested the performance of APFS and found that APFS performance on SSDs is lower than HFS+.
Windows file system
The common file system formats under Windows are: FAT32, NTFS, exFAT
FAT32
Windows platform’s traditional file format universal format, any USB storage device will be pre-installed this file system, can be used on any operating platform. Windows 95 version 2 was first introduced to replace FAT16 (support file maximum capacity of 2GB), compatibility is very good, but the disadvantage is that there is a limit on the file size, does not support more than 4GB files. So, for many large games, image files, compressed packages, videos, it is not a solution. In addition, the maximum capacity of the FAT32 format hard drive partition is 2TB, FAT32 is behind the times, so don’t use it if you can. Now when formatting a USB drive, FAT32 is still the default operation, as is Windows 10, more for conservative considerations of compatibility.
exFAT
The most suitable file format for USB flash drives, which is tailored by Microsoft for flash USB flash drives, with advanced performance and technical support, while optimizing protection for flash memory without causing excess damage.
exFAT (Extended File Allocation Table File System, also known as FAT64, i.e. Extended File Allocation Table) is a format introduced by Microsoft in Windows Embeded 5.0 and above (including Windows CE 5.0, 6.0, Windows Mobile5, 6, 6.1), a file system suitable for flash memory, was introduced to solve the problem that FAT32 and others do not support 4G and larger files. For flash memory, NTFS file system is not suitable for use, exFAT is more suitable. The main benefits include: enhanced interoperability between desktops/laptops, mobile devices, maximum 16EB for a single file, improved space allocation lines in the remaining space allocation table, up to 65536 files in the same directory, and support for access control. The biggest disadvantage is that there is no file logging feature, so that the modification records of files on the disk cannot be recorded.
exFAT uses the remaining space bitmap to manage capacity allocation and improve deletion performance, which is important to improve write performance, especially compared to NTFS. but note that it is not possible to install Windows on exFAT partitions. both Windows Vista/7 rely heavily on NTFS for features such as file licensing. However, due to the limitations of Microsoft’s licensing mechanism, exFAT is not widely available and is not particularly used in consumer electronics.
NTFS
The most widely used format for Windows platform is also the best available, supporting large capacity files and very large partitions, and has many advanced technologies including long file names, compressed partitions, event tracking, file indexing, high fault tolerance, data protection and recovery, encrypted access, etc. However, NTFS is still designed for mechanical hard drives and will record detailed hard drive read and write operations, so it can be very burdensome and harmful for flash memory (such as USB drives, SSDs, SD cards, etc.) and can easily affect the lifetime. Flash memory storage chips are limited in the number of reads and writes, and using a logging file system means that all operations on the disk are logged. The large number of small files read and write is extremely harmful to the flash memory and will shorten its life. That’s why NTFS is not recommended for USB drives.
Why do computers still use the NTFS file system designed for mechanical disks when using solid state drives? Because there is no better choice!
ReFS
Resilient File System (ReFS). It is a proprietary file system introduced by Microsoft in Windows Server 2012 and is intended to be the “next generation” file system after NTFS, which is designed to overcome the significant problems that have arisen since NTFS was conceived and is geared towards changing data storage needs. This includes automatic integrity checking and data cleanup, avoidance of the need to run chkdsk, data decay prevention, built-in hard drive failure and redundancy handling, integrated RAID functionality, data and metadata update switching to copy/allocate on write, handling of very long paths and filenames, and storage virtualization and storage pooling, including logical volumes of almost any size (independent of the physical size of the drive used). . Starting with Win10 1709 Fall Creators Update, only Win10 Enterprise and Win10 Pro Workstation editions offer the ReFS partitioning option; other Win10 editions are no longer supported.
ReFS is mostly compatible with NTFS and its main purpose is to maintain a high level of stability by automatically verifying that data is not corrupted and doing its best to recover it. When used in conjunction with the introduced Storage Spaces, it provides better data protection. There are also performance improvements for processing hundreds of millions of files.