When I was learning Python, I basically skimmed over how to import modules and packages. The reason for this is not only that the syntax of importing is very simple, but also that at the early stage of learning, you will not be involved in large projects, nor will you be writing your own modules and packages, so you will not encounter any problems here. In the process of using Python, you will often encounter import errors or failures when deploying or packaging, which is difficult to solve without understanding the relevant mechanism.
Python’s import statement
The import statement is Python’s most common import mechanism, but it’s not the only way. importlib.import_module() and the built-in __import__() function can both invoke the import mechanism.
Python’s import statement actually combines two operations.
- a search operation that looks for a module based on a specified naming
- Bind operation: binds the result of the search to the naming corresponding to the current scope
When a module is first imported, Python searches for it, creating a module object and initializing it if it is found, or throwing a ModuleNotFoundError exception if it is not found. As for how to find these modules, Python defines a variety of search strategies, which can be modified and extended by various hooks provided by importlib, etc.
According to the Python 3.3 changlog, the import system now fully implements the PEP 302 proposal, and all import mechanisms are exposed through sys.meta_path, so there are no more implicit import mechanisms.
Absolute import and relative import
Relative import is the default import method prior to Python 2.5 and takes the following form.
Absolute import, also called full import, was fully implemented after Python 2.5 and is also advocated in PEP 8, where it is used in the following way.
With absolute import, we often run into the problem that Python cannot find the corresponding library file because of the location, thus throwing an ImportError exception.
Module search path
When we want to import a module, the interpreter first looks for built-in modules based on naming, and if it doesn’t find one, it goes to the directory in the sys.path list to see if it’s in the directory.
Output results.
|
|
The initial value of sys.path comes from.
- the directory where the script is running (or the current directory if the interactive interpreter is open)
- PYTHONPATH environment variable (similar to the PATH variable, also consisting of a set of directory names)
- The default settings for Python installations
Of course, this sys.path can be modified. Note that if the current directory contains a module with the same name as the standard library, the module in the current directory will be used directly instead of the standard module.
If you don’t want to modify sys.path and want to extend the search path at the same time, you can use the .pth file. First of all, the contents of the file are simple, just add the path (absolute path) of the library you want to import, one line at a time; then put the file in a specific location, and Python will read the path in the .pth file when it loads the module.
This specific location can be obtained by the site module’s getsitepackages method at
The result, which varies from platform to platform, is a list of paths, which on Windows is typically the site-packages directory of the corresponding environment (or virtual environment).
Overview of the import statement mechanism
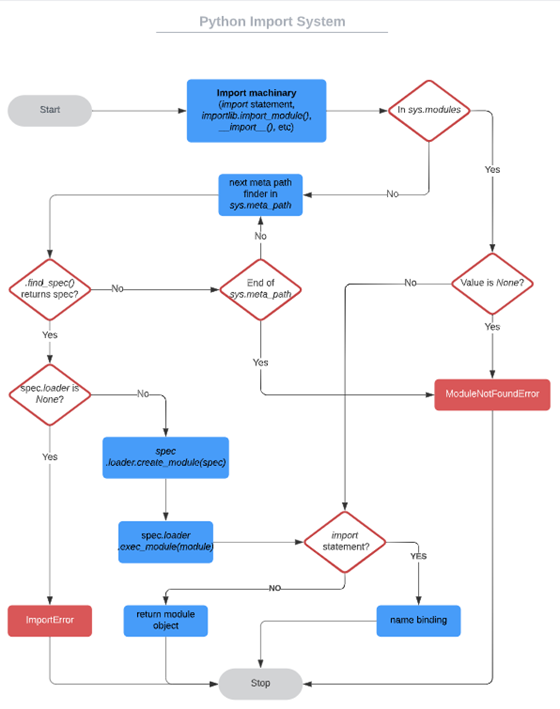
The following code briefly illustrates the process of importing the load section.
|
|
Here are some details.
- Modules need to be cached in modules before the loader executes exec_module: because modules may import themselves, this prevents infinite recursion (worst case) or multiple loads (best case).
- If the load fails, then the failed module will be removed from modules. Any modules that already exist or depend on but are successfully loaded are retained – this is not the same as reloading, which keeps the failed module in sys.modules even if it fails to load.
- Module execution is the key step in loading, and is responsible for populating the module’s namespace. Module execution will be fully delegated to the loader, which will decide how and what to fill.
- The module object created and passed to exec_module for execution may not be the same as the module object that is finally imported.
sys.modules
When the import mechanism is triggered, Python first looks in sys.modules to see if the module has already been introduced, and if it has, it calls it directly, otherwise it proceeds to the next step. Here sys.modules can be thought of as a cache container.
Output results.
|
|
sys.modules is essentially a dictionary whose corresponding values are the respective module objects if they have been imported before. During import, if the key corresponding to the module name is found in sys.modules, its value is retrieved and the import is completed. If the value is None, a ModuleNotFoundError exception is thrown; otherwise, the search operation is performed.
sys.modules is modifiable, forcing the value None will cause the next import of the module to throw a MoudleNotFoundError exception; if the key is deleted, the next import will trigger a search operation.
Post-execution exception.
The best way to recover is to delete the key of sys.modules (side effect: the module object of the module with the same name imported before and after is not the same), and the best practice should be to use the importlib.reload() function.
Finder finder and loader
If the corresponding module is found in sys.modules and the import is triggered by an import statement, then the next step is to bind the corresponding variable to a local variable.
If the module object is not found in the cache, Python will find and load the module according to the import protocol. This protocol, introduced in PEP 320, has two main components: finder and loader. finder’s task is to determine whether a module of that name can be found according to a known policy. An object that implements both the finder and loader interfaces is called an importer – it returns itself when it finds the required module that can be loaded.
In the process, Python iterates over sys.meta_path to find if there is a meta path finder that matches. sys.meta_path is a list of meta path finders. It has three default finders.
- built-in module finder
- Frozen module finder
- path-based module finder.
Output.
The finder’s find_spec method determines whether the finder can handle the module to be introduced and returns a ModuleSpec object that contains the relevant information used to load this module. If no suitable ModuleSpec object is returned, then the system will look at the next meta path finder for sys.meta_path. If no suitable meta path finder is found by traversing sys.meta_path, ModuleNotFoundError will be thrown. this happens when introducing a non-existent module, as all the finders in sys.meta_path are unable to handle this case.
|
|
Return.
However, if this manually adds a finder that can handle this module, then it can also be introduced.
|
|
Post-execution exception.
As you can see, the ModuleNotFound exception is not thrown when we tell the system how to find_spec. But to successfully load a module, a loader loader is also needed.
The loader is a property of the ModuleSpec object that determines how a module is loaded and executed. In the loader, you can decide exactly how to load and execute a module. The decision here is not just to load and execute the module itself, you can even modify a module:
|
|
As you can see from the above example, a loader usually has two important methods create_module and exec_module that need to be implemented. If the exec_module method is implemented, then create_module is required. If this import mechanism is initiated by an import statement, then the variables corresponding to the module object returned by the create_module method will be bound to the current local variables. If a module is thus successfully loaded, it will be cached in sys.modules, and if the module is loaded again, the sys.modules cache will be referenced directly.
Note that before Python 3.4 finder would return the loader directly instead of the module spec, which actually already contains the loader.
import hook
For simplicity, we did not mention the import mechanism hook in the flowchart above, but you can actually add a hook to change sys.meta_path or sys.path to change the behavior of the import mechanism. In the example above, we modified sys.meta_path directly, but you can actually do that with a hook.
The import hook is used to extend the import mechanism, and it comes in two types.
- The meta hook is called at the very beginning of the import (after looking for cached modules), where you can overload the handling of sys.path, frozen module and even built-in modules. Just add a new finder to sys.meta_path to register the meta_hook.
- import path hooks are called when path (or package.path) is processed and they take care of the entries in sys.path. Just add a new callable to sys.path_hooks to register the import path hook.
|
|
meta path finder
The job of the meta path finder is to see if the module can be found. These finders are stored in sys.meta_path for Python to traverse (they can also be returned via the import hook, of course). Each finder must implement the find_spec method. If a finder knows what to do with the module to be introduced, find_spec will return a ModuleSpec object otherwise it returns None.
|
|
Take the foo.bar.baz module as an example to illustrate find_spec
Parameter description.
| Parameters | Description | Example |
|---|---|---|
| fullname | Fully qualified name of the module being imported | foo.bar.baz |
| path | A list of paths to use for the search. For top-level modules, this value is None; for child packages, this value is the value of the parent package’s __path__ property |
foo.bar.__path__ |
| target | Existing module objects used as targets for later loading, this value will only be passed in when reloading the module | None |
For a single import request that may traverse the meta_path multiple times, the modules added to the example are not yet cached, so each finder (named after mpf) will be called in turn
- find_spec(“foo”, None, None)
- find_spec(“foo.bar”, foo.path, None)
- find_spec(“foo.bar.baz”, foo.bar.path, None)
Python 3.4 onwards finder’s find_module() has been replaced by find_spec() and deprecated.
path based finder
As mentioned above, Python comes with several meta path finders by default: the built-in module finder, the frozen module finder, and the path based finder. Here we will focus on the path based finder.) It is used to search for a series of import paths, each of which is used to find if there is a corresponding module that can be loaded. The default path finder implements all the functions for finding modules in special files on the filesystem, including Python source files (.py files), Python post-compiled code files (.pyc files), and shared library files (.so files). If the Python standard library contains zip imports, then the associated files can also be used to find modules that can be introduced.
The path finder is not limited to files on the filesystem; it can also look up URL databases, or any other address that can be represented as a string. You can use the Hook provided in the previous section to implement module lookups for the same type of address. For example, if you want to import a module by URL, then you can write an import hook to parse the URL and return a path finder.
PathBasedFinder will use three variables that will provide additional paths to the custom import mechanism, including.
- path
- path_hooks
- path_importer_cache
The __path__ attribute of a package is also used.
sys.path is a list of strings that provides a search location for modules and packages. Its entries can come from filesystem directories, zip files, or other “locations” where modules can potentially be found (see site modules).
Since PathBasedFinder is a meta path finder, it must implement the find_spec() method. The import mechanism searches for import path by calling this method (by passing in the path parameter - it is a list of traversable strings).
Inside find_spec(), it iterates over each entry of path and looks for the PathEntryFinder corresponding to the entry each time. but since this operation can be resource intensive, the PathBasedFinder maintains a cache – sys.path_ importer_caceh to store the mapping between path entries and finder. Then as long as the entry has been found once the finder will not be matched again.
If there is no key corresponding to a path entry in the cache, each callable object in sys.path_hooks is iterated over. Each of these callable objects accepts a path argument and returns a PathEntryFinder or throws an ImportError exception.
If the entire sys.path_hooks callable does not return a PathEntryFinder, the find_spec() method deposits None in the sys.path_importer_cache and returns None, indicating that the PathBasedFinder could not find the module.
The general flow is shown in the figure.

Note that a path finder is different from a meta-path finder. The latter is used in sys.meta_path to be traversed by Python, while the former refers specifically to a path-based finder. The finder doesn’t actually know how to do import; its job is just to iterate over each entry on the import path, associating them with some path entry finder that knows how to handle a particular type of path. According to the glossary, the path entry finder is returned by the callable object in the sys.path_hook list (provided it knows how to find the module based on a particular path entry). One can think of PathEntryFinder as a concrete implementation of PathBasedFinder. In fact, if the PathBasedFinder is removed from sys.meta_path, no PathEntryFinder will be called.
Since the PathEntryFinder is responsible for importing modules, initializing packages, and building portions for namespace packages, it also needs to implement the find_spec() method, which takes the following form.
|
|
where.
- fullname: the fully qualified name of the module
- target: optional target module
Python 3.4 onwards find_spec() replaces find_loader() and find_module(), the latter two being deprecated.
Note that if the module is a fraction of a namespace package, PathEntryFinder sets the loader in the returned spec object to None and sets submodule_search_locations to a list containing this fraction, to account for it to the import mechanism.
module spec object
Each meta path finder must implement the find_spec method, which returns a ModuleSpec object if the finder knows if the module to be introduced is being processed. This object has two properties worth mentioning, one is the name of the module, while the other is the finder. If the finder of a ModuleSpec object is None, then an exception like ImportError: missing loader will be thrown. The finder will be used to create and execute a module.
The module spec has two main roles.
- Passing – state information can be passed between different components of the import system, such as finder and loader
- template building – the import mechanism can perform template loading based on module spec, which the loader would have to do without module spec.
The module spec is exposed through the __spec__ attribute of the module object.
return
|
|
loader object
loader is an instance of mportlib.abc.Loader and is responsible for providing the most critical loading functionality: module execution. Its exec_module() method accepts a single argument – the module object – and all its return values are ignored.
The loader must satisfy the following conditions.
- If the module is a Python module (as distinguished from built-in modules and dynamically loaded extensions), the loader should execute the module code in the module’s global namespace (
__dict__). - If the loader cannot execute the module, an ImportError exception should be thrown.
Two changes in Python 3.4.
- The loader provides create_module() to create a module object (accepts a module spec object and returns the module object). If None is returned, the import mechanism creates the module itself. This is because the module object must exist in modules before the module can be executed.
- The load_module() method is replaced by the exec_module() method. For forward compatibility, the import mechanism uses the load_module() method only if load_module() exists and exec_module is not implemented.
Import the relevant module properties
In the _init_module_attrs step, the import mechanism populates the module object according to the module spec (this process happens before the loader executes the module).
| Properties | Description |
|---|---|
__name__ |
Fully qualified name of the module |
__loader__ |
The loader object used when the module is loaded, mainly for introspection |
__package__ |
Replaces __name__ for handling relative imports, must be set! When importing packages, this value is the same as __name__; when importing child packages, it is their parent’s name; when it is a top-level module, it should be the empty string |
__spec__ |
The module spec object to use when importing |
__path__ |
If the module is a package, it must be set! This value is an iterable object and can be null if there is no further use for it, otherwise the iteration result should be a string |
__file__ |
Optional, only built-in modules can be set without the __file__ attribute |
__cached__ |
is the path to the compiled bytecode file, which is independent of the existence of __file__. |
Before namespace packages came out, if you wanted to implement namespace package functionality, you generally modified its __path__ attribute in the package’s __init__.py. With the introduction of PEP420, namespace packages can no longer require this operation in __init__.py.
PEP 302: New import hook
Please see https://www.python.org/dev/peps/pep-0302/
Resource Imports
Sometimes you will have code that depends on data files or other resources. In a small script, this is not a problem - you can specify the path to the data file and go on! However, if the resource file is important to your package and you want to distribute your package to other users, a number of challenges arise.
- You will have no control over the path to the resources, as it depends on your user’s settings and how the package is distributed and installed. You can try to figure out the resource path based on your package
__file__or__path__attribute, but this may not always work as expected. - Your package may be located in a ZIP file or an old .egg file, in which case the resource will not even be a physical file on the user’s system.
There have been multiple attempts to address these challenges, including setuptools.pkg_resources. However, with the introduction of the Python 3.7 importlib.resources standard library, there is now a standard way to handle resource files.
Introduction to importlib.resources
importlib.resources allows access to the resources inside the package. In this case, the resources are any file located in the importable package. The file may or may not correspond to a physical file on the file system. This has several advantages. By reusing the import system, you get a more consistent way to work with the files in the package. It also allows you to access resource files in other packages more easily. If you can import a package, you can access the resources in that package.
importlib.resources became part of the Python 3.7 standard library. However, on older versions of Python, it can be installed by installing importlib_resources.
There is one requirement for using importlib.resources: your resource files must be available in the regular package. Namespace packages are not supported. In practice, this means that the files must be located in the directory containing the __init__.py file.
As a first example, suppose you have resources in a package, as follows.
__init__.py is just an empty file that needs to specify books as a regular package.
You can open text and binary files using open_text() and open_binary(), respectively.
open_text() and open_binary() are equivalent to the built-in open() with the described mode parameter sets rt and rb respectively. The convenient function to read text or binary files directly is also available as read_text() and read_binary().
To import on older Python versions you can use the following methods.
Import Tips and Tricks
Handling packages across Python versions
Sometimes you need to handle packages with different names depending on the Python version. As long as the different versions of the package are compatible, you can rename the package to as.
In the rest of the code, you can refer to resources without worrying that you are using importlib.resources or importlib_resources.
It is usually easiest to use the try…except statement to determine which version to use. Another option is to check the version of the Python interpreter. However, this may add some maintenance costs if you need to update the version number.
Handling lost packages: using alternative methods
Suppose there is a compatible re-implementation of a package. The re-implementation is better optimized, so you want to use it when it is available. However, the original package is more readily available and also offers acceptable performance.
One such example is quicktions, which is an optimized version of fractions from the standard library. You can handle these preferences as you did before with different package names.
Another similar example is the UltraJSON package, an ultra-fast JSON encoder and decoder that can be used as a replacement in the json standard library at
By renaming ujson to json, you don’t have to worry about which package is actually being imported.