In this paper, we would like to present a paper from the 2018 ATC Journal – NanoLog: A Nanosecond Scale Logging System, which implements NanoLog, a high-performance logging system that can perform 1 ~ 2 orders of magnitude better than other logging systems in the C++ community, e.g., spdlog, glog, and Boost Log. In this article, we will briefly analyze the design and implementation principles of NanoLog.
Logging is an important part of system observability, and I’m sure many engineers have had the experience of adding logs on the fly to check for problems, a process the author has just re-visited.
Printing logs is a simple task, and almost all engineers learn how to print strings to standard output using functions such as printf from the first day they start programming, and in 99% of programs this is used without performance problems, except in production environments where we use a structured, easy-to-parse format instead of printf, e.g., adding information such as timestamps, filenames, and line numbers to the logs.

But the remaining 1% of programs require ultra-low latency systems, where response time requirements can be in the microsecond or even nanosecond range. In this scenario, if the logging system is still needed to provide observability, we need to delve into the details of writing logs to standard output or files, such as using buffers, writing to files asynchronously, and reducing the use of dynamic features such as reflection, in addition to ensuring that log output is sequential and avoiding lost or truncated messages.
While spdlog, glog and Boost Log already meet the needs of most applications, for these latency machine-sensitive applications, the few microseconds needed to print the log can significantly increase the processing time of the request and affect the performance of the application.
Architecture Design
NanoLog is able to print logs on a nanosecond scale because it can extract static log messages during compilation and handle issues such as formatting of the logs during the offline phase. Its core optimizations are all built on two conditions.
- that formatted logs directly readable by developers do not have to be generated directly at application runtime; we can record the dynamic parameters of the logs during runtime and generate them on-demand afterwards.
- the vast majority of information in log messages is statically redundant, with only a few parameters changing, and we can obtain the static contents of the log during compilation and print it only once in the post-processor.
It is because most logs follow the above characteristics that NanoLog can build on them to achieve nanosecond-scale log printing. the different design approach of NanoLog dictates that it will differ significantly in architecture from traditional logging modules, and it consists of three components.
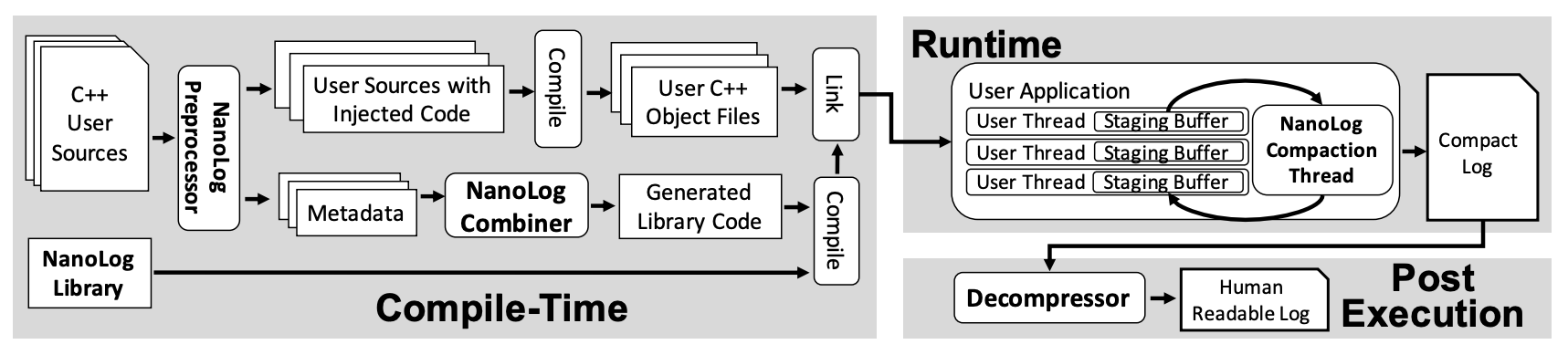
- Preprocessor: extracts log messages from source code during compilation, replaces raw log statements with optimized code, and generates compressed, dictionary helper functions for each log message.
- Runtime library: caches logs printed by multiple threads in a buffer and outputs compressed binary logs using helper functions generated in the preprocessing phase.
- Decoder: decodes the logs using a dictionary containing static information generated in the preprocessing phase to obtain logs that can be read by humans.
However, NanoLog breaks this traditional design by migrating some of the operations to compile-time and post-run in order to reduce run-time overhead, following the Law of Conservation of Work Quality: work does not disappear into thin air, it just moves from run-time to other phases of the program life cycle.
- rewriting logging statements at compile time to remove static information and deferring expensive formatting operations to a post-running phase of the code, which can reduce significant computational and I/O bandwidth requirements at runtime.
- compiles specific code for each log message, enabling efficient handling of dynamic parameters and avoiding parsing log messages and encoding parameter types at runtime.
- reduced runtime I/O and processing time using lightweight compression algorithms and out-of-order logging.
- generating readable logs using a post-processing combination of compressed log data and static information extracted at compile time.
Implementation Principles
In this section we will briefly analyze the implementation principles of the three main components of the NanoLog system, namely pre-processing, runtime and post-processing.
Preprocessing
NanoLog uses Python to implement the preprocessor. The entry point for the program is in processor/parser, which scans the user’s source files, generates metadata files and modified source code, and then compiles the modified code into .so or .a files instead of instead of compiling the initial code. In addition, the preprocessor reads all generated metadata files, generates C++ source code and compiles it into the NanoLog runtime library and finally into the user program.
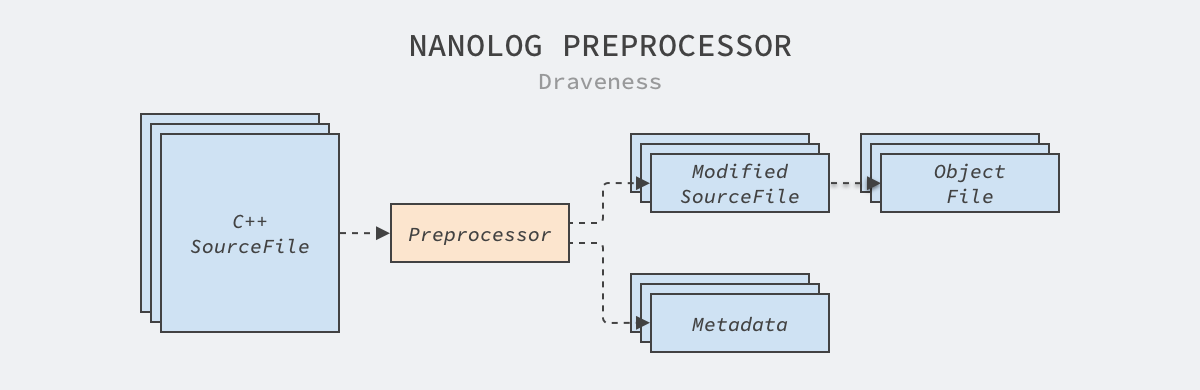
It generates two statements for each NANO_LOG in the source code, record and compress, where the former records the dynamic parameters in the log and the latter compresses the recorded data to reduce the program’s I/O time. Here is the record function generated by the preprocessor.
|
|
Each function contains a specific fmtId, and the logs are compressed and decompressed using the identifiers generated here. The above functions also allocate memory space for the arguments and call recordPrimitive in order to record all arguments into a buffer. The compress used for compression follows a similar logic.
|
|
The logging and compression functions are generated by Python’s preprocessor parsing the source code, and the NANO_LOG used by the engineer at the beginning is expanded into new code by the preprocessor, which has very similar functionality to the C++ preprocessor, except that the code that needs to be expanded here is so complex that it’s hard to implement in C++ using the preprocessor.
Runtime
The application’s statically linked NanoLog runtime decouples low-latency record operations that record dynamic parameters from high-latency operations such as disk I/O through a buffer on the thread. The buffer on the thread stores the results of record method calls, which are also visible to the background compression threads.
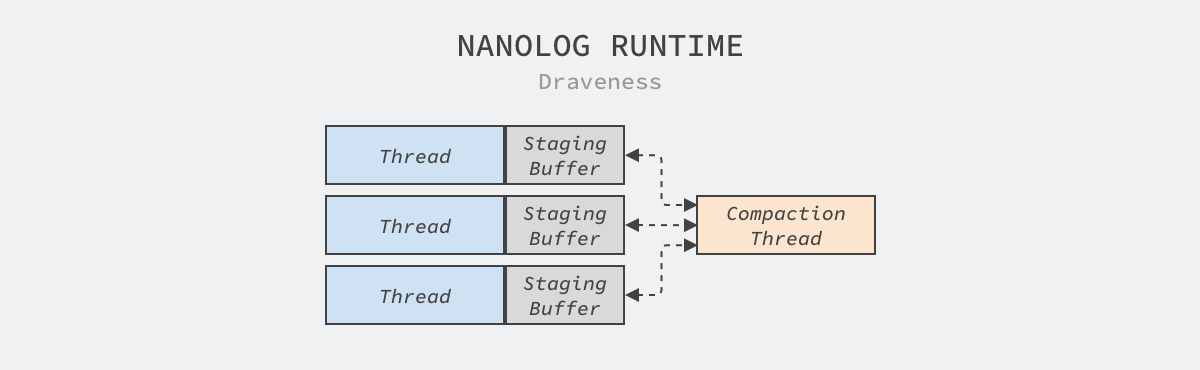
The buffer used for staging data on the thread is the key to improve the performance of the program. We want to meet the additional overhead of avoiding lock contention and cache coherency as much as possible, and the staging buffer uses a ring queue and a single-producer consumer model to reduce the synchronization overhead of data.
A ring queue is a continuous, fixed-size cache data structure with connected heads and tails, ideal for caching data streams. The Linux kernel uses this data structure as a read/write buffer for sockets2 , and audio and video also use ring queues to temporarily store data that has just been received and not yet decoded.
The runtime not only improves performance with a lock-free ring queue, but also needs to address the consumption of logs in the ring queue. To improve the processing power of background threads, the runtime defers the assembly of logs to post-processing and compresses log data to reduce the impact of high I/O latency.
Post-processing
The post-processor is relatively simple to implement, as each log contains a specific identifier, based on which the post-processor finds the compile-time information in the compressed log header, and expands and decompresses the log based on that information.
Note that because each thread has its own staging buffer to store the logs during runtime, the logs that NanoLog eventually prints are not strictly chronological; it only ensures that the log output is in a generally ordered order.
Summary
NanoLog is a very interesting and worthwhile logging system, but it is not suitable for all projects. It shifts the work that needs to be done at runtime to the compilation and post-processing stages, reducing the burden on the program at runtime, but its output binary logs are not directly readable, which also increases the workload of the developer in handling logs.
Although it is mentioned in the paper that log analysis engines basically collect, parse and analyze logs that engineers can read directly, and most of the time is spent on reading and parsing logs, using binary logs not only reduces the time spent on reading and parsing, but also reduces expensive I/O and bandwidth usage, but whether this is an advantage in our system is a matter of opinion.
Using a binary output format for logs does reduce costs in many ways, but it not only requires the support of a log collection and parsing system, but also sacrifices the developer’s local debugging experience, and without a module that automatically collects and decompresses logs, manually decompressing online logs to troubleshoot problems is a very bad experience, but in extreme performance scenarios we may not have much choice, even at the expense of the experience may have to be on.