This paper is about the paper in the 2020 OSDI Journal – Twine: A Unified Cluster Management System for Shared Infrastructure, which implements Twine, Facebook’s cluster management system for production environments for the past decade. Prior to the advent of this system, Facebook’s clusters consisted of separate resource pools customized for the business, which could not be shared with other businesses because the machines in these pools might have separate versions or configurations.
Twine solves the problem of different machine configurations in different resource pools by providing the ability to dynamically configure machines, which allows for the merging of otherwise separate resource pools, improving overall resource utilization, and configuring machines as needed when a business requests resources, e.g., changing kernel versions, enabling HugePages, and CPU Turbo features.
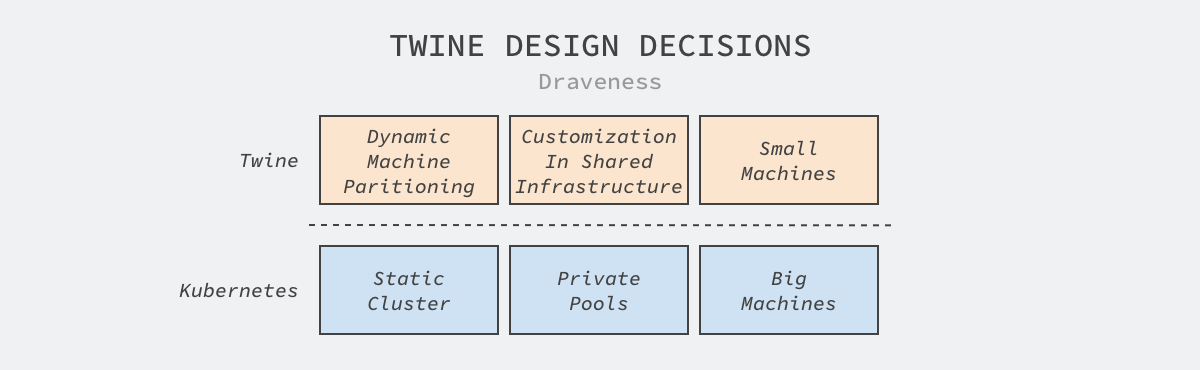
Kubernetes is a very popular cluster management solution today, but Facebook’s solution Twine makes the opposite decision from Kubernetes and implements a very different solution. It is important to note that using Kubernetes does not necessarily mean using static clusters, private node pools, and high-capacity machines; we can still implement features such as dynamic clusters by introducing other modules, but Kubernetes itself does not support these designs. We will only discuss the first two of these three decisions in this article and how Twine enables horizontal scaling and managing large scale clusters.
Architecture Design
As the core scheduling management system that can manage millions of machines and support Facebook’s business, Twine’s ecosystem is very complex, and we briefly describe here some of the core components of the system.
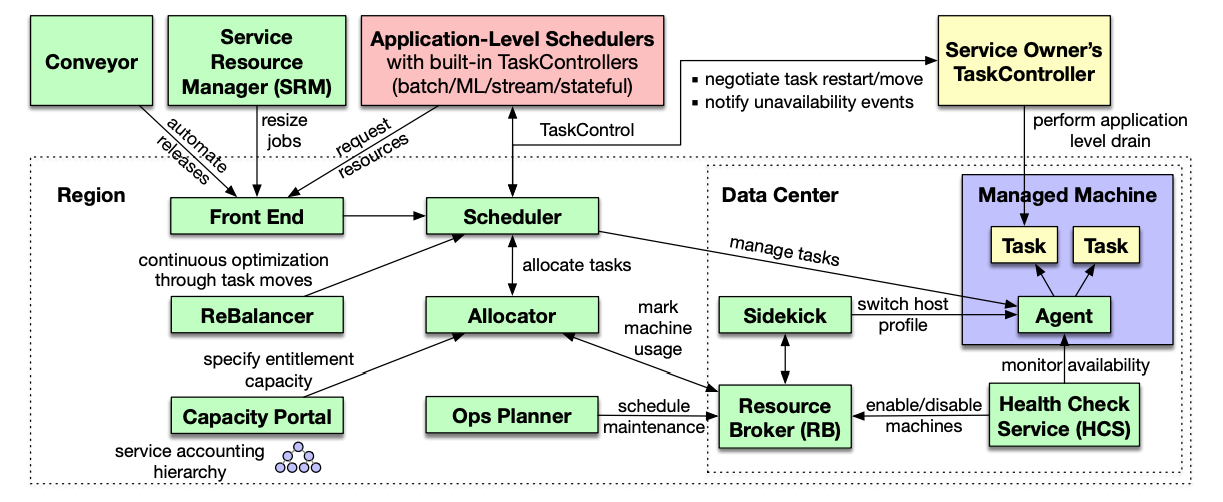
- Allocator: corresponds to the scheduler in Kubernetes, which is responsible for allocating machines to the workload, maintains the indexes and attributes of all machines in memory and handles the scheduling of resource allocation using multiple threads.
- Scheduler: corresponds to the controller in Kubernetes, which is responsible for managing the lifecycle of the workload and driving the system to respond when the cluster experiences hardware failures, routine maintenance, etc.
- Application-Level Schedulers: corresponding to Operators in Kubernetes. If we want to use special logic to manage stateful services, we need to implement custom schedulers.
Dispensers, schedulers and application schedulers are the core components of the Twine system, however, in addition to these components, the ecology also contains front-end interfaces, balancers for optimizing cluster workloads and services for specifying specific business capacities. After understanding these specific components, here we discuss the design of Twine around the dynamic clustering and custom configuration proposed at the beginning of the article.
Dynamic clustering
Twine’s dynamic clustering is built on its abstraction of Entitlement, where each Entitlement cluster contains a set of dynamically assigned machines, belonging to a business-specific pseudo-cluster. This layer of abstraction between machines and tasks in the data center makes the allocation of machines more dynamic.
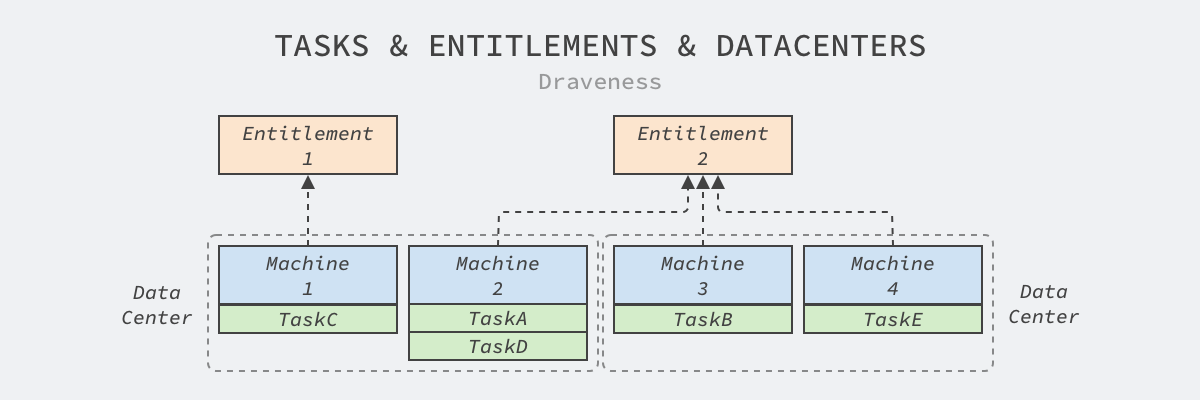
The distributor will not only assign machines to entitlement clusters, but will also schedule workloads within the same entitlement cluster to specific machines.
Note that we have simplified the model in Twine here, Facebook’s data center will consist of dozens of Main Switchboards (MSBs) with independent power supply and network isolation, and the machines on the switchboards can be seen as belonging to the same cluster.
Custom Configuration
Private node pools are not conducive to machine sharing, but there are indeed many business requirements for machine kernel versions and configurations, e.g., many machine learning or data statistics tasks require HugePages for Linux to optimize performance, but HugePages may compromise the performance of online services.
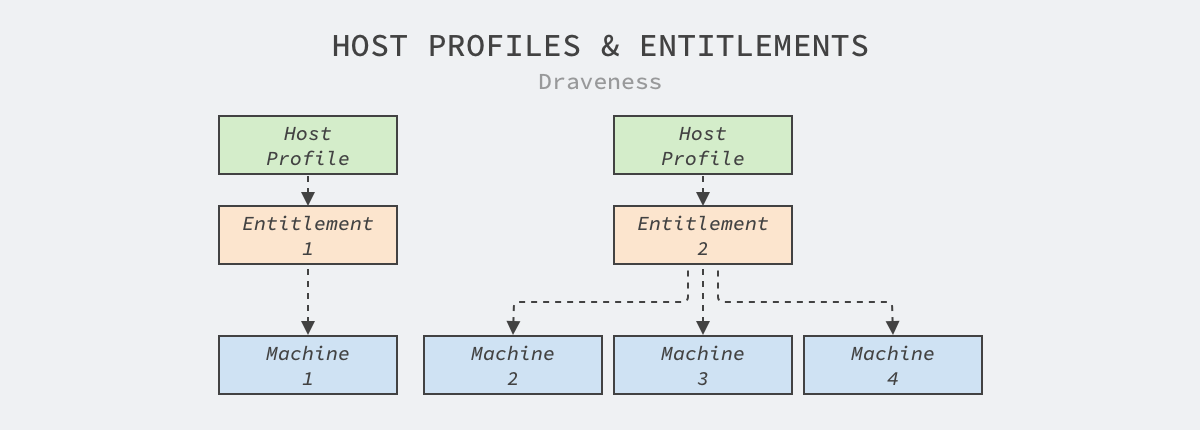
Twine thus introduces the concept of host configuration, binding individual host configurations for each entitlement cluster, and when machines in the data center are assigned to a pseudo-cluster, they are updated based on the cluster’s configuration to provide the workload with the most responsive operating environment, which improves the performance of web tier services by 11% within Facebook and is not met by the current Kuberentes.
Cluster Size
Facebook’s cluster size is also currently the world’s leading. Although the current cluster size has not yet exceeded one million, with the rapid growth of business, Twine will soon need to support the management of one million physical machines, and it will support nodes of this order of magnitude through the following two principles.
- Horizontal scaling by slicing by rights clusters.
- reducing the workload of the scheduling system by separating concerns.
Slicing
Slicing is the most common way for clusters or systems that want to achieve horizontal scaling. Twine is sliced in the dimension of entitlement clusters in order to support horizontal scaling; as a virtual cluster, Twine can migrate entitlement clusters between slices without restarting tasks on the machines, however, migration across entitlement clusters requires rolling update support.
The horizontal scaling of cluster management systems is made non-trivial by sharding, and Twine manages 170,000 machines in its largest shard, which is nearly two orders of magnitude away from the 5,000 nodes Kubernetes can support.
The Kubernetes community’s federation allows the same task to run in multiple independent clusters and can support multi-region, hybrid cloud or even multi-cloud deployments, but it is relatively complex to implement because of the need to synchronize information across clusters; Twine’s scheduler can dynamically migrate new machines when there are not enough machines in a slice. Twine’s scheduler can dynamically migrate new machines when there are not enough machines in a slice, so it is possible to use a single scheduler to manage all copies of a service. We will not discuss the advantages and disadvantages of the two solutions here, you can think about them yourself, but the authors still prefer to manage multiple clusters through the federation.
Separation of concerns
Kubernetes is a centralized architecture where all components read or write information from the API servers in the cluster and all data is stored in separate persistent storage systems, and the centralized architecture and storage systems become bottlenecks in Kubernetes cluster management.
Twine was designed to avoid centralized storage systems and separate the responsibilities of individual components into schedulers, allocators, resource agents, health check services, and host configuration services, each with a separate storage system, which avoids the scaling problems associated with a single storage system.
Summary
With Kubernetes on the rise, it was interesting to see Facebook share the different designs of its internal cluster management system, which made us rethink potential problems with the design in Kubernetes, such as centralized etcd storage, where many large companies using Kubernetes choose to modify the source code of etcd or replace the storage system in order to allow them to manage more nodes.
Kubernetes is a great benefit for companies with smaller clusters, and while it does solve 95% of the problems in cluster management, Kubernetes is not a silver bullet, and it cannot solve all the problems in the scenario. When applying Kubernetes, small and medium-sized companies can receive the Kubernetes architecture and settings wholesale, while large companies can do some customization based on Kubernetes and even participate in the development of standards to increase their technical influence, improve their voice and help support their business growth.