In the process of data crawling, often encountered the need to parse the content of HTML, commonly used is to use regular expressions, today mainly to introduce the lxml tool and the syntax of xpath.
Introduction to lxml
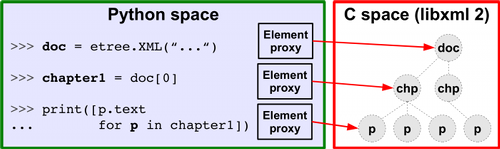
lxml is a high-performance Python XML library that natively supports XPath 1.0, XSLT 1.0, custom element classes, and even a Python style data binding interface. It is built on top of two C libraries: libxml2 and libxslt, which provide the main power for performing core tasks such as parsing, serialization, and conversion. installation in a Linux environment is relatively simple, just run pip install lxml.
lxml installation under Windows
When installing Scrapy on Windows, we also encounter the problem that lxml cannot be installed. The following message error is reported.
‘xslt-config’ is not an internal or external command, nor a runnable program or batch file
The VC compiler was not found and could not be installed.
Solution, go to https://www.lfd.uci.edu/~gohlke/pythonlibs/ to download and install the compiled binary package.
lxml usage
First, we use it to parse HTML code. Let’s start with a small example to get a feel for its basic usage.
|
|
First we use lxml’s etree library, then we initialize it with etree.HTML, and then we print it out. Here we have a very useful feature of lxml, which is auto-correction of html code. lxml inherits the feature of libxml2, which has the function of auto-correction of html code. So the output is.
|
|
Not only the li tag is completed and the br tag is modified, but also the body and html tags are added.
In addition to reading strings directly, we also support reading content from files. Use parse method to read files:
You can get the same result.
Using xpath in lxml (what exactly xpath is will be described in detail below) is very simple, as follows.
|
|
The output results are.
|
|
Introduction to xpath
XPath is a language for finding information in XML documents. XPath can be used to traverse elements and attributes in XML documents. XPath is a key element of the W3C XSLT standard, and both XQuery and XPointer are built on top of XPath expressions are built on top of XPath expressions.
XPath uses path expressions to select nodes in an XML document. Nodes are selected by following a path or step. The following is a list of the most useful path expressions.
| expression | description |
|---|---|
| nodename | Selects all child nodes of this node. |
| / | Selects from the root node. |
| // | Selects nodes in the document from the current node of the matching selection, regardless of their position. |
| . | / |
| … | Selects the parent node of the current node. |
| @ | Selects the attribute. |
In the following table, we have listed some path expressions and the results of the expressions.
| path expression | result |
|---|---|
| bookstore | Selects all child nodes of the bookstore element. |
| /Note: If the path starts with a forward slash ( / ), then this path always represents an absolute path to an element! | bookstore |
| bookstore/book | Fetch all book elements that are children of bookstore. |
| //book | selects all book child elements, regardless of their position in the document. |
| bookstore//book | Selects all book elements that are descendants of bookstore elements, regardless of where they are located under bookstore. |
| //@lang | Selects all attributes named lang. |
The predicate is used to find a specific node or a node that contains a specified value. The predicate is embedded in square brackets. In the following table, we list some path expressions with predicates, and the results of the expressions.
| path expression | result |
|---|---|
| /bookstore/book[1] | Selects the first book element that belongs to the bookstore child element. |
| bookstore/book[last()] | Fetch the last book element that belongs to the bookstore sub-element. |
| bookstore/book[last()-1] | Fetch the penultimate book element that belongs to the bookstore sub-element. |
| /bookstore/book[position()<3] | First two book elements that are children of the bookstore element. |
| /title[@lang] | Selects all title elements that have an attribute named lang. |
| /t/title[@lang=‘eng’] | Selects all title elements that have a lang attribute with the value eng. |
| /bookstore/book[price>35.00] | Selects all book elements of the bookstore element whose price element has a value greater than 35.00. |
| /bookstore/book[price>35.00]/title | Selects all title elements of the book element in the bookstore element whose price element has a value greater than 35.00. |
The XPath wildcard can be used to select unknown XML elements.
| -wildcard | description |
|---|---|
| * | Matches any element node. |
| @* | Matches any attribute node. |
| node() | Match any type of node. |
In the following table, we list some path expressions, and the results of these expressions.
| path expression | result |
|---|---|
| /bookstore/* | Selects all child elements of the bookstore element. |
| //* | Selects all elements in the document. |
| //title[@*] | Selects all title elements with attributes. |
By using the “|” operator in a path expression, you can pick several paths. In the following table, we list some path expressions and the results of these expressions.
| path expression | result |
|---|---|
//book/title | //book/price |
Selects all title and price elements of the book element. |
/title | //price |
Selects all title and price elements in the document. |
/bookstore/book/title | //price |
Selects all title elements of the book element that are part of the bookstore element, and all price elements in the document. |
The following is a list of operators that can be used in XPath expressions.
| operator | description | instance | return value |
|---|---|---|---|
| | | computes the set of two nodes | //book | //cd |
| + | addition | 6 + 4 | 10 |
| - | subtraction | 6 - 4 | 2 |
| * | multiply | 6 * 4 | 24 |
| div | divide | 8 div 4 | 2 |
| = | equals | price=9.80 | Returns true if price is 9.80. Returns false if price is 9.90. |
| ! = | not equal to | price!=9.80 | Returns true if price is 9.90. returns false if price is 9.80. |
| < | is less than | price<9.80 | Returns true if price is 9.00. Returns false if price is 9.90. |
| <= | Less than or equal to | price<=9.80 | Returns true if price is 9.00. Returns false if price is 9.90. |
| > | greater than | price>9.80 | Returns true if price is 9.90. returns false if price is 9.80. |
| >= | greater than or equal to | price>=9.80 | Returns true if price is 9.90. Returns false if price is 9.70. |
| or | or | price=9.80 or price=9.70 | Returns true if price is 9.80. Returns false if price is 9.50. |
| and | with | price>9.00 and price<9.90 | Returns true if price is 9.80. Returns false if price is 8.50. |
| mod | Calculates the remainder of the division | 5 mod 2 | 1 |