In the data crawl will often use regular expressions, if not familiar with Python’s re module, it is easy to be confused by the various methods inside, today we will review the Python re module.

Before learning the Python module, let’s see what the official description documentation says Implementation.
Helpful information.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
|
Help on module re:
NAME
re - Support for regular expressions (RE).
FILE
c:\python27\lib\re.py
DESCRIPTION
This module provides regular expression matching operations similar to
those found in Perl. It supports both 8-bit and Unicode strings; both
the pattern and the strings being processed can contain null bytes and
characters outside the US ASCII range.
Regular expressions can contain both special and ordinary characters.
Most ordinary characters, like "A", "a", or "0", are the simplest
regular expressions; they simply match themselves. You can
concatenate ordinary characters, so last matches the string 'last'.
The special characters are:
"." Matches any character except a newline.
"^" Matches the start of the string.
"$" Matches the end of the string or just before the newline at
the end of the string.
"*" Matches 0 or more (greedy) repetitions of the preceding RE.
Greedy means that it will match as many repetitions as possible.
"+" Matches 1 or more (greedy) repetitions of the preceding RE.
"?" Matches 0 or 1 (greedy) of the preceding RE.
*?,+?,?? Non-greedy versions of the previous three special characters.
{m,n} Matches from m to n repetitions of the preceding RE.
{m,n}? Non-greedy version of the above.
"\\" Either escapes special characters or signals a special sequence.
[] Indicates a set of characters.
A "^" as the first character indicates a complementing set.
"|" A|B, creates an RE that will match either A or B.
(...) Matches the RE inside the parentheses.
The contents can be retrieved or matched later in the string.
(?iLmsux) Set the I, L, M, S, U, or X flag for the RE (see below).
(?:...) Non-grouping version of regular parentheses.
(?P<name>...) The substring matched by the group is accessible by name.
(?P=name) Matches the text matched earlier by the group named name.
(?#...) A comment; ignored.
(?=...) Matches if ... matches next, but doesn't consume the string.
(?!...) Matches if ... doesn't match next.
(?<=...) Matches if preceded by ... (must be fixed length).
(?<!...) Matches if not preceded by ... (must be fixed length).
(?(id/name)yes|no) Matches yes pattern if the group with id/name matched,
the (optional) no pattern otherwise.
The special sequences consist of "\\" and a character from the list
below. If the ordinary character is not on the list, then the
resulting RE will match the second character.
\number Matches the contents of the group of the same number.
\A Matches only at the start of the string.
\Z Matches only at the end of the string.
\b Matches the empty string, but only at the start or end of a word.
\B Matches the empty string, but not at the start or end of a word.
\d Matches any decimal digit; equivalent to the set [0-9].
\D Matches any non-digit character; equivalent to the set [^0-9].
\s Matches any whitespace character; equivalent to [ \t\n\r\f\v].
\S Matches any non-whitespace character; equiv. to [^ \t\n\r\f\v].
\w Matches any alphanumeric character; equivalent to [a-zA-Z0-9_].
With LOCALE, it will match the set [0-9_] plus characters defined
as letters for the current locale.
\W Matches the complement of \w.
\\ Matches a literal backslash.
This module exports the following functions:
match Match a regular expression pattern to the beginning of a string.
search Search a string for the presence of a pattern.
sub Substitute occurrences of a pattern found in a string.
subn Same as sub, but also return the number of substitutions made.
split Split a string by the occurrences of a pattern.
findall Find all occurrences of a pattern in a string.
finditer Return an iterator yielding a match object for each match.
compile Compile a pattern into a RegexObject.
purge Clear the regular expression cache.
escape Backslash all non-alphanumerics in a string.
Some of the functions in this module takes flags as optional parameters:
I IGNORECASE Perform case-insensitive matching.
L LOCALE Make \w, \W, \b, \B, dependent on the current locale.
M MULTILINE "^" matches the beginning of lines (after a newline)
as well as the string.
"$" matches the end of lines (before a newline) as well
as the end of the string.
S DOTALL "." matches any character at all, including the newline.
X VERBOSE Ignore whitespace and comments for nicer looking RE's.
U UNICODE Make \w, \W, \b, \B, dependent on the Unicode locale.
This module also defines an exception 'error'.
CLASSES
exceptions.Exception(exceptions.BaseException)
sre_constants.error
class error(exceptions.Exception)
| Method resolution order:
| error
| exceptions.Exception
| exceptions.BaseException
| __builtin__.object
|
| Data descriptors defined here:
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Methods inherited from exceptions.Exception:
|
| __init__(...)
| x.__init__(...) initializes x; see help(type(x)) for signature
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from exceptions.Exception:
|
| __new__ = <built-in method __new__ of type object>
| T.__new__(S, ...) -> a new object with type S, a subtype of T
|
| ----------------------------------------------------------------------
| Methods inherited from exceptions.BaseException:
|
| __delattr__(...)
| x.__delattr__('name') <==> del x.name
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __getitem__(...)
| x.__getitem__(y) <==> x[y]
|
| __getslice__(...)
| x.__getslice__(i, j) <==> x[i:j]
|
| Use of negative indices is not supported.
|
| __reduce__(...)
|
| __repr__(...)
| x.__repr__() <==> repr(x)
|
| __setattr__(...)
| x.__setattr__('name', value) <==> x.name = value
|
| __setstate__(...)
|
| __str__(...)
| x.__str__() <==> str(x)
|
| __unicode__(...)
|
| ----------------------------------------------------------------------
| Data descriptors inherited from exceptions.BaseException:
|
| __dict__
|
| args
|
| message
FUNCTIONS
compile(pattern, flags=0)
Compile a regular expression pattern, returning a pattern object.
escape(pattern)
Escape all non-alphanumeric characters in pattern.
findall(pattern, string, flags=0)
Return a list of all non-overlapping matches in the string.
If one or more groups are present in the pattern, return a
list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result.
finditer(pattern, string, flags=0)
Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a match object.
Empty matches are included in the result.
match(pattern, string, flags=0)
Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found.
purge()
Clear the regular expression cache
search(pattern, string, flags=0)
Scan through string looking for a match to the pattern, returning
a match object, or None if no match was found.
split(pattern, string, maxsplit=0, flags=0)
Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings.
sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used.
subn(pattern, repl, string, count=0, flags=0)
Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in the source
string by the replacement repl. number is the number of
substitutions that were made. repl can be either a string or a
callable; if a string, backslash escapes in it are processed.
If it is a callable, it's passed the match object and must
return a replacement string to be used.
template(pattern, flags=0)
Compile a template pattern, returning a pattern object
DATA
DOTALL = 16
I = 2
IGNORECASE = 2
L = 4
LOCALE = 4
M = 8
MULTILINE = 8
S = 16
U = 32
UNICODE = 32
VERBOSE = 64
X = 64
__all__ = ['match', 'search', 'sub', 'subn', 'split', 'findall', 'comp...
__version__ = '2.2.1'
VERSION
2.2.1
|
Introduction to Regular Expressions
A regular expression is a logical formula for string manipulation, which is a pre-defined combination of some specific characters and these specific characters to form a “regular string”, which is used to express a filtering logic. Regular expressions are a very powerful tool for matching strings, and they are also used in other programming languages, and Python is no exception.
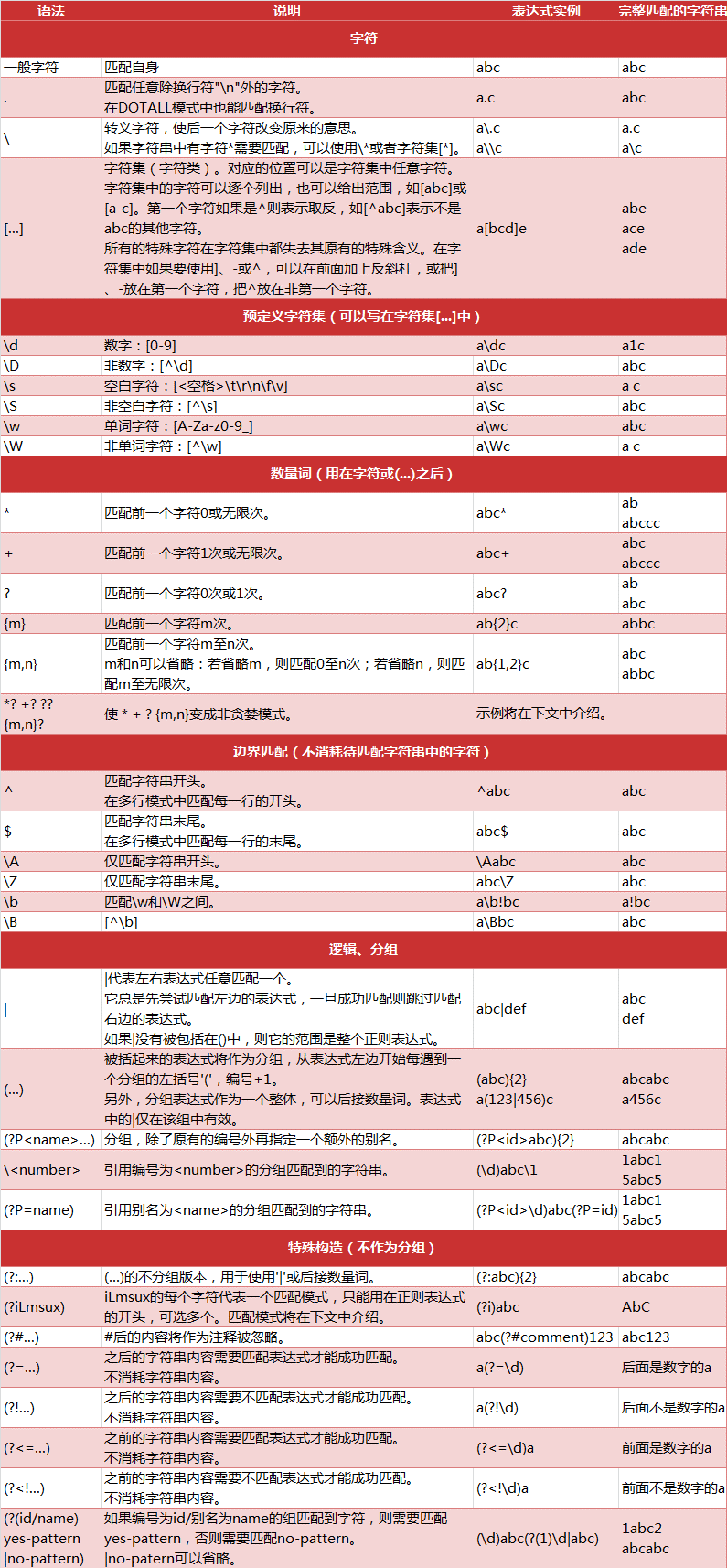
The following table lists the special elements of the regular expression pattern syntax. If you use a pattern with optional flag arguments, the meaning of some pattern elements will change.
Greedy and non-greedy modes for quantifiers
Regular expressions are typically used to find matching strings in text. the default in Python is greedy, always trying to match as many characters as possible. We generally use non-greedy patterns for extraction. Before I explain this concept, I’d like to show an example. We are looking for an anchor tag from a piece of html text.
1
2
3
4
5
|
import re
html = 'Hello <a href="https://www.biaodainfu.com">biaodianfu</a>'
m = re.findall('<a.*>.*<\/a>', html)
if m:
print(m)
|
Implementation results.
1
|
['<a href="https://www.biaodainfu.com">biaodianfu</a>']
|
Let’s change the input and add a second anchor tag.
1
2
3
4
5
|
import re
html = 'Hello <a href="https://www.biaodainfu.com">biaodianfu</a> | Hello <a href="https://www.google.com">Google</a>'
m = re.findall('<a.*>.*<\/a>', html)
if m:
print(m)
|
Implementation results.
1
|
['<a href="https://www.biaodainfu.com">biaodianfu</a> | Hello <a href="https://www.google.com">Google</a>']
|
This time the pattern matches the first open tag and the last closed tag and everything in between, making one match instead of two separate matches. This is because the default matching mode is “greedy”.
When in greedy mode, quantifiers (like * and +) match as many characters as possible. When you add a question mark at the end (. *?) it will become “non-greedy”.
1
2
3
4
5
|
import re
html = 'Hello <a href="https://www.biaodainfu.com">biaodianfu</a> | Hello <a href="https://www.google.com">Google</a>'
m = re.findall('<a.*?>.*?<\/a>', html)
if m:
print(m)
|
Implementation results.
1
|
['<a href="https://www.biaodainfu.com">biaodianfu</a>', '<a href="https://www.google.com">Google</a>']
|
Backslash problems
As with most programming languages, regular expressions use “" as an escape character, which can cause backslash problems. If you need to match the character “" in the text, you will need four backslashes “" in the regular expression using the programming language: the first two and the last two are used to escape to backslashes in the programming language, and then converted to two backslashes and then escaped to one backslash in regular expressions.
Python’s native strings solve this problem nicely, and the regular expression in this example can be represented by r”". Similarly, “\d” matching a number can be written as r”\d”.
Common methods in Python Re
re.compile(pattern, flags=0)
A Pattern (_sre.SRE_Pattern) object is a compiled regular expression that can be matched against text by a series of methods provided by Pattern. pattern cannot be instantiated directly and must be constructed using re.compile().
1
|
pattern = re.compile(r'hello')
|
The flag argument in re.compile is a match pattern, which allows you to modify the way a regular expression works. Multiple flags can be specified by OR-ing them by bit. For example, re.I | re.M is set to the I and M flags. Optional values are.
- I(full name: IGNORECASE): Make the match case-insensitive, and ignore case when matching letters in character classes and strings.
- L(full name: LOCALE): makes the intended character class \w \W \b \B \s \S depending on the current region setting. (Not commonly used)
- M(Full name: MULTILINE): Multi-line mode, change the behavior of ‘^’ and ‘$’.
- S(full name: DOTALL): point any match mode, change the behavior of ‘.’ behavior to make . matches all characters, including newlines.
- X(full name: VERBOSE): detail mode. This mode allows regular expressions to be multi-line, ignores whitespace, and can include comments.
- U (full name: UNICODE): makes \w, \W, \b, \B, \d, \D, \s and \S depend on the character attributes defined by UNICODE.
The match pattern can be numeric, and to satisfy multiple match patterns, the numbers are added together.
- I = IGNORECASE = 2
- L = LOCALE = 4
- M = MULTILINE = 8
- S = DOTALL = 16
- U = UNICODE = 32
- X = VERBOSE = 64
Details.
- L: locales is a feature in the C library that is used to provide assistance with programming that requires consideration of different languages. For example, if you are working with French text and you want to use \w+ to match text, but \w only matches the character class [A-Za-z]; it does not match “é” or “ç”. If your system is properly configured and the localization is set to French, then the internal C function will tell the program that “é” should also be considered a letter. Using the LOCALE flag when compiling regular expressions will result in compiling objects with these C functions to handle \w afterwards; it will be slower, but it will also match French text with \w+, as you would expect.
- M: Use “^” to match only the beginning of the string, and $ to match only the end of the string and the end of the string directly before the newline (if any). When this flag is specified, “^” matches the beginning of the string and the beginning of each line in the string. Likewise, the $ metacharacter matches the end of the string and the end of each line in the string.
- X: This flag makes your regular expressions easier to understand by giving you more flexible formatting. When this flag is specified, whitespace in the RE string is ignored unless it is in a character class or after a backslash; this allows you to organize and indent RE more clearly. it also allows you to write comments to RE that will be ignored by the engine; comments are identified by a “#” sign, but the sign cannot be after the string or after a backslash.
re.template(pattern, flags=0)
Template form compilation? Haven’t used it. Can’t find any more details either.
re.escape(pattern)
Application function that escapes all characters in a string that may be interpreted as regular operators. Use this function if the string is long and contains a lot of special technical characters, and you don’t want to enter a bunch of backslashes, or if the string comes from the user (e.g. by getting the input through the raw_input function) and is to be used as part of a regular expression.
1
2
|
import re
print(re.escape('www.biaodianfu.com'))
|
Implementation results.
re.purge()
Clear the cache of regular expressions
re.search(pattern, string, flags=0)
The re.search function looks for pattern matches within the string, only until it finds the first match and returns it, returning the _sre.SRE_Match object, or None if the string has no matches.
1
2
3
4
5
6
|
import re
pattern = re.compile(r'Hello')
result1 = re.search(pattern,'Hello World')
result2 = re.search(pattern,'Hello World, World Hello!')
print(result1)
print(result2)
|
Implementation results.
1
2
|
<_sre.SRE_Match object at 0x027AFA30>
<_sre.SRE_Match object at 0x027FDDB0>
|
How do I get to the contents of _sre.SRE_Match?
Match Object
The Match object is the result of a match and contains a lot of information about this match, which can be obtained using the readable properties or methods provided by Match.
Attributes.
- string: The text used in the match.
- re: The Pattern object used for the match.
- pos: The index of the regular expression in the text to start the search.
- endpos: The index at which the regular expression in the text ends the search.
- lastindex: index of the last captured grouping in the text. If there are no captured groups, it will be None.
- lastgroup: alias of the last captured group. Will be None if this group has no alias or there is no captured group.
Methods.
- group([group1, …]): gets the string intercepted by one or more groups; will be returned as a tuple when multiple arguments are specified. group can use either a number or an alias; number 0 represents the entire matching substring; returns group(0) when no arguments are filled in; returns None for groups with no intercepted strings. Groups that have intercepted multiple times return the last intercepted substring.
- groups([default]): return all intercepted strings in groups as a tuple. Equivalent to calling groups(1,2,…last). default means that groups with no intercepted strings are replaced with this value, default is None.
- groupdict([default]): Returns a dictionary with the alias of the group with alias as key and the intercepted substring of the group as value. groups without alias are not included. default means the same as above.
- start([group]): return the start index (index of the first character of the substring) of the intercepted substring of the specified group in string. group default is 0.
- end([group]): Returns the end index (index of the last character of the substring + 1) of the substring intercepted by the specified group in string. group defaults to 0.
- span([group]): returns (start(group), end(group)).
- expand(template): Substitute the matched group into template and return. \id or
\g<id>, \g<name> can be used to refer to the group in template, but not number 0. \id is equivalent to \g<id>; but \10 will be considered the 10th group, if you want to express \1 followed by character ‘0’, only \g<1>0 can be used.
re.match(pattern, string, flags=0)
Whether the beginning of a string can match a regular expression. Returns _sre.SRE_Match object, and None if it does not match. match method is very similar to search method, the difference is that match() function only detects if re matches at the beginning of the string, search() scans the whole string to find a match.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import re
pattern = re.compile(r'Hello')
result1 = re.match(pattern,'Hello')
result2 = re.match(pattern,'Hello World')
result3 = re.match(pattern,'World Hello')
if result1:
print(result1.group())
else:
print('1匹配失败!')
if result2:
print(result2.group())
else:
print('2匹配失败!')
if result3:
print(result3.group())
else:
print('3匹配失败!')
|
Implementation results
re.findall(pattern, string, flags=0)
Finds all the substrings matched by RE and returns them as a list. This match is returned in an ordered fashion from left to right. If there is no match, the empty list is returned.
1
2
3
|
import re
pattern = re.compile(r'\d+')
print(re.findall(pattern,'one1two2three3four4'))
|
Implementation results.
1
|
['1', '2', '3', '4'] ['1', '2', '3', '4']
|
re.finditer(pattern, string, flags=0)
Finds all substrings matched by RE and returns them as an iterator. This match is returned in an ordered fashion from left to right. If there is no match, the empty list is returned. Returns the _sre.SRE_Match object.
1
2
3
4
5
|
import re
pattern = re.compile(r'\d+')
results = re.finditer(pattern,'one1two2three3four4')
for result in results:
print(result)
|
Implementation results.
1
2
3
4
|
<_sre.SRE_Match object at 0x0336FA30>
<_sre.SRE_Match object at 0x033BDDB0>
<_sre.SRE_Match object at 0x0336FA30>
<_sre.SRE_Match object at 0x033BDDB0>
|
re.split(pattern, string, maxsplit=0, flags=0)
Separates strings by regular expressions. If the regular expression is enclosed in parentheses, the matching string will also be included in the list and returned. maxsplit is the number of separations, maxsplit=1 separates once, default is 0, no limit on the number of times.
1
2
3
|
import re
pattern = re.compile(r'\d+')
print(re.split(pattern,'one1two2three3four4'))
|
Implementation results.
1
|
['one', 'two', 'three', 'four', '']
|
re.sub(pattern, repl, string, count=0, flags=0)
Finds all substrings matched by RE and replaces them with a different string. The optional parameter count is the maximum number of substitutions after pattern matching; count must be a non-negative integer. The default value is 0 to replace all matches. If there are no matches, the string will be returned unchanged.
re.subn(pattern, repl, string, count=0, flags=0)
Works the same as the re.sub method, but returns a two-tuple containing the new string and the number of times the replacement was performed.
Reference.