When you think of Redis, you think of Memcached, and vice versa. Those who know both have a general impression that Redis supports simple key-value data types compared to Memcached, and also provides storage for data structures such as list, set, zset, and hash; redis supports data backup, redis supports data persistence, and it looks like redis is more powerful than memcached. The redis support for data backup, redis support for data persistence, looks redis than memcached more awesome, so in fact is this not the case?

Salvatore Sanfilippo, the author of Redis, has compared the two memory-based data storage systems.
- Redis supports server-side data manipulation : Redis has more data structures and and supports richer data manipulation than Memcached, where you usually need to take the data to the client to make similar changes and set it back. This greatly increases the number of network IO’s and the size of the data. In Redis, these complex operations are usually just as efficient as a normal GET/SET. So, if you need the cache to be able to support more complex structures and operations, then Redis would be a good choice.
- Memory Efficiency Comparison : Memcached has higher memory utilization when using simple key-value storage, while if Redis uses a hash structure for key-value storage, its memory utilization is higher than Memcached due to its combinatorial compression.
- Performance Comparison : Since Redis uses only a single core, while Memcached can use multiple cores, on average Redis per core has higher performance than Memcached when storing small data. And for data over 100k, Memcached performance is higher than Redis. Although Redis has recently been optimized for storing large data, it is still slightly inferior to Memcached.
The following information was collected on exactly why the above conclusion occurred.
Data type support is different
Unlike Memcached, which supports only simple key-value structured data records, Redis supports a much richer set of data types. The most commonly used data types consist of five main types: String, Hash, List, Set, and Sorted Set. redis internally uses a redisObject object to represent all keys and values. redisObject’s most important information is shown in the figure.
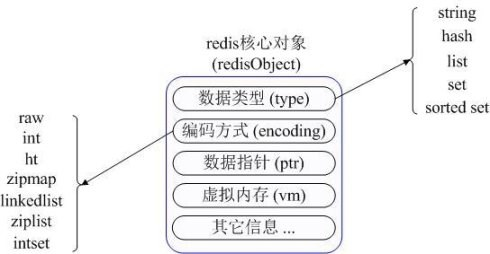
type represents the specific data type of a value object, encoding is a different data type in redis internal storage, for example: type=string represents the value is stored in a common string, then the corresponding encoding can be raw or int, if int is the actual redis The string is stored and represented internally as a numeric class, provided that the string itself can be represented by a numeric value, such as “123″ “456”. The vm field will only be allocated if Redis’ virtual memory feature is turned on, which is off by default.
String
- Common commands: set/get/decr/incr/mget, etc.
- Application scenario: String is one of the most commonly used data types, and ordinary key/value storage can be classified as such.
- Implementation: String is a string by default in redis internal storage, referenced by redisObject, when encountering incr, decr and other operations will be converted to a numeric type for calculation, at this time the encoding field of redisObject is int.
Hash
- Common commands: hget/hset/hgetall etc.
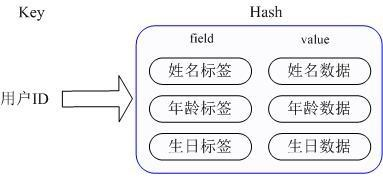
- Application scenario: we want to store a user information object data, which includes user ID, user name, age and birthday, by user ID we want to get the name or age or birthday of the user.
- Implementation: Redis’ Hash actually stores the Value internally as a HashMap and provides an interface to access this Map member directly. As shown in the figure, the Key is the user ID, the value is a Map. key of this Map is the attribute name of the member, and value is the attribute value. This way, data can be modified and accessed directly through the internal Map’s key (called the internal Map’s key as field in Redis), i.e., by using key(user ID) + field(attribute label) to manipulate the corresponding attribute data. There are two ways to implement the current HashMap: when the members of the HashMap are relatively small, Redis will use a compact storage method similar to a one-dimensional array in order to save memory, and will not use the real HashMap structure, when the corresponding value of the redisObject encoding is zipmap, when the number of members increases will automatically When the number of members increases, it will be automatically converted to a real HashMap, and the encoding will be ht.
List
- Common commands: lpush/rpush/lpop/rpop/lrange, etc.
- Application scenarios: Redis list is used in many scenarios and is one of the most important data structures of Redis, for example, twitter’s follow list, fan list, etc. can be implemented using the Redis list structure.
- Implementation: Redis list is implemented as a bi-directional chain table, i.e. it can support reverse lookup and traversal, which is more convenient to operate, but brings some additional memory overhead. Many implementations within Redis, including the send buffer queue, are also using this data structure.
Set
- Common commands: sadd/spop/smembers/sunion, etc.
- Application Scenario: Redis set provides external functionality similar to that of a list. The special feature is that set can be automatically weighted, so when you need to store a list of data and don’t want duplicate data, set is a good choice.
- Implementation: set’s internal implementation is a HashMap whose value is always null, which is actually a way to quickly rank weights by calculating hash, and this is the reason why set can provide a way to determine whether a member is within a set or not.
Sorted Set
- Common commands: zadd/zrange/zrem/zcard, etc.
- Application Scenario: Redis sorted set is similar to set, the difference is that set is not automatically ordered, while sorted set can be sorted for members with an additional priority (score) parameter provided by the user, and is inserted in an ordered, i.e., automatically sorted. When you need an ordered and non-repetitive list of collections, you can choose the sorted set data structure. For example, twitter’s public timeline can be stored with the time of publication as the score, so that it is automatically sorted by time when you get it.
- The Redis sorted set uses a HashMap and a SkipList to ensure that the data is stored and ordered. The HashMap contains the mapping of members to scores, while the SkipList stores all members, and the sorting is based on the scores stored in the HashMap.
Different memory management mechanisms
In Redis, not all data is stored in memory all the time. This is one of the biggest differences compared to Memcached. Redis only caches information about all the keys, and if Redis finds that memory usage exceeds a certain threshold, it triggers a swap operation, which is based on “swappability = age*log (size_in_memory)” to figure out which keys need to be swap to disk. The values corresponding to these keys are then persisted to disk and cleared in memory. This feature allows Redis to hold data that exceeds the size of the machine’s own memory. Of course, the machine’s own memory must be able to hold all of the keys; after all, this data is not subject to swap operations. Also, as Redis swaps data from memory to disk, the main thread providing the service and the child thread performing the swap share this memory, so if the data to be swap is updated, Redis will block the operation until the child thread completes the swap. When reading data from Redis, if the value corresponding to the key read is not in memory, then Redis needs to load the corresponding data from the swap file and return it to the requestor. There is a problem with I/O thread pooling here. By default, Redis blocks, i.e., it finishes loading all swap files before corresponding. This strategy is more appropriate when the number of clients is small and batch operations are performed. But if Redis is applied to a large web application, this is clearly not sufficient for large concurrent situations. So Redis runs us to set the size of the I/O thread pool to operate concurrently on read requests that require loading the appropriate data from the swap file, reducing the time spent blocking.
For memory-based database systems like Redis and Memcached, the efficiency of memory management is a key factor in system performance. The malloc/free functions in traditional C are the most commonly used methods to allocate and free memory, but this method has significant drawbacks: first, mismatched malloc and free are prone to memory leaks for developers; second, frequent calls can cause large amounts of memory fragments that cannot be reclaimed and reused, reducing memory utilization; and finally, as a system call, its system Finally, as a system call, its system overhead is much larger than the general function call. Redis and Memcached both use their own designed memory management mechanisms, but there are significant differences in their implementation methods, which are described below.
Memcached uses the Slab Allocation mechanism by default, which is designed to completely solve the memory fragmentation problem by dividing the allocated memory into blocks of a specific length to store key-value data records of a predefined size. This means that all key-value data is stored in the Slab Allocation system, while other memory requests from Memcached are requested through normal malloc/free, as the number and frequency of these requests determine that they do not affect the performance of the whole system. The principle of Slab Allocation is quite simple. As shown in the figure, it first requests a large chunk of memory from the operating system, splits it into chunks of various sizes, and divides the chunks of the same size into groups of Slab Classes, where the chunk is the smallest unit used to store key-value data. The size of each Slab Class can be controlled by setting the Growth Factor when Memcached is started. Assuming the value of Growth Factor is 1.25, if the size of the first group of Chunk is 88 bytes, the size of the second group of Chunk will be 112 bytes, and so on.

When Memcached receives data from the client, it first selects the most suitable Slab Class according to the size of the received data, and then finds a Chunk that can be used to store data by querying the list of free Chunks in that Slab Class kept by Memcached. When a database expires or is discarded, the Chunk occupied by the record can be reclaimed and added back to the free list. From the above process, we can see that Memcached’s memory management system is efficient and does not cause memory fragmentation, but its biggest drawback is that it leads to wasted space. Because each Chunk is allocated a specific length of memory space, variable length data cannot fully utilize this space. As shown in the figure, caching 100 bytes of data into a 128-byte Chunk results in the remaining 28 bytes being wasted.

Redis’ memory management is implemented through two files in the source code, zmalloc.h and zmalloc.c. After allocating a block of memory, Redis stores the size of that block into the header of the memory block for ease of memory management. As shown in the figure, real_ptr is the pointer returned by redis after calling malloc. redis stores the size of the memory block, size, into the header. the size of the memory occupied by size is known and is of type size_t length, and then returns ret_ptr. ret_ptr is passed to the memory manager when it is time to free the memory. With ret_ptr, the program can easily figure out the value of real_ptr and then pass real_ptr to free to release the memory.

Redis keeps track of all memory allocations by defining an array whose length is ZMALLOC_MAX_ALLOC_STAT. Each element of the array represents the number of memory blocks allocated by the current program, and the size of the block is the subscript of that element. In the source code, this array is zmalloc_allocations. zmalloc_allocations[16] represents the number of memory blocks of 16 bytes in length that have been allocated. zmalloc.c has a static variable used_memory to keep track of the total size of memory currently allocated. So, in summary, Redis uses a wrapped mallc/free, which is much simpler than Memcached’s memory management approach.
Data Persistence Support
Although Redis is a memory-based storage system, it supports in-memory data persistence itself and provides two main persistence strategies: RDB snapshots and AOF logging. And memcached does not support data persistence operation.
RDB Snapshot
Redis supports a persistence mechanism that saves a snapshot of the current data as a data file, i.e., an RDB snapshot. Redis relies on the copy on write mechanism of the fork command. When generating a snapshot, the current process forks a child process, then loops through all the data in the child process and writes the data to an RDB file. We can configure the timing of RDB snapshot generation through the Redis save command, for example, we can configure snapshots to be generated in 10 minutes, or we can configure snapshots to be generated when there are 1000 writes, or we can implement multiple rules together. The definition of these rules is in the Redis configuration file, and you can also set the rules at Redis runtime via the Redis CONFIG SET command, without restarting Redis.
Redis’ RDB file does not break because its write operations are performed in a new process. When a new RDB file is generated, the Redis-generated child process first writes the data to a temporary file and then renames the temporary file to an RDB file via the atomic rename system call, so that at any time there is a failure, Redis’ RDB file is always available. The RDB file is also part of the internal implementation of Redis master-slave synchronization, which has the disadvantage that if the database goes down, the data stored in our RDB file is not brand new, and all data from the last RDB file generation to the Redis downtime is lost. This can be tolerated in some businesses.
AOF Log
The full name of the AOF log is append only file, and it is an append-write log file. Unlike a typical database binlog, an AOF file is recognizable as plain text, and its contents are one Redis standard command after another. Only those commands that cause data to be modified are appended to the AOF file. Each command that modifies the data generates a log, and the AOF file grows larger and larger, so Redis provides a feature called AOF rewrite, which regenerates an AOF file so that a single operation is recorded only once in the new AOF file, unlike an old file that may record multiple operations on the same value. The generation process is similar to RDB, which also forks a process, directly traverses the data, and writes a new AOF temporary file. In the process of writing to the new file, all the write operation logs will still be written to the original old AOF file, and also recorded in the memory buffer. When the rename operation is complete, all the logs in the buffer are written to the temporary file at once. The atomic rename command is then called to replace the old AOF file with the new AOF file.
AOF is a write file operation whose purpose is to write the operation log to disk, so it also encounters the same process we described above for write operations. After calling write on an AOF in Redis, the time to call fsync to write it to disk is controlled by the appendfsync option. The following three setting items for appendfsync are progressively stronger in security.
- appendfsync no When appendfsync is set to no, Redis does not actively call fsync to synchronize the AOF log contents to disk, so it all becomes completely dependent on the debugging of the operating system. For most Linux operating systems, fsync is done every 30 seconds to write the data in the buffer to disk.
- appendfsync everysec When appendfsync is set to everysec, Redis makes a fsync call every second by default, writing the data in the buffer to disk. But when this fsync call is longer than one second, Redis adopts a delayed fsync policy and waits another second. That is, if the fsync is made after two seconds, the fsync will be made regardless of how long it will take to execute. At this point, since the file descriptor will be blocked while fsyncing, the current write operation will block. So the conclusion is that in most cases, Redis will fsync every second, and in the worst case, it will fsync once every two seconds. This operation is known as a group commit on most database systems, and is a combination of data from multiple write operations to write the logs to disk at once.
- appednfsync always When appendfsync is set to always, fsync is invoked once for every write operation, when the data is safest, but of course, its performance suffers because fsync is performed every time.
For general business needs, it is recommended to use RDB for persistence, the reason is that the overhead of RDB and compared to AOF logging is much lower, for those applications that can not tolerate data loss, it is recommended to use AOF logging.
Differences in Cluster Management
Memcached is an all-memory data caching system. While Redis supports persistence of data, all-memory is, after all, the essence of its high performance. As a memory-based storage system, the size of a machine’s physical memory is the maximum amount of data that the system can hold. If the amount of data to be processed exceeds the physical memory size of a single machine, you need to build a distributed cluster to extend the storage capacity.
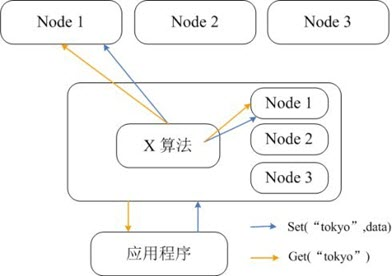
Memcached itself does not support distribution, so it can only implement distributed storage for Memcached on the client side through a distributed algorithm like consistent hashing. The following diagram gives the architecture of Memcached’s distributed storage implementation. When a client sends data to the Memcached cluster, it first calculates the target node for that data by the built-in distributed algorithm, and then the data is sent directly to that node for storage. However, when a client queries data, it also calculates the node where the query data is located, and then sends a query request directly to that node to get the data.
Redis prefers to build distributed storage on the server side as opposed to Memcached, which can only implement distributed storage on the client side. The latest version of Redis already supports distributed storage, and Redis Cluster is an advanced version of Redis that is distributed and allows for a single point of failure, with no central node and linear scalability. The following diagram shows the distributed storage architecture of Redis Cluster, where nodes communicate with each other via the binary protocol and nodes communicate with clients via the ascii protocol. In terms of data placement strategy, Redis Cluster divides the entire key value field into 4096 hash slots, and each node can store one or more hash slots, which means that the maximum number of nodes currently supported by Redis Cluster is 4096. The distributed algorithm used by Redis Cluster is also simple: crc16( key ) % HASH_SLOTS_NUMBER.
To ensure data availability under a single point of failure, Redis Cluster introduces Master nodes and Slave nodes. In Redis Cluster, each Master node has two corresponding Slave nodes for redundancy. This way, the downtime of any two nodes in the cluster will not result in data unavailability. When the Master node drops out, the cluster automatically selects a Slave node to become the new Master node.

Reference link.