Non-Uniform Memory Access (NUMA) is a computer memory design approach, as opposed to Uniform Memory Access (UMA), also known as Symmetric Multi-Processor Architecture (SMP), which was used by early computers, but most modern computers use NUMA architecture to manage CPU and memory resources.
As application developers, we are less likely to need direct access to hardware because the operating system shields us from many hardware-level implementation details. However, because NUMA affects applications, NUMA is something we must understand and be familiar with if we want to write high-performance, low-latency services, and this article will cover its impact in two ways.
- NUMA introduces both local memory and remote memory, and the CPU will have less latency accessing local memory than accessing remote memory.
- The combination of NUMA’s memory allocation and memory reclamation strategies may lead to frequent swap partitions (Swap) in Linux and thus affect the stability of the system.
Local Memory
If the host computer uses the NUMA architecture, then CPU access to local memory will have less latency than access to remote memory, a phenomenon not intentionally created by the CPU designers, but rather a physical limitation. However, the NUMA design did not come with the computer, so let’s analyze the evolution of the CPU architecture before we move on to the impact of NUMA on the program.
In the first decades of computing, processors were basically single-core. According to Moore’s Law, as technology progressed, the performance of processors doubled every two years, and this law was basically in effect for the last century, but in the last decade or so, the increase in the number of transistors in a single processor slowed down, and many manufacturers began to introduce dual-core and multi-core computers.
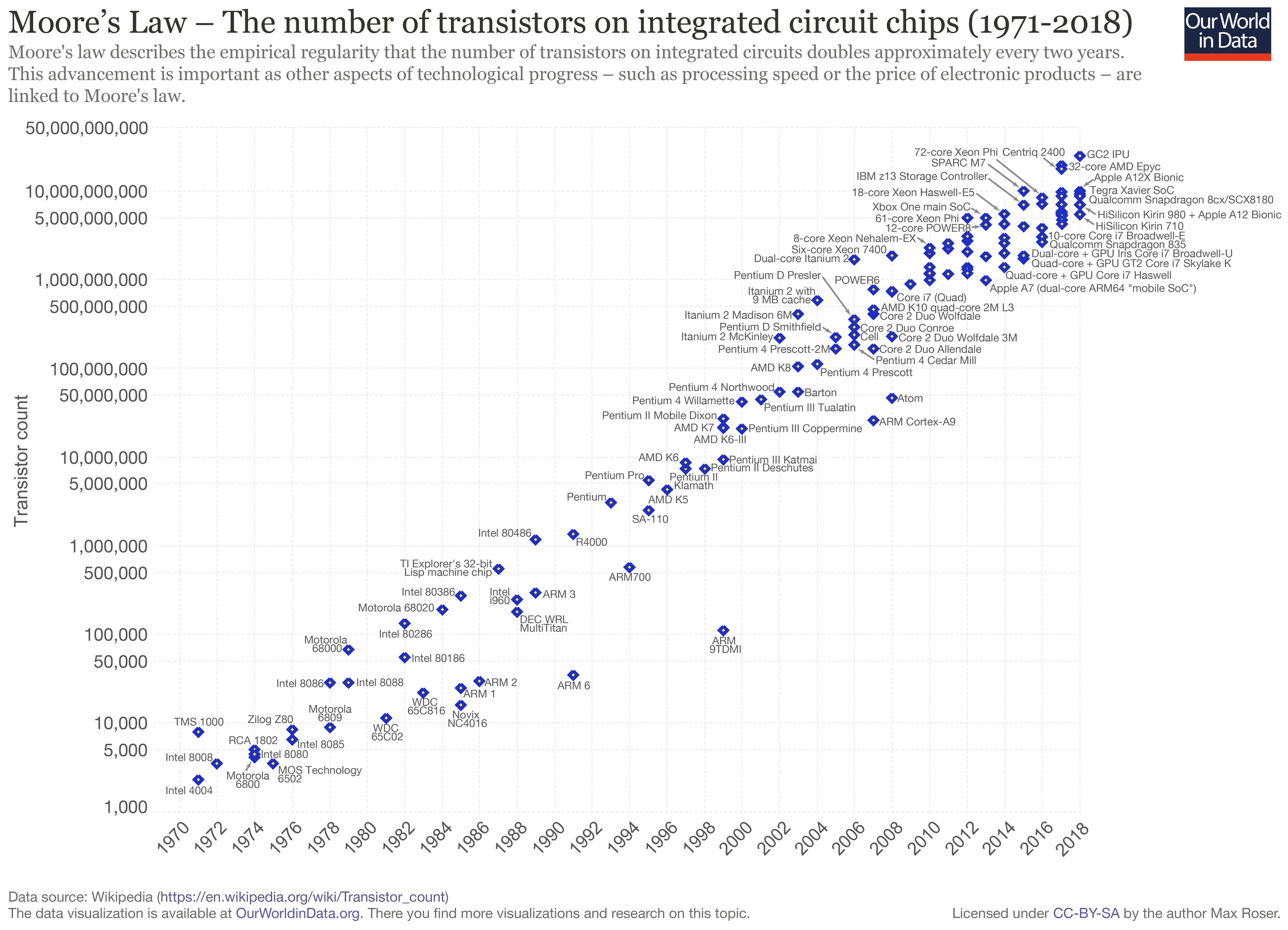
The CPUs on a single-core or multi-core computer would first access the memory in the memory slots through the Front-side bus, Northbridge, and Memory bus, and all CPUs would access the same memory and I/O devices through the same bus, and all resources in the computer would be shared. This architecture is called Symmetric Multi-Processor (SMP) and is also known as Uniform Memory Access (UMA).
However, as the number of CPUs in a computer increases, multiple CPUs need to access memory through the bus and the North Bridge. When the same host contains dozens of CPUs, the bus and North Bridge modules become the bottleneck of the system. To solve this problem, the designers of the CPU architecture solved the problem using multiple CPU modules as shown below.

As shown in the figure above, the host contains 2 NUMA nodes, each containing the physical CPU and memory. From the figure we can see that CPU 1 accesses local memory and remote memory through different channels, which is the fundamental reason for the different access time to memory.
The operating system, as the software that manages computer hardware and software resources and provides common services to applications, deals with the underlying hardware itself, and the Linux operating system provides us with hardware-related NUMA information. You can view the NUMA nodes on your machine directly by using the numactl command.
|
|
From the above output, we can see that the machine contains two NUMA nodes, each containing 24 CPUs and 64 GB of memory, and the last node distances tell us the memory access overhead of the two NUMA nodes, where the latency of NUMA node 0 and NUMA node 1 to access each other’s memory is 2.1 times the latency of each node to access The latency of NUMA node 0 and NUMA node 1 accessing each other’s memory is 2.1 times the latency of each node accessing local memory (21 / 10 = 2.1), so if a process on NUMA node 0 allocates memory on node 1, it will increase the latency of the process.
Because NUMA nodes have different overheads for accessing different memory, the operating system provides interfaces for applications to control the CPU and memory allocation policies, and in Linux we can use the numactl command to control the CPU and memory used by processes.
numactl provides two policies for allocating CPU to processes, cpunodebind and physcpubind, which each provide different granularity of binding methods.
cpunodebind- binds processes to a certain number of NUMA nodes.physcpubind- binds the process to a certain number of physical CPUs.
In addition to these two CPU allocation policies, numactl also provides four different memory allocation policies, namely: localalloc, preferred, membind and interleave.
localalloc- always allocate memory on the current node.preferred- tends to allocate memory on a specific node, and when the specified node runs out of memory, the OS allocates it on other nodes.membind- can only allocate memory on a few nodes passed in, and when the specified node is out of memory, the allocation of memory fails.interleave- memory will be allocated sequentially on the incoming nodes (Round Robin), and when the specified node runs out of memory, the OS will allocate it on other nodes.
The above two CPU allocation policies and four memory allocation policies are what we often need to touch when dealing with NUMA. When the performance of a process is affected by NUMA, we may need to adjust the CPU or memory allocation policy with the numactl command.
Swap Partitioning
While the NUMA architecture can solve performance bottlenecks on the bus and allow us to run more CPUs on the same host, not understanding how NUMA works or using the wrong strategy can cause some problems, as shown in Jeremy Cole’s article The MySQL “swap insanity " problem and the effects of the NUMA architecture analyzes the problem that can occur with MySQL in the NUMA architecture - frequent swap partitions affecting service latency - and we briefly describe the reasons behind the problem here.
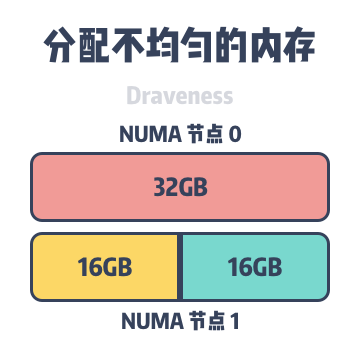
Because databases such as MySQL take up a lot of memory to run, by default processes allocate memory on the NUMA node where they are located first, and then remotely when local memory runs low. As shown above, the host contains two NUMA nodes, each of which has 32GB of memory, but when MySQL InnoDB’s cache pool takes up 48GB of memory, it allocates 32GB and 16GB of memory on NUMA node 0 and NUMA node 1, respectively.
Although 48GB of memory is far from the 64GB memory limit of the host, when some data must be allocated on NUMA node 0 memory, it causes the memory in NUMA node 0 to be swapped to the file system to make way for new memory requests. The frequent swapping of memory in and out of the InnoDB cache pool can cause MySQL queries to be randomly delayed, and once the swapping of partitions occurs, it can be the beginning of a performance spiral.
The zone_reclaim_mode in Linux allows engineers to set the memory reclaim policy when the NUMA node is running low on memory. By default this mode is turned off, and if we enable an aggressive memory reclaim policy in a NUMA system with this configuration, it may affect the performance of the program, and MySQL will also be affected by the memory reclaim policy, but just turning it off will not solve the problem it encounters with frequent swap partitioning triggers.
To solve this problem, we need to change the memory allocation policy to interleave using numactl mentioned in the previous section. Using this memory allocation policy will make MySQL’s memory evenly distributed to different NUMA nodes, reducing the possibility of frequent page swapping in and out.
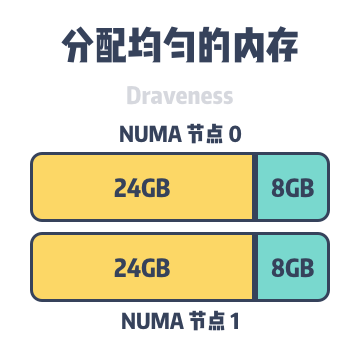
This problem is not unique to MySQL, but is encountered by many memory-intensive databases. Although using interleave temporarily solves these problems, MySQL processes still experience performance losses when accessing remote memory compared to local memory, and the best way to avoid the extra overhead of running services on NUMA once and for all is to Develop applications that are aware of the underlying NUMA architecture. Using MySQL as an example, Jeremy Cole proposes the following modifications in his article that would make better use of NUMA’s local memory.
- intelligently allocate data in the cache pool to different nodes by block or index.
- preserving the default allocation policy for normal query threads, where memory is still allocated locally on the node first.
- rescheduling simple query threads to nodes that have access to local memory.
In addition to MySQL which can use NUMA to improve performance, some frameworks or programming languages can also improve the responsiveness of services by sensing the underlying NUMA information. For example, there is a design document on NUMA-sensing scheduling in the Go language community, and although it is not currently in development because the implementation of this feature is too complex, it is still the future direction of schedulers.
Summary
Many software engineers may think that the operating system and the underlying hardware are so distant from us that we don’t need to consider so many details when developing software, and for the vast majority of applications this holds true. The operating system can shield us from many of the underlying implementation details, allowing us to devote more effort to the implementation of the business logic.
However, as we mentioned in the article, even if the OS makes more isolation and abstraction, the limitations that exist in the physical world will still affect our applications in the dark, and we must pay attention to the next two or even more layers of implementation details if we want to develop high-performance software.
- NUMA introduces both local and remote memory, and the CPU will have less latency to access local memory than to access remote memory.
- NUMA’s memory allocation in combination with memory reclamation strategies may lead to frequent swap partitions (Swap) in Linux and thus affect system stability.
We would certainly prefer all CPUs on a host to have fast access to all memory, but hardware limitations prevent us from achieving such an ideal situation, and NUMA may be an inevitable direction for CPU architecture development, reducing the pressure on the bus by grouping CPU and memory resources and allowing a single host to accommodate many CPUs. In the end, let’s look at some more open-ended questions, and interested readers can think carefully about the following.
- How many CPUs can the NUMA architecture support and what are the bottlenecks of the architecture?
- How does MPP (Massive Parallel Processing) scale the system? What problems does it solve?