This paper is to present the paper in the 2019 SOSP Journal – KVell: the Design and Implementation of a Fast Persistent Key-Value Store, which implements KVell, a key-value store system developed for modern SSDs. Unlike mainstream key-value stores that use LSM trees (Log-structured merge-tree) or B-trees, KVell uses a completely new device in order to take full advantage of its performance and KVell uses a completely different design in order to take full advantage of the new device’s performance and reduce CPU overhead.
As software engineers, the probability of us dealing directly with hardware is actually very small, and most of the time we will be operating different hardware indirectly through the operating system and POSIX. While it may seem that storage hardware such as disks have evolved and been updated very slowly over the last 10 years, in reality.
- Disks are far faster than they were 10 years ago.
- the gap between random and sequential I/O performance of disks has become smaller.
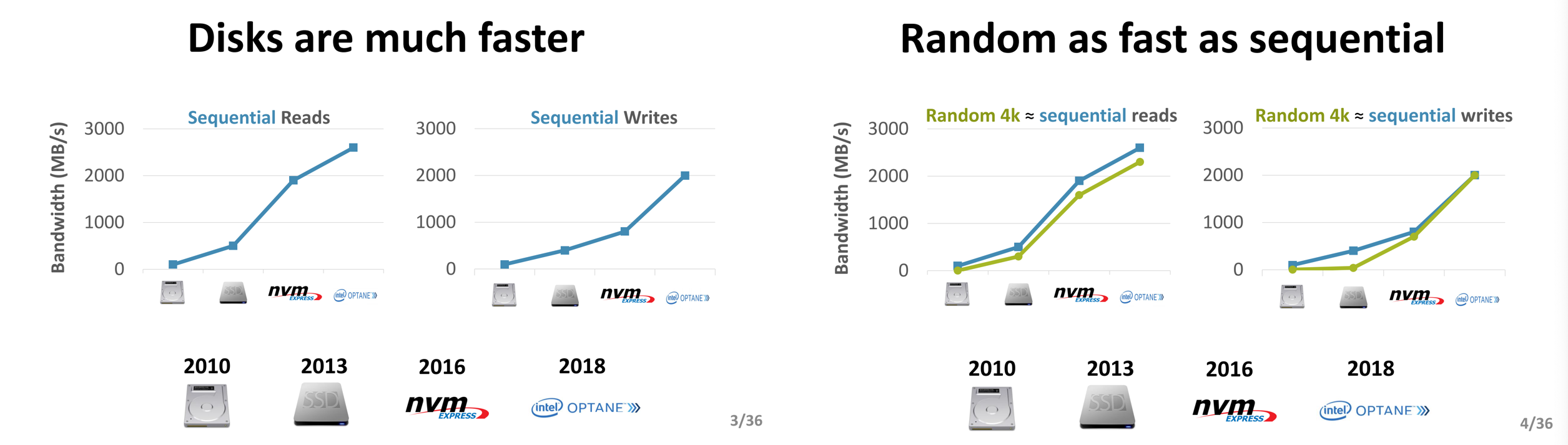
The evolution of disk performance and features has made many designs of key-value stores ineffective in the past, e.g., random I/O is much slower than sequential I/O, and many databases use specific data structures and sacrifice some CPU computational resources to reduce the number of random I/Os, but this is no longer necessary on the latest hardware.
KVell’s paper not only mentions the problems with the current mainstream key-value stores on new storage devices, but also gives the latest design principles, implementations, and performance evaluations. We will not cover everything in the paper here, but will mainly analyze the problems of mainstream key-value stores and the latest design principles, and you can explore the rest in the paper itself.
Implementation Issues
Most of the current key-value storage systems use either LSM trees or B-trees as the primary data structure to store data.
- LSM trees: suitable for write-intensive loads.
- B-trees: suitable for read-intensive loads.
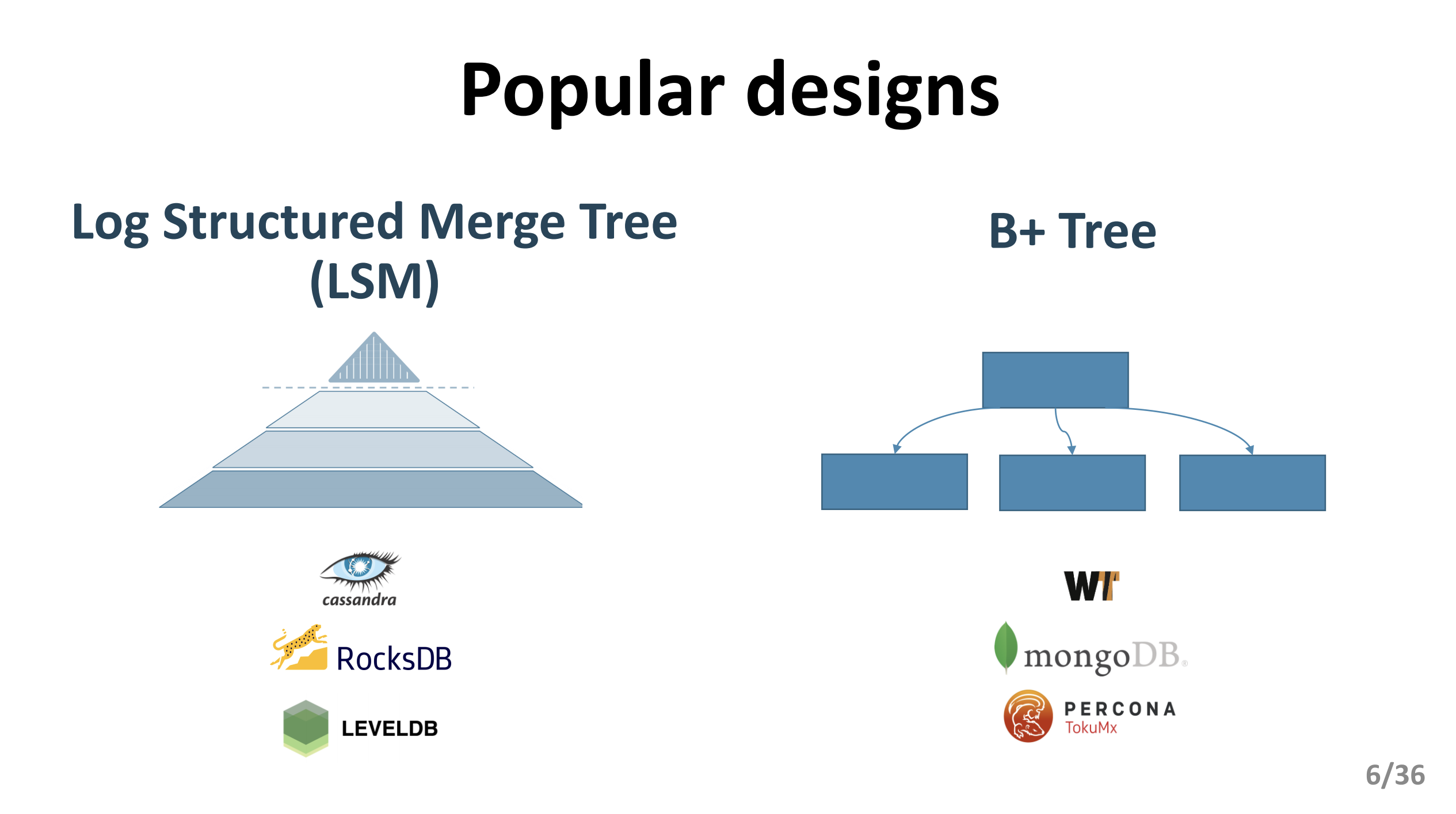
Databases such as RocksDB and Cassandra use LSM trees, while MongoDB and others use B-trees and its variants. While both designs have performed well in the past, both designs do not perform well on newer hardware like NVMe SSDs, where the CPU becomes a bottleneck and causes severe performance fluctuations.
LSM Trees
The LSM tree is a data structure specifically optimized for write intensive loads. In the LSM tree, we use the memory cache to receive all write operations and batch the changes to disk, and the data in the memory cache is merged into a tree structure in persistent storage by a background thread.

The data structure in a disk contains multiple tiers, each of which will contain multiple immutable, sorted files and no overlap in the key ranges of files in the same tier. To ensure these characteristics, LSM introduces a CPU- and I/O-intensive operation - compression, which, as shown above, merges multiple lower-level files into higher-level files, keeping key-value pairs in order and removing duplicate keys. This also makes the CPU already a major bottleneck in the LSM tree on newer storage devices, and this design allows us to spend CPU time on older devices to keep data in order and reduce latency when scanning for sequential access to disk.
In addition to the CPU being a bottleneck, the load on key-value stores using LSM trees is significantly impacted by data compression, and the data in the paper indicates that RocksDB performance can degrade by an order of magnitude during compression, and while there are techniques to mitigate the impact of data compression, these methods are not applicable on high-end SSDs.
B-trees
B+ trees store key-value pair data only at the leaf nodes, the internal nodes contain only the keys used for routing, each leaf node contains a set of sorted key-value pairs, and all leaf nodes will form a chain table for easy scanning. The most advanced B+ trees rely on caching for superior performance, and most write operations are also written to the commit log before being written to the cache, and the information in the B+ tree is updated only when the data in the cache is evicted.
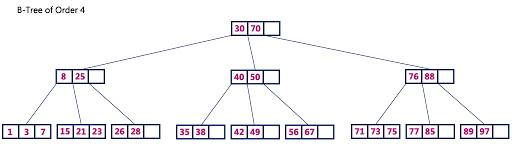
There are two operations in the B+ tree that persist the data in it, Checkpoint and Eviction; the former is triggered at a fixed frequency when the size of the log reaches a specific threshold, which ensures that the size of the commit log is within a fixed range, while Eviction writes dirty data from the cache to the tree, which also triggers a write when the cache reaches a specific threshold.
This design is more susceptible to the extra overhead of Synchronization, and the paper found in its tests that only 18% of the time is spent processing client requests, while the rest of the time is spent waiting for different waits, and 75% of the time in the kernel is spent waiting for function calls like futex and yield.
The performance of the B-tree also suffers when the eviction of data from memory does not complete quickly, and the data in the paper indicates that WiredTiger’s throughput drops from 120 Kops/s to 8.5 Kops/s during the delay, with this huge impact lasting a few seconds before recovering.
Design Principles
In order to take advantage of the features of the new storage device and reduce the CPU overhead of the key-value store, our development of KVell on modern SSDs will follow the design principles shown below to improve the performance of the key-value store.
- No data sharing: all data structures are stored in slices on different CPUs, and all CPUs do not need to synchronize data while performing calculations.
- Unsorted data on disk and indexed sorting in memory: storing unsorted data on disk avoids expensive reordering operations.
- Less system calls, not sequential I/O: since random I/O and sequential I/O on modern SSDs have similar performance, reducing batch I/O reduces additional CPU overhead.
- No need to commit logs: avoid unnecessary I/O operations by not caching data updates in memory.
No data sharing
In a multi-threaded software system, anyone with a little common sense knows that synchronizing data between different threads can have a relatively large impact on performance. Having multiple threads not share data with each other can avoid the above synchronization overhead and reduce the performance loss caused by waiting for threads.
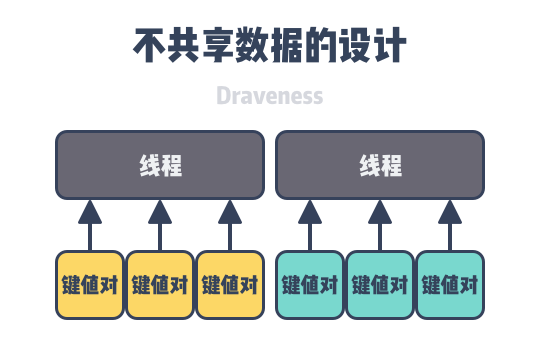
To accomplish this, each thread of KVell handles operations on a specific set of keys and maintains private data structures associated with those keys: 1.
- a lightweight, in-memory B-tree index - which stores the location of the key in the persistent store.
- I/O queues - responsible for quickly reading or writing data from or to the persistent store.
- free lists - in-memory hard disk blocks used to store key-value pairs.
- page cache - uses an internal page cache that is not dependent on the operating system.
Most of the operations of the key-value store are only add, delete, and check of individual keys, and none of these operations require data synchronization between multiple threads; only scans that traverse keys require synchronization between different threads of the in-memory B-tree index.
Disk Unsorting
Because KVell does not sort data in order on disk, the initial position of a key-value pair on disk is its final position. This unordered approach not only reduces the additional overhead of inserting items, but also eliminates the CPU overhead from disk maintenance operations.
Unordered key-value pairs, while reducing the overhead of write operations, can also affect performance when scanning, although according to the tests in the paper, scanning operations are not significantly affected when encountering medium-sized loads and large key-value pairs, so this result is acceptable in most cases.
Reducing system calls
In KVell, all operations perform random reads and writes to disk, so it does not waste CPU time converting random I/O to sequential I/O. Similar to LSM key-value pairs, KVell forwards I/O requests to disk in bulk, and its main purpose is to reduce the number of system calls, i.e., the additional CPU overhead. An effective key-value store should issue enough requests to disk to ensure that disk has enough work, but should not issue too much work to affect disk performance and introduce high latency.
Remove commit logs
KVell does not rely on the commit log to determine whether data is persisted by the system; it only acknowledges updates as they are written to their final location on disk, and once an update is committed by a worker thread, it is processed in the next batch of I/O requests. The role of commit logging is actually to turn random I/O into sequential I/O to address the consistency impact of crashes, but since today’s random I/O and sequential I/O already have similar performance, commit logging has lost its past role in key-value stores, and removing commit logging can reduce disk bandwidth usage.
Summary
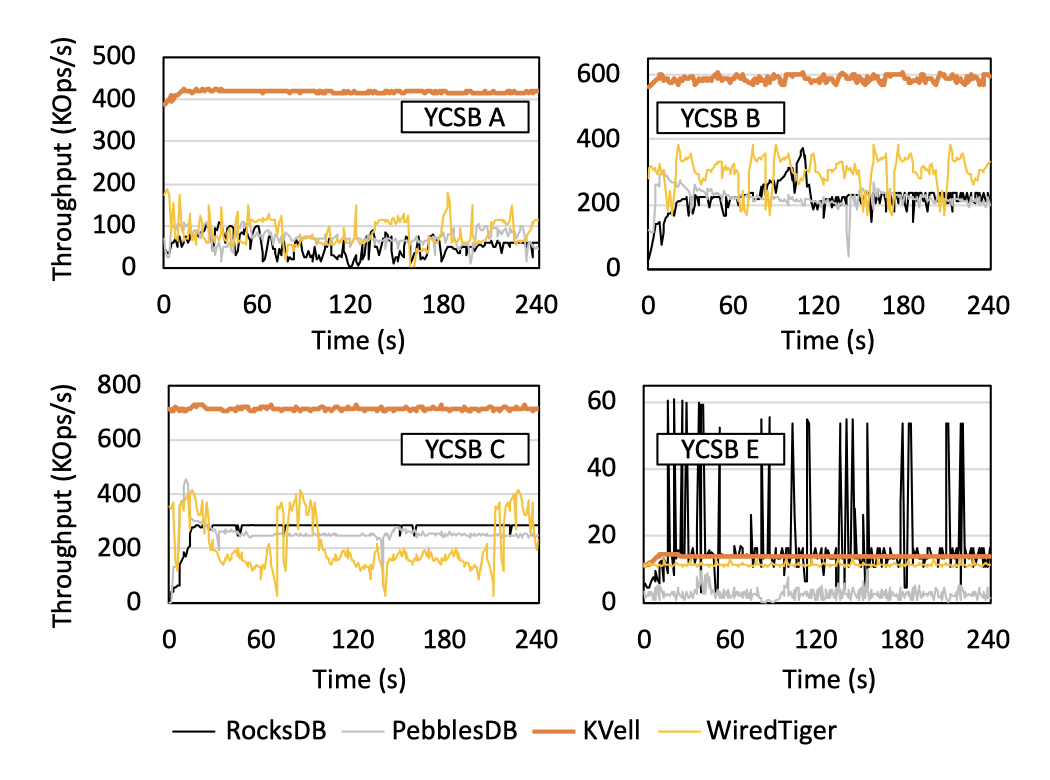
KVell, as a key-value store based on the latest hardware, has excellent performance in specific scenarios. The paper gives a comparison of its throughput with mainstream key-value stores under different loads, where YCSB A, YCSB B, YCSB C and YCSDN E are write intensive, read intensive, read-only and scan intensive tasks, respectively.
From this, we can see that KVell performs much better than mainstream key-value stores such as RocksDB for all loads except scan-intensive tasks.
As software engineers, although the operating system provides us with a standard interface to operate the hardware, so that we are not used to direct contact with the hardware, you can put more effort into the software, but we still have to keep in mind that the hardware on the software system and the many influences and restrictions and development perspective on the progress of hardware, but also only the combination of software and hardware to bring the ultimate performance.