Recently, I’ve been learning about TCP/IP, and I’ve found that most of the HTTP-related content is very old. Many of the materials are not updated with the HTTP version. So I took the time to do some simple organization.
HTTP’s Past Life Saga
Before the HTTP protocol was defined, Berners-Lee had already proposed the hypertext idea and eventually implemented the earliest hypertext systems.
1980 - The Birth of the Hypertext Idea
Between June and December 1980, Berners-Lee worked as an independent contractor at CERN (European Centre for Nuclear Research) in Geneva. During that time, he developed the idea of creating a project based on a hypertext system designed to facilitate the sharing and updating of information among researchers.
He also developed one of the first prototype systems, which he named ENQUIRE. This system allows one to store pieces of information and link related parts in any way. To find information, one links from one sheet of paper to another, just like in the old computer game “Adventure”. He uses it to keep personal records of individuals and modules. It is similar to Apple’s original application Hypercard for the Macintosh, except that the query, despite its lack of fancy graphics, runs on a multi-user system and allows many people to access the same data.
Thus, the first prototype of a hypertext system was born (there was no HTTP protocol at that time). It was also the experience with the ENQUIRE system that planted a solid seed for the birth of the World Wide Web.
1989 - The Birth of the World Wide Web
In 1980, Berners-Lee left CERN and returned after four years of bouncing around. In 1989, to solve the problem of information access at CERN, Berners-Lee used a concept similar to the ENQUIRE system to create the World Wide Web .
There were many problems with CERN information access at that time, also including.
- People move around and information is constantly lost?
- Where is this module used?
- Who wrote this code? Where does he work?
- What is the documentation on this concept?
- What labs are included in this project?
- What systems depend on this device?
- What documents cover this one?
When Berners-Lee realized the problems, he wrote a proposal to try to convince CERN management that a global hypertext system was in line with the current situation at CERN and would still be beneficial. Internet node in Europe. The proposal describes in detail how CERN’s information access problems arose, and describes in detail the evolution of the solution. The final solution was to use a hypertext system.
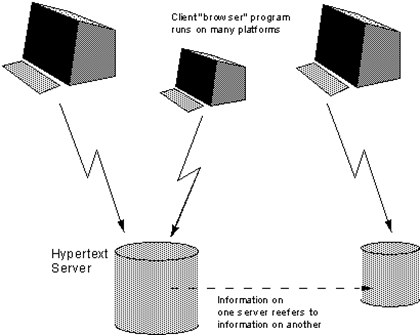
This is also the first time that linked resources are proposed instead of a hierarchical system, rather than keywords to locate resources. The linked resource here is also the system that will later become known as the unique authentication of global web resources, the Uniform Resource Identifier (URI).
Then why did Berners-Lee not use a hierarchical system and keywords to locate resources. In fact, he did consider it, and in the proposal he wrote describes in detail the problems of hierarchical systems and keyword-located resources. The main problems are.
- Problems with the hierarchical system: problems with the tree structure, no restrictions if you use links.
- The problem of keywords: two people never choose the same keywords. These keywords only apply to people who are already familiar with the application.
It was for these reasons that Berners-Lee first built a small linked information system, not realizing that a term had been coined for the idea: “hypertext”.
Eventually, in 1990 Berners-Lee redeveloped the configuration system after it was accepted by his manager, Mike Sendall.
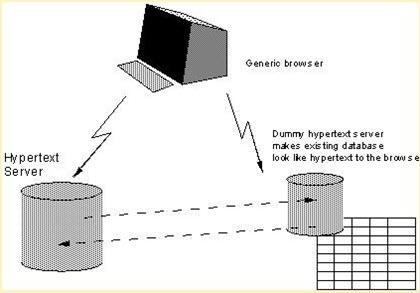
The approximate system of the Berners-Lee redevelopment configuration system is what is shown in the figure. Users view data through a hypertext browser via a hypertext gateway.
It is because of this system that not only laid the foundation for the HTTP/0.9 protocol, but also gave birth to the familiar World Wide Web later.
HTTP protocol was born
In fact, having said all this does not explain the need for the HTTP protocol, why do we need to create a new protocol (HTTP protocol), can’t we use other protocols?
The existing protocols at the time covered many different tasks.
- The mail protocol allows the transmission of ephemeral messages from a single author to a small number of recipients.
- File transfer protocols allow data to be transmitted at the request of the sender or recipient, but do not allow data to be processed on the response side.
- The News protocol allows the broadcast of transient data to a wide audience.
- Search and retrieval protocols allow for indexed searches and document access.
Considering that few protocols exist that can be extended as needed, the only one that is available, Z39.50, is considered a viable bar.
The HTTP protocol must provide.
- a subset of file transfer functionality
- the ability to request indexed searches
- Automatic format negotiation
- the ability to refer clients to another server
The HTTP protocol was born because it was difficult to extend on the original existing protocol.
Introduction to HTTP Protocol
HTTP (HyperText Transfer Protocol) is one of the most widely used network protocols on the Internet today. HTTP, like many protocols in the TCP/IP protocol cluster, is used for communication between clients and servers.
Hypertext" refers to text that goes beyond ordinary text, and is a mixture of text, images, video, etc. It is a mixture of text, images, videos, etc. The key is to have “hyperlinks” that can jump from one hypertext to another.
The HTTP protocol states that when two computers communicate using the HTTP protocol, there must be a client at one end and a server at the other end of a communication line. When you enter a URL in your browser to access a website, your browser (client) encapsulates your request into an HTTP request and sends it to the server, which receives the request and then organizes the response data into an HTTP response back to the browser. In other words, the communication must be established from the client side first, and the server side does not send a response until the request is received.
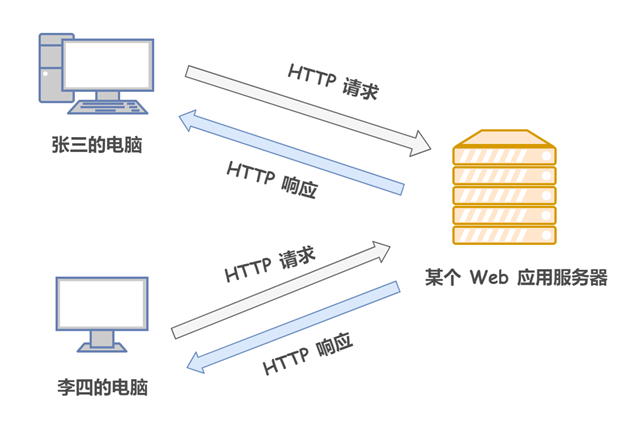
HTTP request message
The HTTP request message consists of 3 main parts.
- Request line (must be on the first line of the HTTP request message)
- The request header (starts on the second line and ends on the first blank line. There is a blank line between the request header and the request body)
- The request body (data is usually passed as a key-value pair {key:value})

The POST at the beginning of the request line indicates the type of request to access the server, called method. The subsequent string /form/login specifies the resource object that is being requested, also called the request URI (request-URI). The final HTTP/1.1, the version number of HTTP, is used to indicate the HTTP protocol function used by the client.
In summary, this request means that it is a request to access the /form/login page resource on an HTTP server with the parameters name = veal, age = 37.
Note that for both HTTP request and HTTP response messages, there is a “blank line” between the request/response header and the request/response body, and the request/response body is not required.
HTTP Request Methods
The role of the methods in the request line is to be able to specify that the requested resource produces a certain behavior according to expectations, i.e. to give commands to the server using the method. These include (HTTP 1.1): GET, POST, PUT, HEAD, DELETE, OPTIONS, CONNECT, TRACE, and of course, the first 2 are the most common and most often used in our development.
HTTP Request Header
Request headers are used to supplement the request with additional information, client information, priority related to the content of the response, etc. The following are common request headers.
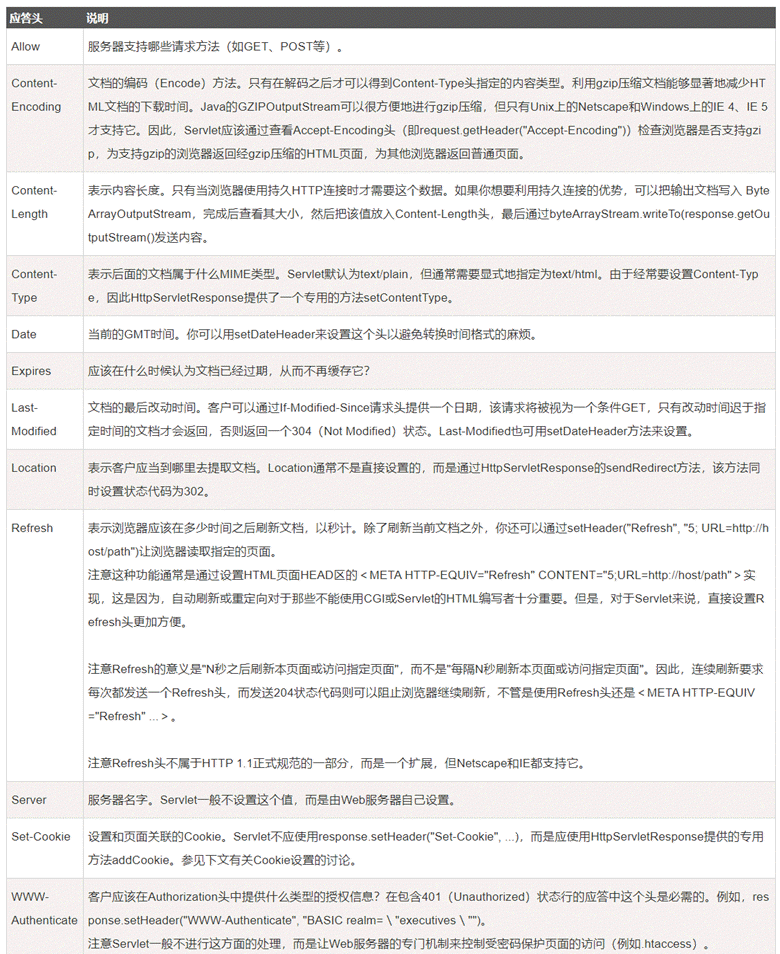
- Referer: indicates from which URI this request is bounced. For example, if you search Taobao.com through Baidu, the value of Referer in the request message to Taobao.com is: baidu.com. If you access it directly, you will not have this header. This field is usually used for anti-theft links.
- Accept: Tells the server the type of response data that the request can support. (Correspondingly, the HTTP response message also has such a similar field Content-Type, used to indicate the type of data sent by the server, if the type specified by Accept and the type returned by the server do not match, it will report an error)
- Host: informs the server of the Internet host name and port number where the requested resource resides. This field is the only field in the HTTP/1.1 specification that must be included in the request header.
- Cookie: The client’s cookie is passed to the server through this header attribute!
- Connection: indicates the type of client-server connection; Keep-Alive means persistent connection, close is closed.
- Content-Length: the length of the request body
- Accept-Language: The browser notifies the server of the language supported by the browser.
- Range: For range requests that only require partial access to the resource, include the first field Range to inform the server of the specified range of the resource
HTTP response message
The HTTP response message also consists of three parts.
- Response line (must be on the first line of the HTTP response message)
- The response header (starts on the second line and ends on the first blank line. There is a blank line between the response header and the response body)
- Response body

The HTTP 1.1 at the beginning of the response line indicates the corresponding HTTP version of the server. The 200 OK that follows indicates the “status code” and “reason phrase” of the result of the request.
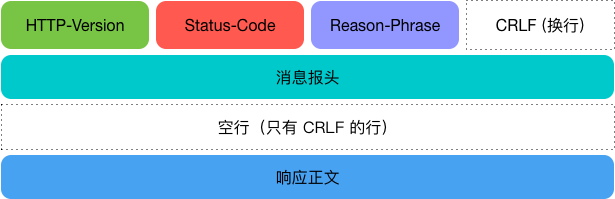
HTTP Status Codes
HTTP status codes are responsible for indicating the return result of a client HTTP request, marking whether the server side is processing properly, notifying of errors, etc. The status code consists of 3 digits, the first of which defines the category of the response.
HTTP Response Header
The response header, also in key-value pairs k:v, is used to supplement the response with additional information, server information, and additional requirements for the client, etc.
HTTP connection management
Short connections (non-persistent connections)
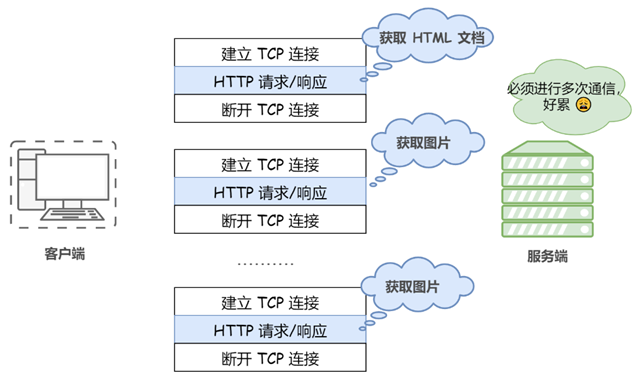
In the initial version of the HTTP protocol (HTTP/1.0), a connection is established for each HTTP session between the client and the server, and the connection is broken at the end of the task. When a client browser accesses an HTML or other type of Web page that contains other Web resources (such as JavaScript files, image files, CSS files, etc.), the browser re-establishes an HTTP session for each such Web resource encountered. This is called a short connection (also called a non-persistent connection).
This means that the connection is re-established once for each HTTP request. Since HTTP is based on the TCP/IP protocol, each establishment or disconnection of a connection requires the overhead of three TCP handshakes or four TCP waves.
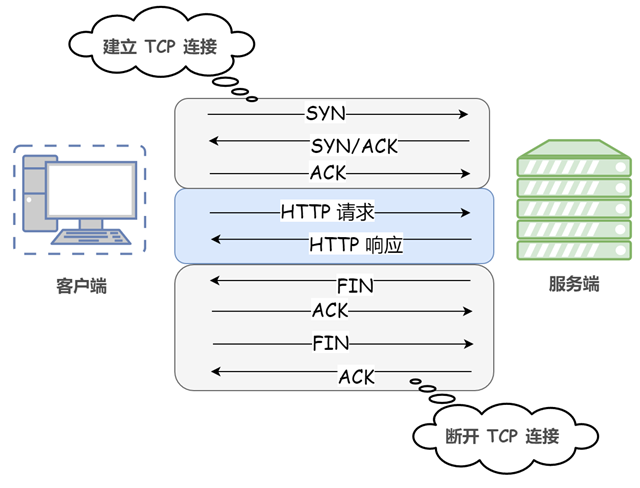
Obviously, there are huge drawbacks to this approach. For example, accessing an HTML page containing multiple images causes needless TCP connections to be established and disconnected with each request for an image resource, greatly increasing the overhead of communication volume.
Long connections (persistent connections)
Since HTTP/1.1, long connections, also called persistent connections, are used by default. HTTP protocols that use long connections include this line of code in the response header: Connection:keep-alive
In the case of long connections, when a web page is opened, the TCP connection used to transfer HTTP data between the client and the server is not closed, and the client will continue to use the established connection when it accesses the server again. This time can be set in different server software (e.g. Apache). Implementing a long connection requires that both the client and server support long connections.
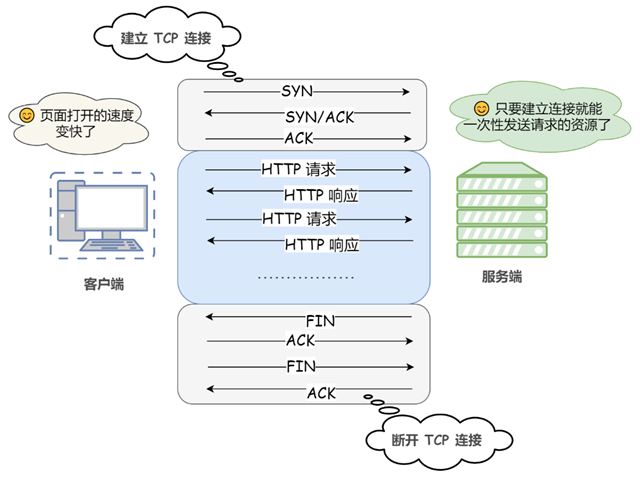
Long and short connections for the HTTP protocol are essentially long and short connections for the TCP protocol.
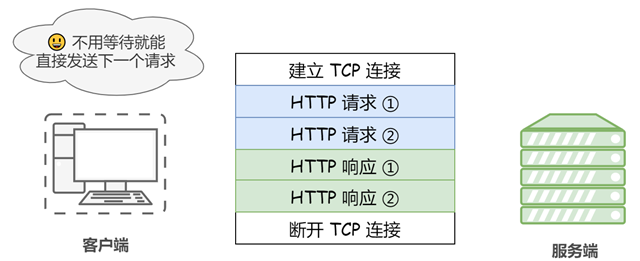
Pipelining
By default, HTTP requests are sent sequentially, and the next request is sent only after the response is received for the current request. Due to network latency and bandwidth limitations, it can take a long time before the next request is sent to the server.
Persistent connections make it possible to send most requests in a “pipelined” fashion, i.e., to send requests continuously on the same persistent connection without waiting for a response to be returned, so that multiple requests can be sent in parallel without having to wait for a response one after another.
Stateless HTTP
The HTTP protocol is a stateless protocol. This means that he does not manage the state of requests and responses that have occurred previously, i.e. he cannot process the current request based on the previous state. This poses an obvious problem. If HTTP cannot remember the user’s login state, wouldn’t every page jump result in the user having to log in again?
Of course, there is no denying that statelessness has significant advantages, as it reduces the server’s CPU and memory consumption by not having to save state. On the other hand, the simplicity of HTTP is the reason why it is so widely used.
While retaining this feature of stateless protocols, it is important to solve the problems caused by statelessness. There are various solutions, and one of the simpler ways is to use cookie technology.
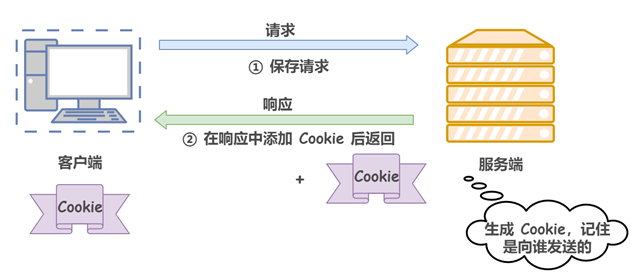
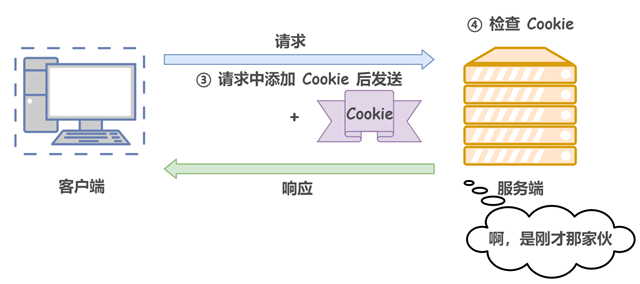
Cookies control the state of the client by writing cookie information in the request and response messages. Specifically, the cookie notifies the client to save the cookie based on the information in the initial field called Set-Cookie in the response message sent from the server, and when the client sends the next request to the server, the client automatically adds the cookie value to the request message and sends it out. After receiving the cookie from the client, the server will check which client sent the connection request, and then compare the records on the server to get the previous status information.
Figuratively speaking, after the client’s first request, the server will send an ID card with the client’s information, and when the client subsequently requests the server, it will bring the ID card with it so that the server will recognize it.
The following diagram illustrates a scenario in which a cookie interaction occurs.
Requests in the state without cookie information.
Requests after the 2nd time (with cookie information status)
HTTP and HTTPS
The HTTPS protocol can be understood as an upgrade of the HTTP protocol, which is the addition of data encryption on top of HTTP. Before the data is transmitted, it is encrypted and then sent to the server. In this way, even if the data is intercepted by a third party, your personal information is still safe because the data is encrypted. This is the major difference between HTTP and HTTPS.
Internet communication security is based on SSL/TLS protocols, SSL “Secure Sockets Layer” protocol and TLS “Secure Transport Layer” protocol, both of which are encryption protocols that protect privacy and data integrity in the transmission of data over the network. This ensures that information transmitted over the network is not intercepted or modified by unauthorized elements, thus ensuring that only legitimate senders and receivers have full access to the information being transmitted.
- SSL : (Secure Socket Layer), a protocol layer that sits between the reliable connection-oriented network layer protocol and the application layer protocol. SSL enables secure communication between clients and servers by authenticating each other, using digital signatures to ensure integrity, and using encryption to ensure privacy. The protocol consists of two layers: the SSL Record Protocol and the SSL Handshake Protocol.
- TLS : (Transport Layer Security), used between two applications to provide confidentiality and data integrity. The protocol consists of two layers: the TLS logging protocol and the TLS handshake protocol.
HTTP communication without SSL/TLS is communication without encryption. All information is disseminated in clear text, which poses three major risks.
- Eavesdropping risk (eavesdropping): Third parties can be informed of the content of the communication.
- tampering: Third parties can modify the content of the communication.
- The risk of impersonation (pretending): Third parties can participate in the communication by impersonating someone else’s identity.
The SSL/TLS protocol is designed to address these three major risks, hoping to achieve.
- All messages are transmitted encrypted and cannot be eavesdropped by third parties.
- Equipped with a checksum mechanism so that if tampered with, both sides of the communication will immediately discover it.
- Equipped with an ID book to prevent identity impersonation.
The Internet is an open environment and both communicating parties are unknown identities, which makes the design of the protocol very difficult. Moreover, the protocol must also be able to withstand all outlandish attacks, which makes the SSL/TLS protocol extremely complex.
HTTP protocol evolution
Up to now, the IETF has released five HTTP protocols, including HTTP 0.9, HTTP 1.0, HTTP 1.1, HTTP 2, HTTP 3. Here are the differences between the versions.
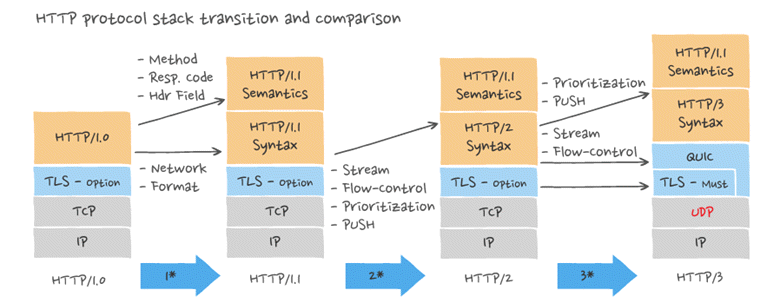
HTTP/0.9
The original version of the HTTP protocol did not have a version number, which was later positioned at 0.9 to distinguish it from later versions. The deprecated HTTP/0.9 was the first version of the HTTP protocol, born in 1989. It was extremely simple in composition, allowing clients to send only one request, GET, and did not support request headers. Since there was no protocol header, HTTP/0.9 could only support one type of content - plain text. The server can only respond with a string in HTML format, not any other format. Once the server has finished sending, it closes the TCP connection. HTTP/0.9 is typically stateless, with each access handled independently and disconnected when processing is complete. No error codes are returned if the requested page does not exist.
HTTP/1.0
In November 1996, a new document (RFC 1945) was published. Document RFC 1945 defines HTTP/1.0, but it is narrowly defined and is not an official standard. HTTP 1.0 is the second version of the HTTP protocol and is still widely used today. It expands and improves upon HTTP/0.9 in a number of ways, including
- the ability to transfer documents other than plain text HTML files, such as images, videos, and binary files, not just text
- In addition to GET commands, POST and HEAD commands have been introduced, enriching the means of interaction between the browser and the server.
- The format of HTTP requests and responses has also changed. In addition to the data portion, each communication must include a header (HTTP header), which describes some metadata.
- Other new features include status code, multi-character set support, multi-part type, authorization, cache, content encoding, and more.
Request Header
Header information for a simple request
You can see that after the request method there is the location of the requested resource + the request protocol version, followed by some client information configuration
Response header
Header information for a simple response (v1.0)
The first response header of the server is the request protocol version, followed by the status code of the request, and the description of the status code, followed by a description of the returned content.
Content-Type field
In HTTP 1.0, any resource can be transmitted in a variety of formats, and the content of the response body is parsed by the client according to the Content-Type. Regarding the encoding of characters, version 1.0 specifies that the header information must be ASCII, and the data that follows can be in any format. Therefore, when the server responds, it must tell the client what format the data is in, so the server must return with this field.
Values of common Content-Type fields.
- text/html
- text/css
- image/png
- image/gif
- application/javascript
- application/octet-stream
These Content-Types have a general name called MIME type.
These data types are collectively called MIME type, and MIME type can also have parameters added at the end using a semicolon.
|
|
The client can also use Accept to declare the format of the data it receives when requesting
|
|
Content-Encoding field
Since the data to be transmitted may be large, it can be compressed at one time for transmission. The Content-Encoding field is a description of how the data is compressed.
When requesting, the client uses the Accept-Encoding field to indicate which compression methods it can accept.
|
|
status code
The status code consists of three digits, the first of which defines the category of the response and has five possible values.
- 1xx: indication message - indicates that the request has been received and processing continues
- 2xx: Success - indicates that the request has been successfully received, understood, accepted
- 3xx: Redirect - further actions must be taken to complete the request
- 4xx: Client-side error - the request has a syntax error or the request could not be fulfilled
- 5xx: Server-side error - the server failed to implement a legitimate request
Features of HTTP/1.0
- Stateless: the server does not track or record the requested state (you can use the cookie/session mechanism to do authentication and state recording)
- connectionless: the browser needs to establish a tcp connection for each request
Disadvantages of HTTP/1.0
The most obvious disadvantage of version 1.0 of HTTP, which is the same as 0.9, is short connections, which can cause two problems that affect two aspects of HTTP communication: speed and bandwidth, respectively. Connections cannot be reused, resulting in processes such as three TCP handshakes for each request, resulting in slower speeds; the resulting lack of bandwidth can cause later responses to be blocked. This problem becomes more pronounced as more and more external resources (images, CSS, JavaScript files, etc.) are loaded on a web page.
To solve this problem, some browsers use a non-standard Connection field in their requests.
|
|
This field asks the server not to close the TCP connection so that other requests can be reused. The server responds to this field as well.
|
|
A reusable TCP connection is then established until the client or server actively closes the connection. However, this is not a standard field, and the behavior may not be consistent across implementations, so it is not a fundamental solution.
In addition, TCP as maintained by HTTP 1.0 can only handle one request at a time, and although it can receive multiple requests at once, it still has to process them one at a time in sequence, which can easily cause blocking while subsequent requests wait for the preceding request to complete. Also, it does not support breakpoint sequencing.
HTTP/1.1
The third version of the HTTP protocol is HTTP 1.1. HTTP 1.1 was introduced six months after the release of 1.0 and completes version 1.0. HTTP 1.1 is the most widely used version of the protocol and is currently the dominant version of the HTTP protocol.
HTTP 1.1 introduces a number of key performance optimizations.
1) Persistent connections/long connections
The biggest change in version 1.1 is the introduction of persistent connection, which means that TCP connections are not closed by default and can be reused by multiple requests without having to declare Connection: keep-alive.
Clients who want to close a connection can do so safely by adding Connection:close to the request header of the last request.
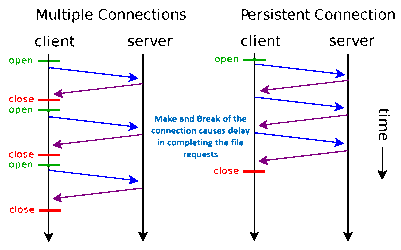
Currently for the same domain name, most browsers allow 6 persistent connections to be established at the same time.
2) Pipelining mechanism
Pipelining mechanism (pipelining): i.e., inside the same TCP link, the client can send multiple requests from colleagues. This further improves the efficiency of the HTTP protocol. For example, a client needs to request two resources. The previous practice was to send request A, then wait for the server to respond, and then send request B after receiving it. The pipeline mechanism allows the browser to send both A and B requests, but the server still responds to the A request in order, and then responds to the B request after it is completed.
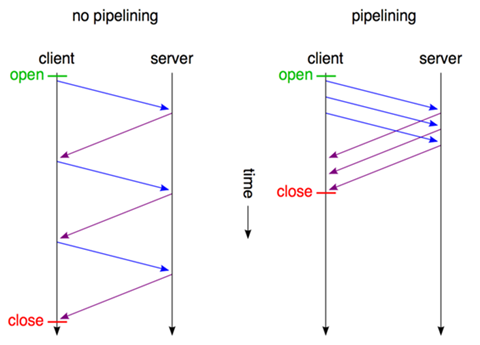
Here is the question, how does the client distinguish between where the first response is and where the next response is?
HTTP 1.1 adds a Content-Length prefix for this purpose, which marks the end of the response and the beginning of the next response.
|
|
The above code tells the browser that the length of this response is 1234 bytes, and that the next bytes belong to the next response.
The pipeline mechanism solves the parallel request limitation problem mentioned above, because it supports sending multiple requests at once, but there is still a problem: the server still responds to requests in order, so if the previous request is slow, there will be many requests queued behind, which is called “Head-of-line blocking”.
3) Chunked transmission
The prerequisite for using the Content-Length field is that the server must know the data length of the response before it sends it. For some very time-consuming dynamic operations, this means that the server has to wait until all operations are completed before it can send the data, which is obviously not very efficient. A better way to handle this is to send a piece of data as it is generated, using “stream mode” instead of “buffer mode”. That is, send a piece of data as it is generated.
This takes the form of a Transfer-Encoding field returned in the response header, indicating that the data is composed of undefined chunks of data.
|
|
For each chunk, a Content-Length is added, and when all chunks have been transferred, an empty chunked is returned with Content-Length set to 0 to indicate that the transfer is complete.
Version 1.1 allows the use of “chunked transfer encoding” without the Content-Length field. Whenever a request or response has a Transfer-Encoding field in its header, it indicates that the response will consist of an undetermined number of chunks of data.
4) New HTTP methods
New HTTP methods are added, including PUT, PATCH, OPTIONS, DELETE.
- GET request gets the resource identified by Request-URI
- POST appends new data to the resource identified by the Request-URI
- HEAD request to get the response message header for the resource identified by the Request-URI
- PUT request for the server to store a resource and use the Request-URI as its identifier
- DELETE request for the server to delete the resource identified by the Request-URI
- TRACE requests the server to send back information about the received request, primarily for testing or diagnostic purposes
- CONNECT reserved for future use
- OPTIONS requests to query the performance of the server, or to query options and requirements related to the resource
5) Added 24 new status response codes
24 new status response codes were added in HTTP 1.1, such as.
- 409 (Conflict) indicates that the requested resource conflicts with the current state of the resource.
- 410 (Gone) indicates that a resource on the server has been permanently deleted
6) Mandatory HOST header
In HTTP 1.0 it was considered that each server was bound to a unique IP address, so the URL in the request message did not pass the hostname (hostname). However, with the development of virtual hosting technology, multiple virtual servers (Multi-homed Web Servers) can exist on a single physical server and they share a single IP address. HTTP 1.1 request and response messages should support the Host header field, and the absence of a Host header field in the request message will report an error (400 Bad Request). With the Host field, it is possible to send requests to different websites on the same server, laying the groundwork for the rise of web hosting.
7) Introduced range header field/breakpoint
HTTP/1.1 also supports the RANGE method, which transmits only a part of the content. This way when the client already has a part of the resource, it only needs to request the other part of the resource from the server. This is the basis for supporting file breakpoint sequencing. This feature is implemented by introducing the RANGE header field in the request message, which allows requesting only a certain part of the resource. The Content-Range header field in the response message declares the offset value and length of the returned part of the object. If the server returns the content of the requested range of the object accordingly, the response code 206 (Partial Content) is returned. When uploading/downloading resources, if the resources are too large, split them into multiple parts and upload/download them separately. If you encounter a network failure, you can continue the request from the place where it has been uploaded/downloaded well, without starting from the beginning, to improve efficiency.
8) Cache handling
HTTP/1.0 uses Pragma:no-cache + Last-Modified/If-Modified-Since + Expire as criteria for cache determination; HTTP/1.1 introduces more cache control policies: Cache-Control, Etag/If-None-Match
The response header in all HTTP 1.1 requests contains a “Date:” header, so each Response adds a timestamp to the cache.
9) Added type, language, encoding and other header
10) Added TLS support, i.e., support for https transmission
11) Support more connection models
Four models are supported: short connection, long link with reusable tcp, server-side push model (server-side actively pushes data into client-side cache), and websocket model.
SYPD
In 2009, Google made public its self-developed SPDY protocol, which mainly addresses the inefficiencies of HTTP/1.1. This protocol was used as the basis for HTTP/2 after it was proven to work on Chrome, and the main features were inherited from HTTP/2.
SPDY’s solution optimizes HTTP1.X request latency and addresses HTTP1.X security, as follows.
- Reduce latency, for the problem of high HTTP latency, SPDY elegantly adopts multiplexing (multiplexing). Multiplexing solves the problem of HOL blocking by sharing a tcp connection with multiple request streams, reducing latency and increasing bandwidth utilization.
- Request prioritization. SPDY allows to set priority to each request, so that important requests will be responded to first. For example, if the browser loads the home page, the html content of the home page should be displayed first, followed by various static resource files, script files, etc. This ensures that the user can see the page content first.
- header compression. As mentioned earlier, the header of x is often duplicated and redundant. Choosing the right compression algorithm can reduce the size and number of packets.
- HTTPS-based encryption protocol transmission, which greatly improves the reliability of the transmitted data.
- Server push (server push), using the SPDY web page, for example, my web page has a request for css, while the client receives sytle.css data, the server will push the sytle.js file to the client, when the client tries to get sytle.js again it can get it directly from the cache, without sending a request.
- SPDY sits below HTTP and above TCP and SSL, so that it can easily be compatible with older versions of the HTTP protocol (encapsulating x’s content into a new frame format) while using the existing SSL functionality.
The difference between SPDY and HTTP/1.1
SPDY is not used to replace HTTP, it simply modifies the way HTTP requests and answers are transmitted over the network; this means that only one SPDY transport layer is added and all existing server-side applications do not have to be modified in any way. When transported using the SPDY approach, HTTP requests are processed, tagged for simplicity and compressed. For example, each SPDY endpoint keeps track of every HTTP message header that has been sent in a previous request, thus avoiding the duplication of sending headers that have not yet been changed. And the data portion of the message that has not yet been sent will be sent after being compressed.

On the left is a normal HTTPS load, and on the right is a SPDY load.
The SPDY protocol only makes significant performance optimizations to HTTP. The core idea is to minimize the number of connections, but not to make significant changes to the semantics of HTTP. Specifically, SPDY uses the methods and headers of HTTP, but removes some headers and rewrites the parts of HTTP that manage connections and data transfer formats, so it’s basically HTTP-compatible.
In the SPDY white paper, Google states that it wants to penetrate below the protocol stack and replace the transport layer protocol (TCP), but since this is quite difficult to deploy and implement for the time being, Google intends to improve the application layer protocol HTTP first by adding a session layer on top of SSL to implement the SPDY protocol, while the GET and POST message formats of HTTP remain unchanged, i.e. all existing server-side applications do not have to make any changes.
Therefore, at this point in time, SPDY is intended to enhance HTTP and is a better implementation and support for HTTP.
The core of SPDY is the framing layer, which manages the connection between two endpoints and the transfer of data. There can be multiple data streams between two endpoints. At the top of the framing layer, SPDY implements HTTP request/response processing. This allows us to use SPDY without much or no change to the existing website.
Shortcomings of the HTTP 1.1 protocol
- The biggest disadvantage of the HTTP protocol is that each TCP connection can only correspond to one HTTP request, i.e., each HTTP connection requests only one resource, and the browser can only solve this problem by establishing multiple connections. In addition, requests are made on a strict first-in-first-out (FIFO) basis in HTTP, so if an intermediate request takes longer to process, it will block later requests.
- HTTP only allows requests to be initiated by the client. The server can only wait for the client to send a request, which is a shackle in the status quo that can satisfy preloading.
- HTTP header redundancy. HTTP headers are sent repeatedly in the same session, and redundant information in between, such as User-Agent, Host, and other information that does not need to be sent repeatedly, is also being sent repeatedly, wasting bandwidth and resources.
Benefits of SPDY protocol:
- Multiplexing request optimization. SPDY provides for an unlimited number of parallel requests within a single SPDY connection, i.e., it allows multiple concurrent HTTP requests to share a single TCP session. This makes SPDY more efficient by multiplexing multiple requests on a single TCP connection instead of opening separate connections for each request, so that only one TCP connection can be established to deliver all the resources on the web page, reducing message interaction round-trip time and avoiding delays caused by creating new connections. In addition, SPDY’s multiplexing can set priority, unlike traditional HTTP, which processes requests one by one strictly on a first-in-first-out basis, it selectively transfers more important resources such as CSS first, and then less important resources such as website icons.
- Supports server push technology. The server can initiate communication to the client to push data to the client. This preloading allows the user to maintain a fast network all the time.
- SPDY compresses HTTP headers. The unnecessary headers are discarded and compressed to save the waiting time and bandwidth associated with redundant data transfers.
- Google believes that the future of the Web must be a secure network connection, and all requests for SSL encryption make information transmission more secure.
In 2015, Google decided to merge SPDY into the HTTP standard and named it HTTP / 2.
HTTP/2
HTTP/2.0 is the first update to the HTTP protocol since the release of HTTP/1.1 in 1999, based primarily on the SPDY protocol, and was approved on February 17, 2015. Key features.
- HTTP/2 is in binary format rather than textual format
- HTTP/2 is fully multiplexed, rather than ordered and blocking - only one connection is needed for parallelism
- HTTP/2 uses header compression to reduce overhead
- HTTP/2 allows servers to actively “push” responses to the client cache
- HTTP/2’s changes over HTTP/1.1 do not break existing programs, but new programs can take advantage of the new features to get better speed.
- HTTP/2 retains much of the semantics of HTTP/1.1, such as request methods, status codes and even URIs, and most HTTP header fields are consistent. HTTP/2, however, uses a new approach to encoding and transferring data between clients and servers.
HTTP 2.0 can be considered an upgrade of SPDY (in fact, it was originally designed based on SPDY), but there are still differences between HTTP 2.0 and SPDY, as follows.
- 0 supports plaintext HTTP transmission, while SPDY forces the use of HTTPS
- 0 The message header compression algorithm uses HPACK instead of DEFLATE, which is used by SPDY
Using the HTTP2.0 test it can be seen that HTTP2.0 is a significant performance improvement over the previous protocol. Several features of the HTTP 2.0 protocol are summarized below.
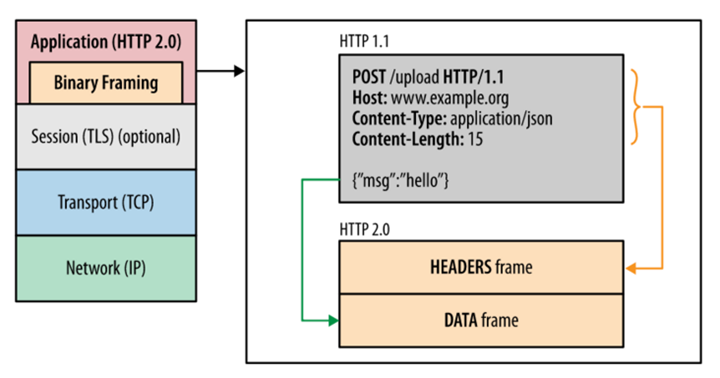
1) Binary Transfer
HTTP/1.1 has a header that is definitely text (ASCII) and a data body that can be either text or binary. HTTP/2 is a completely binary protocol, with both the header and the data body being binary and collectively referred to as “frames”: header frames and data frames.
HTTP/2 adds a binary framing layer between the application layer (HTTP/2) and the transport layer (TCP or UDP). It addresses the performance limitations of HTTP 1.1 without changing the semantics, methods, status codes, URIs, and prefix fields of HTTP/1.x. It improves transport performance and enables low latency and high throughput. In the binary framing layer, HTTP/2 splits all transmitted information into smaller messages and frames and encodes them in binary format, where the HTTP1.x header information is encapsulated in the HEADER frame and the corresponding Request Body is encapsulated in the DATA frame.
One of the benefits of the binary protocol is that additional frames can be defined. HTTP/2 defines nearly a dozen frames, laying the groundwork for advanced applications in the future. Parsing the data would become very cumbersome if such functionality were implemented using text, binary parsing is much easier.
2) Multiplexing/ Binary Framing
Multiplexing allows multiple request-response messages to be initiated simultaneously over a single HTTP/2 connection. In the HTTP/1.1 protocol browser clients are limited to a certain number of requests for the same domain at the same time. Requests that exceed the limit are blocked. This is one of the reasons why some sites have multiple static resource CDN domains, while HTTP/2’s Multiplexing allows multiple request-response messages to be initiated over a single HTTP/2 connection at the same time. HTTP/2 therefore makes it easy to implement multiple streams in parallel without relying on the establishment of multiple TCP connections. HTTP/2 reduces the basic unit of HTTP protocol communication to a single frame, which corresponds to a message in a logical stream. Messages are exchanged in both directions over the same TCP connection in parallel.
In HTTP 2.0, two concepts are important: the frame and the stream. A frame is the smallest unit of data, each frame identifies the stream to which it belongs, and a stream is a flow of data consisting of multiple frames.
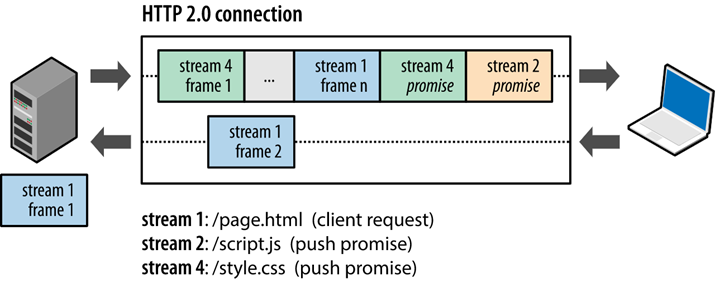
By multiplexing, we mean that there are multiple streams in a TCP connection, i.e., multiple requests can be sent at the same time, and the other end can know which request the frame belongs to by the representation in the frame. At the client side, these frames are sent in a jumbled order and then reassembled at the other end based on the stream identifier at the beginning of each frame. With this technique, the queue head blocking problem of older versions of HTTP can be avoided, greatly improving transmission performance
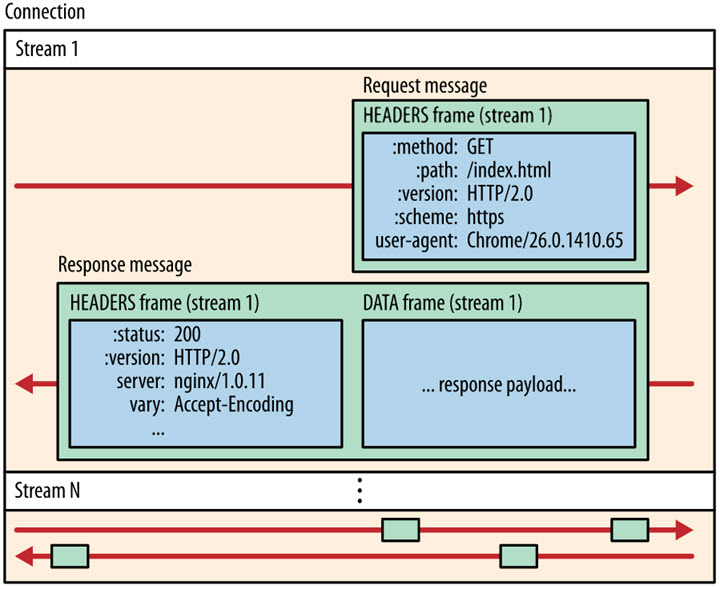
Because HTTP/2 packets are sent out of order, consecutive packets inside the same connection may belong to different responses. Therefore, the packet must be marked to indicate which response it belongs to.
HTTP/2 refers to all packets of each request or response as a stream. Each stream is given a unique number. When a packet is sent, it must be marked with a stream ID to distinguish which stream it belongs to. It is also specified that the ID is always odd for streams sent by the client and even for those sent by the server.
The only way to cancel a stream in version 1.1 is to close the TCP connection. This means that HTTP/2 can cancel a request while ensuring that the TCP connection is still open and can be used by other requests.
The client can also specify the priority of the data stream. The higher the priority, the sooner the server will respond.
By splitting each frame with a stream ID to avoid sequential responses, the other side receives the frame and splices the stream according to the ID, thus avoiding head-of-queue blocking during requests by making the response chaotic. However, the blocking problem at the TCP level cannot be solved by HTTP/2 (HTTP is an application layer protocol, TCP is a transport layer protocol), because the TCP blocking problem is due to the possibility of packet loss during the transmission phase, and once the packet is lost, it will wait for resending and block the subsequent transmission. It does not solve the problem completely.
3) Header Compression
HTTP/1.1 does not support HTTP header compression, for this reason SPDY and HTTP/2 were created, SPDY uses the generic DEFLATE algorithm, while HTTP/2 uses the HPACK algorithm, which is designed specifically for header compression.
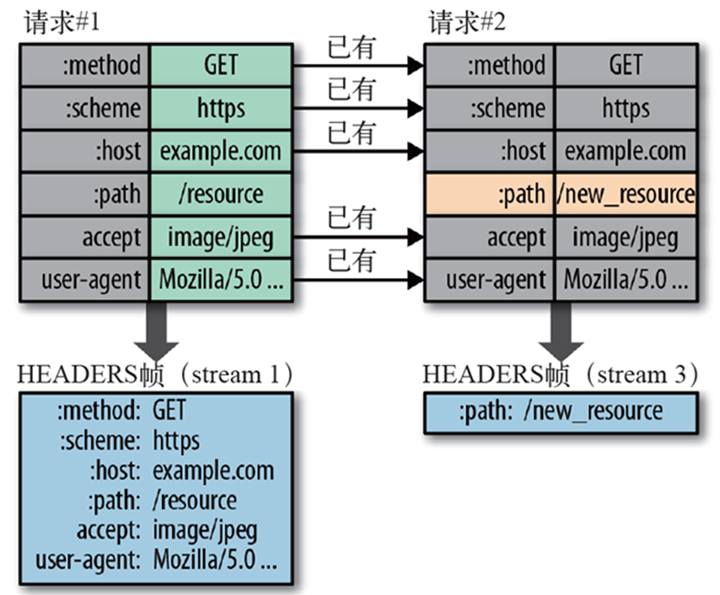
When a client requests many resources from the same server, like images from the same web page, there will be a large number of requests that look almost identical, which requires compression techniques to deal with this almost identical information. the HTTP protocol does not come with state, and all information must be attached to each request. So, many fields of the request are duplicated, such as Cookie and User Agent, exactly the same content that must be attached to each request, which wastes a lot of bandwidth and affects speed. Therefore, HTTP 2 can maintain a header information dictionary and update the header information in a differential amount to reduce the resources occupied by the header information transmission.
4) Server Push
HTTP/2 allows the server to send resources to the client unsolicited, which is called server push.
A common scenario is that the client requests a web page that contains many static resources. Under normal circumstances, the client must receive the web page, parse the HTML source code, find static resources, and then send a static resource request. In fact, the server can expect that after the client requests the web page, it is likely to request static resources again, so it takes the initiative to send these static resources to the client along with the web page.
In HTTP 2.0, the server can take the initiative to push other resources after a certain request from the client. You can imagine that some resources will be requested by the client, and then you can take the server-side push technology to push the necessary resources to the client in advance, which can relatively reduce the delay time a little. You can also use prefetch in the case of browser compatibility.
QUIC
Here are some brief introductions.
The background of QUIC’s creation
HTTP 2.0, while already performing well, still has many shortcomings.
- Long connection establishment time (essentially a TCP problem)
- Queue head blocking problem
- Poor performance in mobile Internet (weak network environment)
- ……
All these shortcomings are basically due to the TCP protocol.
TCP is a connection-oriented, reliable transport layer protocol on which almost all important current protocols and applications are based.
The network environment is changing rapidly, but the TCP protocol is relatively slow, and it was this paradox that prompted Google to make a seemingly unexpected decision to develop a new generation of HTTP protocols based on UDP.
Looking at the shortcomings of TCP and some of the advantages of UDP alone.
- There are so many devices and protocols developed based on TCP that compatibility is difficult
- The TCP stack is a significant part of Linux internals, and modifications and upgrades cost a lot
- UDP itself is connectionless, no chain building and unlinking costs
- UDP’s packets have no queue head blocking problem
- UDP retrofitting costs are small
It is never easy for Google to modify and upgrade from TCP, but while UDP does not have the problems caused by TCP to ensure reliable connections, UDP itself is unreliable and cannot be used directly.
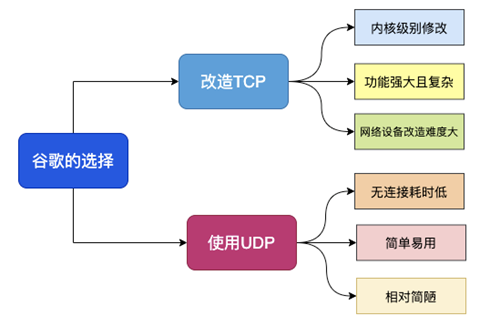
In combination, it is logical that Google decided to transform a new protocol with the advantages of TCP protocol on top of UDP, and this new protocol is QUIC protocol.
Introduction to QUIC
QUIC is actually an abbreviation for Quick UDP Internet Connections, which directly translates to Fast UDP Internet Connection.
Some introduction to the QUIC protocol from Wikipedia: Originally designed, implemented and deployed by Jim Roskind at Google in 2012, the QUIC protocol was publicly announced in 2013 as experiments expanded and were described to the IETF. QUIC improves the performance of connection-oriented web applications that are currently using TCP. It does this by establishing multiple multiplexed connections between two endpoints using User Datagram Protocol (UDP). secondary goals of QUIC include reducing connection and transmission latency and performing bandwidth estimation in each direction to avoid congestion. It also moves the congestion control algorithm to user space rather than kernel space, in addition to scaling using forward error correction (FEC) to further improve performance in the event of errors.
HTTP/3.0
HTTP 3.0, also known as HTTP Over QUIC, abandons the TCP protocol in favor of using the UDP-based QUIC protocol to implement it.
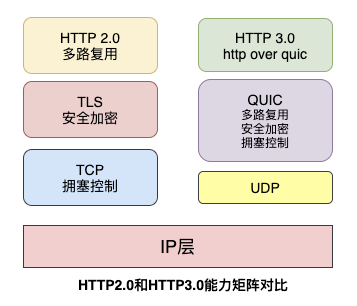
Since HTTP 3.0 has chosen the QUIC protocol, it means that HTTP 3.0 basically inherits the powerful features of HTTP 2.0 and further solves some of the problems that existed in HTTP 2.0, while inevitably introducing new problems.
Although the HTTP2 protocol has significantly improved the performance of HTTP/1.1, the TCP-based implementation of HTTP2 leaves behind three problems.
- Head-of-line blocking induced by sequential byte streams, which makes HTTP2’s multiplexing capability much worse.
- TCP and TLS overlay the handshake delay, and there is room for a 1x reduction in the chain-building time.
- Determining a connection based on TCP quaternions, a design born in wired networks, is not suitable for wireless networks in the mobile state, which means that frequent changes in IP addresses lead to repeated handshaking of TCP connections, TLS sessions, and high costs.
The HTTP3 protocol addresses these issues.
- HTTP3 redefines connections based on the UDP protocol, enabling the transmission of unordered, concurrent byte streams at the QUIC layer, solving the head-of-queue blocking problem (including dynamic table-based head-of-queue blocking based on QPACK).
- HTTP3 redefines the way the TLS protocol encrypts QUIC headers, both increasing the cost of network attacks and reducing the speed of establishing connections (only 1 RTT is needed to complete both chain building and key negotiation).
- HTTP3 separates Packet, QUIC Frame, and HTTP3 Frame, which enables connection migration function and reduces the connection maintenance cost of high-speed mobile devices in 5G environment.
1) Head-of-line blocking problem
Head-of-line blocking Head-of-line blocking (abbreviated as HOL blocking) is a computer network is a performance-limited phenomenon, in layman’s terms: a packet affects a bunch of packets, it does not come everyone can not go.
Head-of-line blocking problem may exist in the HTTP layer and TCP layer, in HTTP1.x when both levels have the problem.
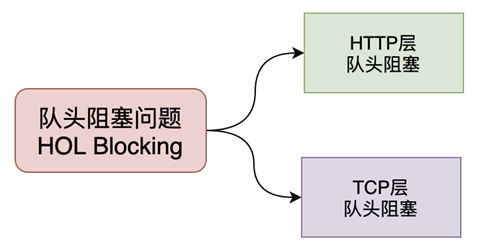
The multiplexing mechanism of the HTTP 2.0 protocol solves the queue head blocking problem at the HTTP layer, but the queue head blocking problem still exists at the TCP layer.
After the TCP protocol receives a packet, this data may arrive in disordered order, but TCP must collect and sort all the data for the upper layers to use, and if one of the packets is lost, it must wait for retransmission, thus a lost packet data blocks the data use of the whole connection.
The QUIC protocol is based on the UDP protocol, and there can be multiple streams on a link, and the streams do not affect each other, so when a stream has a packet loss, the impact is very small, thus solving the head blocking problem.
2)0RTT Link Building
A common metric for measuring network link building is RTT Round-Trip Time, which is the time consumed for one round-trip of data packets.
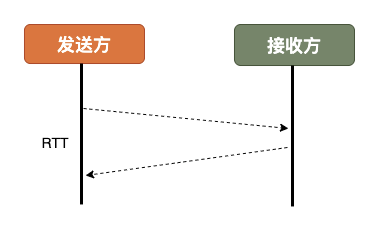
RTT consists of three components: round-trip propagation delay, queuing delay within network devices, and application data processing delay.
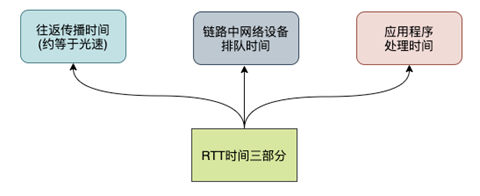
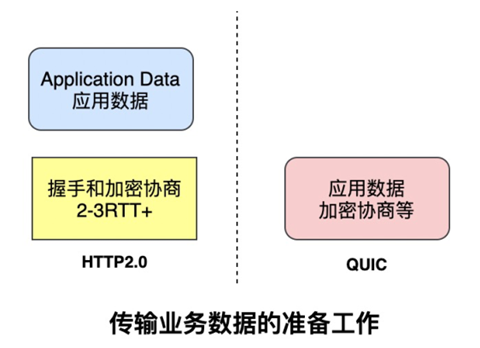
Generally speaking HTTPS protocol requires at least 2-3 RTTs in total to establish a complete link including: TCP handshake and TLS handshake, and the normal HTTP protocol also requires at least 1 RTT to complete the handshake.
However, the QUIC protocol can achieve 0 RTT by including valid application data in the first packet, but this is also conditional.
Simply put, HTTP 2.0, based on TCP and TLS protocols, takes some time to complete the handshake and encryption negotiation before the packet is actually sent, and only after that can the actual business data be transmitted.
But QUIC, on the other hand, can send business data on the first packet, thus having a significant advantage in connection latency, saving hundreds of milliseconds.
QUIC’s 0RTT also requires conditions, and for the first interaction between the client and the server 0RTT is also not doable, after all, both parties are completely unknown.
Therefore, the QUIC protocol can be discussed in two cases, first-time connection and non-first-time connection.
The client and server using the QUIC protocol have to use 1RTT for key exchange, and the exchange algorithm used is the DH (Diffie-Hellman) Diffie-Hellman algorithm.
First connection
Briefly, the key negotiation and data transfer process between the client and the server during the first connection involves the basic process of the DH algorithm.
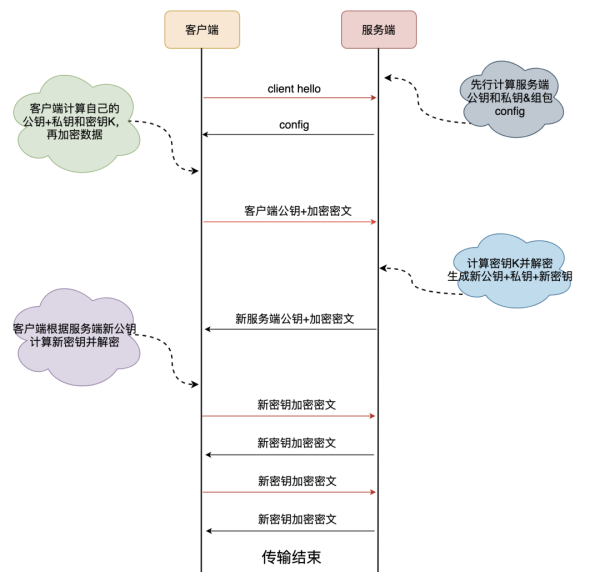
Non-first connection
As mentioned earlier, the client and the server pass the config package when they connect for the first time, which contains the server’s public key and two random numbers, and the client stores the config, which can be used directly when connecting again, thus skipping the 1RTT and realizing the 0RTT business data interaction.
There is a time limit for the client to save the config, and the key exchange at the first connection is still required after the config expires.
3) Forward Security Issues
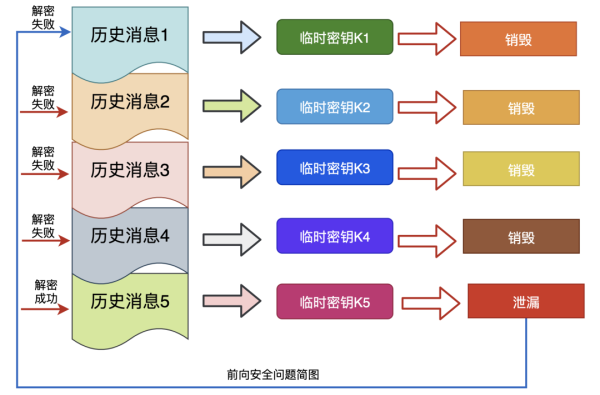
Forward security or forward secrecy Forward Secrecy is a security property of communication protocols in cryptography, which refers to the fact that the leakage of a long-used master key does not lead to the leakage of past session keys. Forward security protects communications conducted in the past from the threat of cryptographic or key exposure in the future. If a system has forward security, it can guarantee the security of historical communications in the event of a master key compromise, even if the system is actively attacked. In layman’s terms, forward security means that a key leak will not allow previously encrypted data to be leaked even if the key is compromised, affecting only the present and having no effect on previous data.
As mentioned earlier, QUIC protocol generates two encryption keys when connecting for the first time, and since the config is stored by the client, if the private key of the server is leaked during the period, then the key K can be calculated based on K = mod p. If this key is used for encryption and decryption all the time, then all historical messages can be decrypted with K. Therefore, a new key is subsequently generated and used for encryption and decryption, and at that time is destroyed when the interaction is completed, thus achieving forward security.
4) Forward Error Correction
Forward Error Correction also called Forward Error Correction Code Forward Error Correction abbreviated as FEC is a method to increase the trustworthiness of data communication, in a one-way communication channel, once the error is detected, its receiver will not have the right to request another transmission.FEC is a method to use data for transmission redundancy information, when an error occurs in transmission, will allow the receiver to build the data again.
The QUIC performs a heterodyne operation on each set of data sent and sends the result as a FEC packet. The receiver receives this set of data and can perform checksum and error correction based on the data packet and the FEC packet.
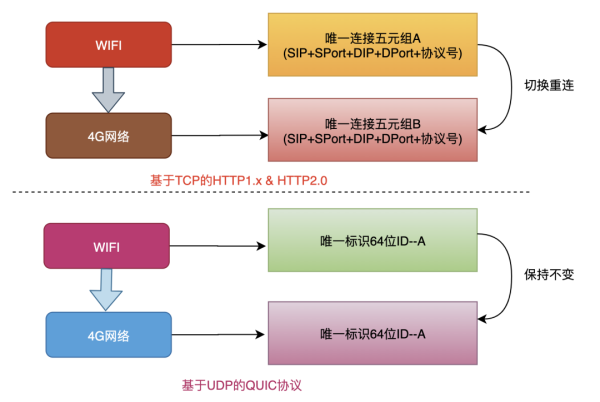
5) Connection Migration
Network switching happens almost all the time.
The TCP protocol uses a quintet to represent a unique connection, and when we switch from a 4G environment to a wifi environment, the IP address of the phone changes, and a new TCP connection must be created to continue transmitting data.
QUIC protocol based on UDP implementation discards the concept of quintet and uses a 64-bit random number as the ID of the connection and uses that ID to represent the connection.
Based on QUIC protocol, we can improve the service layer experience by not reconnecting during daily wifi and 4G switching, or switching between different base stations.