A few days ago we used NodeLocal DNSCache to solve the 5 second timeout problem with CoreDNS, and the cluster DNS resolution performance was significantly improved. However, today we encountered a major pitfall, when we were doing DevOps experiments, the tools were using custom domains, so we needed to add custom domain name resolution to access each other, which we could solve by adding hostAlias to Pods, but when using Jenkins’ Kubernetes plugin, this parameter was not supported. This parameter is not supported when using Jenkins’ Kubernetes plugin and needs to be defined using YAML, which is a bit of a pain, so we thought we’d add an A record via CoreDNS to solve this problem.
Normally we just need to add the hosts plugin to the ConfigMap of CoreDNS and it will work.
However, after the configuration is complete, the custom domain name never resolves.
This is a bit strange, doesn’t the hosts plugin work this way? After some checking, I was convinced that this was the right way to configure it. Then I turned on CoreDNS logging to filter the resolution logs for the above domain name.
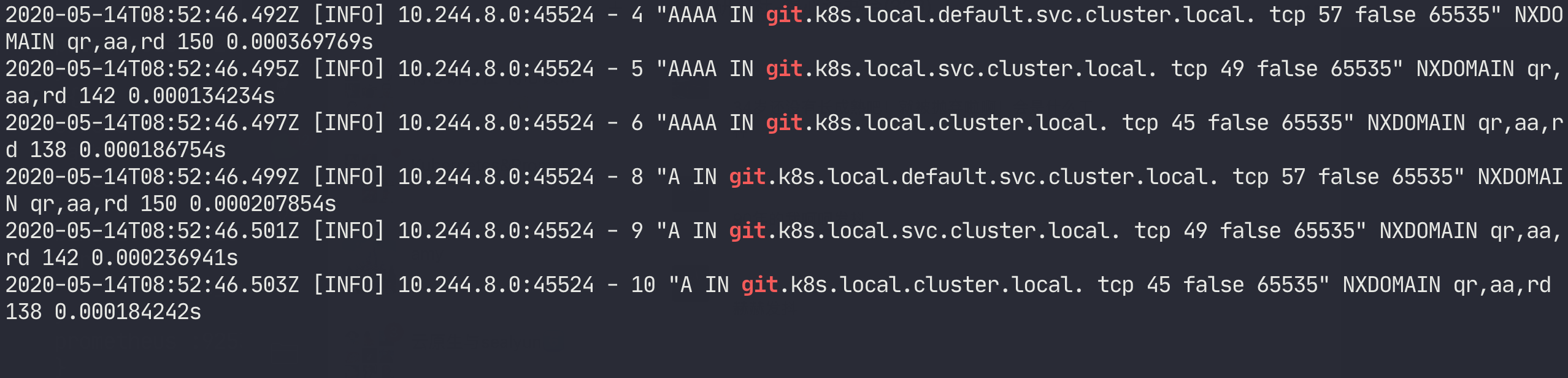
We can see that we walked through the search field, but did not get the correct parsing result, which is a bit puzzling. After tossing around a bit, it occurred to me that we have NodeLocal DNSCache enabled in the cluster, could this be the cause of the problem? Isn’t this the component that forwards queries to CoreDNS when the resolution doesn’t hit?
To verify this, let’s test the resolution directly using the CoreDNS address: NodeLocal DNSCache.
It was found to be correct, which means that there is nothing wrong with the CoreDNS configuration, and the problem must be caused by the NodeLocal DNSCache, which was found to be a direct failure using the LocalDNS address (169.254.20.10).
At this point it’s time to look at the LocalDNS Pod logs:
|
|
Analyzing the LocalDNS configuration information above, 10.96.0.10 is the Service ClusterIP of CoreDNS, 169.254.20.10 is the IP address of LocalDNS, and 10.96.207.156 is a new Service ClusterIP created by LocalDNS This Service is associated with the same list of CoreDNS Endpoints as CoreDNS.
A closer look reveals that cluster.local, in-addr.arpa and ip6.arpa are forwarded to 10.96.207.156 via forward, i.e. to CoreDNS for resolution, while the others are forward . /etc/resolv.conf through the resolv.conf file, which reads as follows.
So when we resolve the domain git.k8s.local we need to go through the search domain, while the domain cluster.local is directly forwarded to CoreDNS for resolution, CoreDNS naturally does not resolve these days records. So isn’t it natural to think that we can just configure the hosts plugin on the LocalDNS side? This should be exactly the right idea:
|
|
After the update is complete, we can manually rebuild the NodeLocalDNS Pod and find that the NodeLocalDNS Pod fails to start, with the following error message.
|
|
It turns out that the hosts plugin is not supported at all. Then we have to go to CoreDNS to resolve it, so this time we need to change forward . /etc/resolv.conf to forward . 10.96.207.156, which will go to CoreDNS, and make the following changes in the ConfigMap of NodeLocalDNS.
Once the same changes are made, the NodeLocalDNS pod will need to be rebuilt for the changes to take effect.
The
__PILLAR__CLUSTER__DNS__and__PILLAR__UPSTREAM__SERVERS__parameters are automatically configured in mirror 1.15.6 and above, and the corresponding values are derived from kube-dns ConfigMap and the custom Upstream Server address.
Now let’s go back and test that the custom domain name resolves properly.
For those using NodeLocalDNS be aware of this issue, if the hosts or rewrite plugins are not working, this is basically the cause of the problem. The best way to troubleshoot problems is always to analyze them through logs.