Why MySQL uses B+ trees is a question that often comes up in interviews. Many people may have some understanding of this question, but most answers are incomplete and inaccurate, and most people simply talk about the difference between B+ and B trees. But none of them really answer the question of why MySQL chooses to use B+ trees. In this article, we will analyze in depth some of the reasons behind MySQL’s choice of B+ trees.
Overview
The first point to clarify is that MySQL has no direct relationship with B+ trees, but rather with InnoDB, MySQL’s default storage engine, which is responsible for storing and extracting data, and also supports MyISAM as the underlying storage engine for tables.

We can specify the storage engine for the current table when we create the table with SQL statement, you can find all the supported storage engines in MySQL’s documentation Alternative Storage Engines, such as MyISAM, CSV, MEMORY, etc. By default, however, creating a table using the SQL statement as shown below will result in a table supported by the InnoDB storage engine.
The final question we are going to analyze today is why MySQL’s default storage engine, InnoDB, uses B+ trees to store data. I believe anyone who knows a little bit about MySQL knows that both the data in the table (primary key index) and the secondary index will eventually use B+ trees to store data, where the former will be stored in the table as <id, row> and the latter will be stored as <index, id>, which is actually quite understandable.
- In a primary key index,
idis the primary key and we are able to find all the columns of the row byid. - In a secondary index, where several columns in the index form the key, we are able to find
idby the columns in the index and then, if needed, the entire contents of the current data row byid.
For InnoDB, all data is stored as key-value pairs. Primary and secondary indexes will store data with id and index as keys, and all columns and id as the values corresponding to the keys.
Before we analyze the reasons behind InnoDB’s use of B+ trees, we need to find a few “imaginary enemies” for B+ trees, because if we had only one choice, then choosing B+ trees wouldn’t be worth discussing. The two imaginary enemies we found are the B-tree and the hash, which I believe is a real problem that many people will encounter in interviews, and we will use these two data structures as examples to analyze and compare the advantages of the B+ tree.
Design
At this point we have clarified the question to be discussed today, which is why MySQL’s InnoDB storage engine chooses B+ trees as the underlying data structure instead of B-trees or hashes? In this section, we will present the reasons for InnoDB’s choice in the following two ways.
- The scenarios and features that InnoDB needs to support require strong performance on specific queries.
- the CPU takes a lot of time to load data from disk into memory, which makes B+ trees a very good choice.
The persistence of data and the querying of persistent data is actually a common requirement, and the persistence of data requires us to deal with disk, memory, and CPU; MySQL as an OLTP database not only needs to have the ability to handle transactions, but also to ensure the persistence of data and to be able to have some real-time data querying ability, these requirements together determine the choice of B+ tree, and we will analyze the logic behind the above two reasons in detail.
Read/Write Performance
Many people may not be particularly familiar with the term OLTP, so let’s help you readers quickly understand that there are OLAP compared to OLTP, they are Online Transaction Processing and Online Analytical Processing, from these two names we can see that the former refers to The former refers to the traditional relational database, which is mainly used to deal with basic and daily transaction processing, while the latter is mainly used in data warehouses to support some complex analysis and decision making.
As the storage engine that underpins OLTP databases, we often use InnoDB to do some of the following.
- Adding, modifying, and deleting data in tables with the
INSERT,UPDATE, andDELETEstatements. - Bulk deletion of eligible data via the
UPDATEandDELETEstatements. - Querying all columns of a row with the
SELECTstatement and primary key. - querying a table for rows that match certain conditions and sorting them by certain fields via the
SELECTstatement. - querying the number of rows of data in a table by means of the
SELECTstatement. - ensuring the uniqueness of a field or fields in a table by means of a unique index.
If we use B+ tree as the underlying data structure, then the time complexity of all SQL that will only access or modify one piece of data is O(log n), which is the height of the tree, but it is possible to reach O(1) time complexity using hashing, which doesn’t look particularly nice. But the hash does not perform so well when we use the SQL as follows.
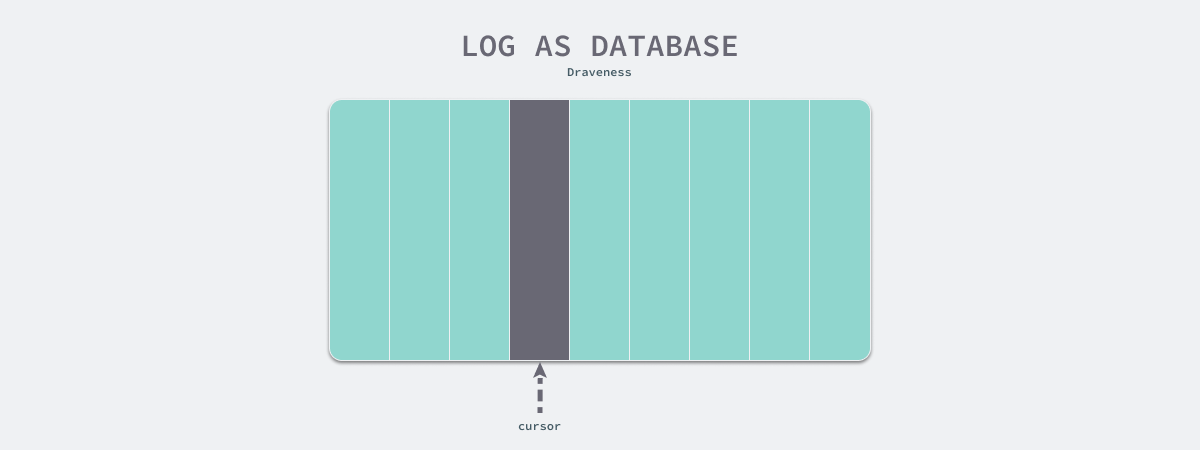
If we use hash as the underlying data structure, when we encounter the above scenario, there may be no way to quickly process the primary key index or secondary index using hash composition, it will be very poor performance for handling range queries or sorting, and we can only do a full table scan and determine whether the conditions are satisfied in turn. A full table scan is a very bad result for the database, which actually means that the data structure we use has no other effect on these queries, and the final performance may not even be as good as matching sequentially from the log.
Using a B+ tree actually ensures that the data is stored in the order of the keys, i.e. all adjacent data is actually in natural order, which is not possible with a hash, because the purpose of the hash function is to spread the data into as many buckets as possible, so a table with a hash as the underlying data structure may face a database query nightmare – a full table scan – when there may be identical keys author = 'draven or sorting and range queries comments_count > 10.
B-trees and B+-trees are actually somewhat similar in their data structure in that they can both traverse the contents of the index in some order, and they offer better performance than hashes for operations such as sorting and range queries, although they can still lead to full table scans if the index is not built well enough or if the SQL query is very complex.
Compared with B-tree and B+ tree, a table with hash as the underlying data structure can handle the addition, deletion, and correction of a single row of data in O(1) speed, but it will result in a full table scan when facing a range query or sorting, while B-tree and B+ tree need O(log n) time for the addition, deletion, and correction of a single row of data, but it will store the data with similar index columns in order, so it can avoid a full table scan.
Data Loading
Since using hashes cannot cope with operations like sorting and range queries in our common SQL, and both B-trees and B-trees and B+-trees can perform these queries relatively efficiently, why don’t we choose B-trees? The reason is very simple - computers load data into memory in pages when they read and write files. The page size may vary depending on the operating system, but in most operating systems the page size is 4KB, and you can get the page size on the operating system by using the following command:
The page size of the macOS system used by the authors is
4KB, but of course it is entirely possible to get different results on different computers.
When we need to query data in a database, the CPU will find that the current data is located on disk instead of in memory, which triggers an I/O operation to load the data into memory for access. The data is loaded in the page dimension, however the cost to read the data from disk into memory is very large. Normal disks (not SSDs) take about 10ms to load data through queuing, seeking, spinning, and transfer.

We can use the order of 10ms to estimate the time taken by random I/O when estimating MySQL queries. What we want to say here is that random I/O can have a huge impact on MySQL query performance, while sequential reading of data from disk can reach 40MB/s. The performance gap between the two is several orders of magnitude, so we should also try to reduce the number of random I/Os to improve performance.
The major difference between a B-tree and a B+ tree is that a B-tree can store data in non-leaf nodes, but a B+ tree actually stores all data in leaf nodes, and when the data structure at the bottom of a table is a B-tree, suppose we need to access all data that is ‘greater than 4 and less than 9’.
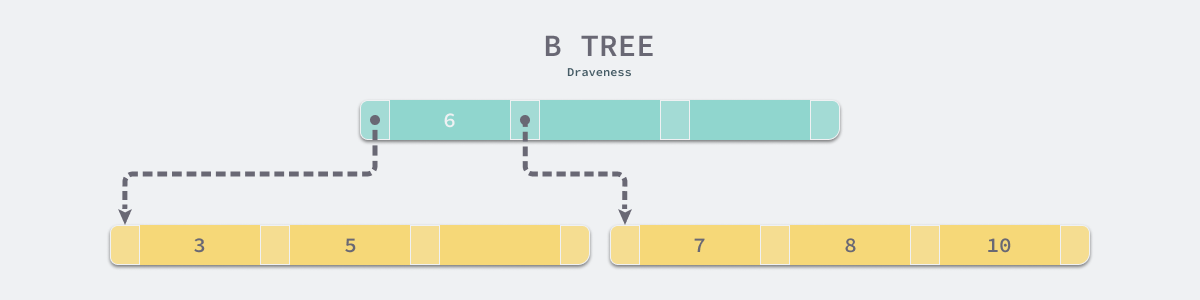
Without considering any optimization, in the above simple B-tree we would need to perform 4 random I/Os of the disk to find all the data rows that satisfy the following conditions.
- load the page where the root node is located and find that the first element of the root node is 6, which is greater than 4.
- load the page where the left child node is located via the pointer to the root node, traverse the data in the page, and find 5.
- reload the page where the root node is located and find that the root node does not contain a second element.
- load the page where the right child node is located by means of the pointer to the root node, traverse the data in the page and find 7 and 8.
Of course we can optimize the above process in various ways, but the B+ tree can do basically all the optimizations that the B tree can do, so we do not need to consider the benefits that come from optimizing the B tree, and it is straightforward to see what kind of optimizations the B+ tree can do that the B tree cannot.
Since all nodes may contain target data, we always have to traverse the subtree from the root node down to find the rows of data that satisfy the conditions, a feature that brings a lot of random I/O and is the biggest performance problem with B-trees.
This problem does not exist in the B+ tree because all data rows are stored in the leaf nodes, which can be connected sequentially by ‘pointers’, so that we can directly jump between multiple child nodes when traversing the data in the B+ tree as shown below. Sorting With a single leftmost leaf node of the B+ tree, we can traverse the entire tree like a chain table, or we can introduce a bidirectional chain table to ensure performance when traversing in reverse order.
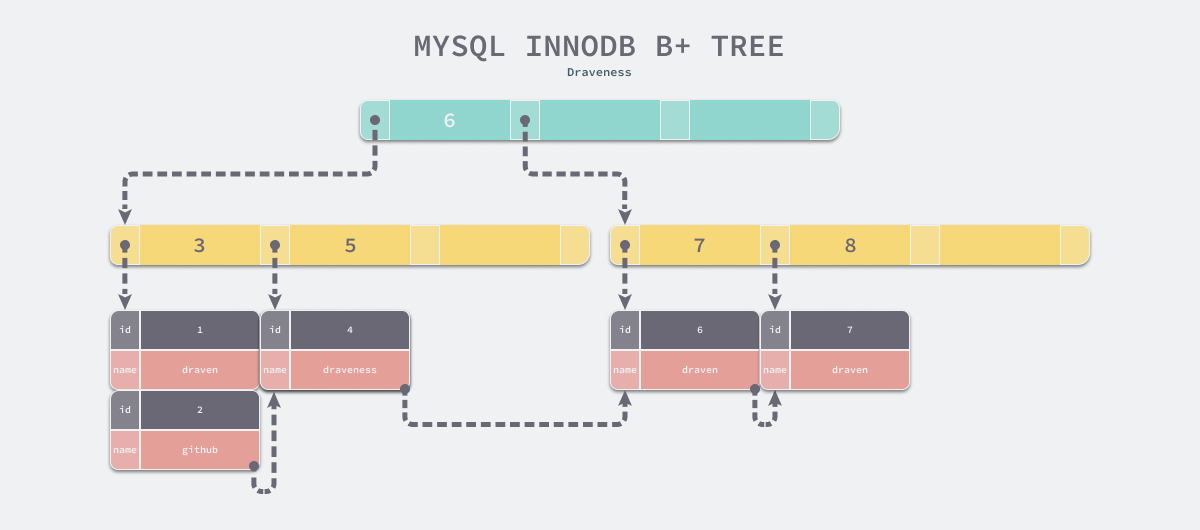
Some readers may think that using a data structure like a B+ tree increases the height of the tree and thus the overall time consumption. However, a B+ tree of height 3 is capable of storing tens of millions of data, and in practice B+ trees are at most 4 or 5 in height, so this is not a fundamental performance issue.
Summary
Any design that does not take into account the application scenario is not the best design. Once we clearly define the common query requirements when using MySQL and understand the scenario, it is only logical to choose a different data structure, and of course the B+ tree may not perform well for all OLTP scenarios, but it solves most of the problems.
Let’s revisit here the reasons why MySQL’s default storage engine chooses B+ trees over hashes or B-trees.
- Hashing, while capable of providing
O(1)performance for single-data-row operations, does not support range queries and sorting well, ultimately leading to full-table scans. - B-trees are able to store data in non-leaf nodes, but this also leads to potentially more random I/O when querying contiguous data, whereas B+ trees, where all leaf nodes can be interconnected by pointers, can reduce the additional random I/O generated during sequential traversal.
If we want to pursue the ultimate performance in all aspects is not impossible, but it will bring higher complexity, we can build both B+ tree and hash storage structure for a table, so that different types of queries can choose a relatively faster data structure, but it will lead to the need to operate multiple copies of data when updating and deleting.
From today’s point of view, B+ tree may not be the optimal choice for InnoDB, but it must be able to meet the needs of the design scenario at that time. Decades have passed since B+ tree was used as the underlying storage structure of the database, and we have to say that good engineering design does have enough vitality. And we, as engineers, should be very clear about the scenarios for which different databases are suitable when choosing a database, because there is no silver bullet in software engineering.
At the end of the day, let’s look at some of the more open and relevant questions, and interested readers can think carefully about the following.
- What kind of data structures do OLAP databases commonly used for analytics typically use to store data? Why?
- How does Redis store data persistently? What are some of the common data structures?