I will mainly list here the Consistent Hash algorithm, Gossip protocol, QuorumNWR algorithm, PBFT algorithm, PoW algorithm, ZAB protocol, and Paxos will be spoken separately.
Consistent Hash Algorithm
The Consistent Hash algorithm is designed to solve the migration cost of the Hash algorithm. Taking a 10-node cluster as an example, if you add nodes to the cluster, you need to migrate up to 90.91% of the data if you use the hash algorithm, and only 6.48% of the data if you use the Consistent Hash.
Therefore, when using the consistent hash algorithm for hash addressing, you can reduce the impact of node downtime on the entire cluster by increasing the number of nodes and the amount of data that needs to be migrated when recovering from a failure. Later, when needed, you can increase the number of nodes to improve the disaster recovery capacity and efficiency of the system. And when you do data migration, you only need to migrate some data to achieve cluster stability.
Consistent Hash Algorithm without Virtual Nodes
We all know that the common hash algorithm is modulo for routing addressing, and similarly the consistent hash uses modulo operations, but unlike the hash algorithm, which modulo for the number of nodes, the consistent hash algorithm modulo for 2^32. You can imagine that the consistent hash algorithm, the entire hash value space is organized into a virtual ring, that is, the hash ring.

In consistent hashing, you can map nodes to a hash ring by performing a hashing algorithm so that each node can determine its position on the hash ring.
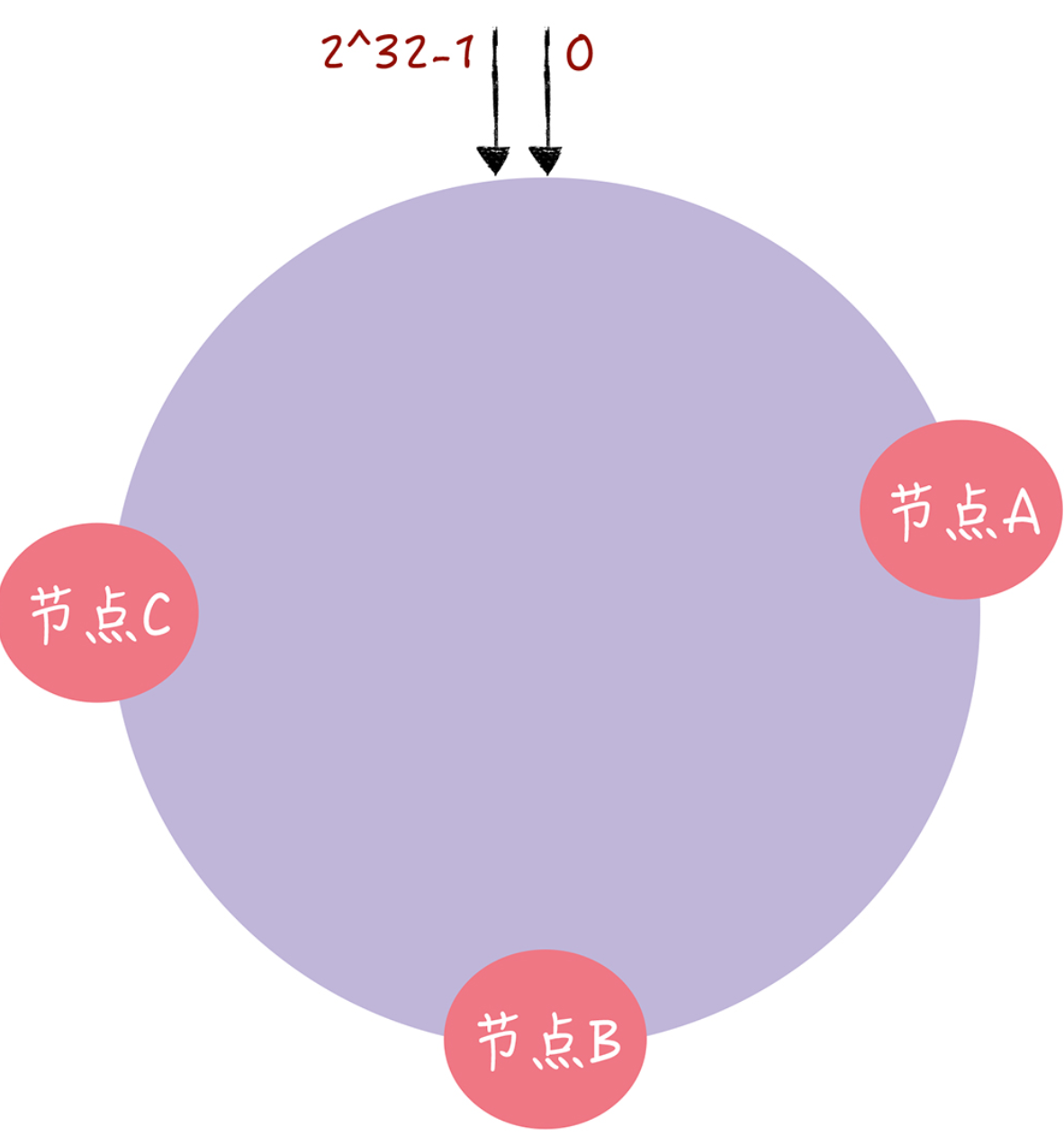
Then when the value of the specified key is to be read, by doing a hash on the key and determining the position of this key on the ring, the first node encountered is the node corresponding to the key when “walking” clockwise along the hash ring from this position.
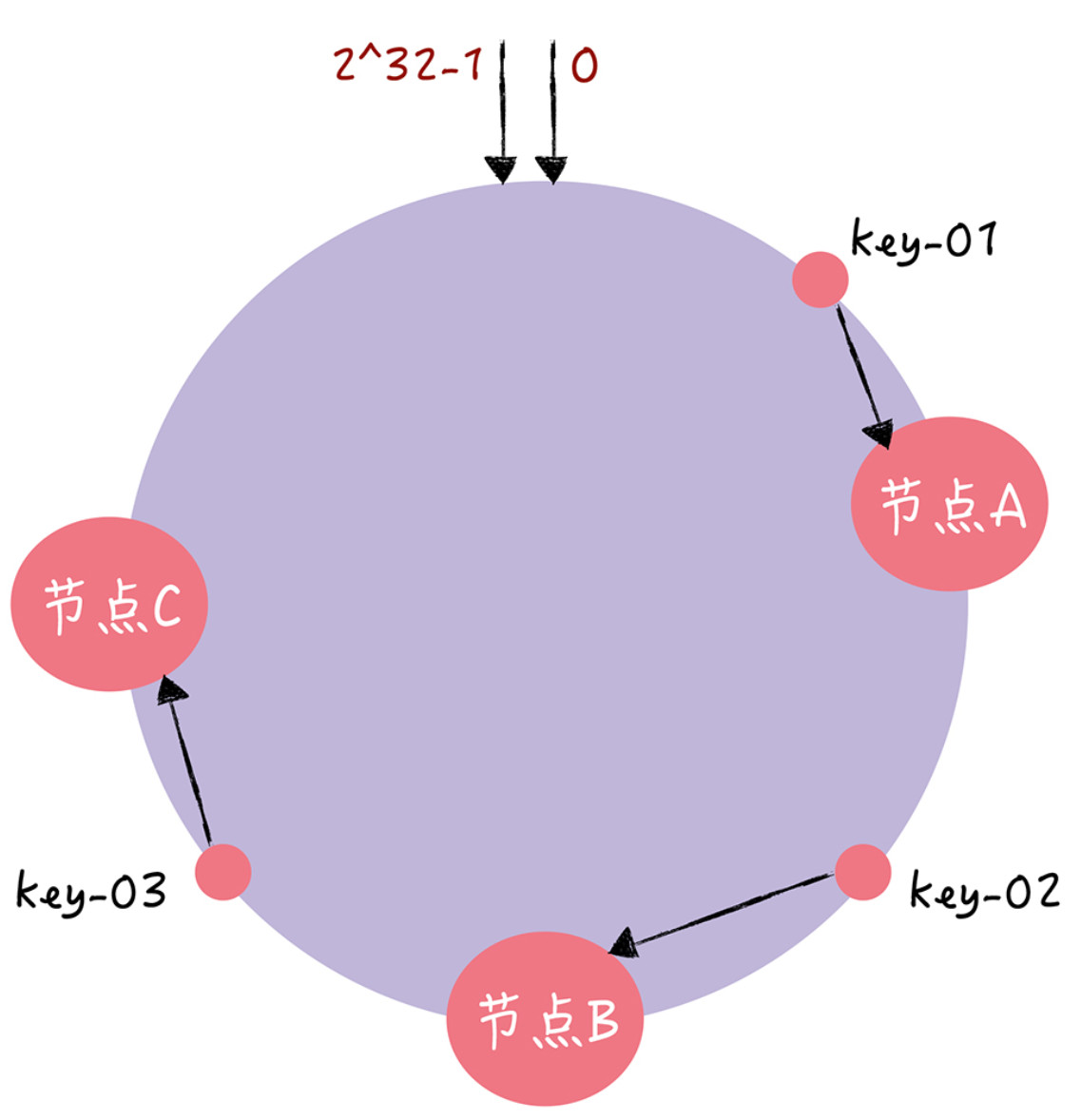
At this time, if node C is down, then the data of node B and node A will not actually be affected, only the data originally in node C will be relocated to node A, thus as long as the data of node C does the migration.
If the cluster cannot meet the business needs at this time, a node needs to be expanded.
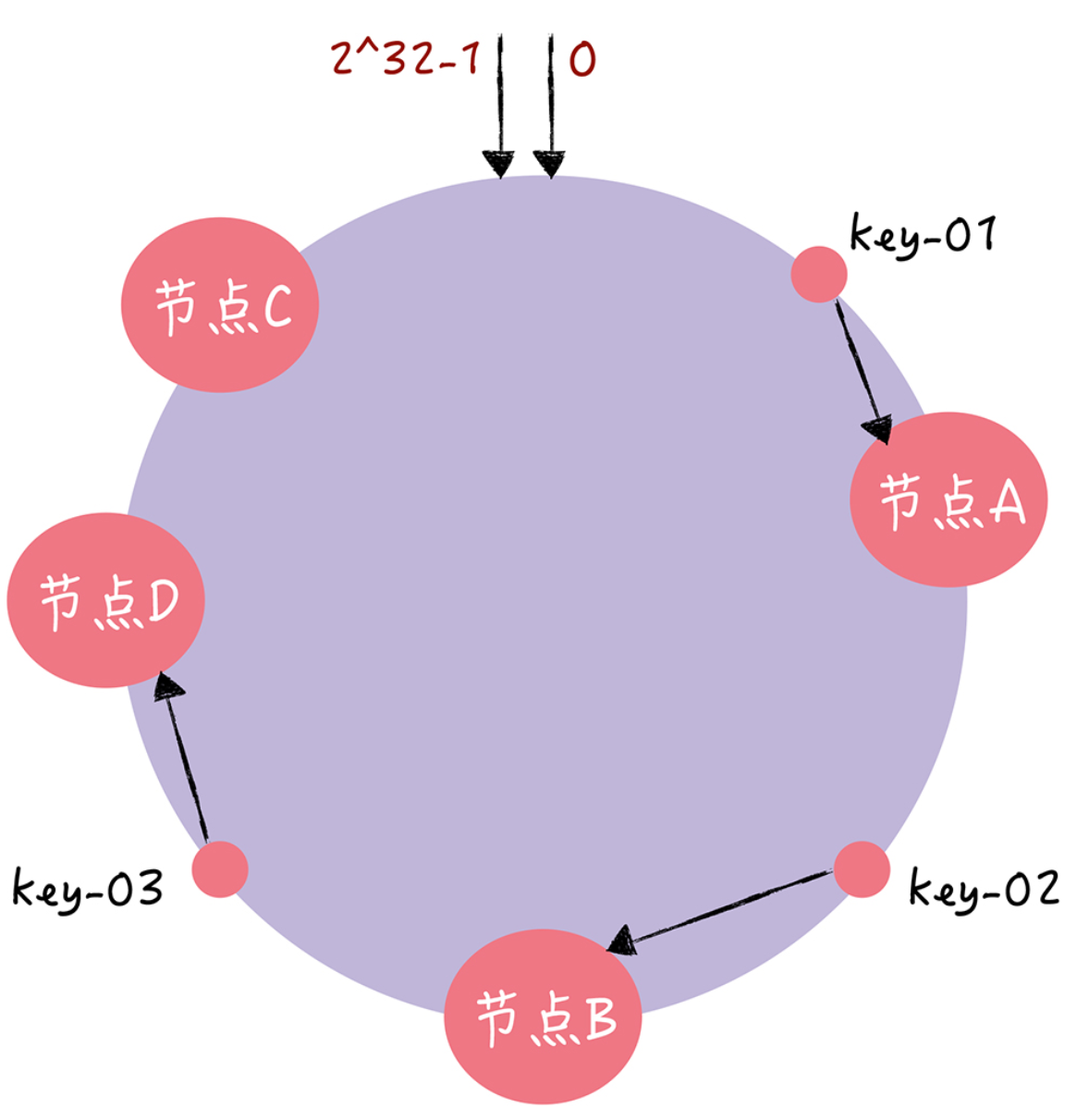
You can see that key-01 and key-02 are not affected, and only the addressing of key-03 is relocated to the new node D. In general, in the consistent hashing algorithm, if a node is added, the only data affected is the data that will be addressed between the new node and the previous node, and the other data will not be affected.
The implementation code is as follows.
|
|
Consistent Hash Algorithm with Virtual Nodes
The above hash algorithm may result in uneven data distribution, i.e., most access requests are concentrated on a few nodes. So we can solve the uneven distribution of data by virtual nodes.
In fact, it is to calculate multiple hash values for each server node, and place a virtual node at each calculated location, and map the virtual node to the actual node. For example, the number can be added after the host name to calculate “Node-A-01”, “Node-A-02”, “Node-B-01”, “Node-B-02”, respectively “Node-B-02”, “Node-C01”, “Node-C-02”, so that 6 virtual nodes are formed.
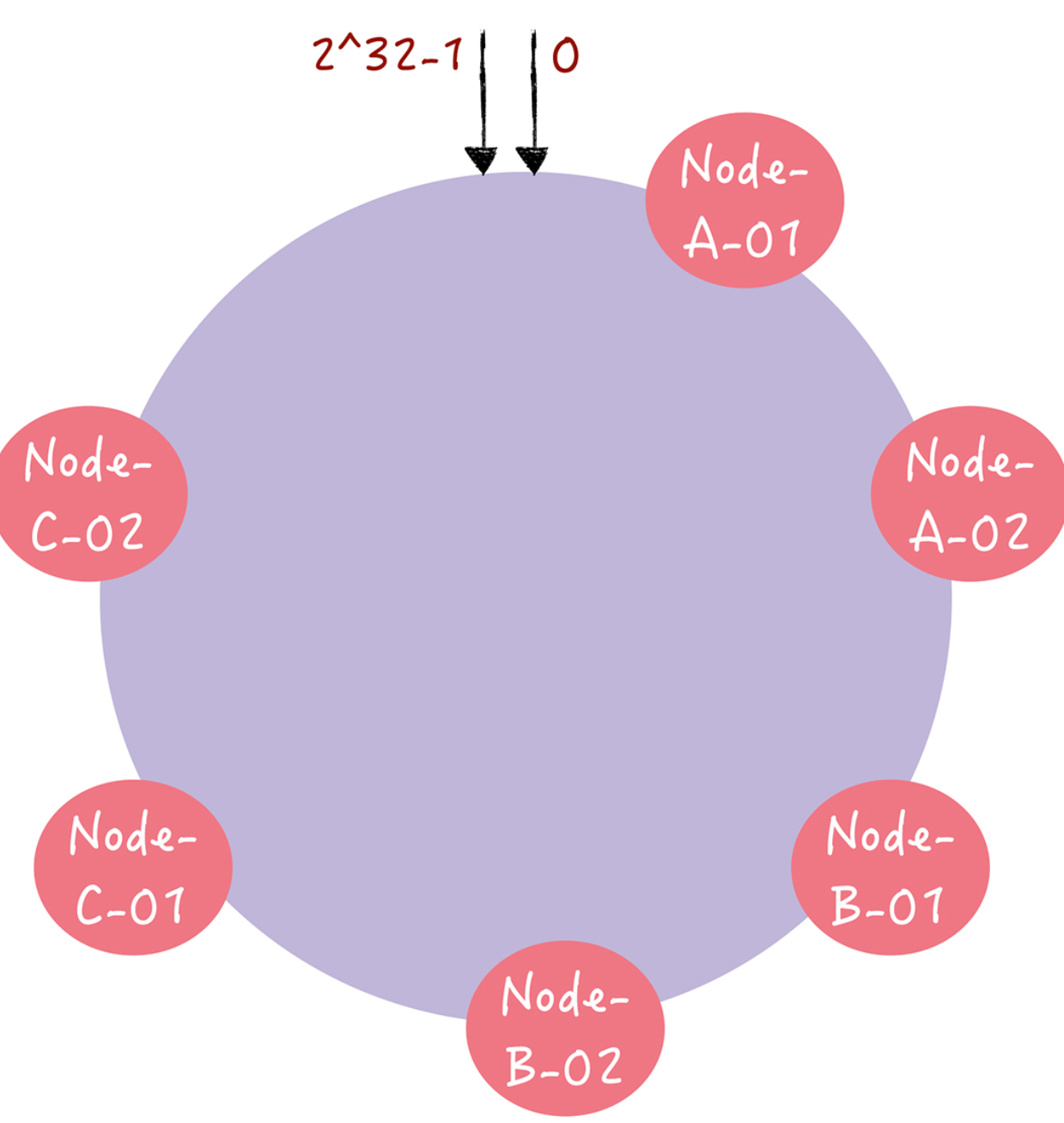
With the addition of nodes, the distribution of nodes on the hash ring is relatively even. At this point, if an access request addresses the virtual node “Node-A-01”, it will be relocated to Node A.
The specific code implementation is as follows.
|
|
Gossip Protocol
The Gossip protocol, as the name implies, uses a random and contagious way to spread information throughout the network and to make all nodes in the system consistent for a certain period of time. The Gossip protocol, with the above features, ensures that the system can operate in extreme situations (e.g., when only one node is running in a cluster).
Gossip Data Dissemination Methods
Gossip data propagation methods are: Direct Mail, Anti-entropy, and Rumor mongering.
Direct Mail: sends updates directly, caches them when they fail, and then retransmits them. Although direct mail is easier to implement and data synchronization is timely, data may be lost because the cache queue is full. In other words, it is not possible to achieve final consistency using only direct mail.
Anti-entropy: Anti-entropy means that the nodes in a cluster randomly select some other node at regular intervals, and then exchange all their data with each other to eliminate the difference between them and achieve the ultimate consistency of data.
In achieving anti-entropy, there are three main ways to push, pull and push-pull. The push approach is to push all the data of one’s own copy to the other to repair the entropy in the other’s copy, and the pull approach is to pull all the data of the other’s copy to repair the entropy in its own copy.
Rumor mongering (Rumor propagation): It means that when a node has new data, this node becomes active and periodically contacts other nodes to send it new data until all nodes have stored that new data. Since rumor propagation is very contagious, it is suitable for distributed systems that change dynamically
Quorum NWR algorithm
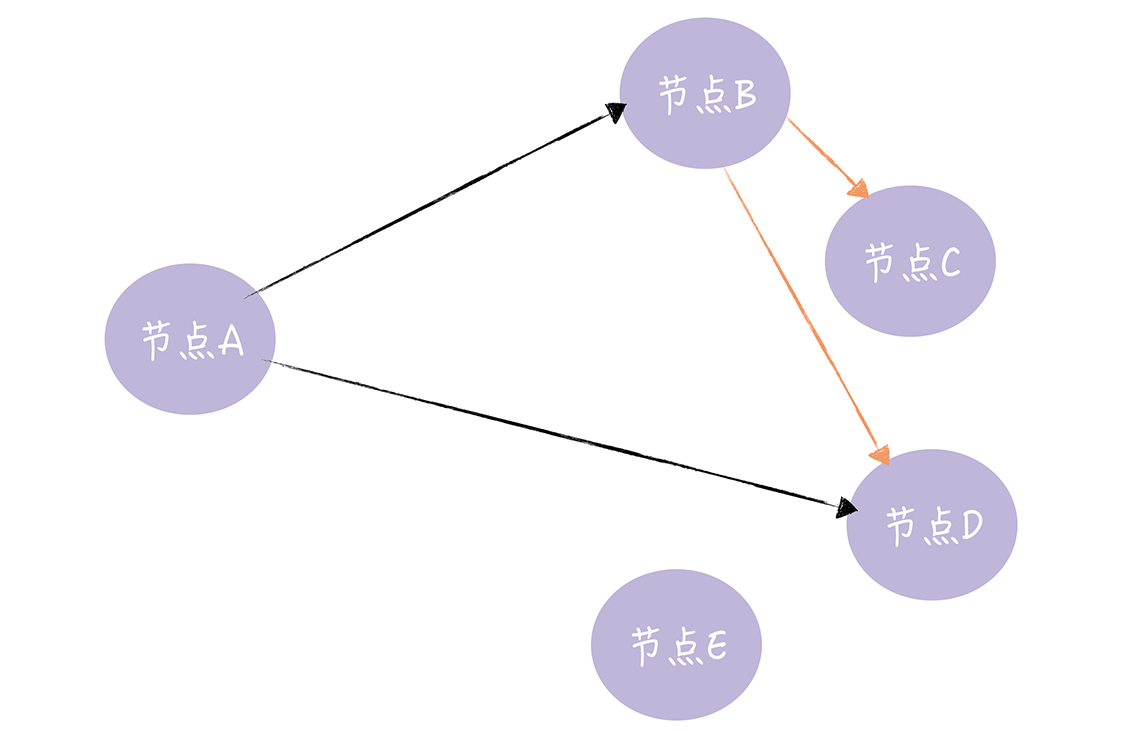
There are three elements in Quorum NWR, N, W, and R.
N is the number of replicas, also called the Replication Factor. That is, N represents the number of replicas of the same data in the cluster, as shown in the figure below.
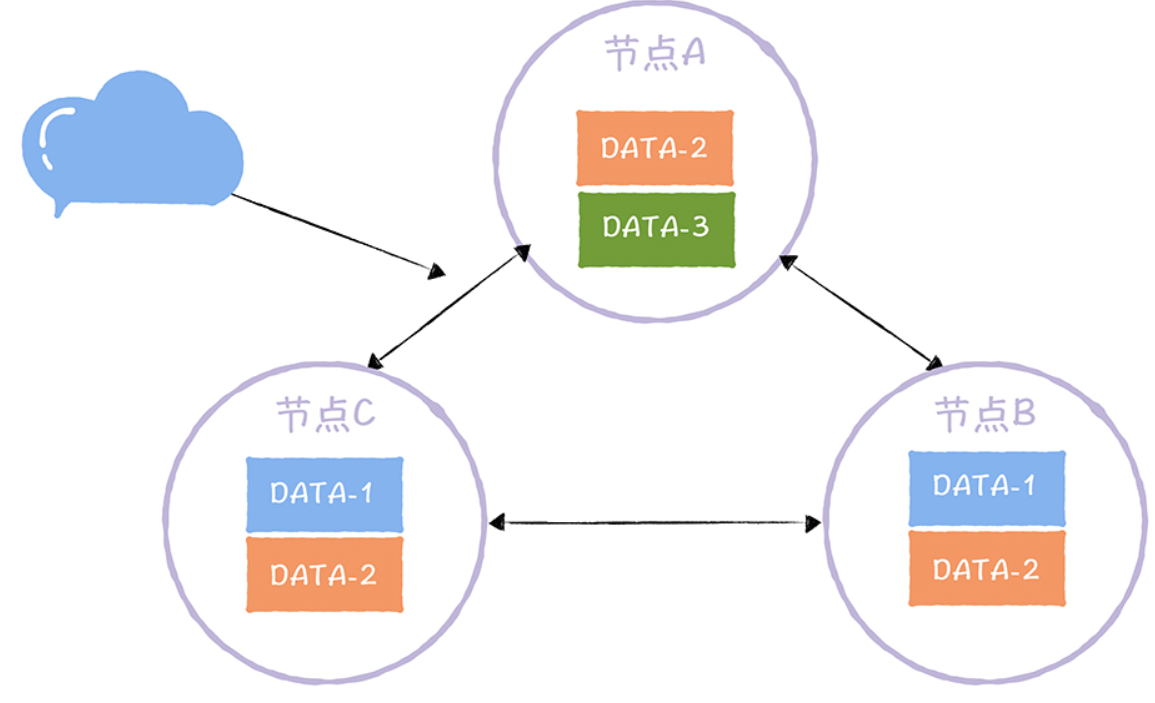
In this three-node cluster, DATA-1 has 2 replicas, DATA-2 has 3 replicas, and DATA-3 has 1 replica. In other words, the number of replicas may not be equal to the number of nodes, and different data may have different numbers of replicas.
W, also known as Write Consistency Level, indicates the successful completion of W replica updates.
R, also known as the Read Consistency Level, means that R copies of a data object need to be read when it is read.
With Quorum NWR, you can customize the consistency level by temporarily adjusting the writes or queries to achieve strong consistency when W + R > N.
So if you want to read node B, we then assume the formula W(2) + R(2) > N(3), that is, when writing two nodes and reading two nodes at the same time, then the read data must be read back to the client must be the latest copy of that data.
What you should note about NWR is that different combinations of N, W, and R values will produce different consistency effects, specifically, there are two effects.
When W + R > N, the entire system can guarantee strong consistency for the client, and will definitely return the updated data. When W + R < N, for the client, the system can only guarantee the final consistency and may return the old data.
PBFT Algorithm
The PBFT algorithm is very practical and is a Byzantine fault-tolerant algorithm that can be grounded in real-world scenarios.
Let’s start with an example to see a concrete implementation of the PBFT algorithm.
Suppose Su Qin is once again leading an army against Qin. On this day, Su Qin and four generals from four countries, Zhao, Wei, Han, and Chu, discuss important military matters, but not long after the discussion, Su Qin receives information that there may be a traitor in the allied army. How does Su Qin give the orders to ensure that the loyal generals carry out the orders correctly and consistently and are not interfered with by the traitor?
It is important to note that all messages are signed messages, meaning that the identity of the message sender and the content of the message cannot be forged or tampered with (for example, Chu cannot forge a message pretending to be from Zhao).
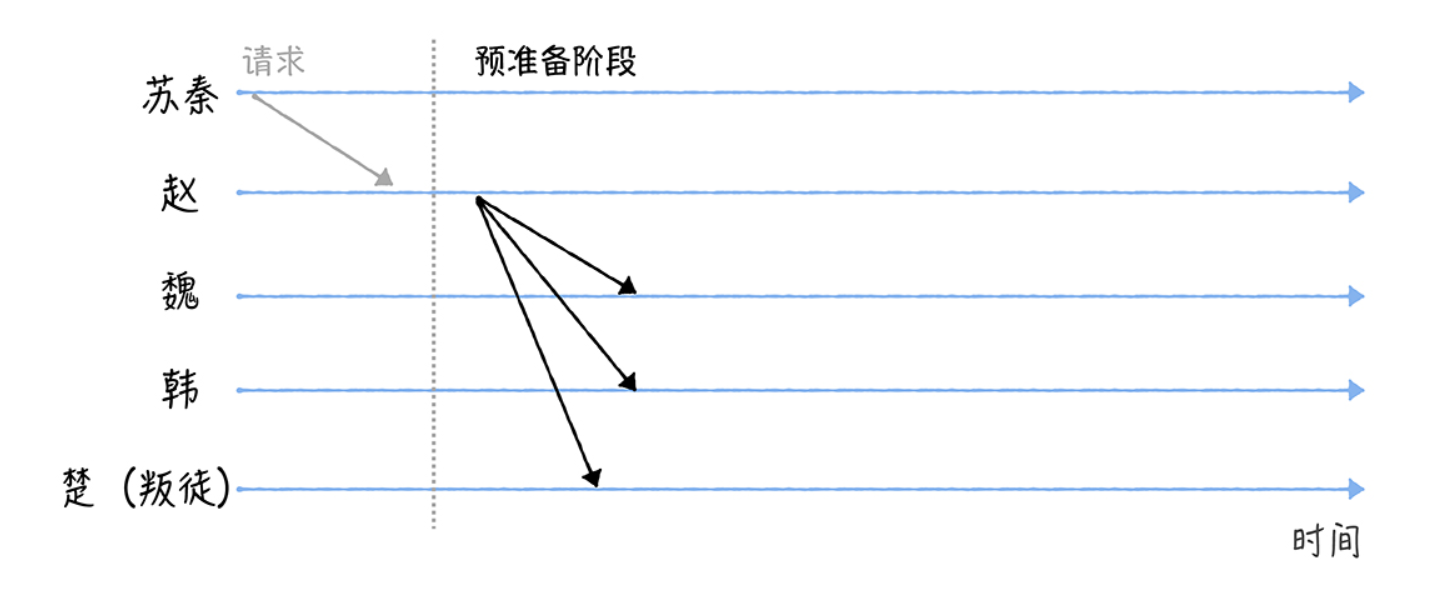
First, Su Qin contacts Zhao and sends a request to Zhao containing the command “attack” (as shown in the picture below).

When Zhao receives Su Qin’s request, it will execute the Three-phase protocol.
Zhao will enter the pre-preparation phase, constructing a pre-preparation message containing combat instructions and broadcasting it to the other generals (Wei, Han, and Chu).
Because Wei, Han and Chu, after receiving the message, could not confirm that they received the same instructions as the others received. So they need to move to the next phase.
After receiving the Prepare message, Wei, Han, and Chu will enter the Prepare phase and broadcast a Prepare message to the other generals with combat instructions.
For example, Wei broadcasts a preparation message to Zhao, Han, and Chu (as shown in the figure). For the sake of demonstration, let’s assume that the traitor Chu wants to interfere with the consensus negotiation by not sending a message (you can see in the diagram that Chu is not sending a message).
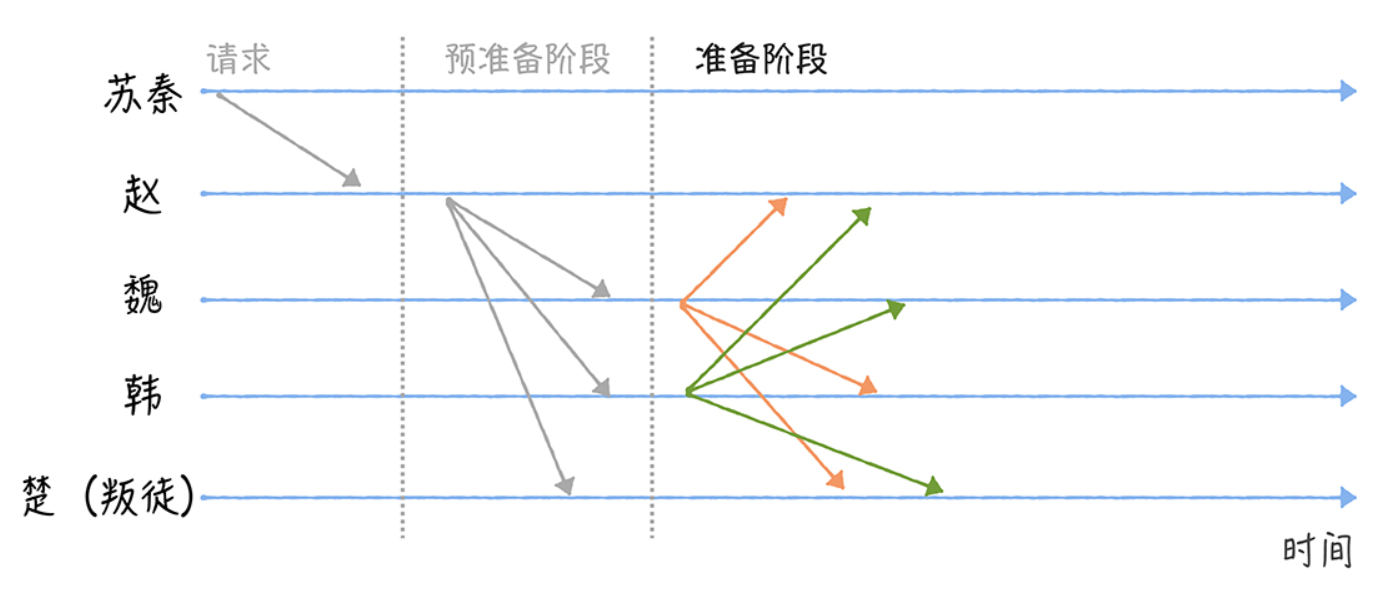
Because Wei cannot confirm whether Zhao, Han, and Chu have received 2f (where 2f includes itself, where f is the number of traitors, which in my demonstration is 1) consistent preparation messages containing combat instructions. So you need to move to the next phase, Commit.
After entering the Commit phase, each general broadcasts a commit message to the other generals, that is, to tell the other generals that I am ready to execute the order.
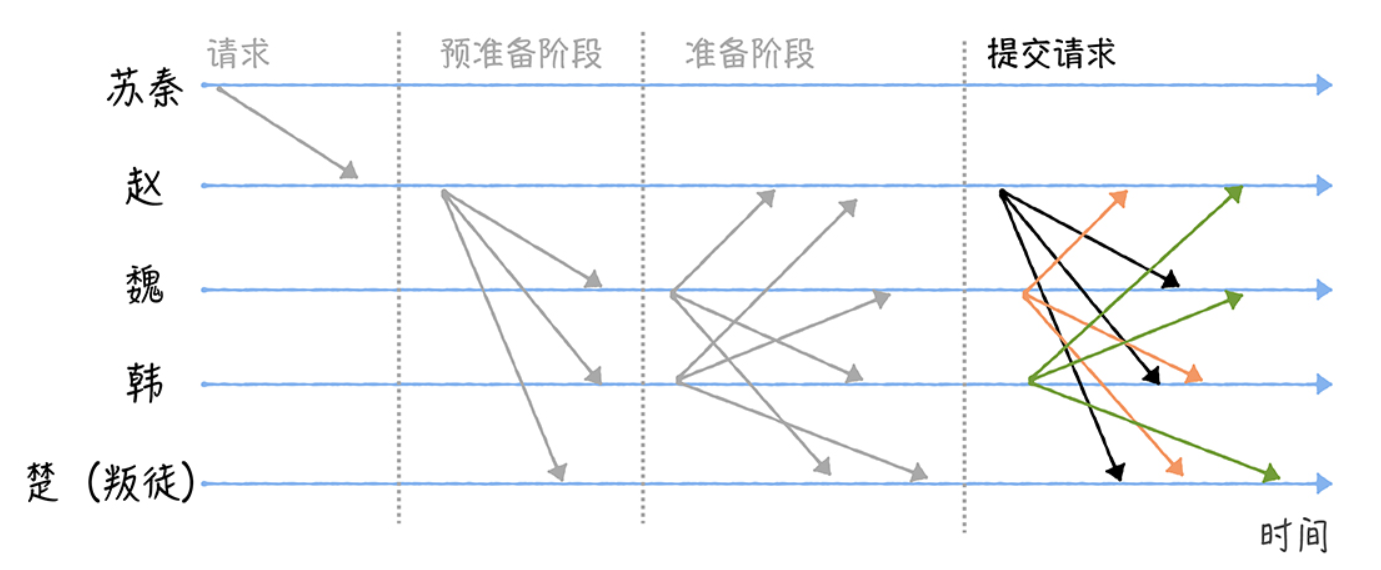
Finally, when a general receives 2f + 1 validated submission messages, the majority of the generals have reached a consensus that it is time to execute the battle order, then the general will execute Su Qin’s battle order and send a successful execution message to Su Qin when the execution is complete.
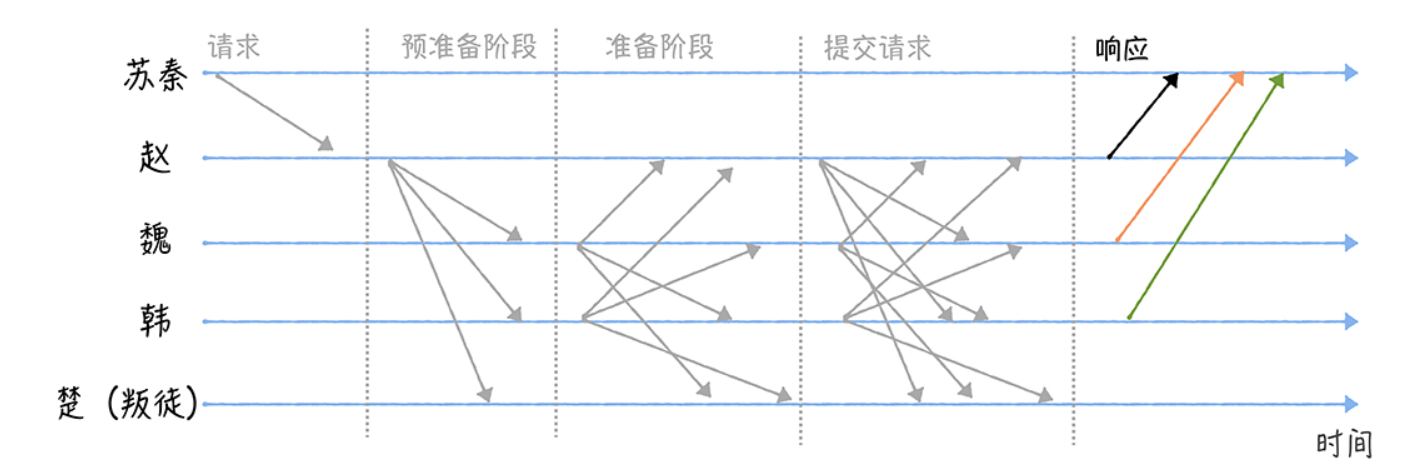
Finally, when Su Qin receives f+1 identical Reply messages, the generals have reached a consensus on the battle order and have executed it.
In the above example.
Zhao, Wei, Han, and Chu can be understood as the four nodes of the distributed system, where Zhao is the primary node and Wei, Han, and Chu are the secondary nodes.
Understanding Suqin as the business, i.e., the client.
Understanding the message as a network message.
The combat command “attack” is understood as the value proposed by the client, that is, the value that is expected to be agreed by the nodes and submitted to the state machine.
If the client does not receive the same f + 1 response to the request within the specified time, it is considered that the cluster is faulty and the consensus is not reached, and the client will resend the request.
The PBFT algorithm deals with master node misbehavior by means of View Change, and when a master node is found to be misbehaving, a new master node will be elected in a “rotating shift”. If you are interested, you can check it out yourself.
The PBFT algorithm can tolerate (n 1)/3 malicious nodes (which can also be faulty nodes) compared to the Raft algorithm, which is completely unsuitable for malicious scenarios. The PBFT algorithm is an O(n ^ 2) message complexity algorithm, so as the number of messages increases, the impact of network latency on the operation of the system will be greater, which limits the size of the distributed system running the PBFT algorithm, and determines that the PBFT algorithm is suitable for small and medium-sized distributed systems.
PoW Algorithm
Proof Of Work (PoW) is a proof that you have done a certain amount of work. Specifically, the client needs to do a certain amount of work to get a result, but the verifier can easily check if the client has done the corresponding work by the result.
The specific workload proof process looks like the one in the following figure.
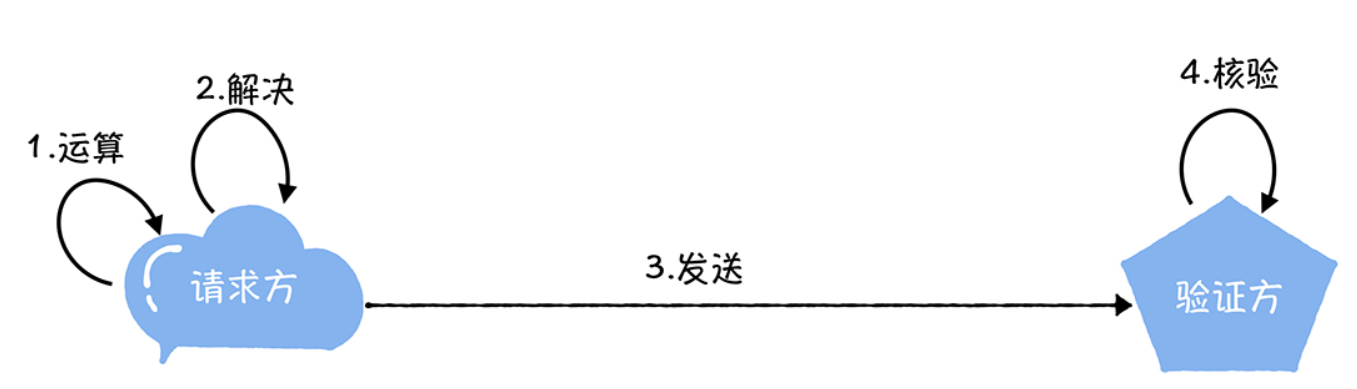
So proof of work is commonly used in blockchains, which prevent bad guys from doing bad things by increasing the cost of doing bad things through Proof of Work.
Proof of Work
Hash Function, also known as a hash function. That is, you enter a string of any length, the hash function will calculate a hash of the same length.
After understanding what a hash function is, how can we prove the workload by hashing the hash function?
For example, we can give a workload requirement: based on a basic string, you can add an integer value to this string, and then perform a SHA256 hash operation on the changed (added integer value) string, and if the hash value (in hexadecimal form) obtained after the operation starts with “0000”, then the verification passes.
To achieve this workload proof goal, we need to keep incrementing the integer values, one by one, and perform a SHA256 hash on the new string.
As you can see from this example, the proof of workload is done by performing a hash operation, and after a period of computation, a hash value is obtained that meets the conditions. In other words, we can prove our workload by this hash value.
How does the blockchain implement the PoW algorithm?
First look at what a blockchain is.
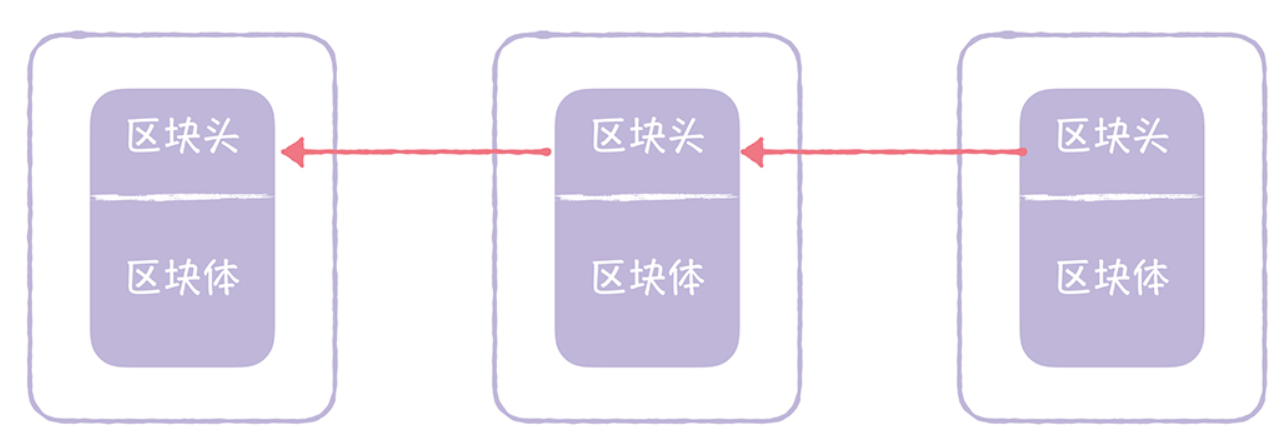
A blockchain block is composed of 2 parts: block head and block body.
- Block Head: The block head is mainly composed of the hash of the previous block, the hash of the block body, and a 4-byte random number (nonce).
- Block Body: The block contains the transaction data, the first of which is the Coinbase transaction, a special transaction that motivates miners.
In the blockchain, the block header with a fixed length of 80 bytes is the input string of the hash operation used for the proof of workload of the blockchain, and the hash value calculated by the double SHA256 hash operation (that is, the result of the SHA256 hash operation is executed once more) is valid only if it is less than the target value, otherwise the hash value is invalid and must be recalculated.
Therefore, in the blockchain is to prove its workload by performing SHA256 hash operation on the block header to get a hash value less than the target value.
After calculating the qualified hash value, the miner will broadcast this information to all other nodes in the cluster, and after the other nodes pass the verification, they will add the block to their blockchain, which eventually forms a chain of blocks, like the following figure.
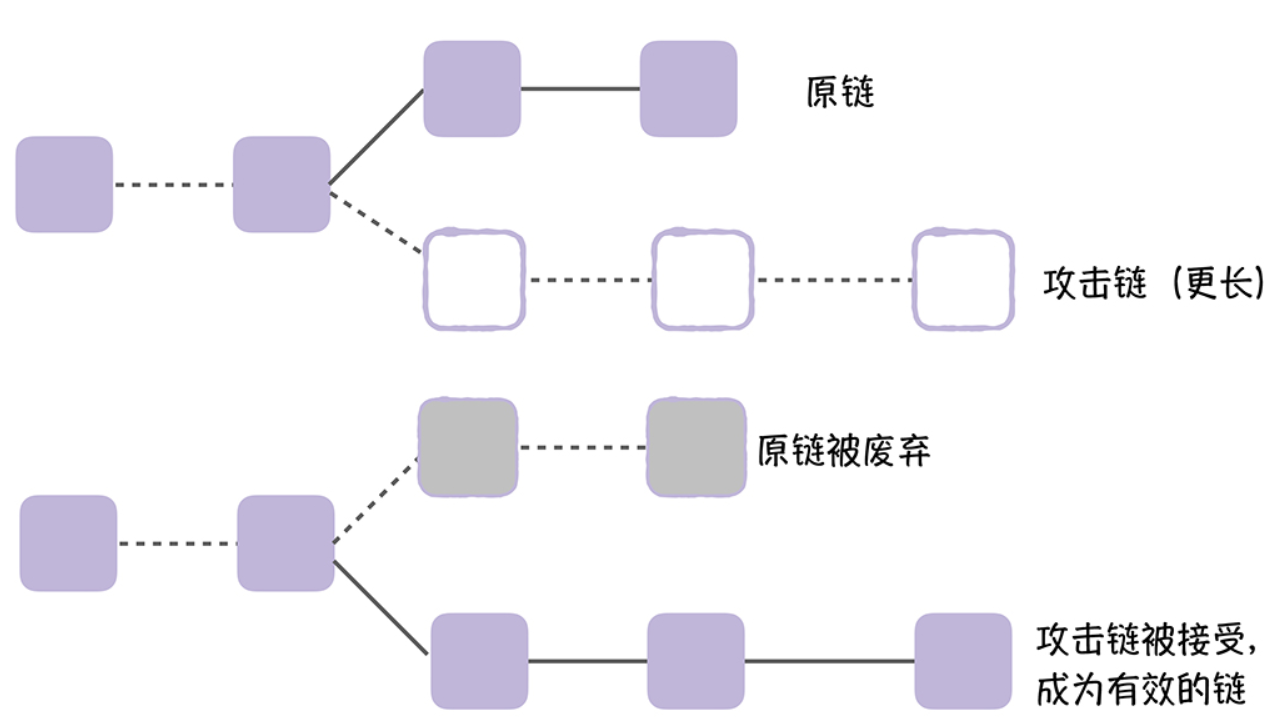
So, it means that the attacker has more computing power and can mine a longer attack chain than the original chain and broadcast the attack chain to the whole network, then, according to the agreement, the node will accept the longer chain, that is, the attack chain, and discard the original chain. It looks like the following figure.
ZAB Protocol
The Zab protocol is called Zookeeper Atomic Broadcast, and Zookeeper is used to ensure the ultimate consistency of distributed transactions through the Zab protocol, which is designed with the core goal of achieving sequential operations.
Since ZAB is not based on a state machine, but on the Atomic Broadcast protocol in a master-standby mode, it ultimately achieves sequential operations.
There are several main reasons why ZAB achieves sequential operations.
First, ZAB implements the master-standby mode, which means that all data is based on the master node
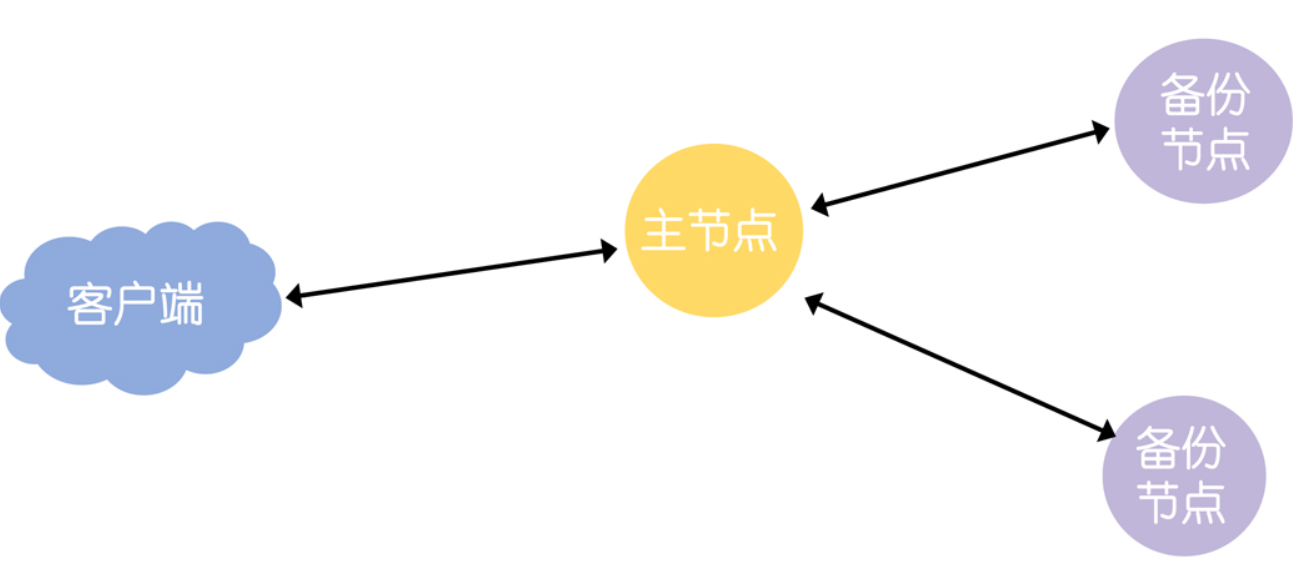
Second, ZAB implements a FIFO queue to ensure sequential message processing.
Finally, ZAB also implements that when the master node crashes, only the node with the most complete logs can be elected as the master node, because the most complete node contains all the logs that have been committed, so that the committed logs will not change again.