1. What is Http Client
The Http protocol, a common language across the Internet, and the Http Client, arguably the most basic method we need to get data from the Internet world, is essentially a URL to a webpage conversion process. And with the basic Http Client functionality, paired with the rules and policies we want, everything from content retrieval down to data analysis can be implemented.
Today we’re giving you a high-performance Http client in C++, and it’s easy!
|
|
Once Workflow is installed, the above code can be compiled into a simple http_client with the following command.
|
|
According to the Http protocol, we execute this executable . /http_client , and we get the following.
|
|
Similarly, we can also get other Http header and Http body returned through other api’s, everything is in this WFHttpTask. And because Workflow is an asynchronous scheduling framework, this task will not block the current thread after it is issued, plus it comes with internal connection reuse, which fundamentally ensures the high performance of our Http Client.
The next step is to give you a detailed explanation of the principle ~
2. The process of requesting
1. Creating an Http Task
As can be seen in the above demo, the request is implemented by initiating a Workflow Http asynchronous task with the following interface for creating the task.
The first parameter is the URL that we want to request. Correspondingly, in the example at the beginning, our number of redirects redirect_max is 2 and the number of retries retry_max is 3. The fourth argument is a callback function, which we use in the example as a lambda. Since Workflow tasks are all asynchronous, we are passively notified about the matter of processing the results, and the callback function is called up when the results come back, in the following format.
|
|
2. fill in the header and send
Our network interaction is nothing but Request-Reply, which corresponds to Http Client. After we have created the task, we have some time to deal with the Request, which in the Http protocol is to fill in the header with protocol related things, for example we can specify via Connection that we want to get to establish Http’s Long Connection to save the time consuming next connection establishment, then we can set Connection to Keep-Alive. The example is as follows.
Finally we will send the task with the request set up, via task->start();. The reason there is a getchar(); statement in the http_client.cc example at the beginning is because our asynchronous task is non-blocking when it is issued, the current thread will exit without stopping temporarily, and we want to wait until the callback function comes back, so we can use a variety of pauses.
3. Handling return results
A return result, according to the Http protocol, will contain three parts: message line, message header, message body. If we want to get the body, we can do this.
3. Basic guarantees of high performance
We use C++ to write Http Client, and the most fragrant thing is that we can take advantage of its high performance. How does Workflow guarantee high concurrency? Two things, really.
- pure asynchrony.
- Connection reuse.
The former is the reuse of threaded resources, the latter is the reuse of connected resources, all of which are managed for the user at the framework level, fully reducing the developer’s mental burden.
1. Asynchronous scheduling model
The synchronous and asynchronous modes directly determine how concurrent our Http Client can be. Why? A first look at what the thread model looks like for a synchronous framework launching three Http tasks can be found in the following diagram.
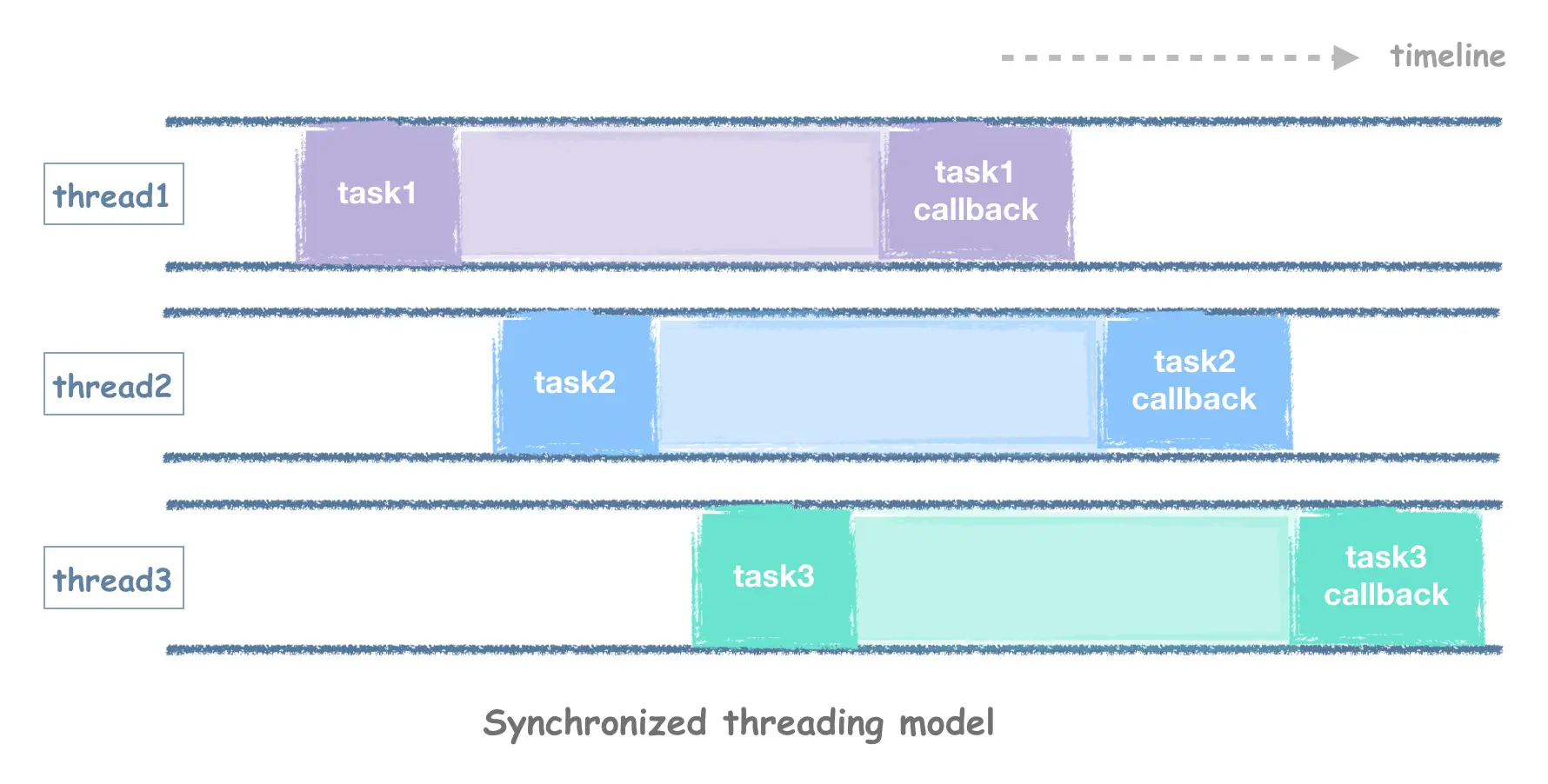
Network latency is often very high and if we are waiting for a task to come back synchronously, the thread will be occupied all the time. This is when we need to see how the asynchronous framework is implemented.
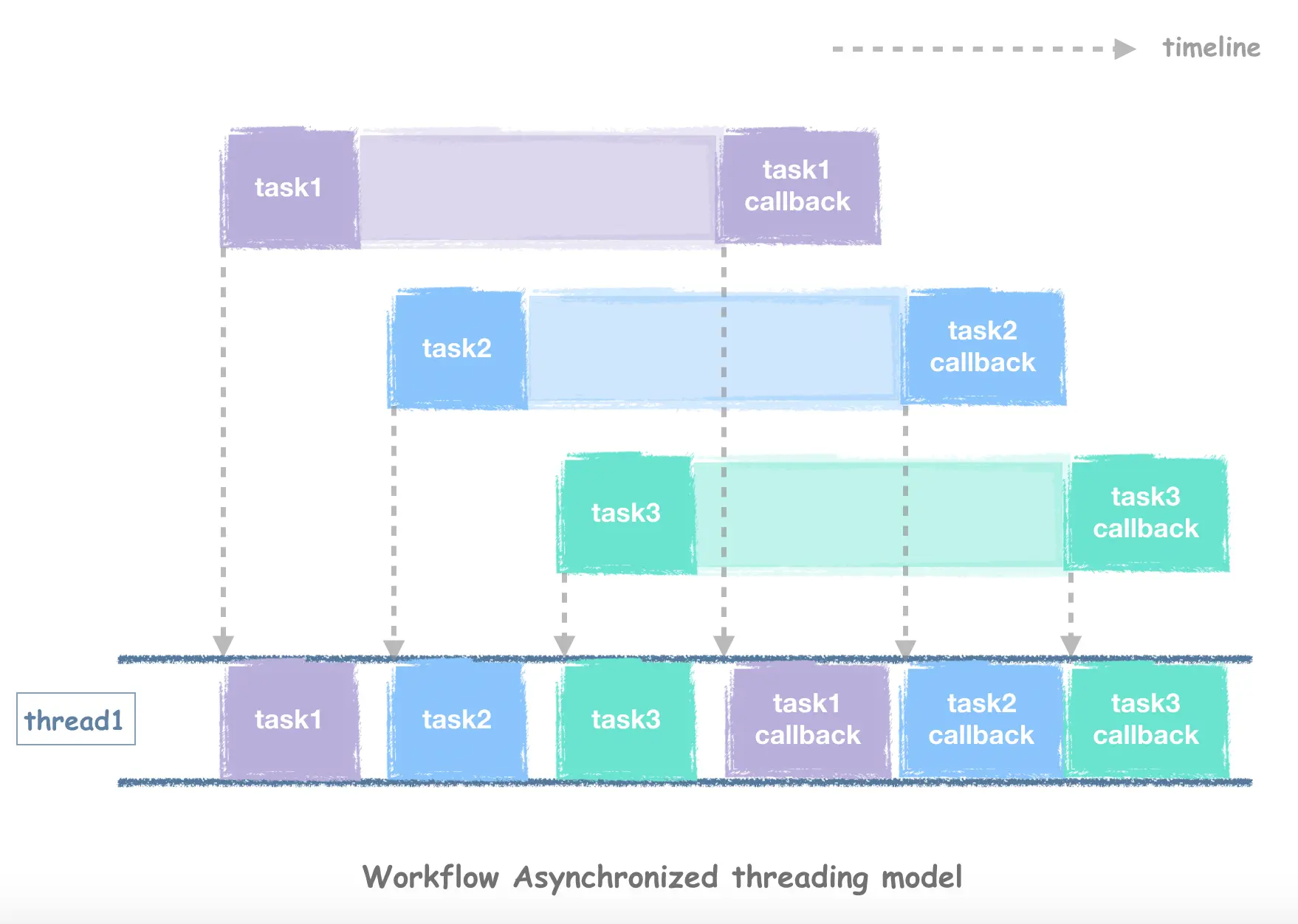
As shown in the diagram, as soon as the task is sent out, the thread can do other things, we pass in a callback function to do asynchronous notification, so after the task’s network reply is received, and then let the thread execute this callback function to get the results of the Http request, during multiple tasks concurrently out, the thread can be reused, easily reach hundreds of thousands of QPS concurrency degree.
2. Connection Reuse
As we mentioned earlier, as long as we have established long connections, we can increase efficiency. Why? Because the framework has multiplexing of connections. Let’s look at what it would look like if a single request created a single connection.
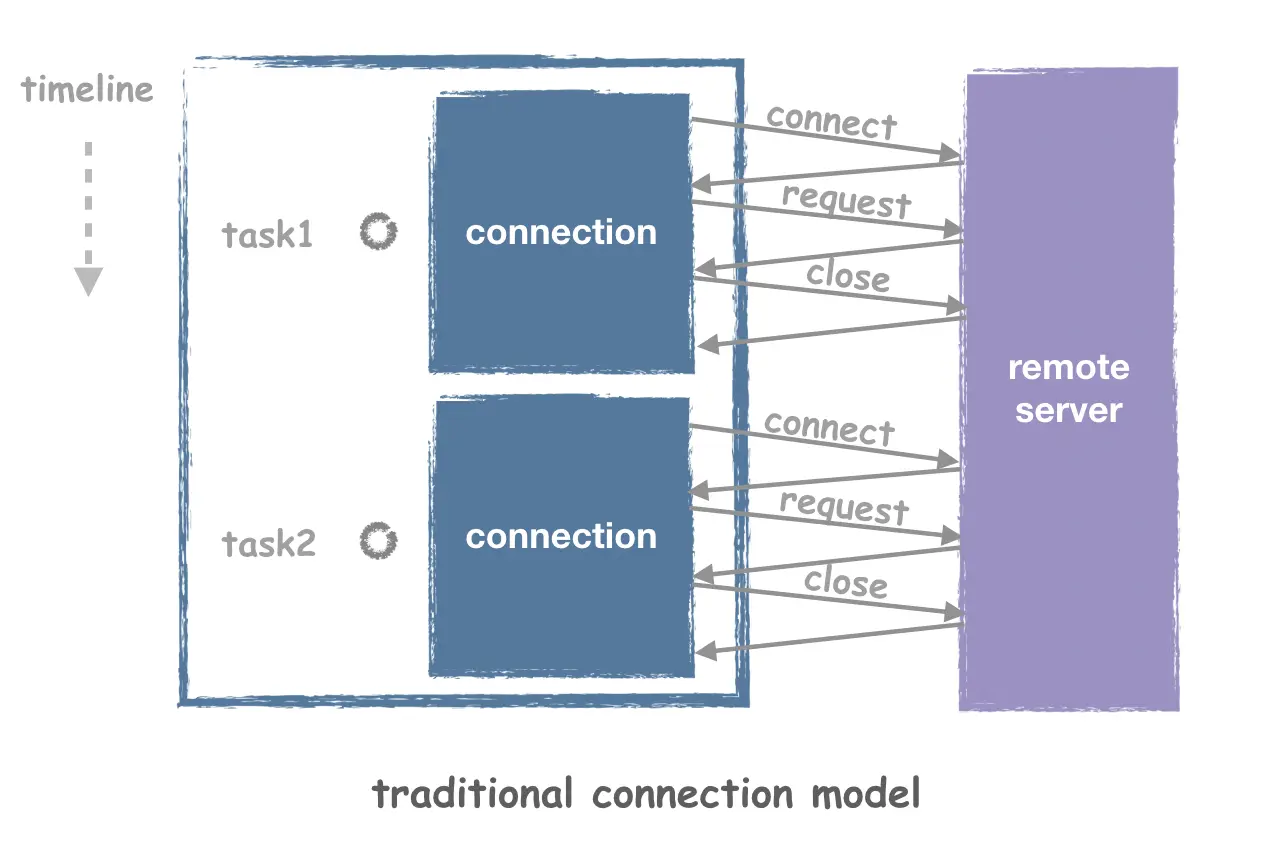
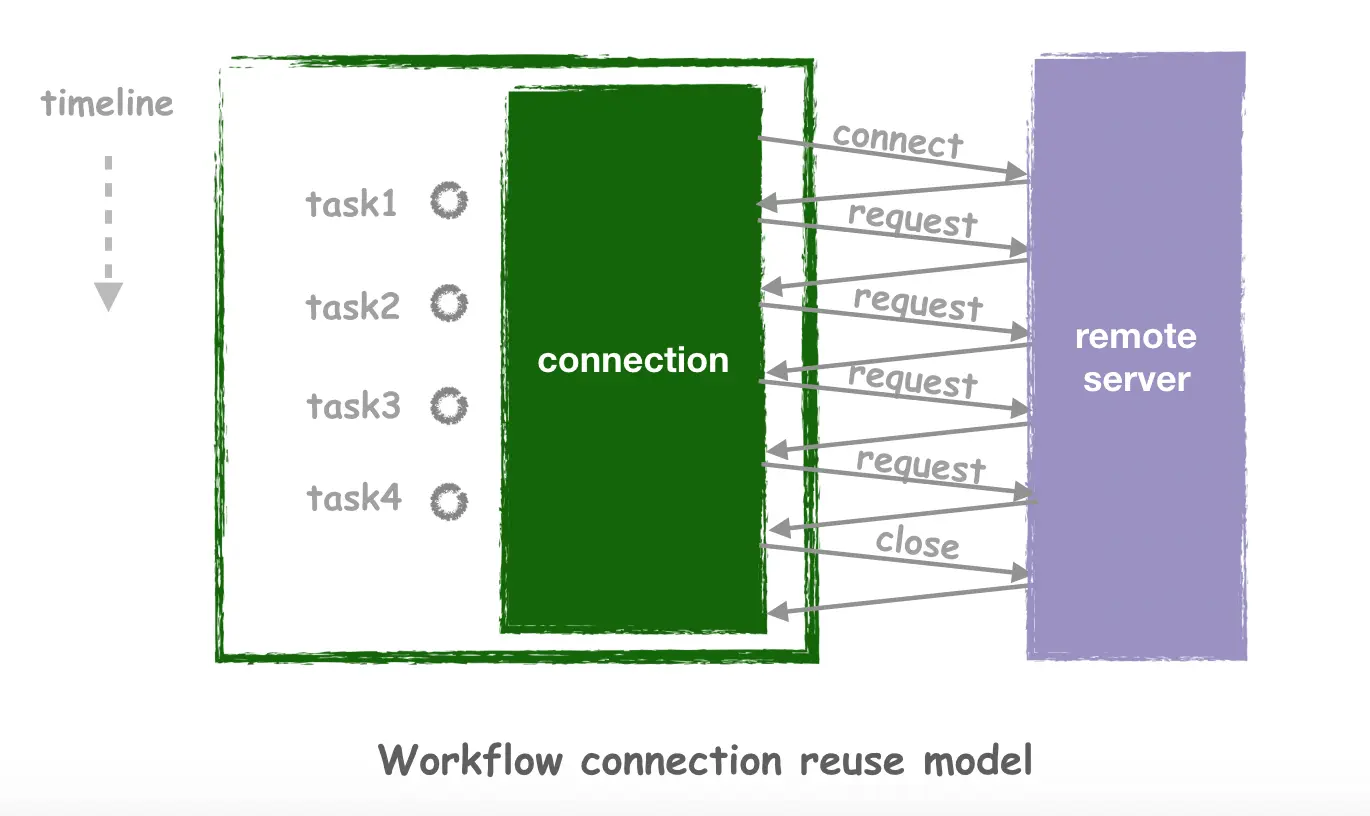
Obviously, taking up a lot of connections is a waste of system resources, and having to do connect and close every time is very time consuming, and the process of establishing connections can be relatively complex for many application layer protocols, in addition to the common TCP handshake. With Workflow there is no need to worry about this, as Workflow will automatically look for currently reusable connections when the task is issued, and only create them if they are not available, without requiring the developer to care about the details of how the connections are reused.
3. Unlock other features
Of course, in addition to the above high performance, a high performance Http Client often has many other requirements, which can be shared here in conjunction with.
- superscale parallel crawling in combination with workflow’s serial and parallel task flow
- Sequential or requesting content from a site at a specified rate to avoid being blocked for over-requesting.
- Http Client can automatically do the jump for me when I encounter redirect to request the final result in one step.
- want to access
HTTPandHTTPSresources through proxy proxy.
These requirements require the framework to be super flexible for orchestrating Http tasks, as well as having very grounded support for practical requirements (such as redirect, ssl proxy and other features), which Workflow has implemented.