1. Background
In existing network environments, some businesses using Redis clusters often need to expand their node capacity as business volume increases.
I have previously learnt that some of my operations and maintenance colleagues have experienced a decrease in performance after scaling a Redis cluster with a relatively large number of nodes, as evidenced by a significant increase in access latency.
Some businesses are sensitive to Redis cluster access latency, such as the existing network environment for real-time model reads, or some businesses rely on the synchronisation process of reading Redis clusters, which can affect the real-time process latency of the business. This may not be acceptable on the business side.
To find the root cause of this problem, we troubleshoot the cluster performance degradation after a particular Redis cluster migration operation.
1.1 Problem Description
The scenario for this specific Redis cluster issue is that a particular Redis cluster has undergone a scaling operation. The business side uses Hiredis-vip for Redis cluster access and performs MGET operations.
The business side perceives that the latency to access the Redis cluster becomes high.
1.2 Description of the current network environment
- Most of the Redis versions deployed in the current network environment are 3.x or 4.x versions;
- The business is using the client Hiredis-vip to access the Redis cluster;
- The Redis cluster has a relatively large number of nodes, 100+ in size;
- The cluster has been previously expanded.
1.3 Observing the phenomenon
Because the latency becomes high, we troubleshoot in several ways.
- whether the bandwidth is fully occupied.
- whether the CPU is over-occupied.
- whether the OPS is high.
By simple monitoring and troubleshooting, the bandwidth load is not high. However, the CPU was found to be behaving abnormally.
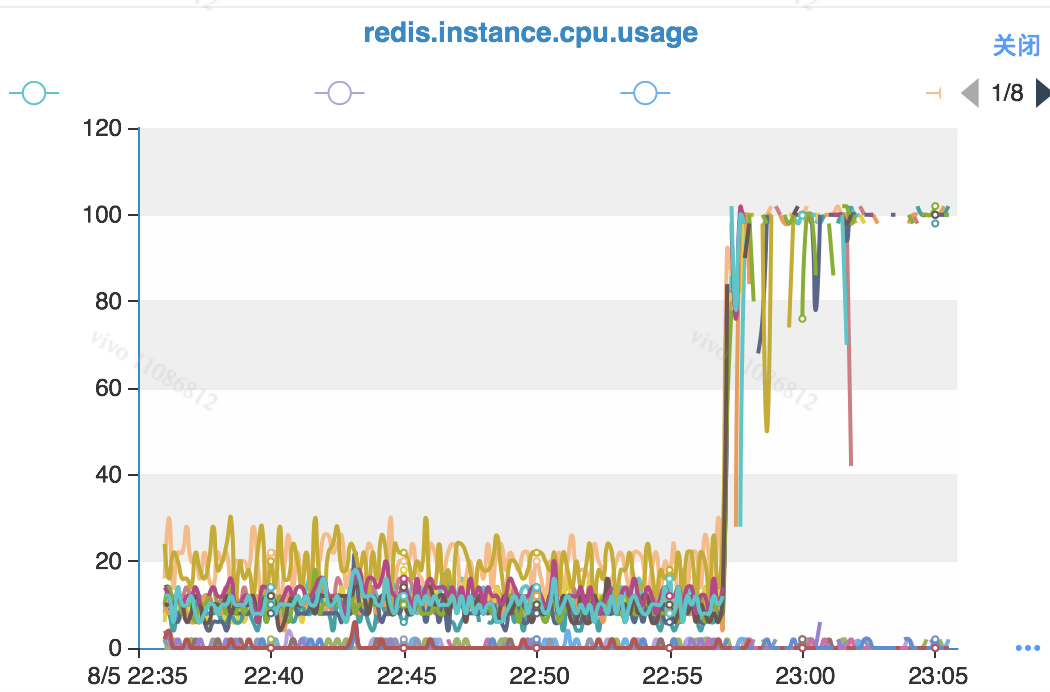
1.3.1 Comparing OPS and CPU load
Looking at the MGET and CPU load used by the business feedback, we found the corresponding monitoring curves.
Analyzed in terms of time, there is no direct correlation between high MGET and CPU load. The feedback from the business side was a general increase in latency for MGET. Here we see that the OPS and CPU load of MGET are staggered.
Here it can be tentatively determined that there is no direct relationship between business requests and CPU load for the time being, but it can be seen from the curves: there is a staggering of business requests and CPU load on the same timeline, and there should be an indirect relationship between the two.
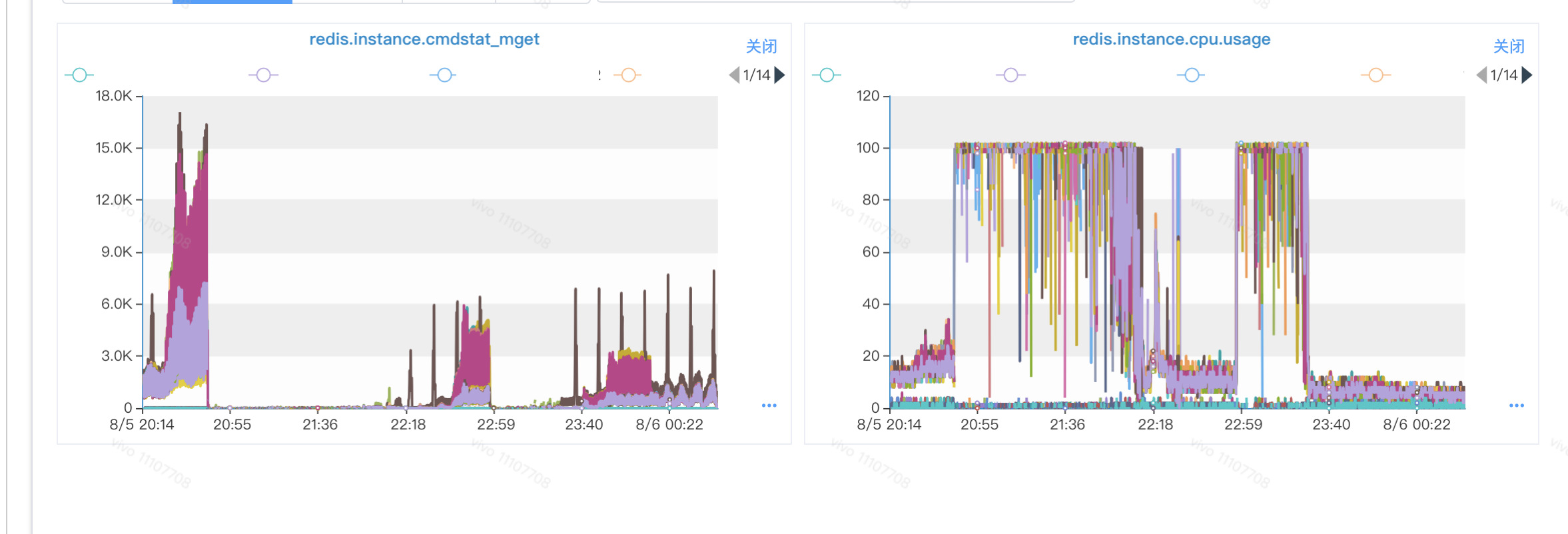
1.3.2 Comparing Cluster command OPS and CPU load
As a colleague on the operations side has previously had feedback that the cluster has undergone expansion operations, there is bound to be a migration of slots.
Considering that business clients generally use caches to store slot topology information for Redis clusters, it was suspected that there was some connection between the Cluster directive and CPU load.
We found that there was indeed some connection.
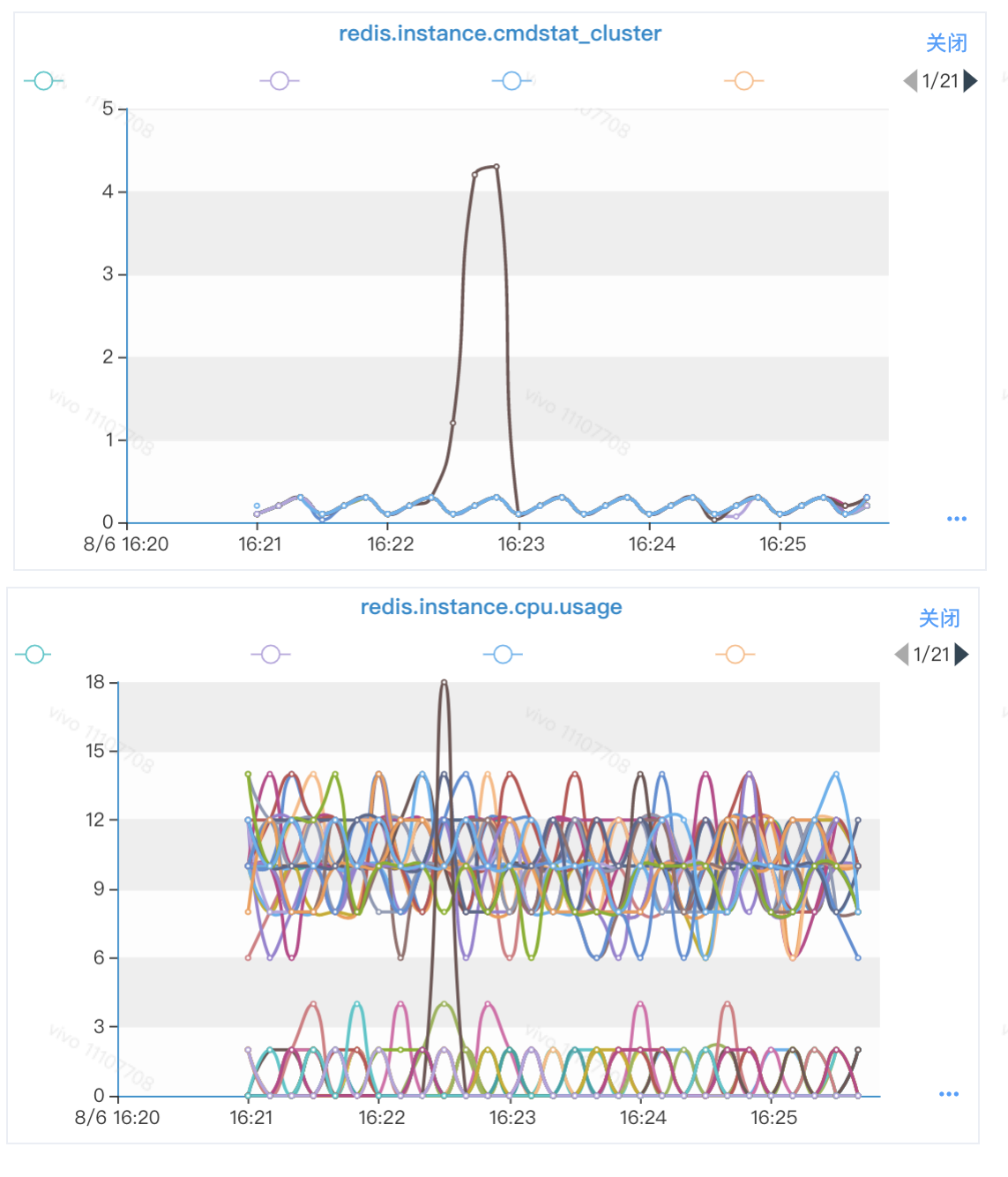
Here it is obvious: the CPU usage of a certain instance rises significantly when executing Cluster instructions.
Based on the above phenomena, a simple focus can be roughly made on.
- MGET execution on the business side, where the Cluster instruction is executed for some reason.
- Cluster instructions that for some reason cause high CPU usage affecting other operations.
- Cluster instructions are suspected to be a performance bottleneck.
Also, to elicit a few issues of concern.
Why are there more Cluster instructions being executed?
Why are CPU resources higher when Cluster instructions are executed?
Why are clusters with large node sizes prone to “hitting” the migration slots?
Why is it easy to “get caught” in a cluster migration slot operation with large node sizes?
2. Troubleshooting
2.1 Redis hotspot troubleshooting
We performed a simple analysis using perf top on a Redis instance that appeared to have a high CPU load on site.

As you can see from the above diagram, the function (ClusterReplyMultiBulkSlots) takes up 51.84% of the CPU resources, which is an exception.
2.1.1 ClusterReplyMultiBulkSlots implementation principle
We analyse the clusterReplyMultiBulkSlots function.
|
|
Each node (ClusterNode) uses a bitmap (char slots[CLUSTER_SLOTS/8]) to store information about the allocation of slots.
A brief description of the logic of BitmapTestBit: clusterNode->slots is an array of length CLUSTER_SLOTS/8. CLUSTER_SLOTS is a fixed value of 16384. each bit of the array represents a slot. the subscript of the bitmap array here is 0 to 2047, and the range of slots is 0 to 16383. The range of slots is 0 to 16383.
Since it is important to determine whether the bit at the pos position is a 1, therefore.
- off_t byte = pos/8: gets the information on which byte (Byte) on the bitmap corresponds to this pos position. Since there are 8 bits in a Byte, using pos/8 gives a guide as to which Byte to look for. Here the bitmap is treated as an array, and here it corresponds to the Byte with the corresponding subscript.
- int bit = pos&7: Get the information about which bit corresponds to the pos position on this byte. You can imagine grouping pos in groups of 8, and the last group (not satisfying 8) corresponds to the subscript position of the bit array on the corresponding byte of the bitmap.
- (bitmap[byte] & (1«bit)): determine whether the corresponding bit exists on the bitmap[byte].
Example with a slot of 10001.
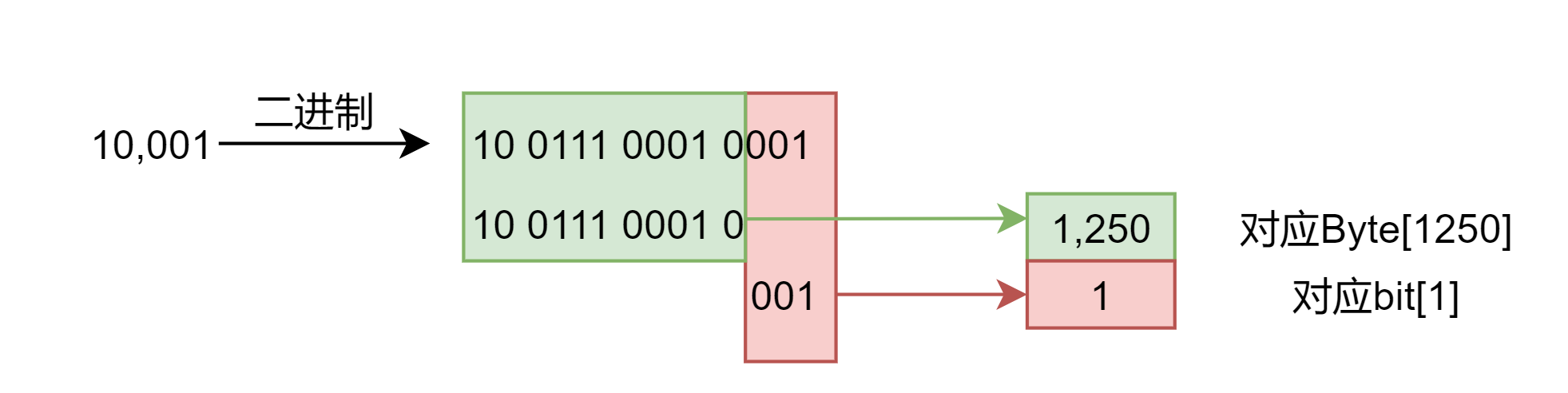
Therefore the slot 10001 corresponds to the byte with subscript 1250, and the bit to be checked is the subscript 1.
The corresponding position on the ClusterNode->slots.

The green square shows bitmap[1250], which is the byte that holds slot 10001; the red box (bit[1]) corresponds to the location 1«bit. bitmap[byte] & (1«bit), which is to confirm whether the location corresponding to the red box is 1. If so, it means that 10001 on the bitmap has been If so, the bitmap is marked with 10001.
The summary logic of ClusterNodeGetSlotBit is: Determine if the current slot is allocated on the current node . So the approximate logic of ClusterReplyMultiBulkSlots is as follows.
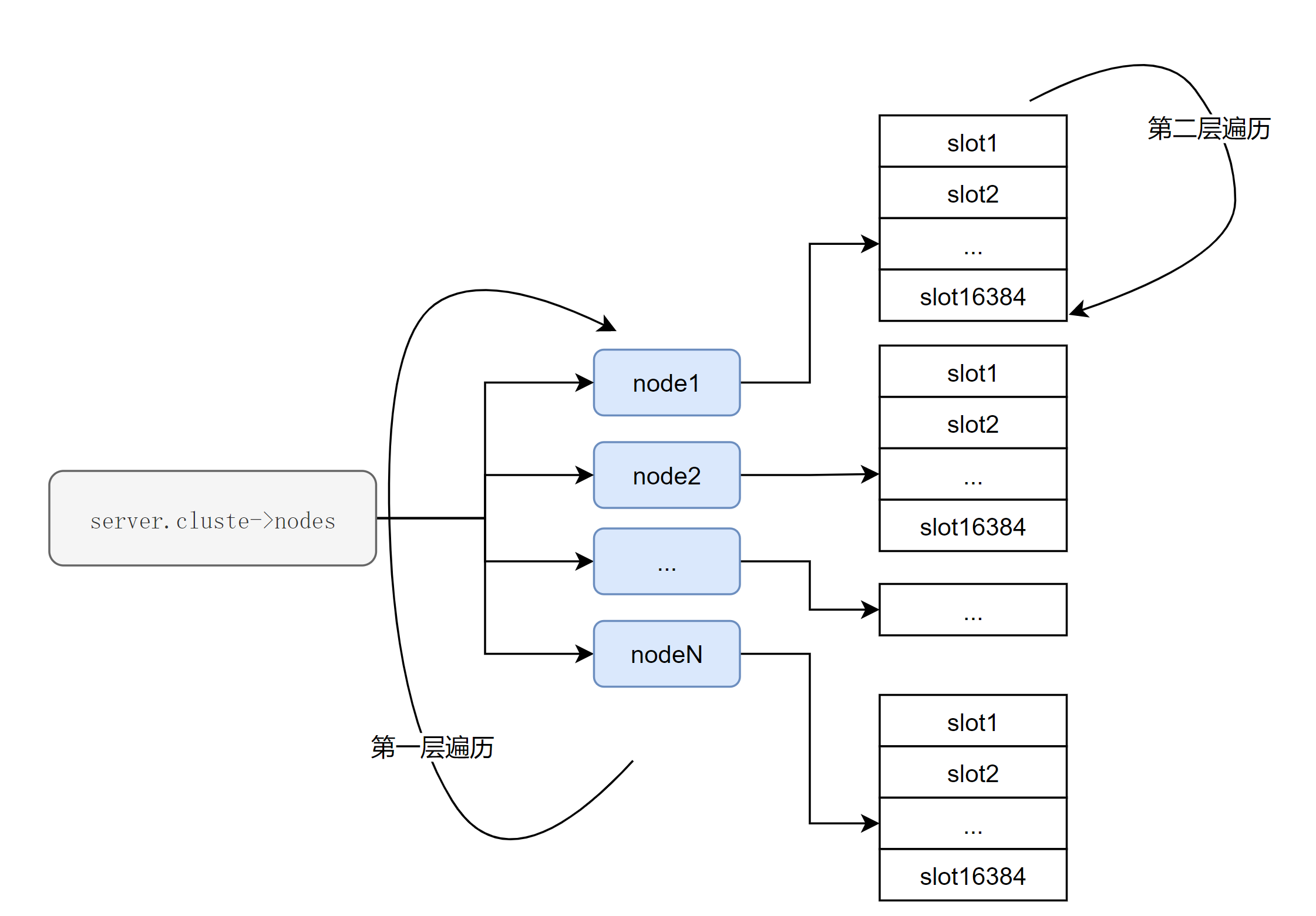
The approximate steps are as follows.
- Iterate over each node.
- For each node, traverse all slots and use ClusterNodeGetSlotBit to determine if the slots in the traversal are assigned to the current node.
From the result of the GetCLUSTER SLOTS command, we can see that the complexity is <number of cluster master nodes> * <total number of slots>. Where the total number of slots is 16384, a fixed value.
2.1.2 Redis hotspot troubleshooting summary
As far as we can see, the CLUSTER SLOTS instruction latency grows linearly with the number of master nodes in the Redis cluster. The larger number of master nodes in the cluster we are investigating explains the larger latency of the CLUSTER SLOTS command in the current network.
2.2 Client troubleshooting
We understand that the operation and maintenance students have expansion operations, and after the expansion is completed, some keys are bound to have MOVED errors when they are accessed.
The current use of Hiredis-vip client code for a simple browse, a brief analysis of the following current business use of Hiredis-vip client in the encounter MOVED when how to deal with. As most other businesses commonly use the Jedis client, this is also a brief analysis of the corresponding process for the Jedis client.
2.2.1 Principles of Hiredis-vip implementation for MOVED processing
Hiredis-vip operation for MOVED.
To see the process of calling Cluster_update_route.
Here the cluster_update_route_by_addr performs a CLUSTER SLOT operation. As can be seen, when a MOVED error is fetched, Hiredis-vip re-updates the Redis cluster topology with the following characteristics.
- Because the nodes are hashed the same way through ip:port as the key, multiple clients can easily access the same node at the same time if the cluster topology is similar.
- If a node fails to access, it goes through an iterator to find the next node, and for the above reasons, multiple clients can easily access to the next node at the same time.
2.2.2 Principles of Jedis implementation of MOVED processing
A brief glance at the Jedis client code shows that renewSlotCache is called if there is a MOVED error.
Continuing to look at the renewSlotCache call, we can confirm that Jedis sends the Redis command CLUSTER SLOTS when it encounters a MOVED error in cluster mode, which pulls the Redis cluster’s slot topology again.
2.2.3 Summary of client implementation principles
As Jedis is a Redis client for Java and Hiredis-vip is a Redis client for C++, it can be simply assumed that this exception handling mechanism is a common operation.
The process for sorting out MOVED in client-side cluster mode is roughly as follows.
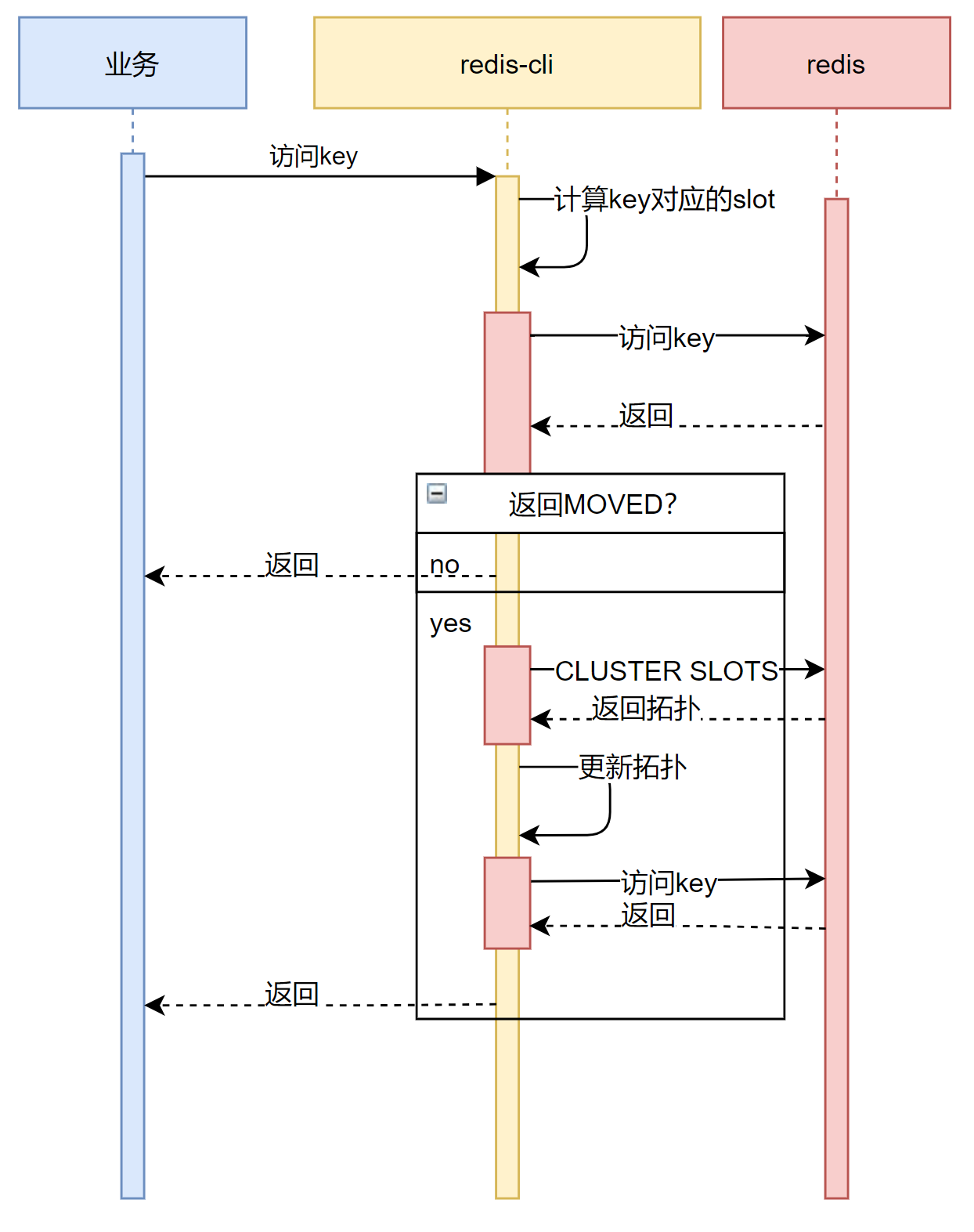
In summary.
-
access to the key using the client-side cached slot topology.
-
Redis node returns normal.
- Access is normal, continue with subsequent operations
-
Redis node returns MOVED.
- Execute the CLUSTER SLOTS command on the Redis node to update the topology.
- Re-access to the key using the new topology.
2.2.3 Client troubleshooting summary
The Redis cluster is expanding, which means that there are bound to be some Redis clients that are accessing the Redis cluster and encountering MOVED, executing the Redis command CLUSTER SLOTS for topology updates.
If the migrated key has a high hit rate, the CLUSTER SLOTS command will be executed more frequently. This results in the Redis cluster being continuously executed by the client during the migration process with the CLUSTER SLOTS command.
2.3 Summary of troubleshooting
2.3 Summary of troubleshooting
Here, combined with the Redis-side CLUSTER SLOTS mechanism and the client-side processing logic for MOVED, several questions can be answered.
Why are there more Cluster instructions being executed?
Because a migration operation has occurred, the business accessing some of the migrated keys will get a MOVED return, and the client will pull the slot topology information again for that return and perform CLUSTER SLOTS.
Why are CPU resources higher when Cluster instructions are executed?
Analyzing the Redis source code, I found that the time complexity of the CLUSTER SLOT instruction is proportional to the number of master nodes. The business’s current Redis cluster has a high number of master nodes, so it naturally takes a lot of time and CPU resources.
Why is it easy to “hit” a cluster with a large node size to migrate a slot operation?
- Migration operations inevitably bring about the return of MOVED for some client access to the key.
- clients execute the CLUSTER SLOTS command for the return of MOVED.
- the CLUSTER SLOTS instruction increases in latency as the number of cluster master nodes increases.
- Business accesses rise during migration of slots due to CLUSTER SLOTS latency, which is perceived externally as elevated latency in executing instructions.
3. Optimization
3.1 Current Situation Analysis
According to the current situation, it is a normal process for a client to encounter MOVED for CLUSTER SLOTS execution, as the cluster’s slot topology needs to be updated to improve the efficiency of subsequent cluster accesses.
In addition to Jedis and Hiredis-vip, other clients should also perform similar sloot information caching optimizations. There is not much room for optimization of this process, as the cluster access mechanism of Redis dictates.
The cluster information logging for Redis is therefore analysed.
3.1.1 Redis cluster metadata analysis
Each Redis node in the cluster has some cluster metadata records, recorded in server.cluster, which are as follows.
As described in 2.1, the original logic obtained the topology by traversing the slot information of each node.
3.1.2 Redis cluster metadata analysis
Observe the results returned by CLUSTER SLOTS.
In combination with the cluster information stored in server.cluster, I think that here we can use server.cluster->slots for traversal. This is because server.cluster->slots already gets updated at every cluster topology change, saving the node pointers.
3.2 Optimisation options
A simple optimisation idea is as follows.
- Iterate over the slots to find blocks where the nodes in the slots are contiguous.
- If the node of the currently traversed slot is the same as the previously traversed node, then the currently accessed slot is under the same node as the previous one, i.e. it is in a “contiguous” slot region under a node.
- If the node of the currently traversed slot does not match the previously traversed node, the currently accessed slot is different from the previous one, and the previous “continuous” slot region can be exported; the current slot is used as the start of the next new “continuous” slot region.
Therefore, it is sufficient to iterate over server.cluster->slots to satisfy the requirement. A simple representation would look like this.
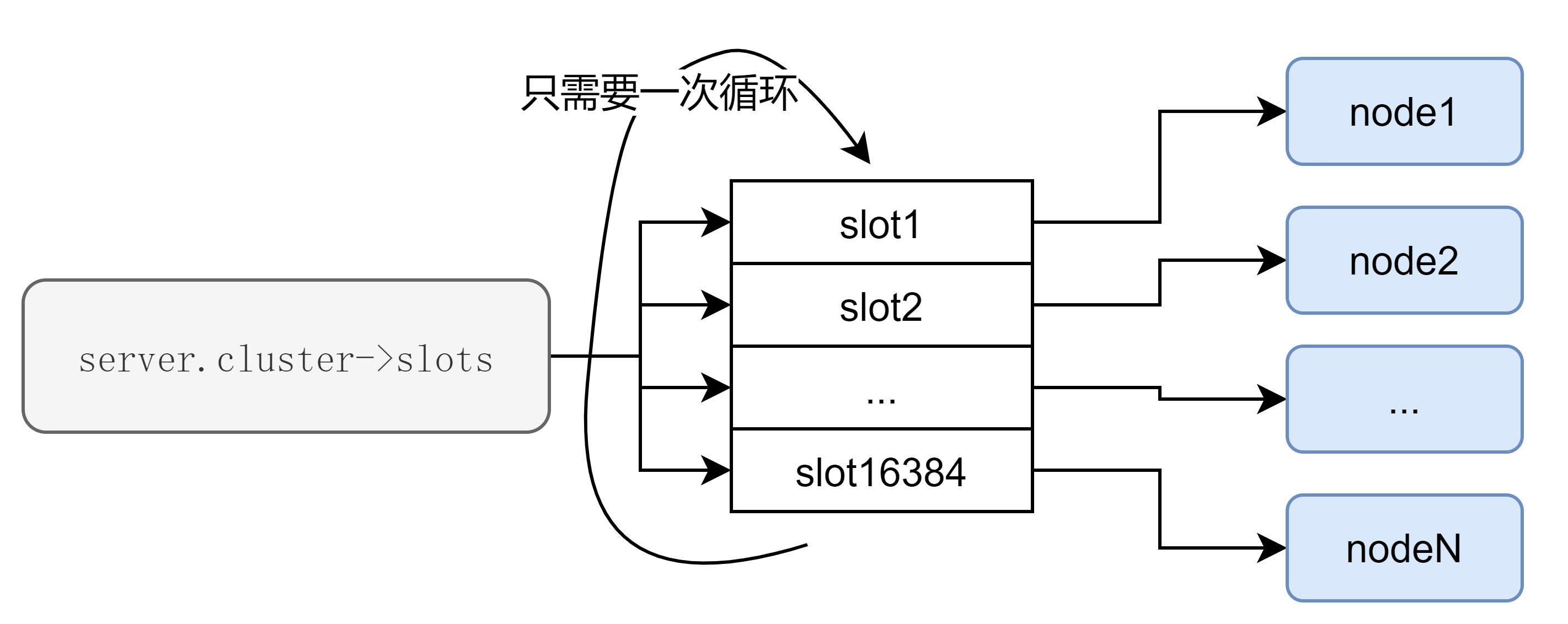
This reduces the time complexity to <total number of slots>.
3.3 Implementation
The optimisation logic is as follows.
|
|
By traversing server.cluster->slots, a “contiguous” slot region under a node is found, and once it is subsequently discontiguous, the node information of the previous “contiguous” slot region and its backup nodes are output, and then the next “contiguous” slot region is found and output. If the slots are not consecutive, the node information of the previous “consecutive” slot region and its backup nodes are output, and then the next “consecutive” slot region is found and output.
Comparison of Optimisation Results
A side-by-side comparison of the CLUSTER SLOTS command between the two versions of Redis.
4.1 Test Environment & Pressure Test Scenarios
Operating system: manjaro 20.2
Hardware configuration:
- CPU: AMD Ryzen 7 4800H
- DRAM: DDR4 3200MHz 8G*2
Redis Cluster Information:
-
Persistence Configuration
- Turn off aof
- Turn off bgsave
-
Cluster node information.
- Number of nodes: 100
- All nodes are master nodes
Pressure testing scenarios:
- Using the benchmark tool to send CLUSTER SLOTS commands continuously to individual nodes of the cluster.
- After pressure testing one of the versions, recycle the cluster, redeploy it and then proceed to the next round of pressure testing.
4.2 CPU resource usage comparison
perf exported flame chart. Original version.

Optimised for.

It is clear to see that the optimised share has dropped significantly. This is largely as expected.
4.3 Time consumption comparison
Tests were carried out on, with embedded time consuming test code on.
Input logs for comparison.
Original log output:
37351:M 06 Mar 2021 16:11:39.313 * cluster slots cost time:2061 us.
Optimized version log output:
35562:M 06 Mar 2021 16:11:27.862 * cluster slots cost time:168 us.
This is a significant drop in time consumption: from 2000+us to 200-us; the time consumption in a cluster of 100 master nodes is reduced to 8.2% of the original; the optimization results are basically as expected.
5. Summary
Here it is possible to briefly describe the above actions of the article leading to such a conclusion: a performance defect.
To briefly summarize the above troubleshooting and optimization process.
- A large Redis cluster was experiencing significant access latency on some nodes due to the CLUSTER command.
- Using the perf top command to troubleshoot Redis instances, the clusterReplyMultiBulkSlots command was found to be using an unusual amount of CPU resources.
- Analysis of clusterReplyMultiBulkSlots revealed significant performance issues with this function.
- Optimization of clusterReplyMultiBulkSlots resulted in significant performance improvements.
From the above troubleshooting and optimization process, it can be concluded that the current Redis has a performance flaw in the CLUSTER SLOT instruction.
Because of Redis’ data slicing mechanism, the key access method in Redis cluster mode is to cache the topology of the slots. The only place to start is with CLUSTER SLOTS. The number of nodes in a Redis cluster is generally not as large, and the problem is not as obvious.
In fact, the logic of Hiredis-vip is also somewhat problematic. As mentioned in 2.2.1, Hiredis-vip’s method of updating the slot topology is to traverse all the nodes one by one to perform CLUSTER SLOTS, which can have a knock-on effect if the Redis cluster is large and the business-side clients are large.
-
if the Redis cluster is large, the CLUSTER SLOTS response is slower.
-
if a node does not respond or returns an error, the Hiredis-vip client will continue the request to the next node.
-
the same method of iterative traversal of the Redis cluster nodes in the Hiredis-vip client (since the information about the cluster is essentially the same across clients), when the client size is large, there may be blocking on a Redis node, which will cause the hiredis-vip client to traverse the next Redis node.
-
A large number of Hiredis-vip clients accessing a number of Redis nodes one by one, which can lead to Redis nodes being requested one by one under the “traversal” of a large number of Hiredis-vip clients if the Redis nodes cannot cope with such requests.
In conjunction with point 3 above, imagine that there are 1w clients accessing the Redis cluster. Because there is a migration operation for a key with a high hit rate, all the clients need to update the slot topology. Since all clients have the same cluster node information cached, the order of traversal is the same across all nodes. Redis nodes are accessed by most of the clients (e.g. 9k+ clients) in order of traversal. Executing the CLUSTER SLOTS command causes Redis nodes to block one by one.
- The end result is that the CPU load on most Redis nodes skyrockets, and many Hiredis-vip clients continue to be unable to update the slot topology.
The end result is that after a large scale Redis cluster undergoes a slot migration operation, the business side perception is that common command latency becomes high and the Redis instance CPU resource usage is high under large scale Hiredis-vip client access. This logic can be optimised to some extent.
The optimizations in subsection 3 above have now been committed and merged into Redis version 6.2.2.