
Note: This article is not an introductory tutorial, to learn Argo Workflows please go to the official documentation Argo Documentation
Argo Workflows is a cloud-native workflow engine that focuses on orchestrating parallel tasks. It has the following features.
- defines workflows using Kubernetes Custom Resources (CR), where each step in a workflow is a container.
- model multi-step workflows as a series of tasks, or use directed acyclic graphs (DAGs) to describe the dependencies between tasks.
- Computationally intensive jobs for machine learning or data processing can be easily run in a short period of time.
- Argo Workflows can be seen as an enhanced version of Tekton, so obviously it is also possible to run CI/CD streamlines (Pipielines) with Argo Workflows.
AliCloud is a deep user and contributor to Argo Workflows, and the underlying workflow engine of Kubeflow is also Argo Workflows.
I. Argo Workflows vs. Jenkins
Before we switched to Argo Workflows, the CI/CD tool we used was Jenkins. Here is a more detailed comparison between Argo Workflows and Jenkins to understand the advantages and disadvantages of Argo Workflows.
1. Definition of Workflow
Workflow is defined using the kubernetes CR, so it’s obviously a yaml configuration.
A Workflow is a pipeline running on Kubernetes that corresponds to a single Build of Jenkins.
A WorkflowTemplate is a reusable Workflow template that corresponds to a Job in Jenkins.
The yaml definition of WorkflowTemplate is identical to Workflow, except for Kind!
WorkflowTemplate can be referenced and triggered by other Workflows, or can be passed manually to generate a Workflow workflow.
2. Workflow orchestration
The most important feature of Argo Workflows compared to other pipeline projects (Jenkins/Tekton/Drone/Gitlab-CI) is its powerful pipeline orchestration capability.
Other pipeline projects give little thought to the interconnectedness of pipelines, and basically assume that pipelines are independent of each other.
Argo Workflows, on the other hand, assumes that there are dependencies between “tasks”, and provides two methods for coordinating the scheduling of “tasks”: Steps and DAGs.
With the help of templateRef or Workflow of Workflows, the orchestration of Workflows can be implemented.
The main reason we chose Argo Workflows over Tekton is that Argo’s pipeline orchestration is much more powerful than Tekton. (Perhaps because our backend middleware structure is special, our CI pipeline needs to have complex orchestration capabilities)
An example of a complex workflow is as follows.
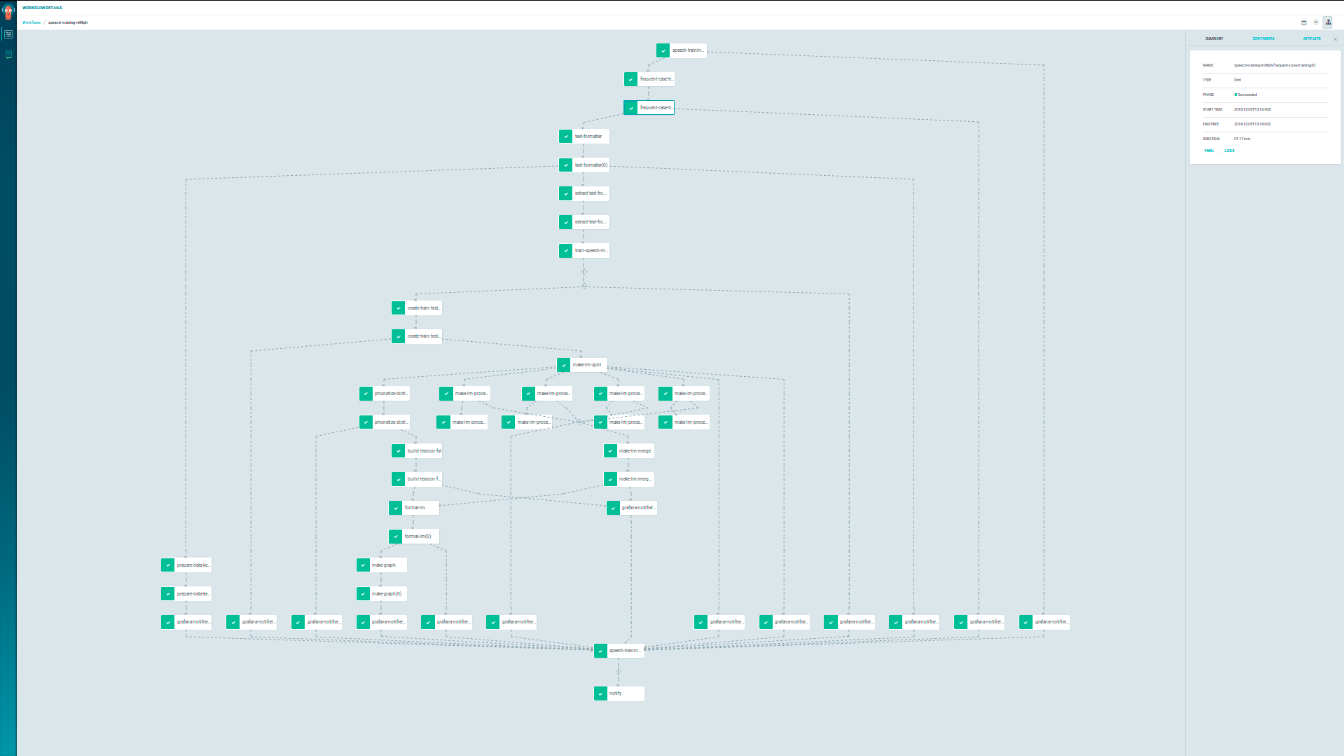
3. Declarative configuration of Workflow
Argo uses Kubernetes Custom Resources (CR) to define Workflow, and users familiar with Kubernetes Yaml should get up to speed quickly.
Here’s a comparison of the Workflow definition file and the Jenkinsfile.
- argo uses yaml entirely to define the pipeline, and the learning cost is lower than the groovy Jenkinsfile. This is especially true for students familiar with Kubernetes.
- After rewriting the jenkinsfile with argo, there is a significant bloat in the amount of code. A 20-line Jenkinsfile may become 60 lines when rewritten with Argo.
Configuration bloat is a problem, but given that it’s fairly readable, and that Argo’s Workflow scheduling feature replaces some of the Python build code we currently maintain, among other benefits, configuration bloat is an acceptable problem.
4. Web UI
The Argo Workflows web UI feels primitive. It does have all the features it should support, but it doesn’t seem to be “user” oriented and is rather low level.
It doesn’t have a very user-friendly interface like Jenkins (although Jenkins’ UI is also very old…)
In addition, all of its workflows are independent of each other, so there is no way to visually find all the build records of a WorkflowTemplate, you can only sort them by label/namespace and search by task name.
Jenkins, on the other hand, makes it easy to see all the build histories of the same Job.
5. Classification of Workflow
Why Workflow needs to be classified in detail
Common microservices projects are often split into many Git repositories (microservices) for development, and having many Git repositories can lead to the creation of many CI/CD pipelines. Without any classification, it becomes a challenge to manage this large number of pipelines.
The most obvious requirements: it would be good to have a distinction between the front-end and back-end pipelines, with a breakdown down to the front-end web side and client side, and a distinction between the back-end business layer and the middle office.
We also want to integrate Ops and automation testing tasks into the system (we currently use Jenkins for Ops and automation testing tasks), without any categories, this huge pipeline will be chaotic.
Argo Workflows’ Classification Capabilities
When there are more and more Workflows, it can be very confusing to have a bunch of WorkflowTemplates stacked together without categorization. (Yes, I think Drone has this problem…)
Argo is completely based on Kubernetes, so for now it can only be categorized by namespace/labels.
This classification structure is very different from Jenkins’ view-folder system, which doesn’t feel very useful at the moment (or maybe it’s purely a web UI issue)
6. Ways to trigger builds
Argo Workflows’ pipeline has several ways to trigger.
- Manual trigger: manually committing a Workflow triggers a build. This can be done by workflowTemplateRef directly referencing a ready-made workflow template.
- Timed triggers: CronWorkflow
- Triggered by Git repository changes: you can do this with argo-events, see the documentation for details.
- It’s also unclear how reliable WebHook is. Could a Git repository change without Workflow triggering because of a downtime or disconnection, and there’s no visible error notification? If this error is just hidden away, it could lead to serious problems!
7. secrets management
The Argo Workflows pipeline can get information from kubernetes secrets/configmap, inject it into environment variables, or mount it as a file in a Pod.
Git private keys, Harbor repository credentials, and kubeconfig for CDs are all available directly from secrets/configmap.
Also, since Vault is so popular, you can save secrets in Vault and inject them into the Pod via the vault agent.
8. Artifacts
Argo supports access to an object store to make a global Artifact repository, which can be used locally with MinIO.
The biggest benefit of using an object store to store Artifacts is that you can pass data between Pods at will, and Pods can run on any node in a Kubernetes cluster in a completely distributed fashion.
Also consider using the Artifact repository to implement cache reuse across pipelines (not tested) to improve build speed.
9. Container image building
Distributed builds of container images can be achieved with container image build tools such as Buildkit.
Buildkit also has good support for build caching, which can be stored directly in the container image repository.
Google’s Kaniko is not recommended, it does not have good support for cache reuse, and the community is not active.
10. Client/SDK
Argo has a command line client available, as well as an HTTP API to use.
The following projects are worth trying.
- argo-client-python: Python client for Argo Workflows
- To be honest, it feels as hard to use as kubernetes-client/python, after all, it’s all generated by openapi-generator…
- argo-python-dsl: writing Argo Workflows using Python DSL
- Feels more difficult to use than yaml, and not very useful.
- couler: provide a unified build and management interface for Argo/Tekton/Airflow
- Good idea, to be studied
I think couler is pretty good, you can write WorkflowTemplate in Python directly, so all CI/CD code is in Python in one step.
In addition, since Argo Workflows is a kubernetes custom resource CR, you can also use helm/kustomize to do workflow generation.
Currently some of our Argo workflow configurations, which are very multi-step but also very repetitive, are generated using helm - the key data is extracted into values.yaml and the workflow configuration is generated using the helm template + range loop.
II. Install Argo Workflows
Install a cluster wide version of Argo Workflows, using MinIO for artifacts storage.
|
|
Deploy MinIO:
|
|
When minio is deployed, it saves the default accesskey and secretkey in a secret named minio. We need to modify argo’s configuration to make minio its default artifact repository.
Add the following fields to the data in configmap workflow-controller-configmap.
|
|
There is one last step left: manually access minio’s Web UI and create the bucket argo-bucket. You can access the Web UI by directly accessing minio’s port 9000 (you need to expose this port using nodeport/ingress, etc.) and logging in using the aforementioned secret minio with the key/secret, and you can create the bucket.
ServiceAccount configuration
Argo Workflows rely on the ServiceAccount for authentication and authorization, and by default it uses the default ServiceAccount of the namespace where it runs the workflow.
But the default ServiceAccount doesn’t have any privileges by default! So Argo’s artifacts, outputs, access to secrets, etc. are all unusable due to insufficient permissions!
For this reason, Argo’s official documentation provides two solutions.
Method 1 is to bind cluster-admin ClusterRole directly to default and give it cluster administrator privileges with a single command (but obviously security is a concern).
|
|
Method 2, the official Role definition of the least privilege required for Argo Workflows is given, I changed it to a ClusterRole for convenience:
|
|
Create the smallest ClusterRole above, then for each namespace, run the following command to bind the default account to the clusterrole:
|
|
This will give the default account minimal access to run workflow.
Or if you want to use another ServiceAccount to run workflow, you can create your own ServiceAccount and then follow the process in method 2 above, but at the end, remember to set the spec.ServiceAccountName.
Workflow Executors
A Workflow Executor is a process that conforms to a specific interface and through which Argo can perform actions such as monitoring Pod logs, collecting Artifacts, managing container lifecycles, etc…
There are several implementations of Workflow Executor, which can be selected via the configmap workflow-controller-configmap mentioned earlier.
The available options are as follows.
- docker (default): Currently the most widely used, but the least secure. It requires mount access to
docker.sock, so you must have root privileges! - kubelet: Very little used and currently lacking in functionality, must also provide root privileges
- Kubernetes API (k8sapi): directly by calling k8sapi to achieve log monitoring, Artifacts phone and other functions, very secure, but performance is not good. Process Namespace Sharing (pns): Less secure than k8sapi because Process is visible to all other containers. But the relative performance is much better.
At a time when docker is being abandoned by kubernetes, if you have switched to containerd as the kubernetes runtime, argo will not work because it uses docker as the runtime by default!
We recommend changing the workflow executore to pns to balance security and performance, and workflow-controller-configmap as follows.
III. Using Argo Workflows as a CI tool
The official Reference is quite detailed and provides a lot of examples for our reference, here we provide a few common workflow definitions.
- use buildkit to build images: https://github.com/argoproj/argo-workflows/blob/master/examples/buildkit-template.yaml
- buildkit supports caching, you can customize the parameters based on this example
- Note that using PVC to share storage across steps is much faster than using artifacts.
IV. Frequently Asked Questions
1. Does workflow use the root account by default?
If your image defaults to a non-root account and you want to modify the files, you are likely to encounter Permission Denined issues.
Solution: Manually set the user/group of the container via Pod Security Context:
For security reasons, I recommend that all workflows manually set securityContext, for example
Or you can set the default workflow configuration with workflowDefaults of workflow-controller-configmap.
2. How to read secrets from hashicorp vault?
Refer to Support to get secrets from Vault
hashicorp vault is currently arguably the most popular secrets management tool in the cloud-native space. We use it as a distributed configuration center in our production environment, and we also use it to store sensitive information in our local CI/CD.
Now that we are migrating to argo, we of course want to have a good way to read the configuration from the vault.
The most recommended method, by far, is to use vault’s vault-agent to inject secrets into the pod as a file.
With the valut-policy - vault-role - k8s-serviceaccount configuration, you can set very granular secrets permissions rules, and the configuration information cannot be re-read, making it very secure.
3. How do I use the same secrets in multiple namespaces?
A common problem when using Namespace to classify workflow is how to use secrets necessary for workflow such as private-git-creds / docker-config / minio / vault in multiple namespaces.
A common approach is to create secrets once in all namespaces.
But there are also more convenient tools for secrets synchronization.
For example, to configure secrets synchronization using kyverno.
|
|
The kyverno configuration provided above will monitor all Namespace changes in real time and will immediately sync the vault secret to a new Namespace as soon as it is created.
Alternatively, use the dedicated secrets/configmap replication tool: kubernetes-replicator
4. Argo’s validation of CR resources is not rigorous enough, it doesn’t even report an error if you write the wrong key
To be studied
5. how to archive historical data?
When Argo is used for a long time, all the Workflows/Pods run by Argo are saved in Kubernetes/Argo Server, which makes Argo slower and slower.
To solve this problem, Argo provides some configurations to limit the number of Workflows and Pods, see: [Limit The Total Number Of Workflows And Pods](https://argoproj.github.io/argo/cost- optimisation/#limit-the-total-number-of-workflows-and-pods)
These limits are Workflow parameters, if you want to set a global default limit, you can modify argo’s workflow-controller-configmap configmap as follows:
|
|
6. Other advanced configurations for Argo
The configuration of Argo Workflows is stored in the workflow-controller-configmap configmap, which we have already touched on.
Here is a full example of this configuration file: https://github.com/argoproj/argo/blob/master/docs/workflow-controller-configmap.yaml
Some of the parameters that may need to be customized are as follows.
parallelism: the maximum number of parallelism for the workflowpersistence: save completed workflows to postgresql/mysql, so that you can view workflow records even if the workflow is deleted from k8s- also supports configuring the expiration time
sso: enable single sign-on
7. Should I try to use the features provided by CI/CD tools?
I know from my colleagues and the web that some DevOps people advocate using Python/Go to implement the CI/CD pipeline by themselves as much as possible, and not to use the features provided by CI/CD tools if they can.
That’s why I have this question. Here’s a detailed analysis.
Try to use the CI/CD tools to provide plug-ins / features, the benefit is not to achieve their own, can reduce maintenance costs. But the relative operations and maintenance staff will need to learn the use of this CI/CD tool in depth, in addition to the CI/CD tool binding, will increase the difficulty of migration.
If you try to use Python code to implement the pipeline and let the CI/CD tool only be responsible for scheduling and running the Python code, then the CI/CD can be easily changed at will, and the operation and maintenance personnel do not need to learn the use of the CI/CD tool in depth. The downside is that it may increase the complexity of the CI/CD code.
I have observed some examples of argo/drone and found that they are characterized by: 1.
- all CI/CD related logic is implemented in the pipeline, no other build code is needed
- each step uses a dedicated image: golang/nodejs/python
- for example, first use golang image for testing, building, and then use kaniko to package into container images
So should we try to use the features provided by CI/CD tools? ** It’s really a question of which method to use when there are multiple ways to implement the same thing. This question is common in all areas. **
In my experience so far, it needs to be problem specific, using Argo Workflows as an example.
- the pipeline itself is very simple, then you can directly use argo to implement, no need to get a python script
- a simple pipeline, migration is often very simple. There is no need to use argo to call a python script just for the sake of migratability.
- If there is a lot of logic/data passing between steps in the pipeline, there is probably something wrong with your pipeline design!
- The data passed between steps of the pipeline should be as small as possible! Complex logical judgments should be encapsulated in one of the steps as much as possible!.
- in this case, python scripts should be used to encapsulate the complex logic, instead of exposing it to Argo Workflows!
- I need to run a lot of pipelines in batch, with complex dependencies between them: I should obviously take advantage of the advanced features of argo wrokflow.
- argo’s dag/steps and workflow of workflows are two features that can be combined to simply implement the above functionality.
8. How to improve the speed of creation and destruction of Argo Workflows?
We found that workflow pods consume a lot of time to create and destroy, especially destruction. This caused our single pipeline to run on argo, but not as fast as on jenkins.
Experience
I’ve been using Argo Workflows for over a month now, and in general, the most difficult part is the Web UI.
All the others are minor problems, but the Web UI is really hard to use, I feel like I haven’t designed it properly…
Urgently need a third party Web UI…
How to handle dependencies between other Kubernetes resources
The most important feature of Argo, compared to other CI tools, is that it assumes that there are dependencies between “tasks”, so it provides a variety of ways to orchestrate “tasks”.
However, it seems that Argo CD does not inherit this concept. When Argo CD is deployed, it does not define dependencies between kubernetes resources through DAG and other methods.
Microservices have dependencies and want to be deployed as such, while ArgoCD/FluxCD deploys kubernetes yaml without any dependencies in mind. There is a contradiction here.
There are many ways to solve this contradiction, I have checked many sources and done some thinking myself, and the best practice I got is from Resolving Service Dependencies - AliCloud ACK Container Service, which gives two options.
- Application-side service dependency checking : that is, add dependency checking logic to the entry of microservices to ensure that all dependent microservices/databases are accessible before the renewal probe returns 200. If it times out, it directly Crashes
- Independent Service Dependency Checking Logic : Some legacy code may be difficult to modify using method 1, so you can consider using pod initContainer or adding dependency checking logic to the container startup script.
But there are still some problems with these two solutions, so before I explain the problem, let me explain our “deploy in order” application scenario.
We are a very small team, and when we do RPC interface upgrade on the backend, we usually do the full upgrade + test directly in the development environment. Therefore, on the O&M side as well, we do a full upgrade every time.
Because there is no protocol negotiation mechanism, the “RPC server” of the new microservice will be compatible with both the old and new protocols of v1 v2, while the new “RPC client” will directly use the v2 protocol to request other microservices. This means that we must upgrade the “RPC server” before we can upgrade the “RPC client “.
For this reason, when performing a full upgrade of a microservice, it is necessary to upgrade sequentially along the RPC call chain, which involves the dependencies between Kubernetes resources.
The key problem I’ve learned so far is that we’re not using a true microservice development model, but are treating the entire microservice system as a “single service”, which leads to this dependency critical issue. The new company I joined had no such problem at all. All services were decoupled at the CI/CD stage, and the CI/CD did not need to consider the dependencies between services, nor did it have the ability to automatically batch release microservices according to the dependencies, which were all maintained by the developers themselves. Perhaps this is the correct posture, if you do not move to update a large number of services, the design of the microservice system, splitting must be a problem, and the production environment will not allow such a frivolous update.
As mentioned earlier, AliCloud’s “application-side service dependency checking” and “independent service dependency checking logic” are best practices. Their advantages are.
- simplify the deployment logic, each time directly do a full deployment OK. 2.
- improve deployment speed, as evidenced by: GitOps deployment process only needs to go once (sequential deployment is many times), all images are pulled in advance, and all Pods are started in advance.
However, there is a problem with “grayscale releases” or “rolling updates”, both of which have the problem of new and old versions co-existing.
If there is an RPC interface upgrade, then you must first complete the “gray release” or “rolling update” of the “RPC server”, and then update the “RPC client”.
Otherwise, if you do grayscale update for all microservices directly and only rely on “service dependency checking”, you will have this problem - the “RPC server” is in a “Schrödinger” state, and the version of the server you invoke is new or old, depending on the load balancing policy and probability.
So when doing a full upgrade of RPC interfaces, relying only on “service dependency checking” won’t work. The options I have in mind so far are as follows.
- Our current use scenario: Implement sequential deployment in the yaml deployment step and poll kube-apiserver after each deployment to make sure all grayed out before proceeding to the next stage of yaml deployment.
- Let the backend add a parameter to control the version of the RPC protocol used by the client, or have a protocol negotiation. This eliminates the need to control the order of microservice releases.
- The deployment of many stateful applications in the community involves complex operations such as deployment order, and a popular solution is to use Operator+CRD for such applications.