We all know how to use WaitGroup, but we also need to know how it is implemented, so that we can avoid the panic caused by incorrect use in the project as much as possible, and this article will also write about the memory alignment aspect to do a resolution, I hope you like it.
WaitGroup Introduction
WaitGroup provides three methods.
- Add, which sets the count value of the WaitGroup.
- Done, used to subtract 1 from the WaitGroup’s count, which is actually a call to Add(-1).
- Wait, the goroutine that calls this method will keep blocking until the count of the WaitGroup becomes 0.
I will not give examples, the Internet is a lot of, here we go straight to the point.
Analysis
|
|
Here at the very beginning, WaitGroup shows off its muscles, let’s see how the big bully writes his code and think about how an atomic operation operates on different architectural platforms, and let’s take a look at memory alignment before looking at why it’s done inside the state method.
Memory alignment
On Wikipedia https://en.wikipedia.org/wiki/Data_structure_alignment we can see the definition of memory alignment.
A memory address a is said to be n-byte aligned when a is a multiple of n bytes (where n is a power of 2).
In short, the CPU now accesses memory bytes at a time, for example, the 32-bit architecture accesses 4bytes at a time, the processor can only start reading data from memory with an address that is a multiple of 4, so the data is required to be stored at a multiple of 4 when the first address value is stored, which is called memory alignment.
Since I couldn’t find the alignment rules for Go, I checked the memory alignment rules for C, which can be matched with Go, so I refer to the following rules first.
Memory alignment follows the following three principles.
- the start address of a structure variable can be divided by the size of its widest member.
- the offset of each member of the structure relative to the start address can be divided by its own size, or if not, by additional bytes after the preceding member.
- the overall size of the structure is divisible by the size of the widest member or, if not, is followed by additional bytes.
A hands-on look at memory alignment is given by the following example.
In a 32-bit architecture, int8 takes up 1byte, int32 takes up 4bytes, and int16 takes up 2bytes.
|
|
The following is an example of running in a 32-bit architecture.
The default alignment size in a system with 32-bit architecture is 4bytes.
Suppose the starting address of a in structure A is 0x0000, which can be divided by the widest data member size of 4bytes (int32), so it is stored from 0x0000 to occupy a byte that is 0x0000~0x0001; b is int32, which occupies 4bytes, so to meet condition 2, it needs to padding 3 bytes after a, starting from 0x0004 start; c is int16, accounting for 2bytes so from 0x0008 to occupy two bytes, that is, 0x0008 ~ 0x0009; this time the entire structure occupies the space is 0x0000 ~ 0x0009 occupy 10 bytes, 10%4! = 0, does not meet the third principle, so you need to add two bytes later, that is, after the final memory alignment occupies the space is 0x0000 ~ 0x000B, a total of 12 bytes.
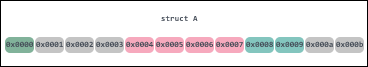
Similarly, it is more compact compared to structure B.

Memory alignment of state method in WaitGroup
Before we talk about it, we need to note that noCopy is an empty structure with size 0, so we don’t need to do memory alignment, so we can ignore this field when we look at it.
In the WaitGroup, the uint32 array is used to construct the state1 field, and then different return values are constructed according to the number of bits in the system, so I will talk about how to build the waiter number, count value, and semaphore through the sate1 field.
Pointer` to get the address value of state1 and then convert it to uintptr type, and then determine whether the address value is divisible by 8. Here, the address mod 8 is used to determine whether the address is 64-bit aligned.
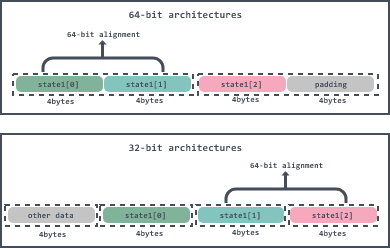
Because of the existence of memory alignment, in the 64-bit architecture WaitGroup structure state1 starting position is definitely 64-bit aligned, so in the 64-bit architecture with the first two elements of state1 and into uint64 to represent statep, state1 last element represents semap.
So can the 64-bit architecture get the first element of state1 to represent semap, and the last two elements to be spelled into 64-bit return?
The answer is naturally no, because the alignment of uint32 is guaranteed to be 4bytes, and the fixed length of a one-time transaction in the 64-bit architecture is 8bytes, so if the last two elements of state1 represent a 64-bit word field, the CPU needs to read the memory twice, which cannot guarantee atomicity.
But in 32-bit architecture, a word length is 4bytes, to operate 64-bit data distributed in two data blocks, two operations are needed to complete the access. If there is a possibility of other operations modifying the data between the two operations, atomicity is not guaranteed.
Similarly, if the 32-bit architecture wants to operate atomically on 8bytes, it needs to be guaranteed by the caller that its data address is 64-bit aligned, otherwise the atomic access will have an exception, as we can see here https://golang.org/pkg/sync/atomic/#pkg-note-BUG that describes.
On ARM, x86-32, and 32-bit MIPS, it is the caller’s responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically. The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
So to ensure 64-bit word alignment, only the first 64-bit word in variables or open structures, arrays and sliced values can be considered 64-bit word aligned. But when using WaitGroup there are nested cases and it is not guaranteed to always have WaitGroup present on the first field of the structure, so we need to add padding to make it 64-bit word aligned.
In 32-bit architecture, WaitGroup is allocated memory address randomly when it is initialized, so the location of the start of WaitGroup structure state1 is not necessarily 64-bit aligned, it may be: uintptr(unsafe.Pointer(&wg.state1))%8 = 4 , if such a situation occurs , then you need to use the first element of state1 for padding and the last two elements of state1 to merge into uint64 for statep.
Summary
Here is a small summary, because it took a lot of consulting to complete the above content to come up with this result. So here is a small summary, in the 64-bit architecture, the word length of each CPU operation is 8bytes, the compiler will automatically help us to initialize the address of the first field of the structure to 64-bit alignment, so the 64-bit architecture with the first two elements of state1 and into uint64 to represent statep, state1 last element represents semap.
Then in the 32-bit architecture, when initializing the WaitGroup, the compiler can only guarantee 32-bit alignment, not 64-bit alignment, so by uintptr(unsafe.Pointer(&wg.state1))%8 to determine if it is equal to 0 to see if the state1 memory address is 64-bit aligned, if it is, then also and 64-bit architecture is the same, use the first two elements of state1 and merge into uint64 to represent statep, the last element of state1 represents semap, otherwise use the first element of state1 for padding, use the last two elements of state1 and merge into uint64 to represent statep.
Add method
|
|
-
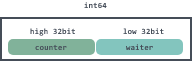
The first thing the add method does is to call the state method to get the values of statep and semap. statep is a value of type uint64, the high 32 bits are used to record the sum of the delta values passed in by the add method; the low 32 bits are used to indicate the number of goroutines waiting by calling the wait method, that is, the number of waiters. It is as follows.
-
the add method calls the
atomic.AddUint64method to shift the incoming delta 32 bits to the left, that is, to add the value of the counter to the delta. -
int32 to get the counter value because the counter counter may be negative, waiter cannot be negative, so uint32 is used to get it.
-
Next is a series of checks, v can not be less than zero means that the task counter can not be negative, otherwise it will panic; w is not equal to, and the value of v is equal to delta means that the wait method is executed before the add method, at this time will also panic, because the waitgroup does not allow to call the add method after calling the Wait method.
-
v is greater than zero or w is equal to zero is returned directly, indicating that the waiter does not need to be released at this time, so it is returned directly.
-
*statep ! = stateBy the time this check is done, the state can only be waiter greater than zero and counter zero. When the waiter is greater than zero, it is not allowed to call the add method, and the wait method cannot be called when the counter is zero, so the value of state is used here to compare with the address value of the memory to see if add or wait is called to cause the state to change, if so, it is an illegal call that will cause panic. -
finally reset the value of statep to zero and then release all waiters.
Wait method
|
|
- the Wait method first also calls the state method to get the state value.
- after entering the for loop Load statep value, and then get the counter and counter respectively.
- if counter is already zero, then return directly without waiting.
- counter is not zero, then use CAS to add waiter by 1. Since CAS may fail, the for loop will come back here again for CAS until it succeeds.
- call runtime_Semacquire to hang and wait for wakeup.
*statep ! = 0After waking up, statep is not zero, which means that the WaitGroup is reused again, which will panic.
waitgroup usage summary
After reading the add method and wait method of waitgroup, we found that there are many checks in it, and improper use will lead to panic, so we need to summarize how to use it correctly.
- The counter cannot be set to a negative number, otherwise panic will occur; note that there are two ways to cause the counter to be negative, one is to pass a negative number when calling Add, and the second is to call the Done method too many times, exceeding the count value of the WaitGroup.
- When using a WaitGroup, be sure to wait until all Add methods are called before calling Wait, otherwise it may result in a panic.
- WaitGroup can be reused before wait is finished. waitGroup can be reused, but you need to wait for the last batch of goroutine to finish calling wait before you can continue to reuse WaitGroup.
Summary
The code inside waitgroup is actually very simple and this article is mainly about the concept of memory alignment introduced by waitgroup. The waitgroup takes us through how the concept of memory alignment is used in real code and how to atomically manipulate 64-bit long fields in a 32-bit operating system.
In addition to the concept of memory alignment, we also learn through the source code what we need to do when using waitgroup in order to be compliant with the specification and not trigger a panic.