The data in our database is always changing, and sometimes we want to listen to the changes in the database data and react according to the changes, such as updating the cache corresponding to the changed data, incrementally synchronizing to other data sources, detecting and auditing the data, and so on. And this technology is called Change Data Capture. For this technology we may know a well-known domestic framework Canal , very good! But one limitation of Canal is that it can only be used for Mysql change data capture. Today to introduce another more powerful distributed CDC framework Debezium .
Debezium
I’m sure most casual developers are unfamiliar with the Debezium framework, but the company it belongs to will be no stranger to you.

That’s right the most successful in the open source world, Red Hat. Debezium is a streaming processing framework for capturing data changes, open source and free. Debezium monitors database row-level (row-level) data changes in near real-time and can react to changes. And only committed changes are visible , so do not worry about transaction problems or changes are rolled back . Debezium provides a unified model for all database change events, so there is no need to worry about the complexity of each database system. Debezium provides support for databases such as MongoDB, MySQL, PostgreSQL, SQL Server, Oracle, DB2, etc.
In addition, the Kafka Connector enables the development of an event stream-based change capture platform with high fault tolerance and extreme scalability.
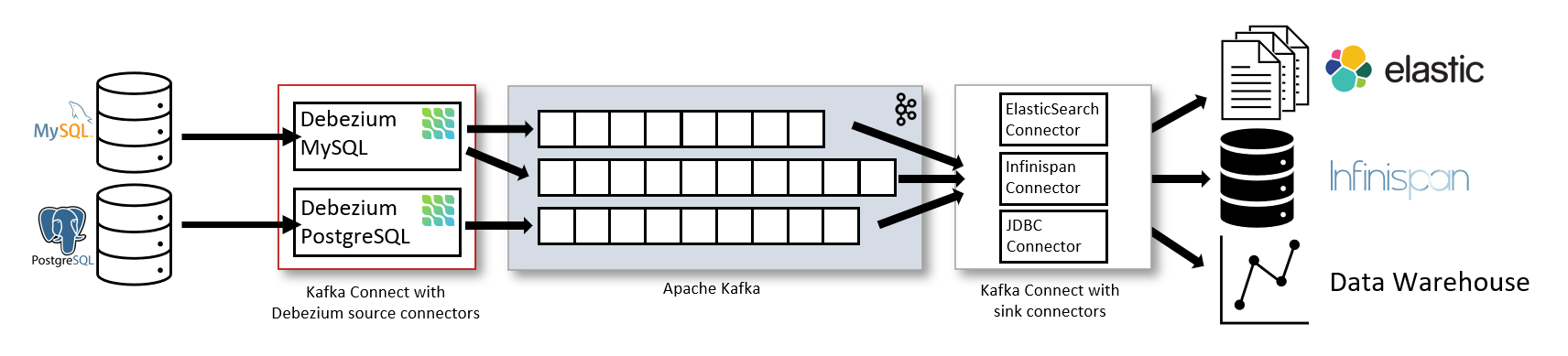
As shown in the figure, Debezium Kafka Connectors for MySQL and PostgresSQL are deployed to capture change events to both types of databases and then transfer those changes to other systems or databases (e.g. Elasticsearch, data warehouses, analytics systems) or caches via a downstream Kafka Connector.
Another way to play with this is to build Debezium into the application to make a message bus-like facility to pass data change events to subscribed downstream systems.
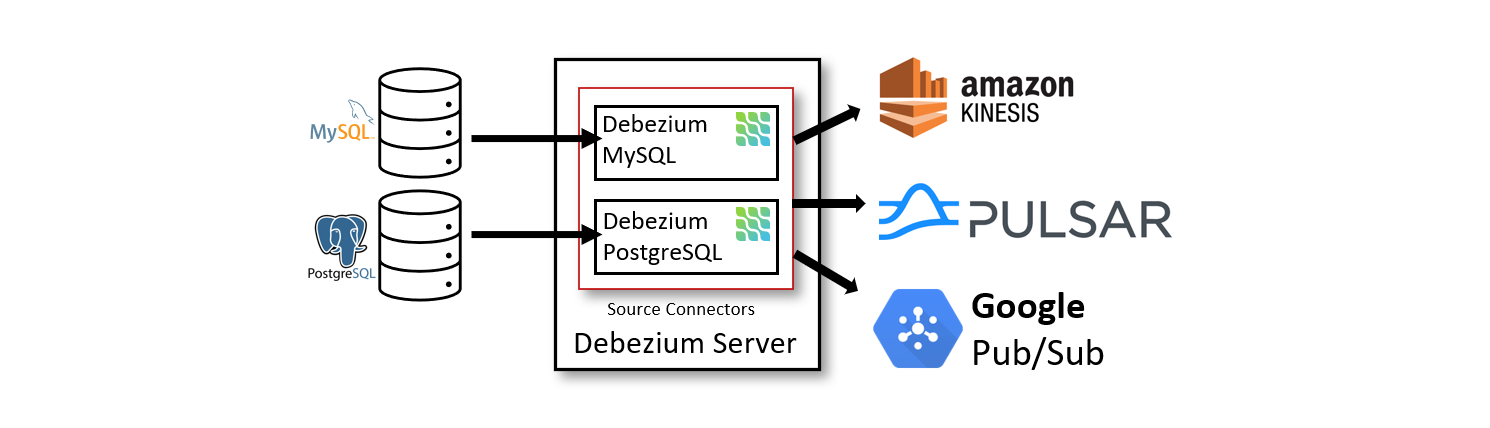
Debezium also does a lot of work on data integrity and availability. Debezium keeps a history of database data changes with persistent, copy-backed logs, so your application can be stopped and restarted at any time without missing events that happened when it stopped running, ensuring that all events are handled correctly and completely.
Later I will demonstrate a Spring Boot data capture system integrated with Debezium.
Spring Boot Integration with Debezium
A theoretical introduction doesn’t give you a visual sense of what Debezium can do, so next I’ll use the Embedded Debezium engine to demonstrate it.
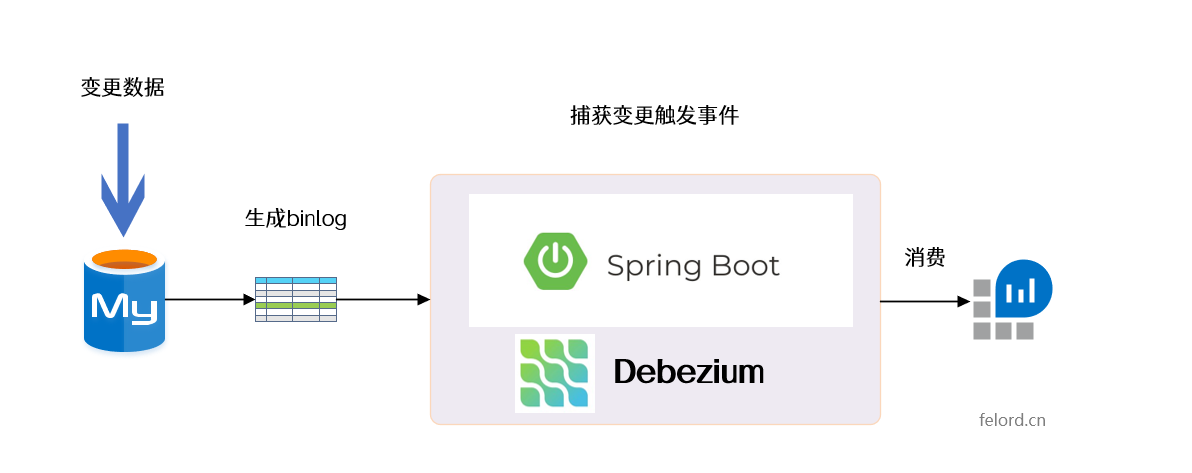
As shown above, when we change a row of data in the MySQL database, the change event is captured by Debezium listening to binlog log changes in real time, and then the change event model is obtained and responded (consumed). Next, let’s set up the environment.
MySQL with binlog logging turned on
To facilitate the use of MySQL’s Docker container here, the corresponding script is.
|
|
The above script runs a MySQL container with user name root and password 123456 and mounts data to local path d:/mysql/data with binlog logging enabled and server-id set to 123454, which will be used later in the configuration.
Note that if you don’t use the
rootuser, you need to ensure that the user hasSELECT,RELOAD,SHOW DATABASES,REPLICATION SLAVE,REPLICATION CLIENTprivileges.
Spring Boot integration with embedded Debezium
Debezium dependencies
The following dependencies are added to the Spring Boot application.
|
|
Declare the configuration
Then declare the required configuration.
|
|
The configuration is divided into two parts.
- One part is the configuration properties of Debezium Engine, see Debezium Engine Configuration.
- One part is the configuration properties of Mysql Connector, see Mysql Connector Configuration.
Instantiating the Debezium Engine
The application needs to start a Debezium engine for the running Mysql Connector, which runs as an asynchronous thread that wraps the entire Mysql Connector connector lifecycle. Declaring an engine requires the following steps.
- Declare the format of the received data change capture message,
JSON,Avro,Protobuf,Connect,CloudEvents, etc. are provided. - Load the configuration defined above.
- Declare the function method for consuming data change events.
Pseudocode for the declaration.
The handlePayload method is.
|
|
The engine is started and closed to fit the Spring bean lifecycle.
|
|
Start
Start the Spring Boot project and you can add, delete and change data to the database using various means and observe that it will print something like the following.
|
|
It means that Debezium has listened for changes to the database. You can think of scenarios in which this technique is useful.