There are many ways to store data today, and hard drives are the preferred choice for most users because of their price and data protection advantages. However, hard disks are several orders of magnitude slower than memory in terms of IO reads and writes, so why would you prefer hard disks?
The first thing that needs to be mentioned is that the main reason why operating a disk is slow is because of the time consuming read and write to the disk. There are three main time consuming parts to read and write: seek time + spin time + transfer time , of which seek time is the longest. Because seek needs to move the head to the corresponding track, through the motor drive magnetic arm movement, is a mechanical movement so it takes a long time. At the same time, our disk operations are usually random reads and writes, which requires frequent movement of the head to the corresponding track, which makes the time consumption extended and appears to be lower performance.
So it seems that if you want to make disk read/write speed faster, you can effectively improve disk read/write speed by not using random reads and writes, or by reducing the number of random reads and writes. So how exactly do you do it?
Sequential reading and writing
Let’s talk about the first method, how to use sequential read/write instead of random read/write? As mentioned above, seek time is the most time consuming, so the most intuitive idea is to save this time, and sequential IO can meet the demand.
Appending writes is a typical sequential IO, and a typical product optimized using this idea is a message queue. Take the popular Kafka as an example. Kafka uses a lot of optimizations to achieve high performance IO, including sequential write optimization.
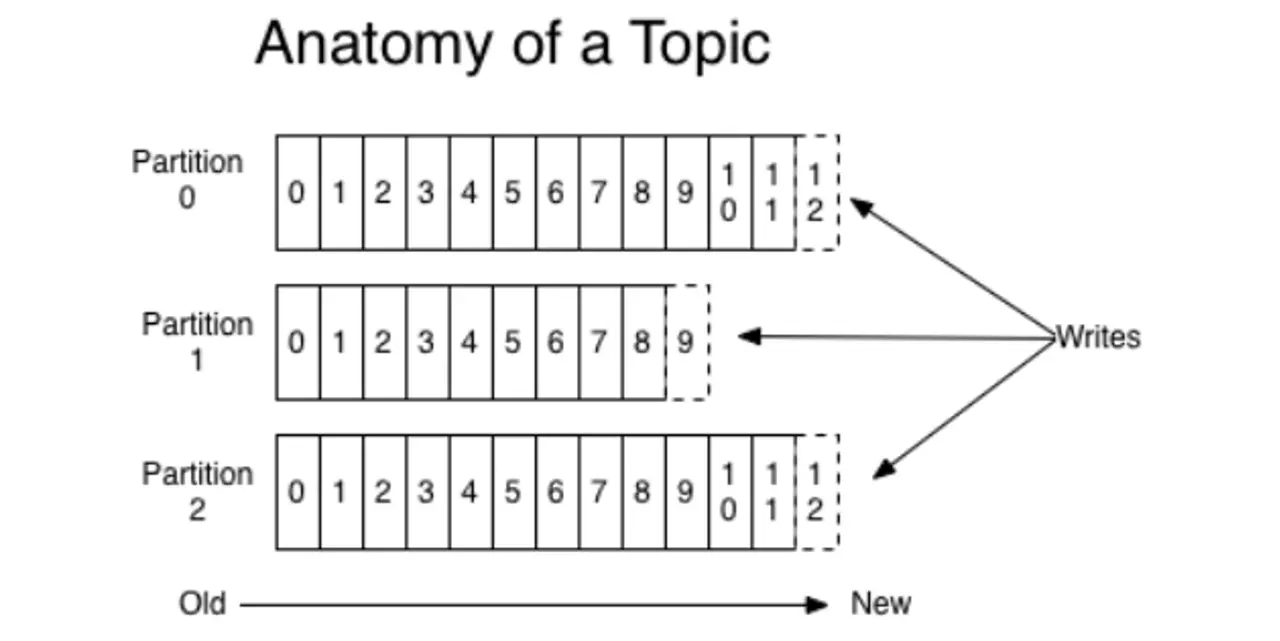
Kafka provides message persistence capabilities with O(1) time complexity, guaranteeing constant time complexity access performance even for terabytes of data or more. For each partition, it writes the messages received from the Producer to the corresponding log file sequentially, and opens a new file only when a file is full. When consuming, it also reads the messages sequentially starting from a global location, i.e., a location in a log file.
Reduce the number of randomizations
After looking at the sequential approach, let’s look at ways to reduce the number of random writes. In many scenarios, in order to facilitate our subsequent reads and operations on the data, we require that the data written to the hard disk be in order. For example, in MySQL, indexes are organized as B+ trees in the InnoDB engine, and MySQL primary keys are clustered indexes (a type of index where data is put together with index data), so when data is inserted or updated, we need to find the location to be inserted and then write the data to a specific location, which generates random IO. Therefore, if we write data to the .ibd file every time we insert or update data, and then the disk has to find the corresponding record and then update it, the IO cost and lookup cost of the whole process are very high, and the performance and efficiency of the database will be greatly reduced.
In order to solve the write performance problem, InnoDB introduces WAL mechanism, more precisely, redo log. below I will briefly introduce Redo Log.
InnoDB redo log is a ring log with a fixed size that is written sequentially. There are two main purposes.
- Improving the efficiency of writing data to the InnoDB storage engine
- Ensure crash-safe capability
Here we are only interested in how it improves the efficiency of writing data. The diagram below shows the redo log.
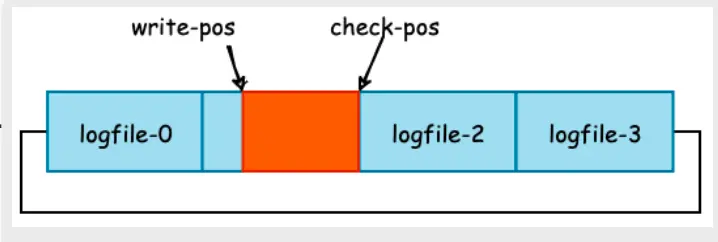
As you can see from the diagram, red olog writes are sequential and do not need to find a specific index location, but simply append from the write-pos pointer location.
Secondly, when a write transaction or update transaction is executed, InnoDB first retrieves the corresponding Page and then modifies it. When the transaction commits, the redo log buffer in memory is forcibly flushed to the hard disk, and if binlog is not considered, we can assume that the transaction execution can return to success, and the write to DB operation is performed asynchronously by another thread. The write to the DB is performed asynchronously by another thread.
Then, the master thread of InnoDB can flush the dirty pages in the buffer pool, that is, the pages we modified above, to disk at regular intervals, and then the modified data is actually written to the .ibd file.
Summary
In many cases, we have to store data on the hard disk, but the hard disk is too “slow” compared to the memory. So we have to find ways to improve performance. The article summarizes two methods, the first is appending writes, using sequential IO to achieve fast writes; the second is the WAL mechanism introduced in many databases to improve performance. In the article, Kafka and MySQL’s InnoDB storage engine are given as examples. In addition to these two, interested students can also look at how LSM trees, etcd, etc. are implemented for fast writing.