Basic Concepts
Kafka Architecture
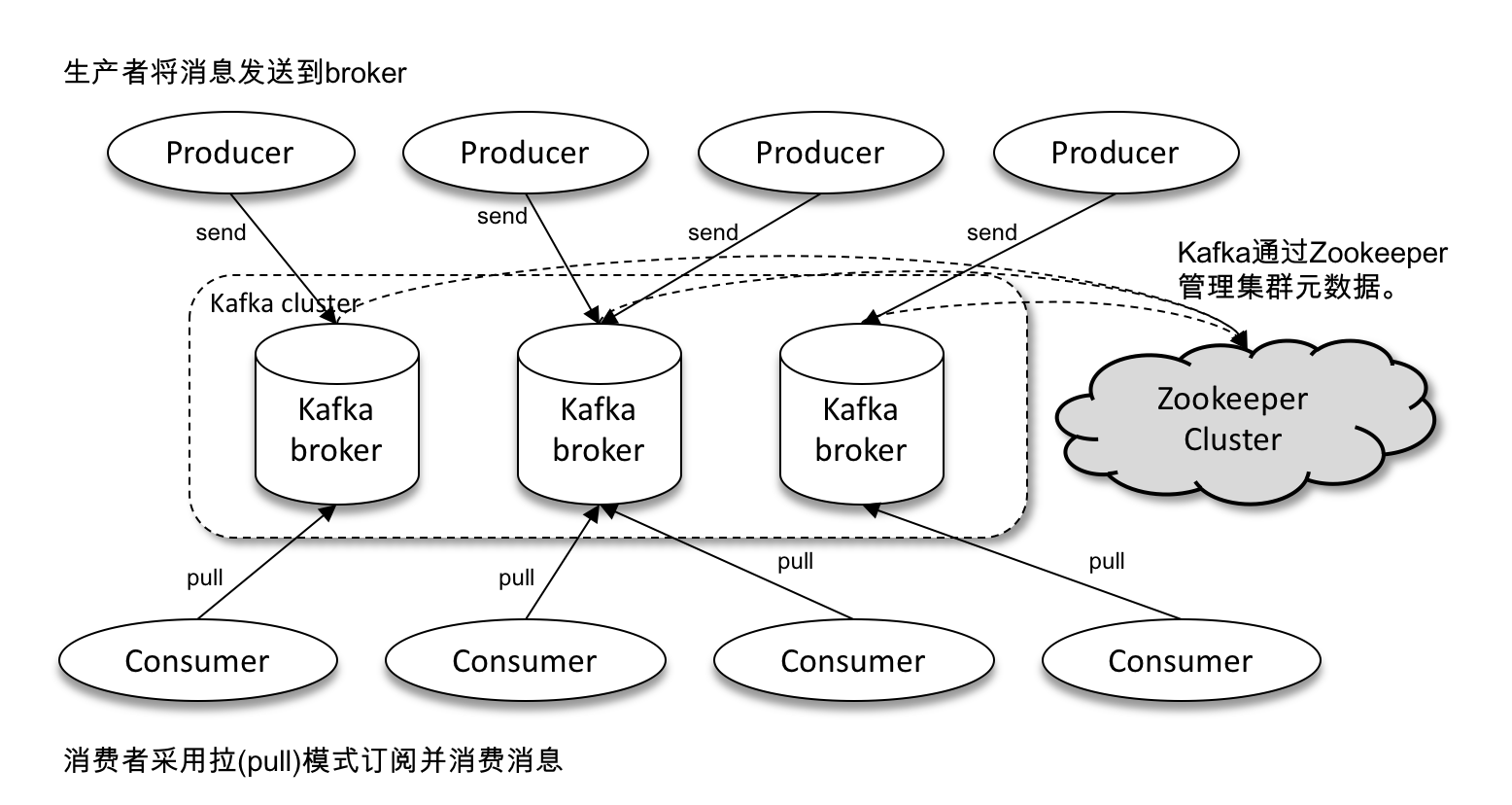
The Kafka architecture consists of a number of Producers, a number of Brokers, a number of Consumers, and a ZooKeeper cluster.
There are two other concepts that are particularly important in Kafka - Topic and Partition.
Messages in Kafka are grouped by topic, producers are responsible for sending messages to a specific topic (each message sent to a Kafka cluster is assigned a topic), and consumers are responsible for subscribing to and consuming topics.
A topic is a logical concept that can also be subdivided into multiple partitions, where a partition belongs to only a single topic, and in many cases is also referred to as a Topic-Partition.
Kafka introduces a multi-replica (Replica) mechanism for partitions, which can improve disaster recovery by increasing the number of replicas. Different replicas of the same partition store the same message (at the same time, the replicas are not exactly the same), and the replicas have a “master-multiple-slave” relationship, where the leader replica is responsible for handling read and write requests, and the follower replica is only responsible for synchronizing with the leader replica’s messages. When the leader replica fails, a new leader replica is re-elected from the follower replica to provide services to the outside world.
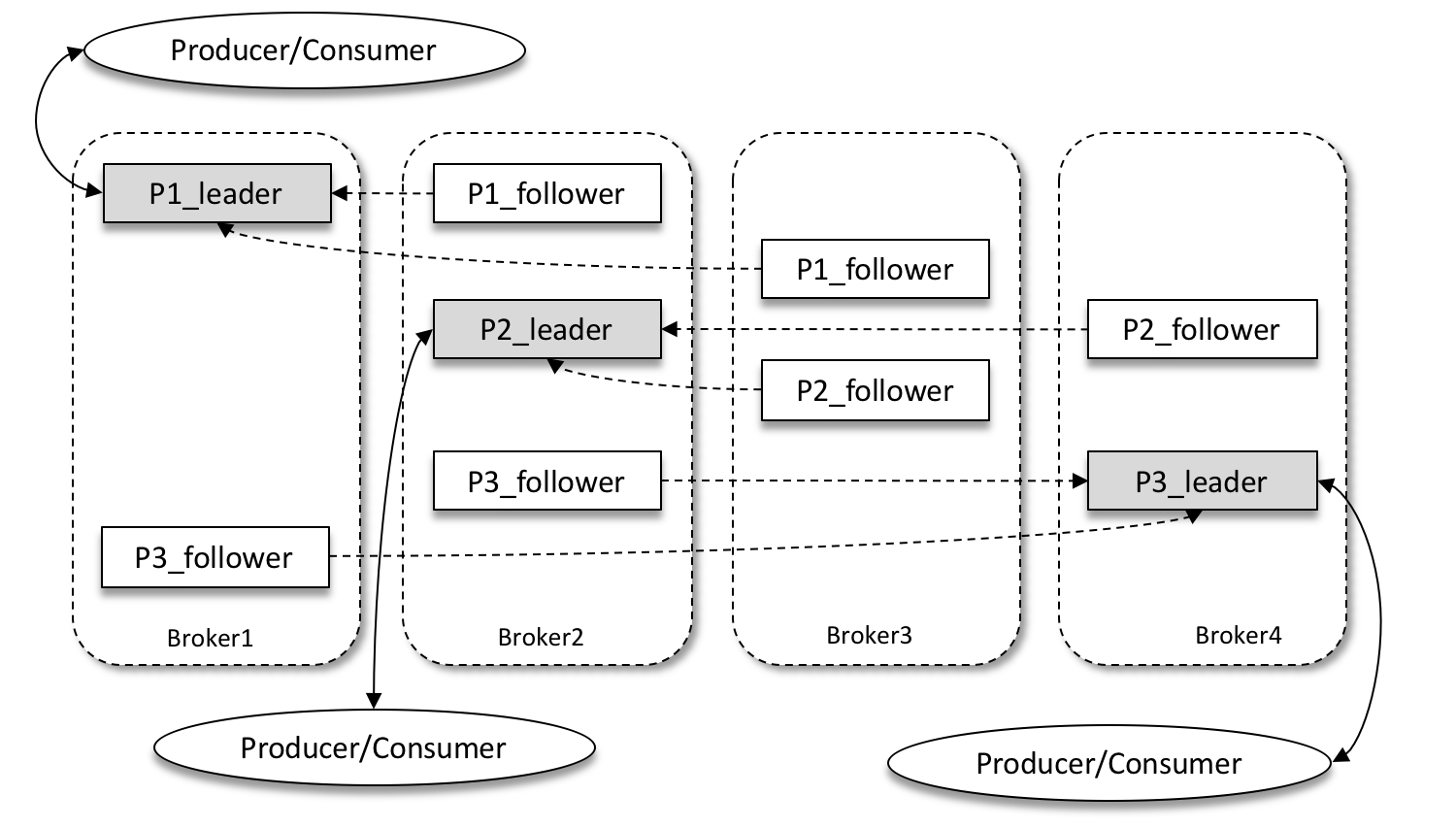
As shown above, there are 4 brokers in a Kafka cluster, 3 partitions in a topic, and the replica factor (i.e., number of replicas) is also 3, so each partition has 1 leader replica and 2 follower replicas.
Data synchronization
All replicas in a partition are collectively known as ARs (Assigned Replicas). All replicas that are synchronized to some degree with the leader replica (including the leader replica) form ISRs (In-Sync Replicas), which are a subset of the AR set.
Under normal circumstances, all follower replicas should be synchronized with the leader replica to some extent, i.e., AR=ISR, OSR set is empty.
The leader copy is responsible for maintaining and tracking the lagging status of all follower copies in the ISR set, and will remove a follower copy from the ISR set if it falls too far behind or fails. By default, when the leader replica fails, only the replicas in the ISR set are eligible to be elected as the new leader.
HW stands for High Watermark, which identifies a specific message offset, and consumers can only pull messages up to this offset. LEO stands for Log End Offset, which identifies the offset of the next message to be written in the current log file.
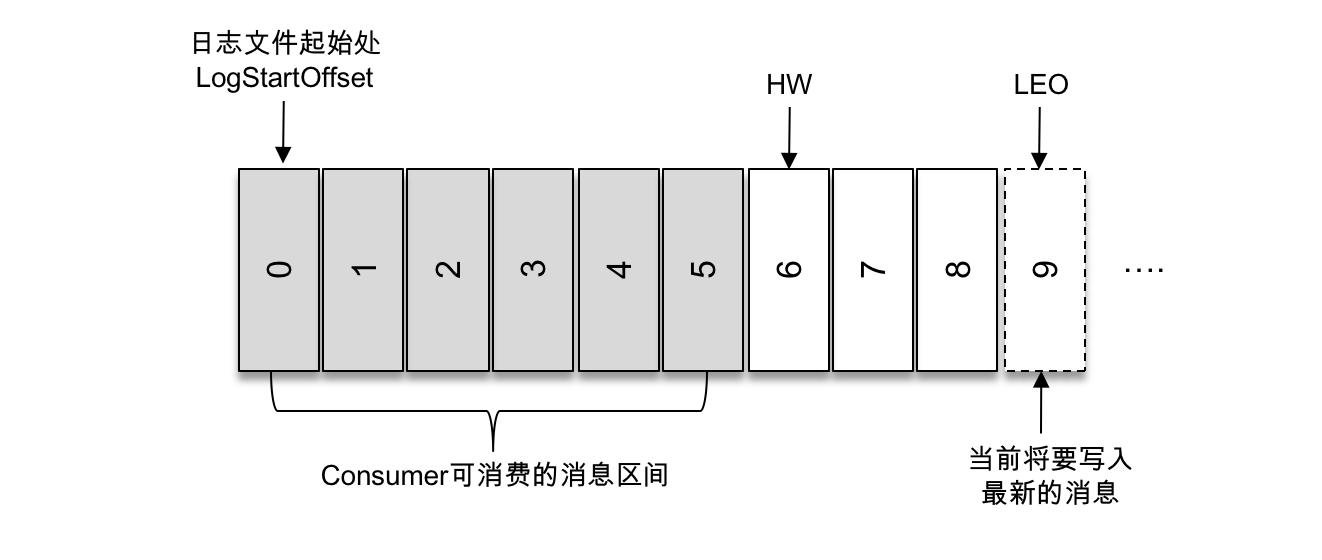
As shown above, the offset (LogStartOffset) of the first message is 0, the offset of the last message is 8, and the message with offset 9 is represented by a dashed box, representing the next message to be written. The HW of the log file is 6, which means that the consumer can only pull messages with offset between 0 and 5, and messages with offset 6 are not visible to the consumer.
The overall structure of the Kafka producer client
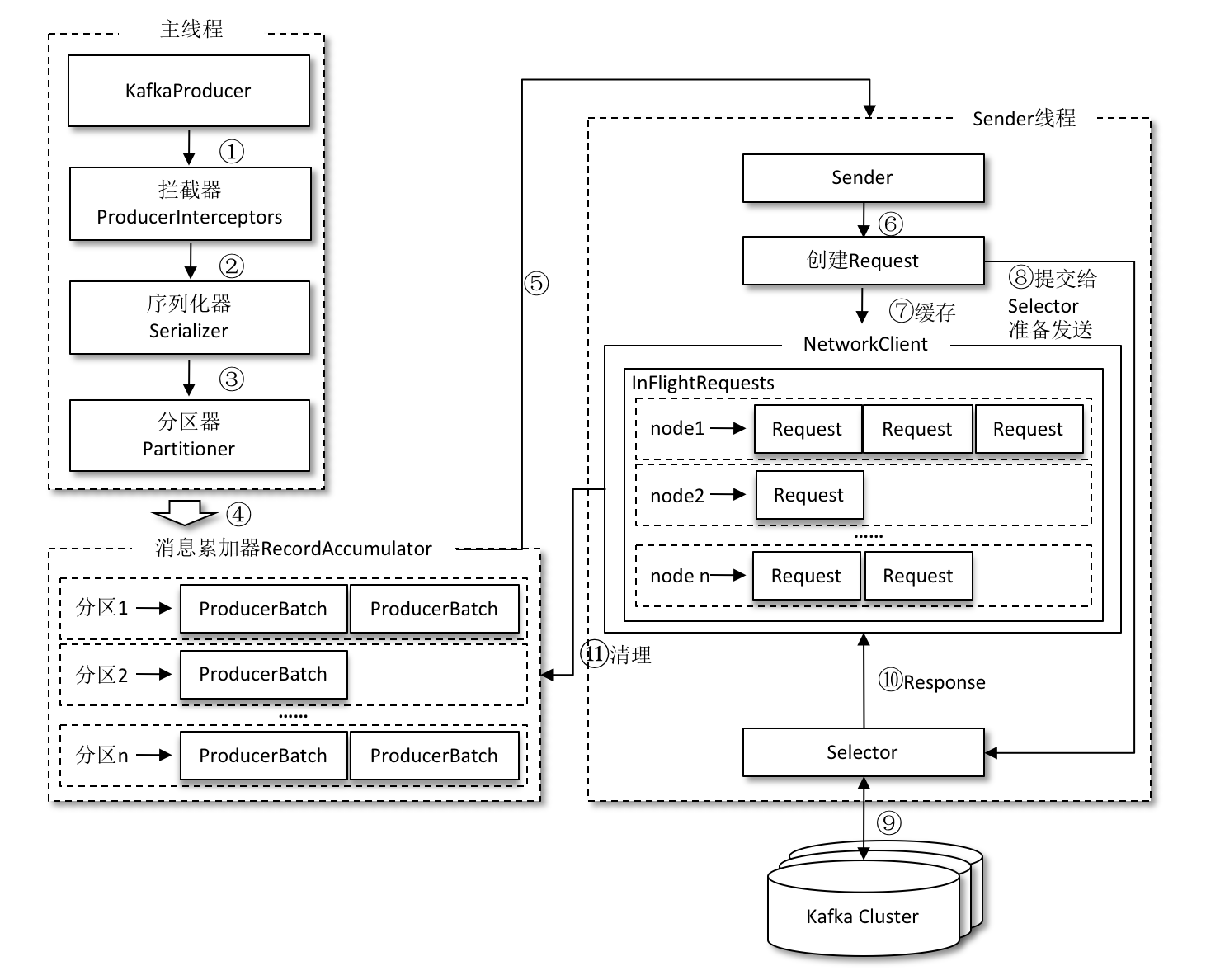
The entire producer client is coordinated by two threads, the main thread and the Sender thread (the sending thread).
In the main thread, messages are created by the KafkaProducer and then cached in the RecordAccumulator (also known as the message collector) after going through possible interceptors, serializers and partitioners. in Kafka.
RecordAccumulator
The RecordAccumulator is mainly used to cache messages so that the Sender thread can send them in bulk, thus reducing the resource consumption of network transfers to improve performance.
Messages sent in the main thread are appended to a double-ended queue in the RecordAccumulator, which maintains a double-ended queue for each partition inside the RecordAccumulator.
When a message is written to the cache, it is appended to the end of the double-ended queue; when the Sender reads a message, it is read from the head of the double-ended queue.
After the Sender fetches the cached messages from the RecordAccumulator, it further transforms the original <Partition, Deque< ProducerBatch>> save form into a <Node, List< ProducerBatch>>, where Node represents the broker node of the Kafka cluster.
Before KafkaProducer can append this message to the leader copy of a partition of the specified topic, it first needs to know the number of partitions of the topic, and then calculate (or directly specify) the target partition, and then KafkaProducer needs to know the address, port, etc. of the broker node where the leader copy of the target partition is located in order to establish the connection. KafkaProducer needs to know the address, port, etc. of the broker node where the leader copy of the target partition is located in order to establish a connection and finally send the message to Kafka.
So there is a conversion required here, for network connections, the producer client establishes a connection to a specific broker node, i.e. sends messages to a specific broker node and does not care which partition the message belongs to.
InFlightRequests
Requests are also saved in InFlightRequests before being sent from the Sender thread to Kafka. InFlightRequests save objects in the form of Map<NodeId, Deque>, whose main purpose is to cache requests that have been sent but have not yet received a response (NodeId is a String type, indicating the id number of the node).
Interceptors
Producer interceptors can be used either to do some preparatory work before the message is sent, such as filtering non-conforming messages according to some rules, modifying the content of the message, etc., or to do some customization requirements before sending the callback logic, such as statistics-type work.
The producer interceptor is also easy to use and is mainly a custom implementation of the org.apache.kafka.clients.producer.
The ProducerInterceptor interface contains 3 methods.
The KafkaProducer calls the onSend() method of the producer interceptor to customize the message accordingly before serializing it and computing the partition. It is generally best not to modify the topic, key, and partition information of the message ProducerRecord.
KafkaProducer calls the onAcknowledgement() method of the Producer Interceptor before the message is answered (Acknowledgement) or if the message fails to be sent, before the user-set Callback. This method runs in the Producer’s I/O thread, so the simpler the code logic implemented in this method, the better, otherwise it will affect the speed of message delivery.
The close() method is mainly used to perform some resource cleanup when the interceptor is closed.
Serializer
The producer needs to use a Serializer to convert objects into byte arrays before sending them to Kafka over the network, while on the other side, the consumer needs to use a Deserializer to convert the byte arrays received from Kafka into the corresponding objects.
If the producer uses a serializer, such as StringSerializer, and the consumer uses another serializer, such as IntegerSerializer, then the desired data cannot be parsed.
Serializers need to implement the org.apache.kafka.common.serialization.Serializer interface, which has three methods.
The configure() method is used to configure the current class, the serialize() method is used to perform the serialization operation. And close() method is used to close the current serializer.
As follows.
|
|
configure() method, which is called when creating a KafkaProducer instance and is mainly used to determine the encoding type.
serialize is used to encode and decode. If the several serializers provided by the Kafka client do not meet the application requirements, you can choose to use generic serialization tools such as Avro, JSON, Thrift, ProtoBuf and Protostuff to implement them, or use a custom type of serializer to implement them.
Partitioners
If a partition field is specified in the message ProducerRecord, there is no need for a partitioner because the partition represents the partition number to which the message is sent.
If the partition field is not specified in the message ProducerRecord, then you need to rely on the partitioner to calculate the value of the partition based on the key field. The role of the partitioner is to assign partitions to messages.
The default partitioner provided in Kafka is org.apache.kafka.clients.producer.internationals. There are 2 methods defined in this interface, which are shown below.
The partition() method is used to calculate the partition number and returns a value of type int. The parameters in the partition() method represent the subject, key, serialized key, value, serialized value, and metadata information of the cluster, through which a feature-rich partitioner can be implemented. close() method is used to reclaim some resources when closing the partitioner.
In the default partitioner implementation of DefaultPartitioner, close() is the null method and the main partition allocation logic is defined in the partition() method. If the key is not null, then the default partitioner will hash the key and eventually calculate the partition number based on the resulting hash, and messages with the same key will be written to the same partition. If the key is null, then the message will be sent to each available partition in the topic in a polled manner.
Custom partitioners simply implement the Partitioner interface like DefaultPartitioner. Since the processing of messages under each partition is sequential, we can use the custom partitioner to achieve orderly consumption by sending all the keys in a series to a partition.
Broker
Broker processing request flow
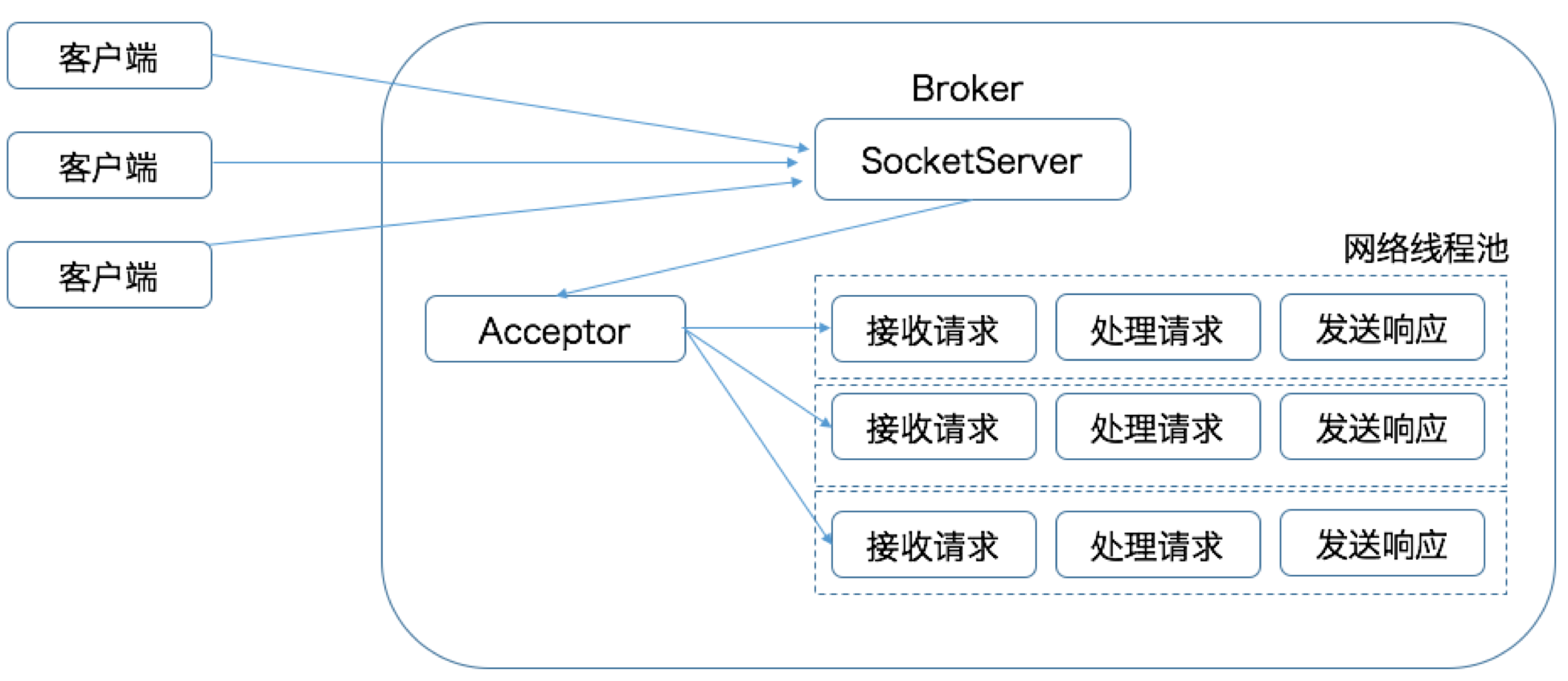
In the Kafka architecture, there are many clients sending requests to the Broker side, and the Broker side of Kafka has a SocketServer component that establishes connections with the clients and then distributes the requests through the Acceptor thread. Throughput.
The default size of the network thread pool is 3, which means that each Broker will create 3 network threads when it starts, specifically to handle requests sent by the client, which can be modified by the Broker side parameter num.network.threads.
Then the next processing network threads processing process is as follows.
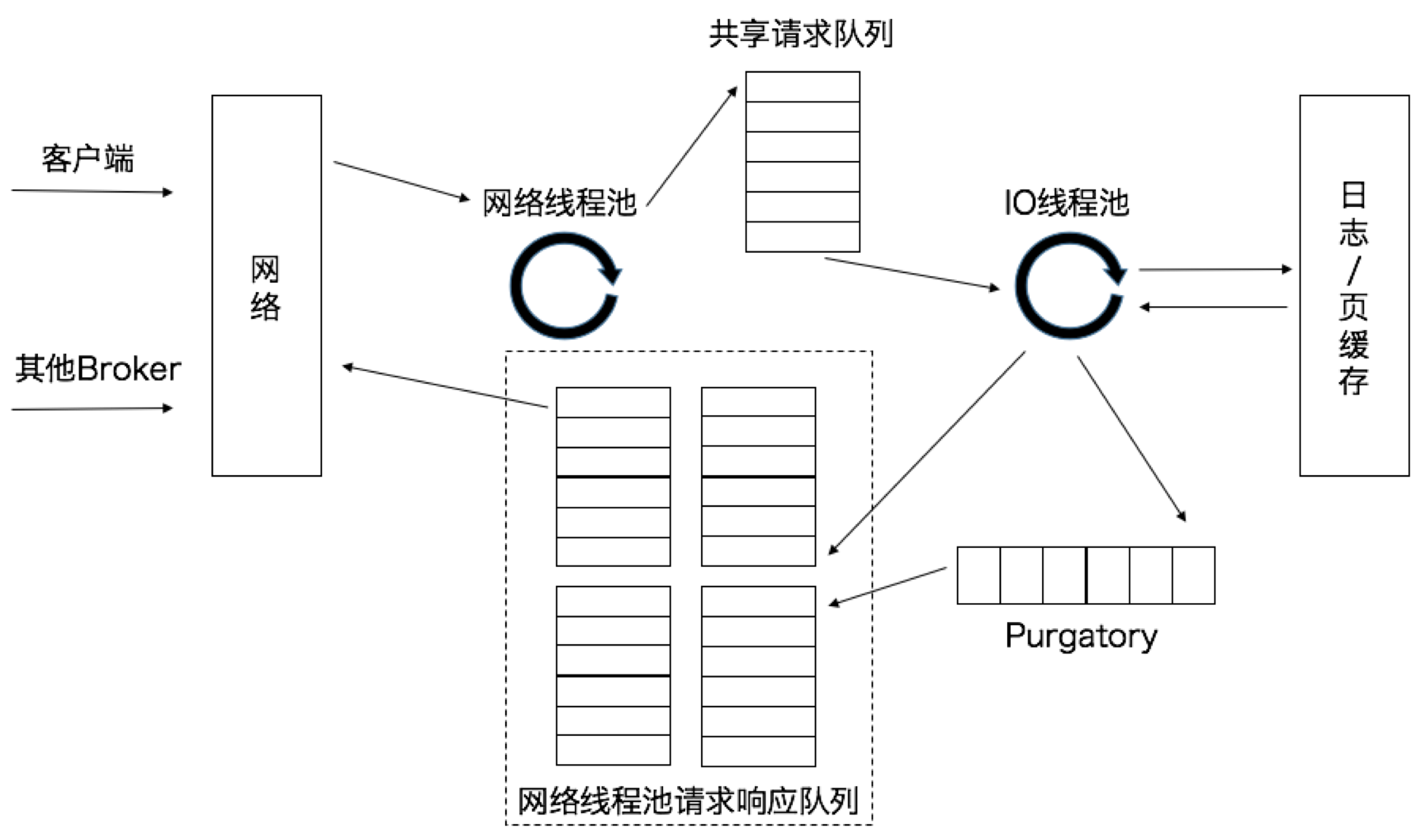
When the network thread gets the request, it puts the request into a shared request queue. there is also a pool of IO threads on the Broker side that takes the request out of this queue and performs the actual processing. If it is a PRODUCE production request, the message is written to the underlying disk log; if it is a FETCH request, the message is read from the disk or page cache.
The threads at the IO thread pool are the threads that execute the request logic. The default is 8, which means that each Broker automatically creates 8 IO threads to process the request when it starts, which can be adjusted with the Broker-side parameter num.io.threads.
The Purgatory component is used to cache delayed requests (Delayed Requests). For example, if a PRODUCE request with acks=all is set, once acks=all is set, the request must wait until all copies in the ISR have received the message before returning, and then the IO thread handling the request must wait for the results of other Broker writes.
Controller
There will be one or more brokers in a Kafka cluster, and one of them will be elected as the controller (Kafka Controller), which is responsible for managing the state of all partitions and replicas in the entire cluster.
How are controllers elected?
When a Broker starts, it tries to create a /controller node in ZooKeeper. Kafka’s current rule for electing controllers is that the first Broker to successfully create a /controller node is designated as the controller.
The /controller_epoch node in ZooKeeper stores an integer controller_epoch value. controller_epoch is used to record the number of times a controller has changed, i.e., how many generations of controllers the current controller is, which we can also call " controller_epoch".
The initial value of controller_epoch is 1, which means that the first controller in the cluster has an epoch of 1. Kafka uses controller_epoch to ensure the uniqueness of controllers and thus the consistency of related operations.
Each request interacting with a controller carries the controller_epoch field. If the controller_epoch value of a request is less than the controller_epoch value in memory, the request is considered to be a request to an expired controller, and the request is considered invalid.
If the controller_epoch value of the request is greater than the controller_epoch value in memory, then a new controller has been elected.
What does the controller do?
- Topic management (create, delete, add partitions)
- Partition reallocation
- Preferred leader election Preferred leader election is mainly a solution provided by Kafka to change the Leader in order to avoid overloading some Brokers.
- Cluster membership management (new Broker, Broker active shutdown, Broker down) The controller component uses the Watch mechanism to check for changes in the number of children under the /brokers/ids node of ZooKeeper. Currently, when a new Broker is started, it creates a dedicated znode node under /brokers. Once created, ZooKeeper pushes a message notification to the controller via the Watch mechanism, so that the controller can automatically sense the change and start subsequent new Broker jobs.
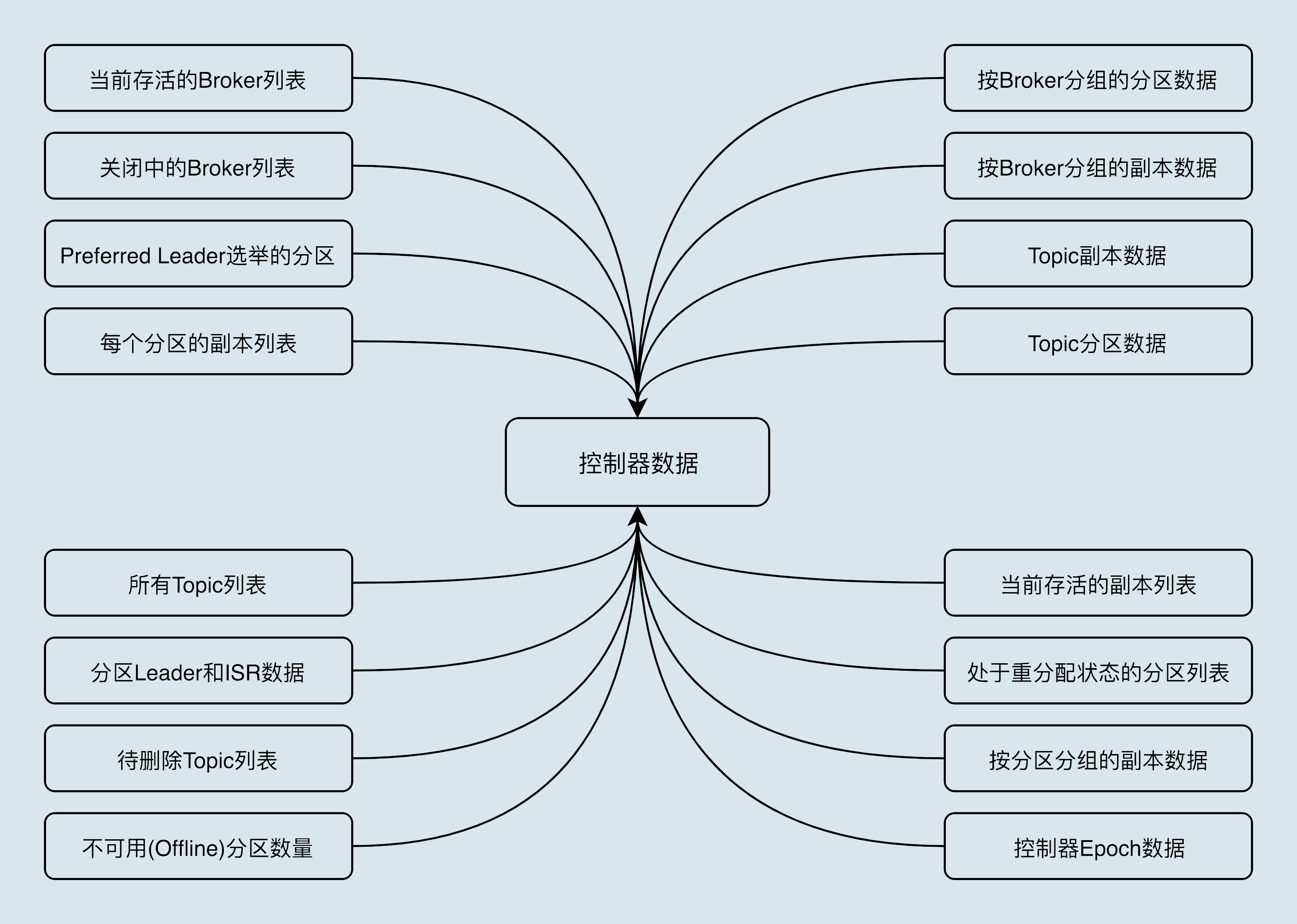
- Data Services The most complete cluster metadata information is stored on the controller.
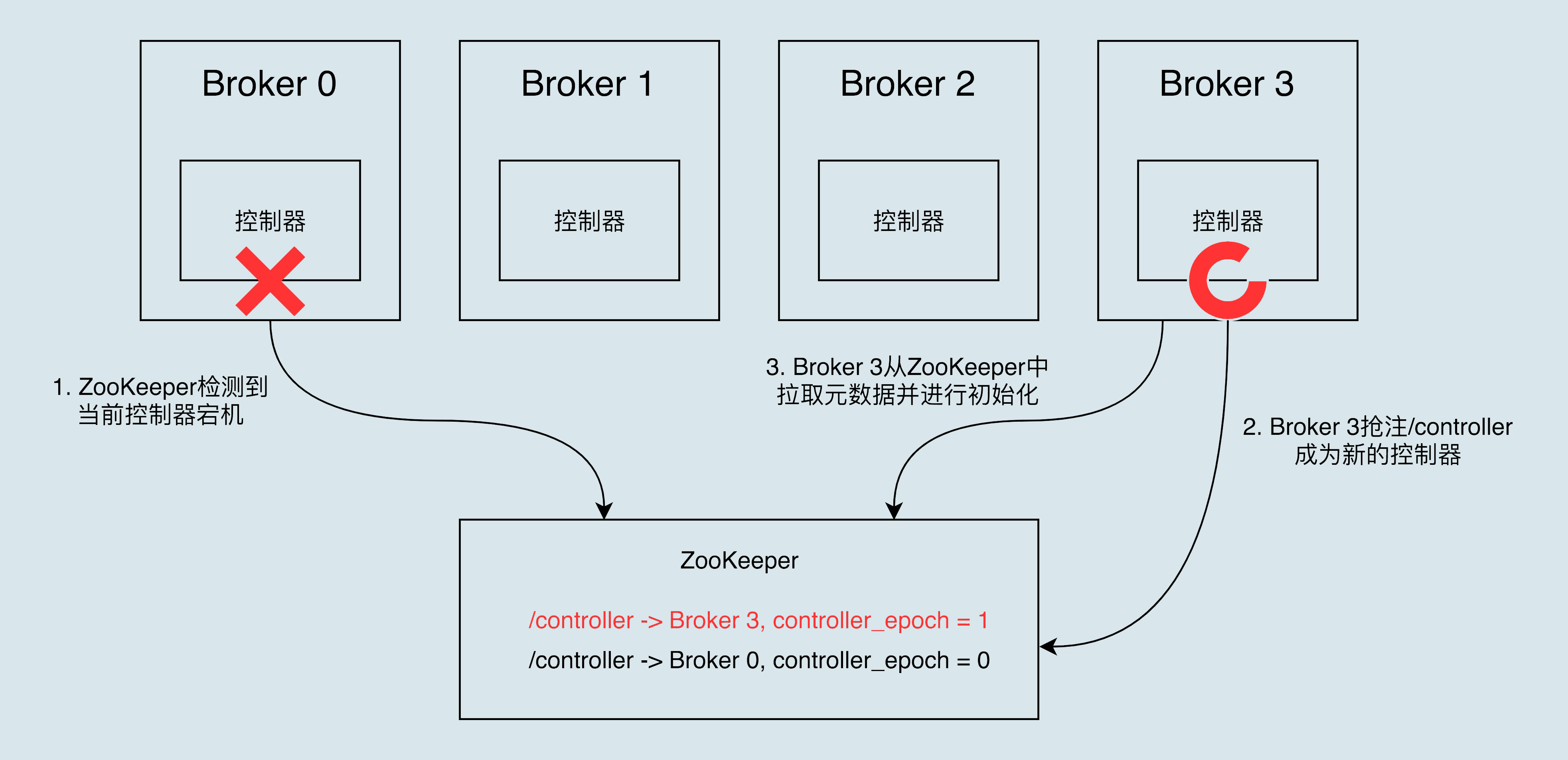
What happens when a controller goes down?
When a running controller suddenly goes down or terminates unexpectedly, Kafka can quickly sense it and immediately enable a standby controller to replace the previously failed one. This process is known as Failover, and it is done automatically without your manual intervention.
Consumers
Consumer groups
In Kafka, each consumer has a corresponding consumer group. When a message is published to a topic, it is only cast to one consumer in each consumer group that subscribes to it. Each consumer can only consume the messages in the partition to which it is assigned. And each partition can only be consumed by one consumer in a consumer group.
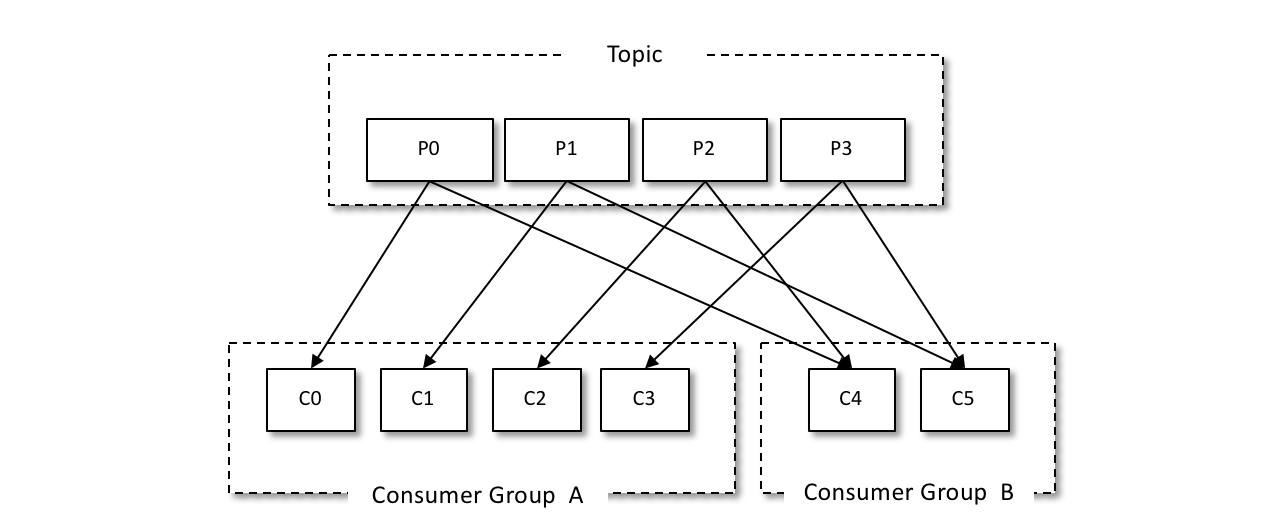
As shown in the figure above, we can set up two consumer groups to broadcast messages, and both consumer group A and group B can receive messages from the producer.
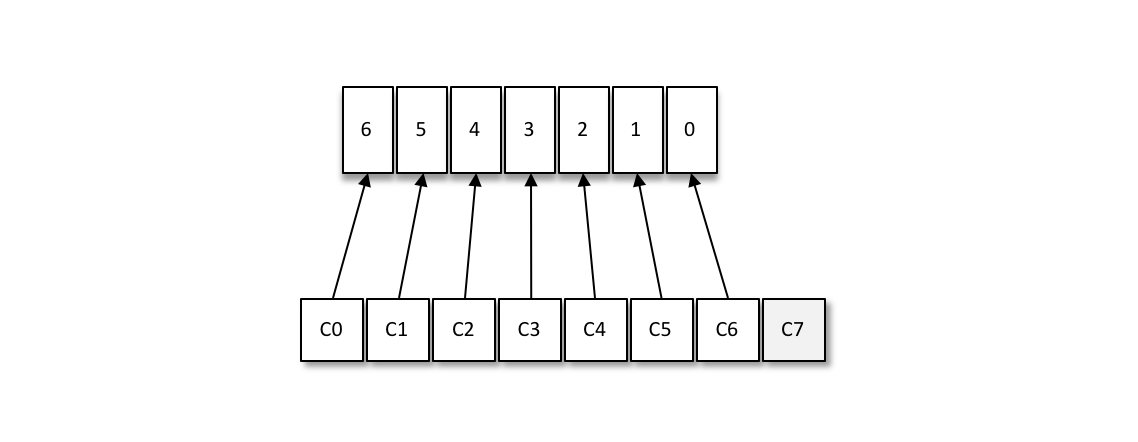
This model of consumers and consumer groups allows the overall consumption capacity to have horizontal scalability, and we can increase (or decrease) the number of consumers to increase (or decrease) the overall consumption capacity. For a fixed number of partitions, increasing the number of consumers will not always increase the spending power, and if there are too many consumers and the number of consumers is greater than the number of partitions, there will be no consumers assigned to any partition.
As follows: there are 8 consumers and 7 partitions, then the last consumer C7 cannot consume any message because it cannot be assigned any partition.
Consumer-side partition assignment strategy
Kafka provides the consumer client parameter partition.assignment.strategy to set the partition assignment strategy between the consumer and the subscription topic.
RangeAssignor assignment strategy
By default, the RangeAssignor allocation strategy is used.
The RangeAssignor allocation strategy works by dividing the total number of consumers and the total number of partitions to obtain a span, and then dividing the partitions evenly by the span to ensure that the partitions are distributed as evenly as possible to all consumers. For each topic, the RangeAssignor policy sorts all consumers subscribed to the topic in the consumer group by the dictionary order of their names, and then divides each consumer into a fixed range of partitions, and if there is not enough equal distribution, then the consumer with the highest dictionary order will be assigned one more partition.
Suppose there are 2 consumers C0 and C1 in the consumer group, both subscribed to topics t0 and t1, and each topic has 4 partitions, then all partitions subscribed can be identified as: t0p0, t0p1, t0p2, t0p3, t1p0, t1p1, t1p2, t1p3. The final allocation result is
Assuming that the 2 topics in the above example have only 3 partitions, then all partitions of the subscription can be identified as: t0p0, t0p1, t0p2, t1p0, t1p1, t1p2. The final allocation is as follows.
It can be clearly seen that such an allocation is not uniform.
RoundRobinAssignor allocation strategy
The RoundRobinAssignor allocation policy works by sorting all consumers in a consumer group and all partitions of topics to which the consumers subscribe in dictionary order, and then assigning the partitions to each consumer in turn by polling.
If all the consumers in the same consumer group have the same subscription information, then the partition distribution of the RoundRobinAssignor allocation policy is uniform.
If the consumers in the same consumer group have different subscription information, then the partition assignment is not a complete polling assignment and may result in uneven partition assignment.
Suppose there are three consumers (C0, C1, and C2) in a consumer group, and t0, t0, t1, and t2 topics have 1, 2, and 3 partitions, respectively, i.e., the entire consumer group subscribes to the six partitions t0p0, t1p0, t1p1, t2p0, t2p1, and t2p2.
Specifically, consumer C0 subscribes to topic t0, consumer C1 subscribes to topics t0 and t1, and consumer C2 subscribes to topics t0, t1, and t2, then the final distribution is as follows.
As we can see, the RoundRobinAssignor policy is not perfect, and this allocation is not optimal, because it is possible to allocate partition t1p1 to consumer C1.
StickyAssignor allocation strategy
This allocation strategy, which has two main purposes.
- the allocation of partitions should be as uniform as possible.
- the allocation of partitions should remain the same as the last allocation as much as possible.
Suppose there are 3 consumers (C0, C1 and C2) in the consumption group, and they all subscribe to 4 topics (t0, t1, t2, t3) and each topic has 2 partitions. That is, the whole consumer group subscribes to the 8 partitions t0p0, t0p1, t1p0, t1p1, t2p0, t2p1, t3p0, t3p1. The final allocation results are as follows.
Assume again that consumer C1 is out of the consumption group at this point, then the distribution results are as follows.
The StickyAssignor allocation policy, like the “sticky” in its name, gives the allocation policy a certain “stickiness” to make the first two assignments as identical as possible, thus reducing the loss of system resources and other The assignment policy is as “sticky” as its name implies.
Rebalance
Rebalance is the act of transferring the ownership of a partition from one consumer to another. It provides guarantees for high availability and scalability of consumer groups, allowing us to easily and safely delete consumers within a consumer group or add consumers to a consumer group.
Disadvantages.
- the consumers in the consumer group cannot read messages during rebalancing.
- Rebalance is very slow. If there are hundreds of Consumer instances in a Consumer group, Rebalance can take several hours at a time.
- The current state of the consumer is also lost when rebalancing is performed. For example, when a consumer finishes consuming a part of a message in a partition, the rebalance occurs before the consumer has time to submit the consumption shift, and then the partition is assigned to another consumer in the consumer group, and the part of the message that was consumed is consumed again, i.e., repeated consumption occurs.
Rebalance occurs at three times.
- the number of group members changes
- the number of topics subscribed to changes
- when the number of partitions in the subscribed topic changes
The latter two types are usually caused by business changes, which we cannot control, so we will focus on how to avoid rebalance caused by changes in the number of group members.
After the Consumer Group completes Rebalance, each Consumer instance periodically sends heartbeat requests to the Coordinator to indicate that it is still alive. If a Consumer instance fails to send these heartbeat requests in time, the Coordinator considers the Consumer “dead” and removes it from the Group and starts a new round of Rebalance.
The Consumer side can set session.timeout.ms, which defaults to 10s, to indicate that if the Coordinator does not receive a heartbeat from a Consumer instance in the Group within 10 seconds, it will assume that the Consumer instance is dead.
The Consumer side can also set heartbeat.interval.ms, which indicates the frequency of sending heartbeat requests.
and the max.poll.interval.ms parameter, which limits the maximum time between two calls to the poll method by the Consumer-side application. The default value is 5 minutes, which means that if your Consumer application cannot consume all the messages returned by the poll method within 5 minutes, the Consumer will initiate a request to “leave the group” and the Coordinator will start a new round of Rebalance.
So knowing the above parameters, we can avoid the following two problems: 1.
-
non-essential Rebalance is caused by Consumer being “kicked out” of the Group due to failure to send heartbeat in time. So we can set it like this in the production environment.
- Set session.timeout.ms = 6s.
- Set heartbeat.interval.ms = 2s.
-
Necessary Rebalance is caused by Consumer consuming too much time. How to consume tasks up to 8 minutes, and max.poll.interval.ms is set to 5 minutes, then Rebalance will also occur, so if there are heavier tasks, you can adjust this parameter appropriately.
-
the frequent Full GC on the Consumer side causes a long stall, which triggers Rebalance.
Consumer group rebalancing full process
The rebalancing process is notified to other consumer instances by the Heartbeat Thread on the consumer side.
When the coordinator decides to start a new round of rebalancing, it wraps “REBALANCE_IN_PROGRESS” in the heartbeat request response and sends it back to the consumer instance. When the consumer instance finds out that the heartbeat response contains “REBALANCE_IN_PROGRESS”, it will immediately know that rebalancing has started again.
So, in fact, heartbeat.interval.ms not only sets the heartbeat interval, but also controls the frequency of rebalancing notifications.
Consumer Group State Machine
Once rebalancing is turned on, the coordinator component on the Broker side has to complete the entire rebalancing process, and Kafka has designed a Consumer Group State Machine to achieve this.
Kafka defines five states for consumer groups, which are Empty, Dead, PreparingRebalance, CompletingRebalance, and Stable.
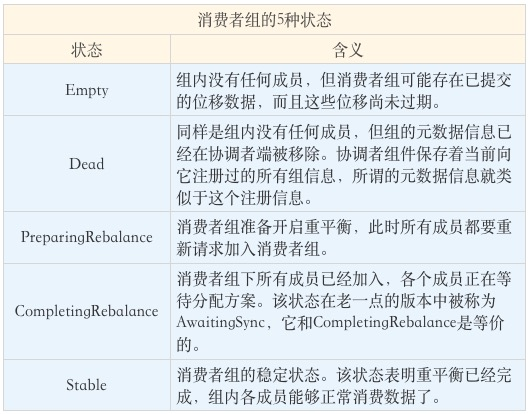
Flow of individual states of the state machine.
When a new member joins or an existing member drops out, the consumer group status jumps directly from Stable to PreparingRebalance, at which point all existing members must reapply to the group. When all members have dropped out of the group, the consumer group status changes to Empty, which is the condition for Kafka to automatically delete expired shifts periodically. So if your consumer group has been down for a long time (more than 7 days), then Kafka has probably deleted the displacement data for that group.
GroupCoordinator
The GroupCoordinator is the component of the Kafka server that is used to manage consumer groups. The most important responsibility of the coordinator is to perform consumer rebalancing operations.
Consumer-side rebalancing process
On the consumer side, rebalancing is divided into two steps: joining the group and waiting for the Leader Consumer (LC) to assign the solution, respectively. That is, JoinGroup request and SyncGroup request.
-
Join Group When a member of a group joins the group, it sends a JoinGroup request to the coordinator. In this request, each member reports the topics to which he/she is subscribed, so that the coordinator can collect the subscription information of all members.
-
Selecting a consumer group leader Once the JoinGroup requests are collected from all members, the coordinator selects one of these members to be the leader of the consumer group. The leader here is a specific consumer instance, which is neither a replica nor a coordinator. The task of the leader consumer is to collect the subscription information of all members and then, based on this information, develop a specific partitioned consumer allocation scheme.
-
Election of partition allocation policy The election of this partition allocation is based on the votes of the individual consumers within the consumer group. The coordinator collects all the allocation policies supported by each consumer to form a candidate set, and each consumer finds the first policy supported by itself from the candidate set and votes for this policy. The strategy with the highest number of votes is the allocation strategy for the current consumer group. If a consumer does not support the selected allocation protocol, then an exception is thrown: Member does not support protocol.
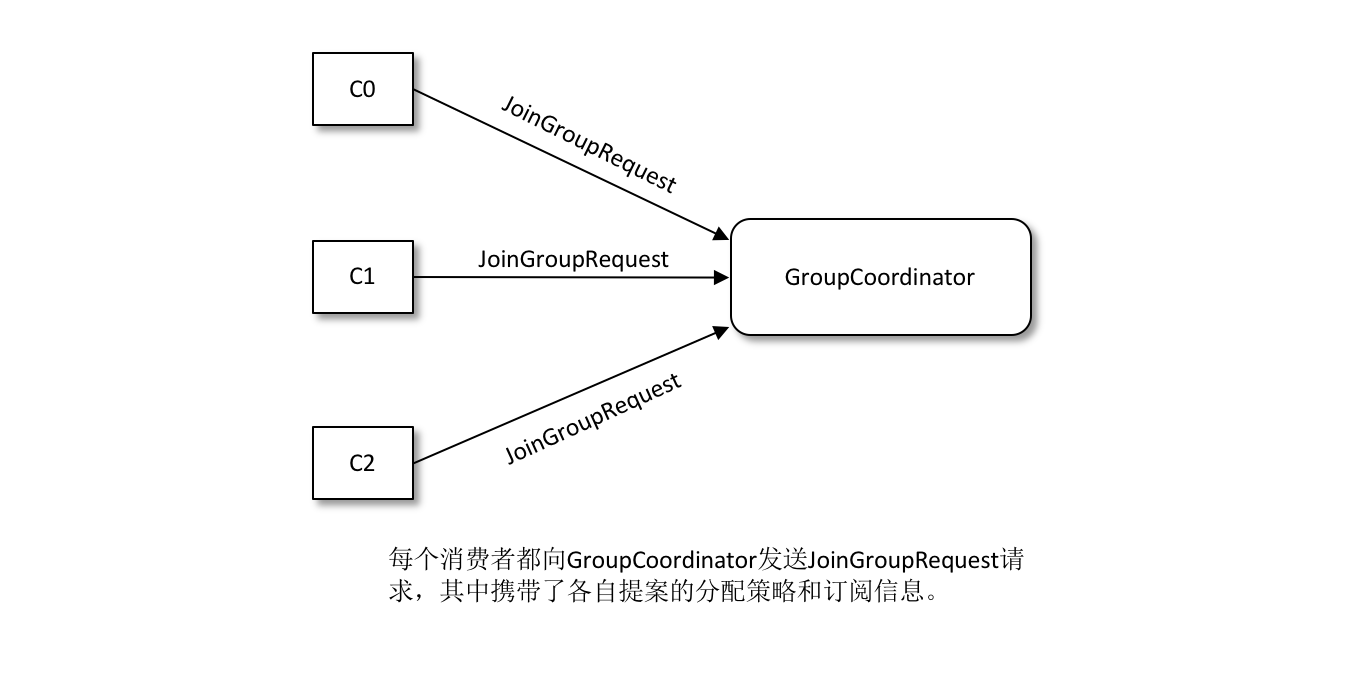
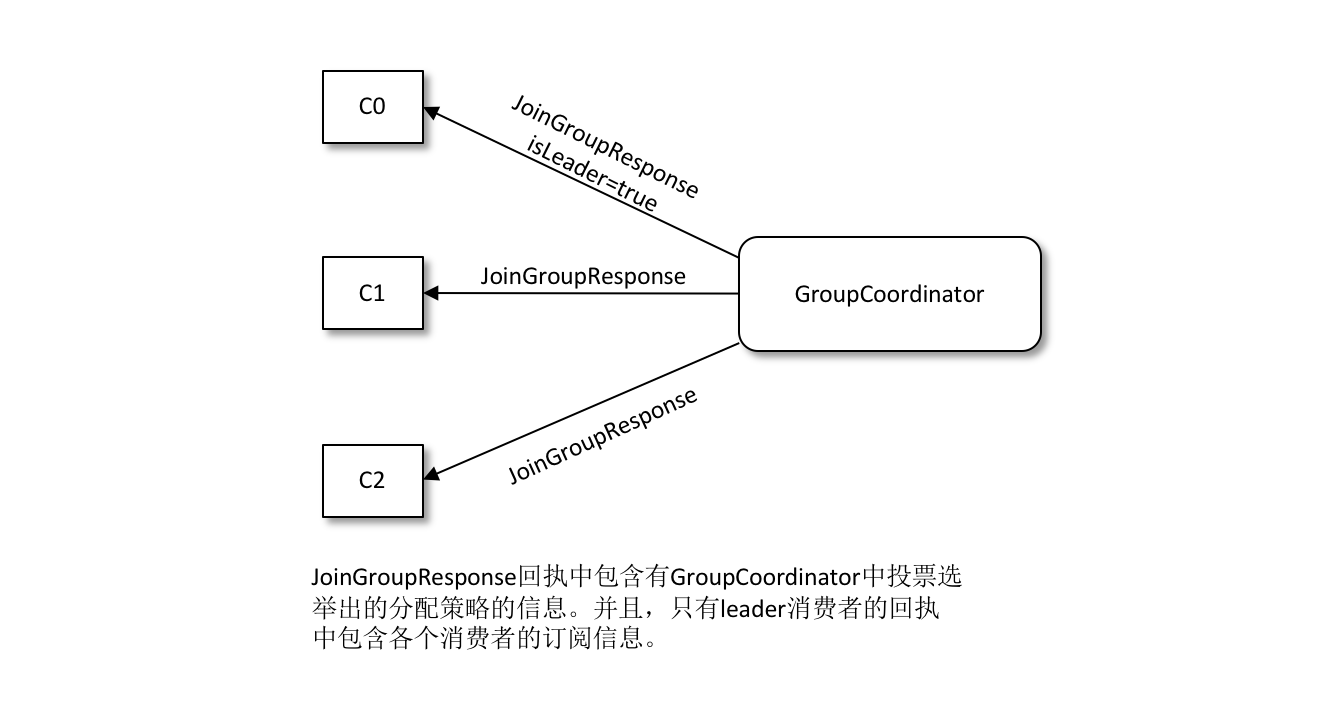
-
Sending a SyncGroup request The coordinator encapsulates the consumer group subscription information in the response body of the JoinGroup request and sends it to the leader, who then sends a SyncGroup request to the coordinator.
-
Responding to a SyncGroup All consumers in the group send a SyncGroup request, except that not the leader’s request content is empty, and then a SyncGroup response is received, accepting the subscription information.