Distributed Systems and the Consistency Problem
The consistency problem is a core problem that needs to be solved in distributed systems. Distributed systems are generally composed of multiple nodes of equal status, and the interaction between the nodes is like several people getting together to discuss a problem. Let’s imagine a more specific scenario, such as three people discussing where to eat at noon, the first person said that a hot pot restaurant has just opened nearby, and I heard that the taste is very good; but the second person said, no, it takes too long to eat hot pot, or just drink some porridge; and the third person said, I just went to that porridge restaurant yesterday, it’s too bad, it’s better to go to McDonalds. As a result, the three people deadlocked, never reached agreement.
Someone said, this is not a bad solution, voting. So the three people voted for a round, the results of each person still adhere to their own proposals, the problem is still not resolved. Someone thought of an idea, why don’t we elect a leader, the leader said anything, we will listen to him, so that we don’t have to fight. The three people finally realized that the issue of “choosing a leader” was still essentially the same as the original issue of “where to eat” and was equally difficult to solve.
At this point, I’m afraid some readers are thinking, “What’s wrong with these three people? …… It’s such a trivial matter as eating a meal, why do they have to fight like this? In fact, without some strictly defined rules and protocols between each node in a distributed system, there is a real possibility that the interaction between them will be like the above scenario. If the whole system does not agree, it will not work at all.
So, there are clever people who have designed consistency protocols (consensus protocol), such as our common ones like Paxos, Raft, Zab and so on. The final goal of the protocol is for each node to reach the same proposal according to certain rules, but whose proposal prevails? One rule that comes to mind is that whichever node makes a proposal first will prevail, and any proposal made later will be invalid.
However, the situation in a distributed system is much more complicated than a few people getting together to discuss the problem, and there is the problem of network latency here. This makes it difficult for X and Y to agree on who is first and who is second, respectively.
The situation is further complicated if we consider the possibility of node downtime and message loss. Node downtime can be seen as a special case of message loss, which is equivalent to the loss of all messages sent to this node. In the theoretical framework of CAP, this is equivalent to network partitioning, which corresponds to the P in CAP. e.g., several nodes are unreachable, i.e., they do not receive any response to the messages sent to them by other nodes. The real reason could be that the middle of the network is down, or that the destination nodes are down, or that the messages are delayed indefinitely. In short, it means that some nodes in the system are out of contact and they can no longer participate in the decision making, but it does not mean that they cannot be reconnected after some time.
To make it more intuitive, let’s assume that some nodes are down. At that time, can the remaining nodes still agree on the proposal without some nodes participating in the decision? Even if they do, after the downed nodes recover (noting that they may not know about the agreed proposals among the other nodes), will they disagree with the agreed proposals again, thus causing confusion? All these are questions that need to be addressed by the distributed consistency protocol.
In fact, it is more important to understand the question itself than the answer to the question.
The Byzantine Generals Problem
In the theory of distributed systems, this problem is abstracted into a well-known problem, the Byzantine Generals Problem (BGP).
The Byzantine Empire sends multiple armies to besiege an enemy army, each with a general, but because of the distance between them, they can only pass messages to each other by messenger. The enemy was so strong that more than half of the Byzantine army had to join the attack in order to defeat the enemy. In the meantime, the generals had to send messages to each other by messenger and then attack at the same point in time after consensus.
Related papers.
The Three Generals’ Dilemma
Suppose there are only three Byzantine generals, A, B and C, and they have to discuss only one thing: whether to attack or retreat tomorrow. To do this, the generals need to vote on the principle of “majority rule”, as long as two of them are in agreement.
For example, if A and B vote to attack and C votes to retreat.
- then the message from A’s messenger to both B and C is to attack.
- the message from B’s messenger to both A and C is attack.
- and the message from C’s messenger to both A and B is retreat.
What if a slight change is made: what if a traitor comes out of the three generals? The traitor’s purpose is to break the agreement between the loyal generals and to make the Byzantine army suffer.
As the traitor C, you will not play the usual cards, so you have a messenger tell A that you “want to attack”, and another messenger tell B that you “want to retreat”.
At this point, General A sees the vote as: Attacker : Retreater = 2 : 1, while General B sees 1 : 2. The next day, the loyal A rushed to the battlefield, but found that only one of their own army launched the attack, while the same loyal B, but has long retreated. Eventually, A’s army loses to the enemy.
Raft’s algorithm is based on the premise that no malicious nodes exist in order to reach agreement . Otherwise, these famous algorithms would then fail.
Starting with a Counter example
Requirements
Provide a Counter where the Client can specify the step size each time it counts, and can also initiate a query at any time.
This seemingly simple requirement has three main functional points.
- Implementation: Counter server, with counting function, with the specific formula: Cn = Cn-1 + delta.
- Provide write service, write delta to trigger the counter operation.
- Provide a read service, which reads the current Cn value.
In addition, we have an optional requirement of availability, we need to have backup machines, and the read and write services cannot be unavailable.
System architecture 1.0
Based on the functional requirements just analyzed, we design the architecture of 1.0, which is very simple. A node Counter Server provides the counting function and receives counting requests and query requests from clients.
However, there are two problems with such an architecture: first, the Server is a single point, and once the Server node fails, the service is unavailable; second, the results are stored in memory, and node failure will lead to data loss.
System Architecture 1.5
For problem 1, we have to start a new standby machine when the node fails. For problem 2, we optimize it by adding a local file store. This will store the data to disk after each counter completes its operation.
But it also leads to another problem: disk IO is very frequent, and this cold standby mode still leads to a period of service unavailability.
System Architecture 2.0
Since the above problems can no longer be solved by just adding machines, we propose Architecture 2.0, which uses a cluster model to provide services. We use three nodes to form a cluster, and one node provides the service to the outside world. When the Server receives a write request from the Client, the Server computes the result and then copies the result to the other two machines, and after receiving successful responses from all the other nodes, the Server returns the computation result to the Client.
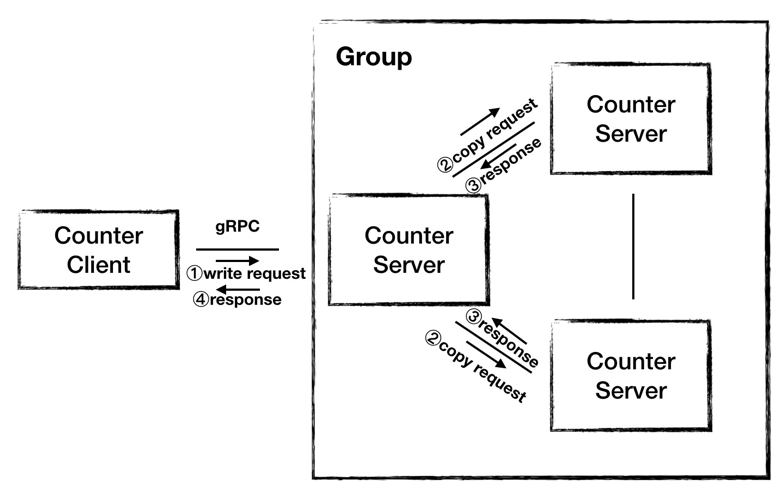
But there is a problem with this architecture: * We choose which Server plays the role of the Leader.
- Which Server we choose to play the role of Leader to provide services to the public;
- Which Server we choose to take over the role of Leader when it becomes unavailable;
- When the Leader is not available, which one will take over?
- The Leader needs to wait until all nodes respond before responding to the Client when processing write requests.
- It is also important that we cannot guarantee that the data replication from Leader to Follower is in order, so the data of the three nodes may be different at any moment.
So to ensure the order and content of the replicated data, this is where the consensus algorithm comes in handy, and we use SOFAJRaft to build our 3.0 architecture.
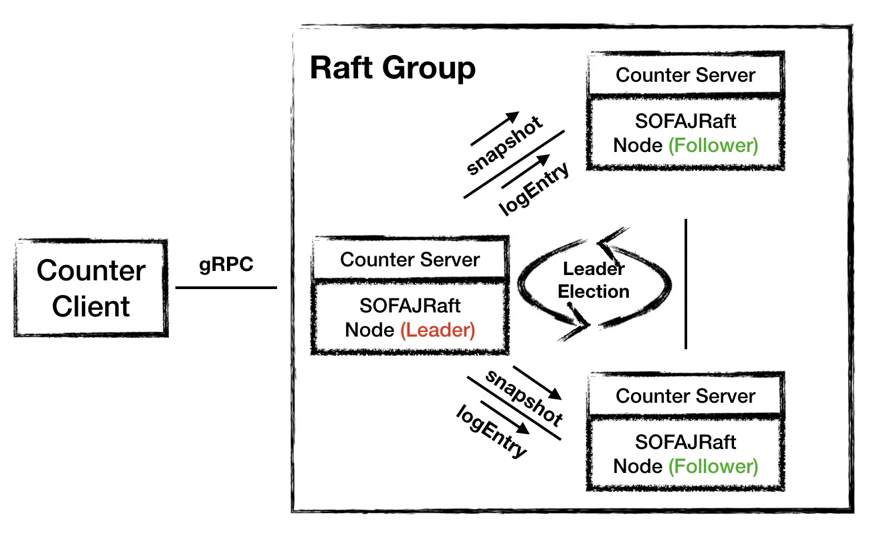
System Architecture 3.0
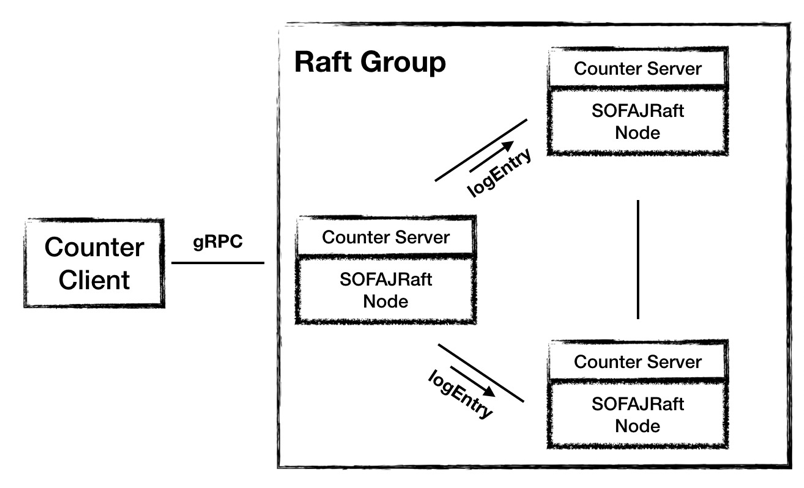
In the 3.0 architecture, Counter Server uses SOFAJRaft to form a cluster, and the election of Leaders and replication of data are left to SOFAJRaft.
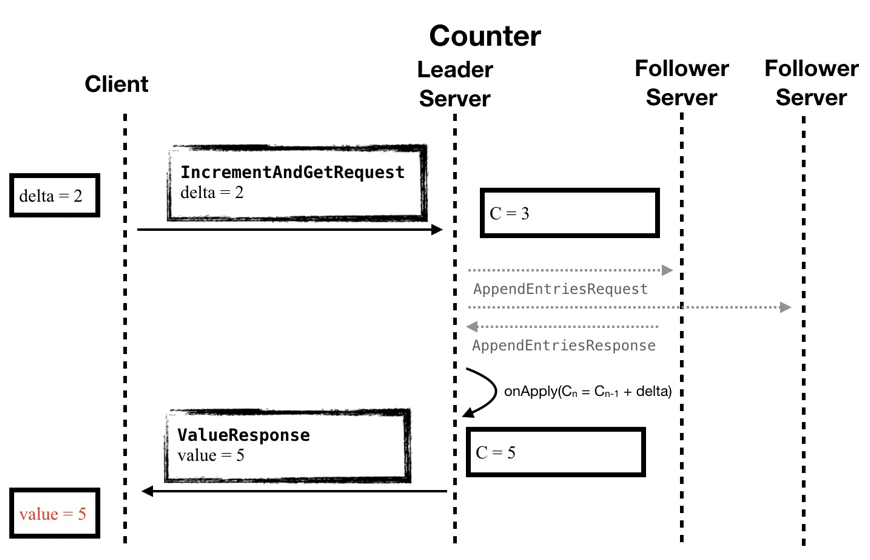
In the timing diagram, we can see that the business logic of Counter has become as simple as in architecture 1.0, and the work of maintaining consistent data is left to SOFAJRaft, so the gray part of the diagram is not business-aware.
In the 3.0 architecture using SOFAJRaft, SOFAJRaft helps us to finish the work of Leader election and data synchronization between nodes, in addition, SOFAJRaft only needs more than half of the nodes to respond, and no longer needs all nodes of the cluster to answer, which can further improve the processing efficiency of write requests.
Raft Consensus Algorithm
Small paper: “In Search of an Understandable consensus Algorithm”
Large paper: “Consensus: Bridging theory and practice”
Raft is a consensus algorithm characterized by allowing multiple participants to reach complete agreement on a single thing: one thing, one conclusion. At the same time, the agreed conclusions are irreversible. To explain the consensus algorithm, let’s take an example of a bank account: if a cluster of servers maintains a bank account system, and a Client issues a command to the cluster to “deposit $100”, then when the cluster returns a successful answer, the Client will be able to query the cluster again and will be able to Even if a machine is unavailable, the $100 account cannot be tampered with. This is what the consensus algorithm aims to achieve.
Basic concepts in Raft
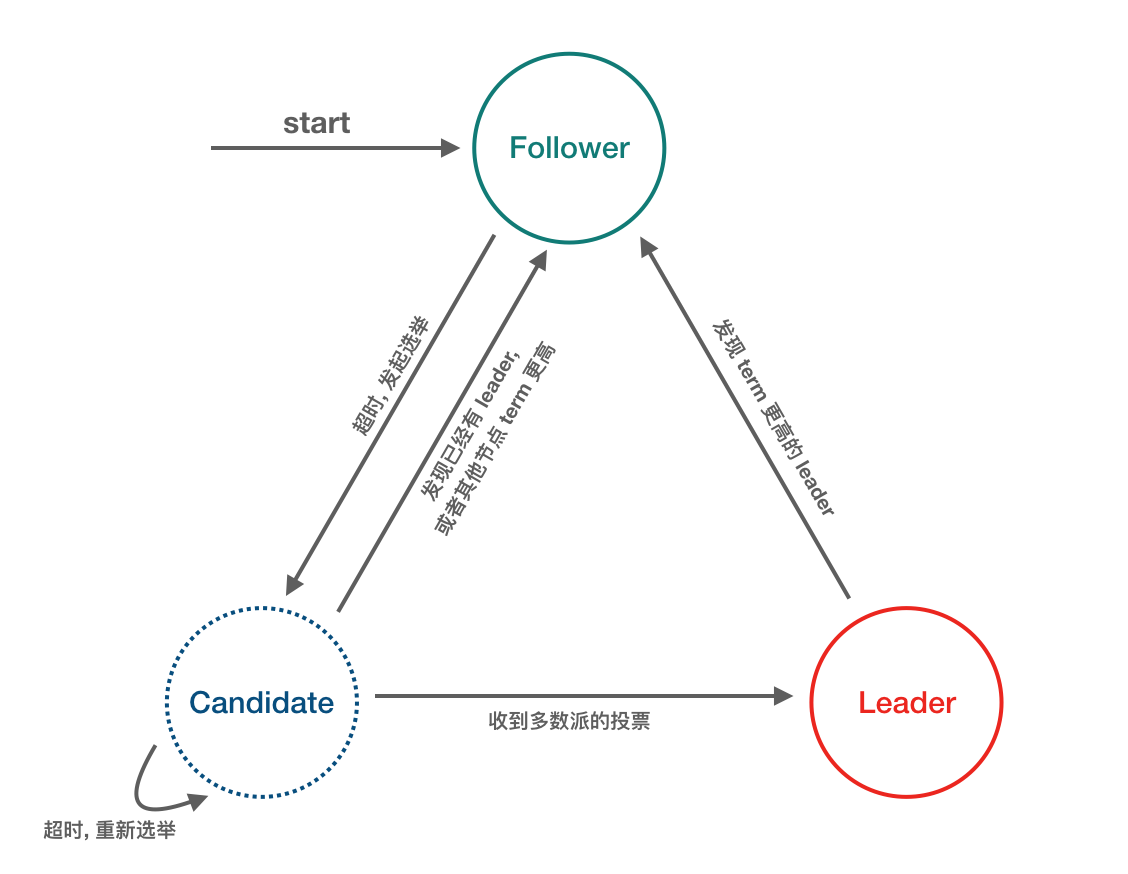
3 Roles/states of Raft-node
There are three types of roles in a cluster organized by the Raft protocol.
- Leader
- Follower
- Candidate
Just like a democratic society, the leader is elected by popular vote. At the beginning there is no leader, all the participants in the cluster are the masses, then first a general election is opened, during the election all the masses can participate in the election, then the role of all the masses becomes the candidates, after the democratic vote to elect the leader begins the term of the leader, then the election is over, all the candidates except the leader return to the role of the masses to obey the leader. Here is a concept called “term of office”, which is expressed in the term Term.
3 types of Message
- RequestVote RPC: sent by Candidate, used to send poll requests.
- AppendEntries (Heartbeat) RPC: sent by the Leader, used to copy log entries from the Leader to the Followers, also used as Heartbeat (an empty log entry is a Heartbeat).
- InstallSnapshot RPC: issued by the Leader, used for snapshot transfer, although in most cases each server creates snapshots independently, the Leader sometimes has to send snapshots to some Follower that is too far behind, which usually happens when the Leader has discarded the next log entry to be sent to that Follower ( This usually happens when the Leader has already discarded the next log entry to be sent to that Follower (cleared out during Log Compaction).
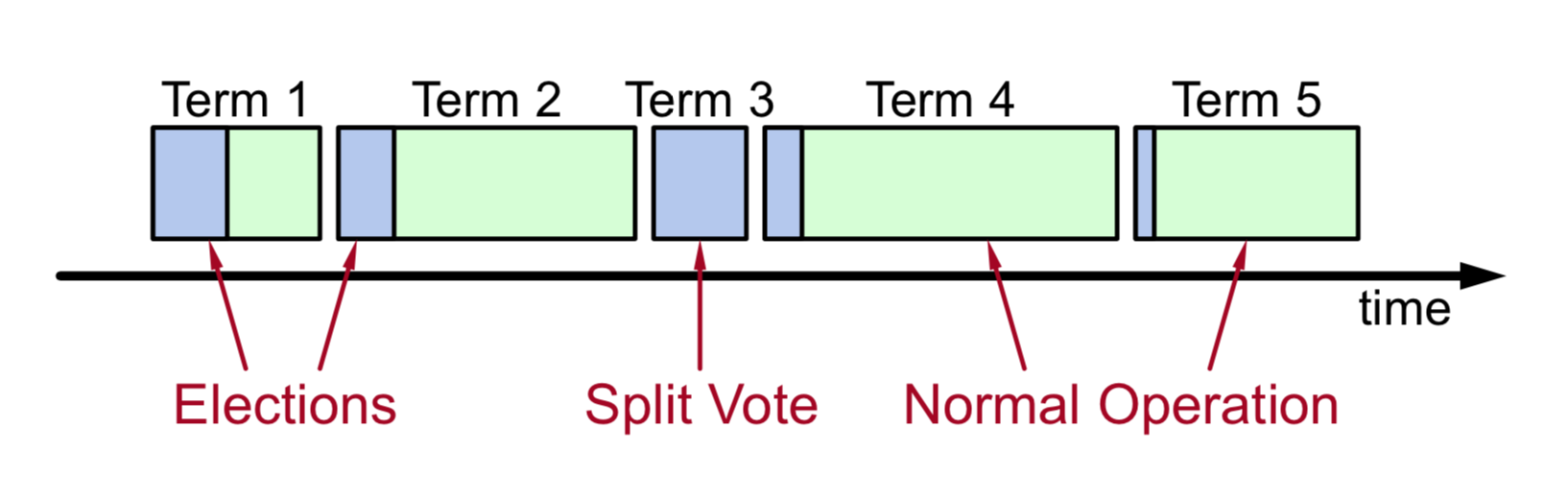
Term Logical Clock
- time is divided into terms, with term ids increasing monotonically on the timeline.
- each term starts with a Leader election, after which the Leader manages the entire cluster for the duration of the term, i.e. “election + routine operations “;
- at most one Leader per term, there may be no Leader (due to spilt-vote).
Leader election
Election steps
The following steps are extracted from the paper for illustration.
- When servers start up, they begin as followers
- If a follower receives no communication over a period of time called the election timeout , then it assumes there is no viable leader and begins an election to choose a new leader
- To begin an election, a follower increments its current term and transitions to candidate state
- then votes for itself and issues RequestVote RPCs in parallel to each of the other servers in the cluster.
- A candidate wins an election if it receives votes from a majority of the servers in the full cluster for the same term
- Once a candidate wins an election, it becomes leader
- a candidate may receive an AppendEntries RPC
- If the leader’s term is at least as large as the candidate’s current term, then the candidate recognizes the leader as legitimate and returns to follower state
- If the term in the RPC is smaller than the candidate’s current term, then the candidate rejects the RPC and continues in candidate state
vote split
if many followers become candidates at the same time, votes could be split so that no candidate obtains a majority. When this happens, each candidate will time out and start a new election by incrementing its term and initiating another round of RequestVote RPCs.
Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly.
Here’s an example to illustrate the election process
What the election is trying to solve
A distributed cluster can be thought of as a fleet of ships that communicate with each other by means of semaphore. In such a fleet, the ships are neither completely isolated from each other, but neither can they maintain very close contact as they do on land; weather, sea conditions, ship spacing, and ship battle damage cause contact between ships to exist but be unreliable.
The fleet as a unified combat cluster needs to have a unified consensus and consistent orders, all of which depend on the flagship command. Each ship has to obey the orders issued by the flagship, and when the flagship can no longer work, another warship needs to take over the role of the flagship.
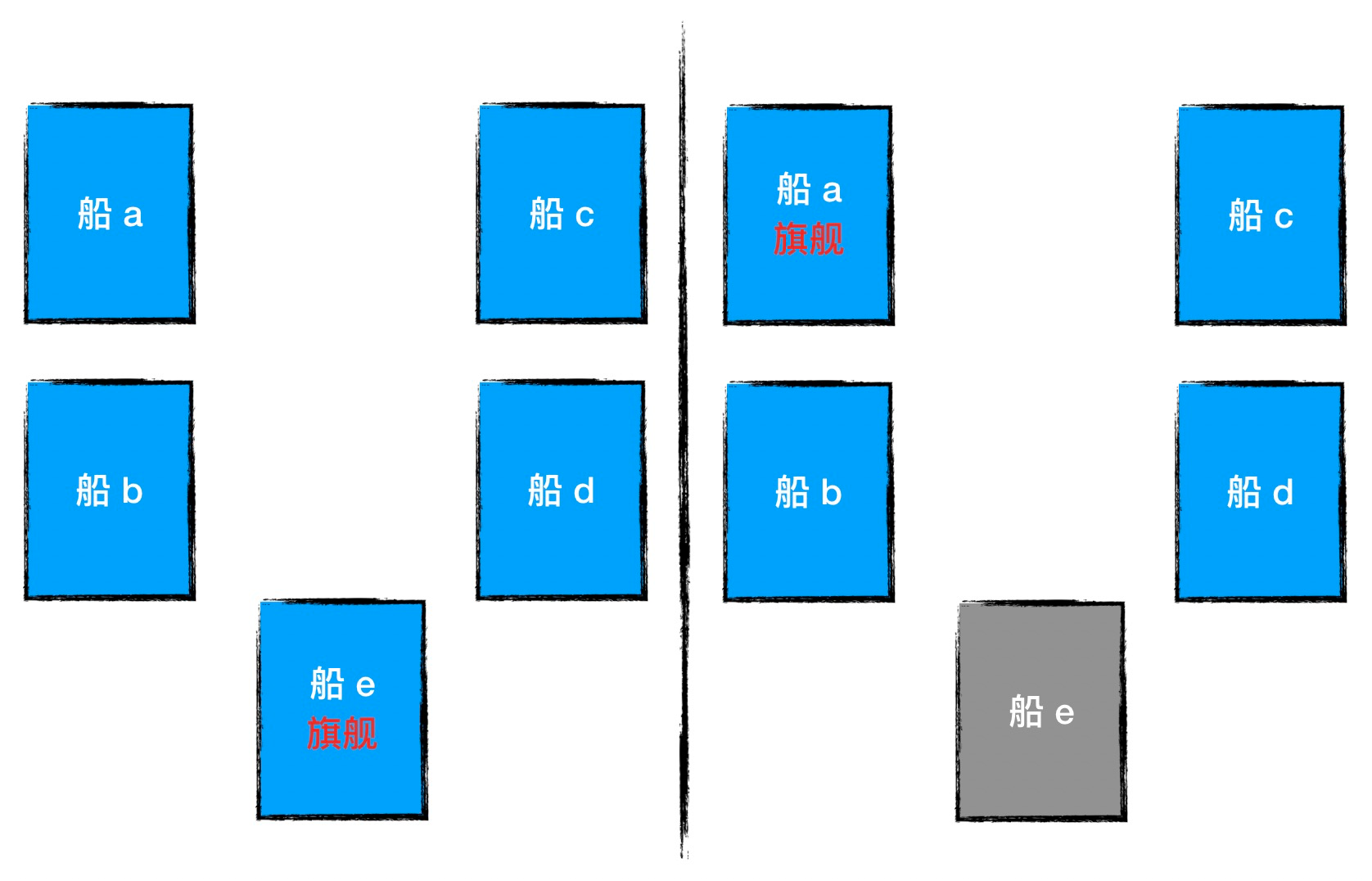
How to choose a flagship that is recognized by everyone in the fleet is the problem that the election in SOFAJRaft will solve.
When an election can be initiated
In SOFAJRaft, the trigger criterion is the communication timeout. When the flagship does not communicate with the Follower ship for a specified period of time, the Follower can assume that the flagship is no longer able to perform the flagship duties properly, and the Follower can try to take over the role of the flagship. This communication timeout is called Election Timeout (ET), and the Follower’s attempt to take over the flagship is also known as initiating an election request.
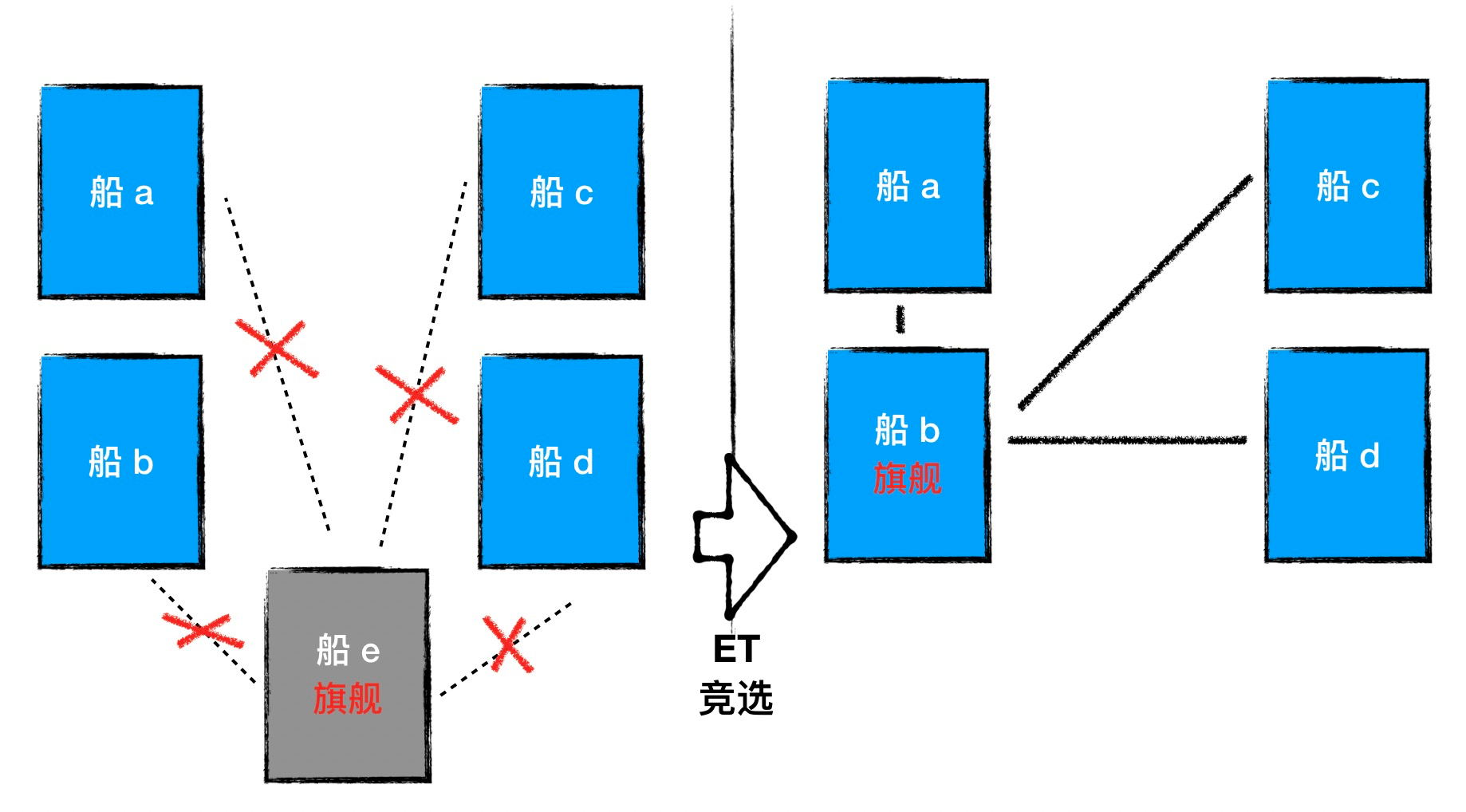
When to actually initiate an election
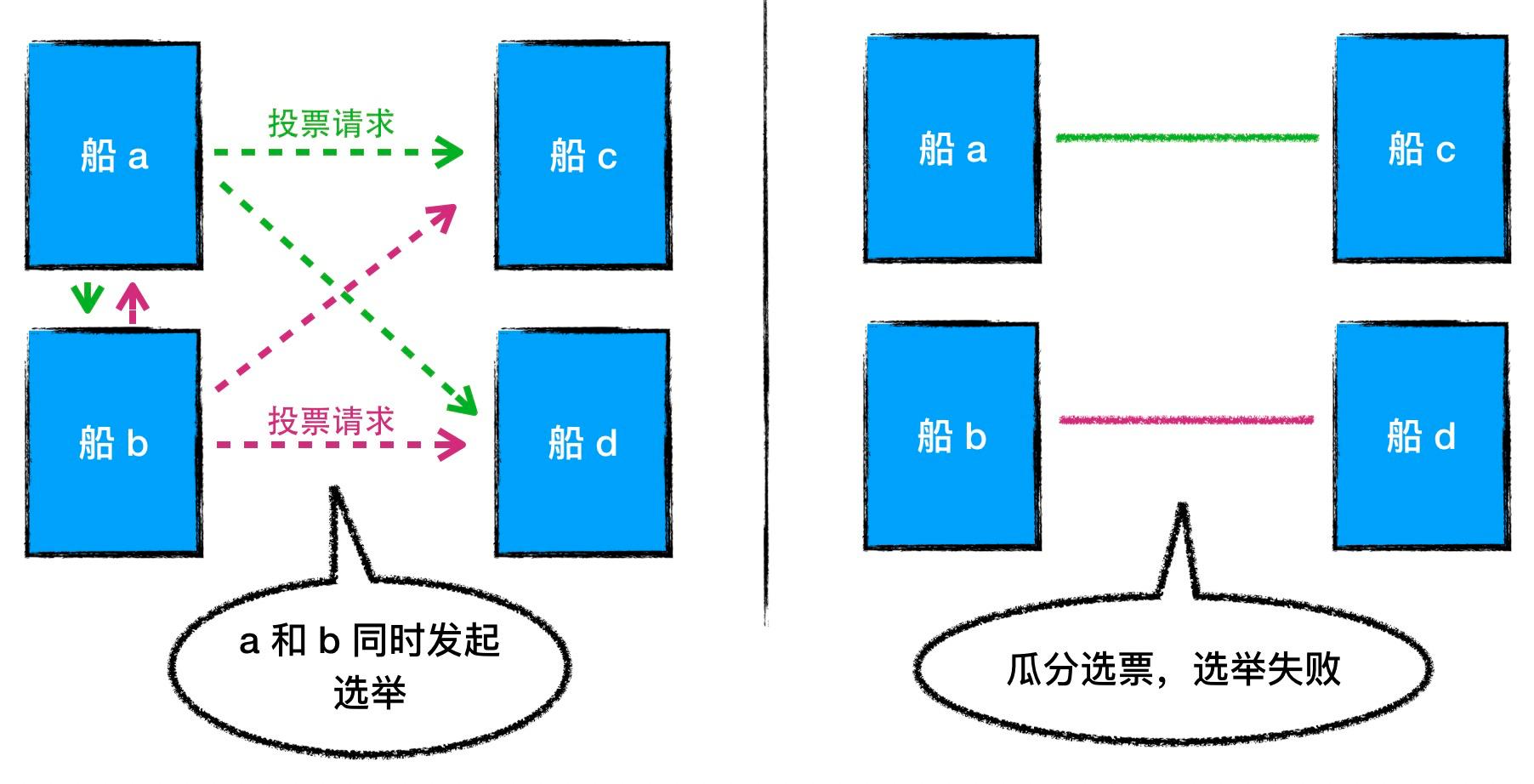
In an election, the ship that initiated the election can only become the flagship if more than half the ships in the fleet agree, otherwise a new round of elections has to be started. So if Follower takes the strategy of starting the election as soon as possible, trying to choose the available flagship for the fleet as soon as possible, there is a potential risk that multiple ships may start the election almost at the same time, and as a result, none of them will get more than half of the votes, resulting in a fruitless round of election, which is called vote split above.
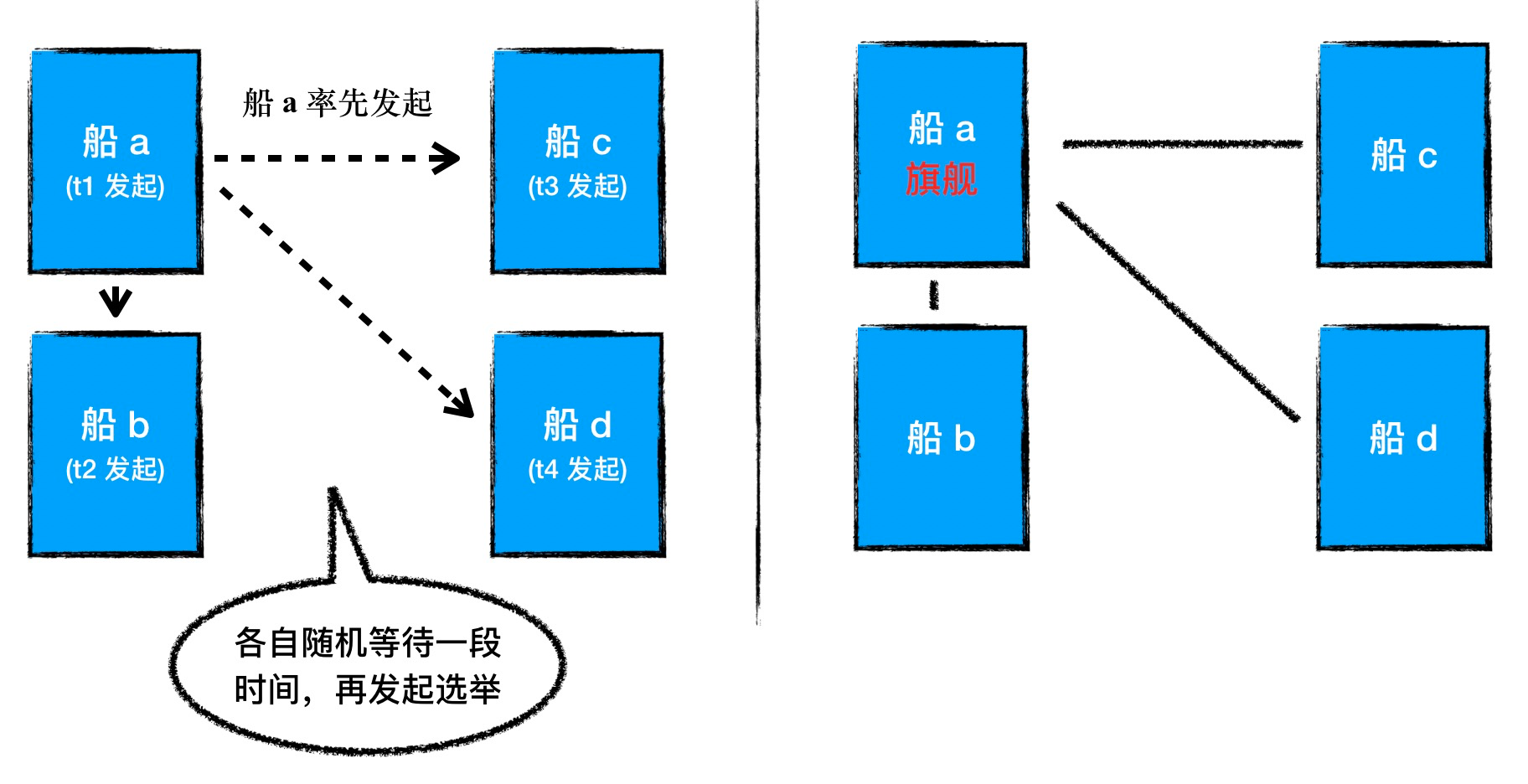
To avoid this, we use a random election trigger time. When Follower finds that the flagship is lost, it will choose to wait for a random period of time Random(0, ET), and if no flagship is elected during the waiting period, then Follower will initiate the election again.
Which candidates deserve votes
SOFAJRaft’s election contains judgments on two attributes: LogIndex and Term, which is the core part of the whole election algorithm.
- Term: we will number the history of flagships in the fleet, such as the 1st flagship and 2nd flagship of the fleet, and this number we will use Term to represent. Since there can only be at most one ship in the fleet as flagship at the same time, each Term belongs to only one ship, and obviously Term is monotonically increasing.
- LogIndex: Each flagship will issue some orders (called “flagship orders”, analogous to “presidential orders”) during its term of office, and these flagship orders should be numbered and filed. This number is identified by two dimensions, Term and LogIndex, and means “LogIndex of the flagship issued by the Term flagship”. Unlike real presidential decrees, the LogIndex of our flagship decrees is always incremental and does not start from the beginning when the flagship changes.
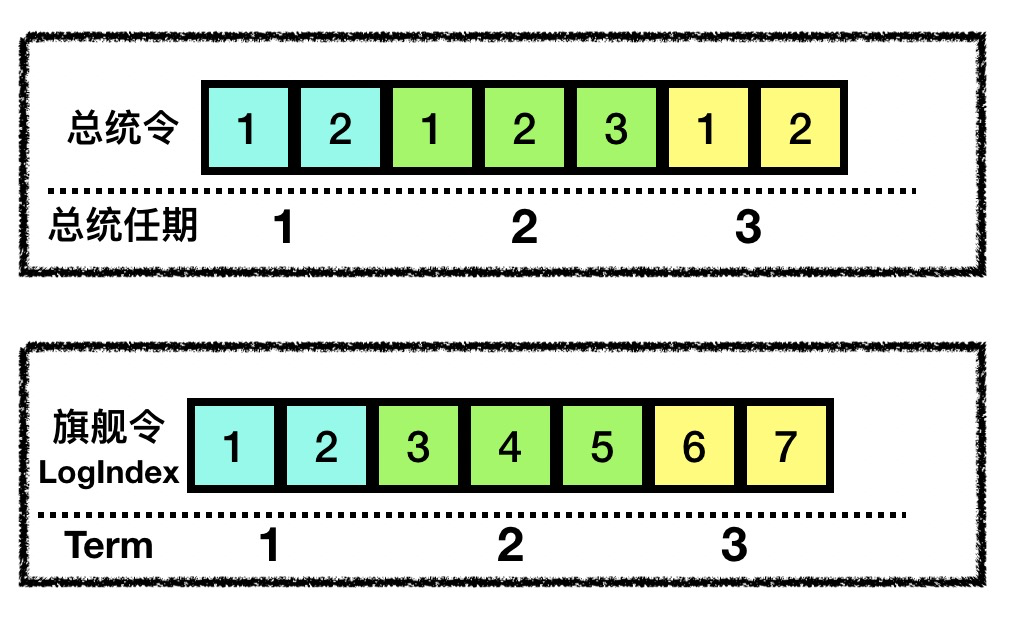
Specifically, a voting ship V will not vote for either candidate C: one where lastTermC < lastTermV; or (lastTermV == lastTermC) && (lastLogIndexV > lastLogIndexC).
The first case means that the last flagship that candidate C communicated with is no longer the latest flagship; the second case means that although both C and V have communicated with the same flagship, the flagship order that candidate C received from the flagship is not as complete as V (lastLogIndexV > lastLogIndexC), so V will not vote for it.
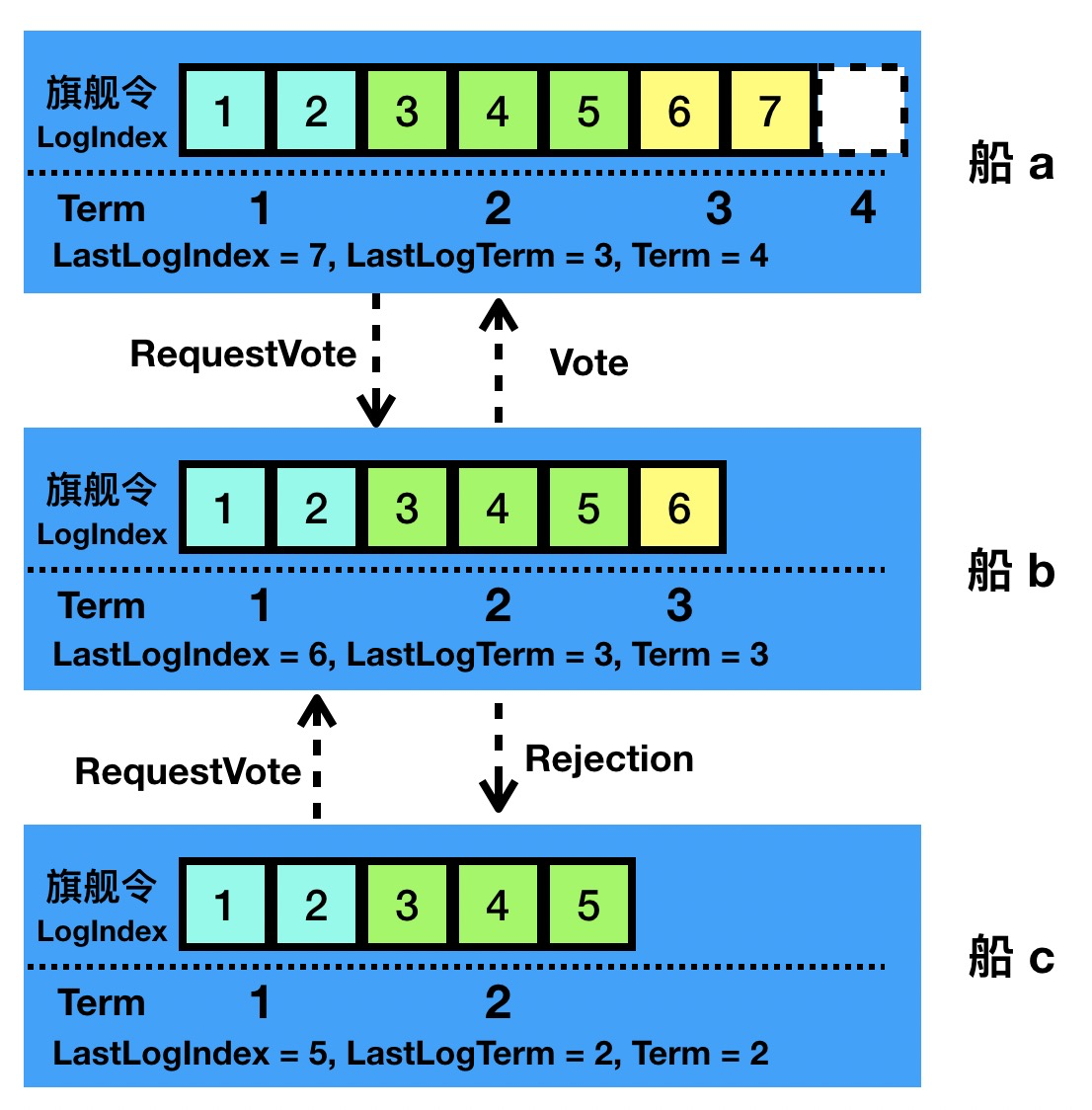
When does step down happen
A step down can occur in a Candidate that has fallen back to Follower, or in a Leader that has fallen back to Follower. If the Candidate is a Leader, then the Candidate abandons the race for the current Leader, and if the Leader is a Follower, then the Candidate reverts to the Follower state and reopens the election.
The Candidate will step down to Follower in the following two cases:
- if the Candidate receives a poll request from another Server with a higher Term while the Candidate is waiting for the Servers’ poll results.
- if a heartbeat from another Server with a higher Term is received while Candidate is waiting for the voting result of Servers.
And for Leader, it will also fall back to Follower state when a Leader with higher Term is found.
How to avoid “spoilers” from underqualified candidates
SOFAJRaft uses LogIndex and Term as selection criteria for elections, so before a ship initiates an election, it increments its own Term and sends it to the other ships in an election request (possibly with a complex semaphore), indicating that it is running for the “Term + 1” flagship.
There is a mechanism that is used to keep the Term increments of each ship synchronized: when the voting Follower ships receive the poll request, they will update their Term to match the candidate if they find their Term is smaller than the one in the poll request, which makes it easy to synchronize the Term increments to the whole fleet.
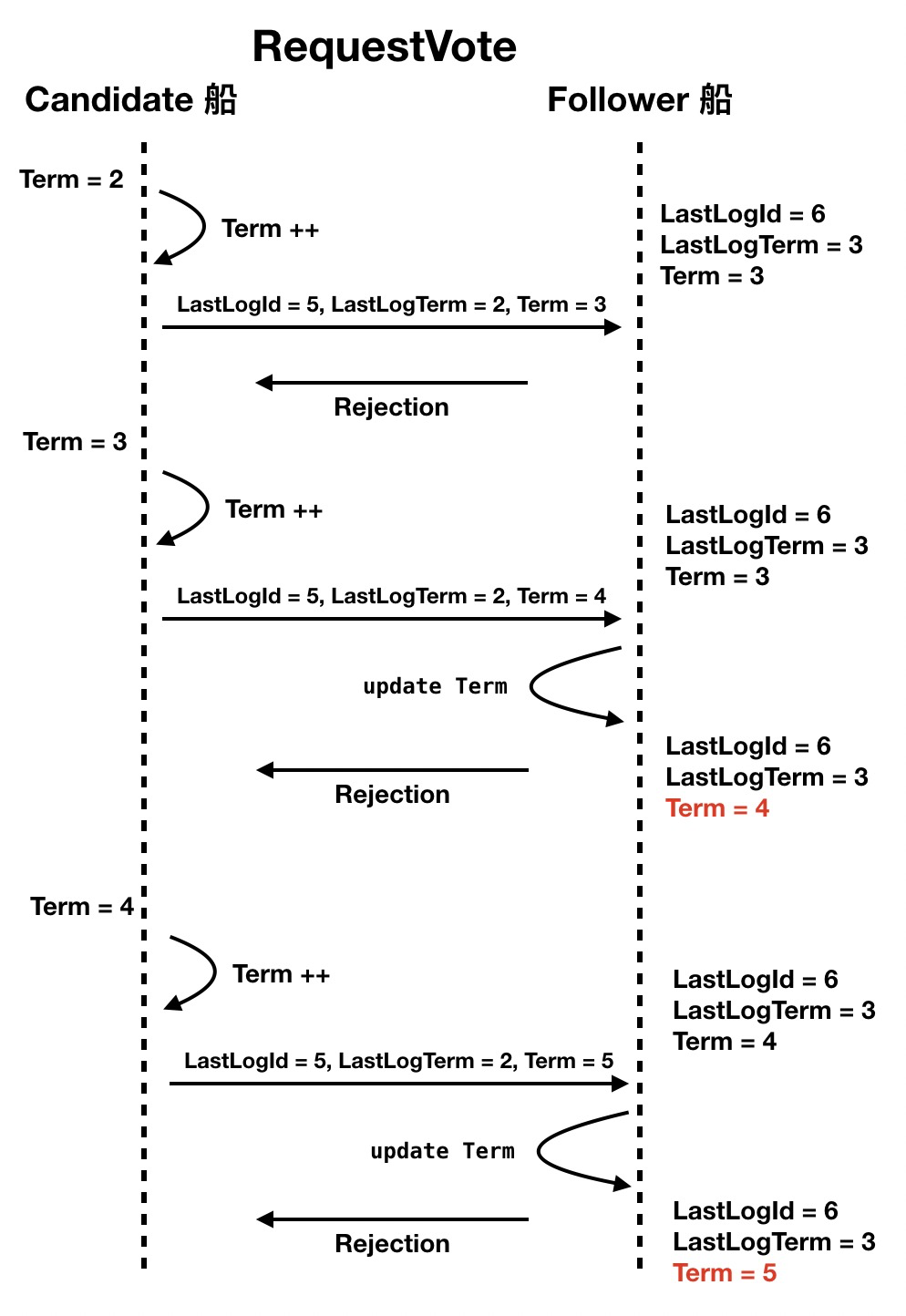
But this mechanism also poses a problem. If a ship does not see the flagship’s semaphore for its own reasons, it will presumptuously try to run to become the new flagship, and although it keeps initiating elections and never gets elected (because the flagship and other ships are communicating normally), it actually raises the global Term by its own vote request, which in the SOFAJRaft algorithm will force the flagship to stepdown (step back from the flagship position).
So we need a mechanism to stop this “disruption”, which is the pre-vote loop. If a candidate does not receive feedback from more than half of the nodes, the candidate will have the sense to drop out of the race and will not raise the global Term.
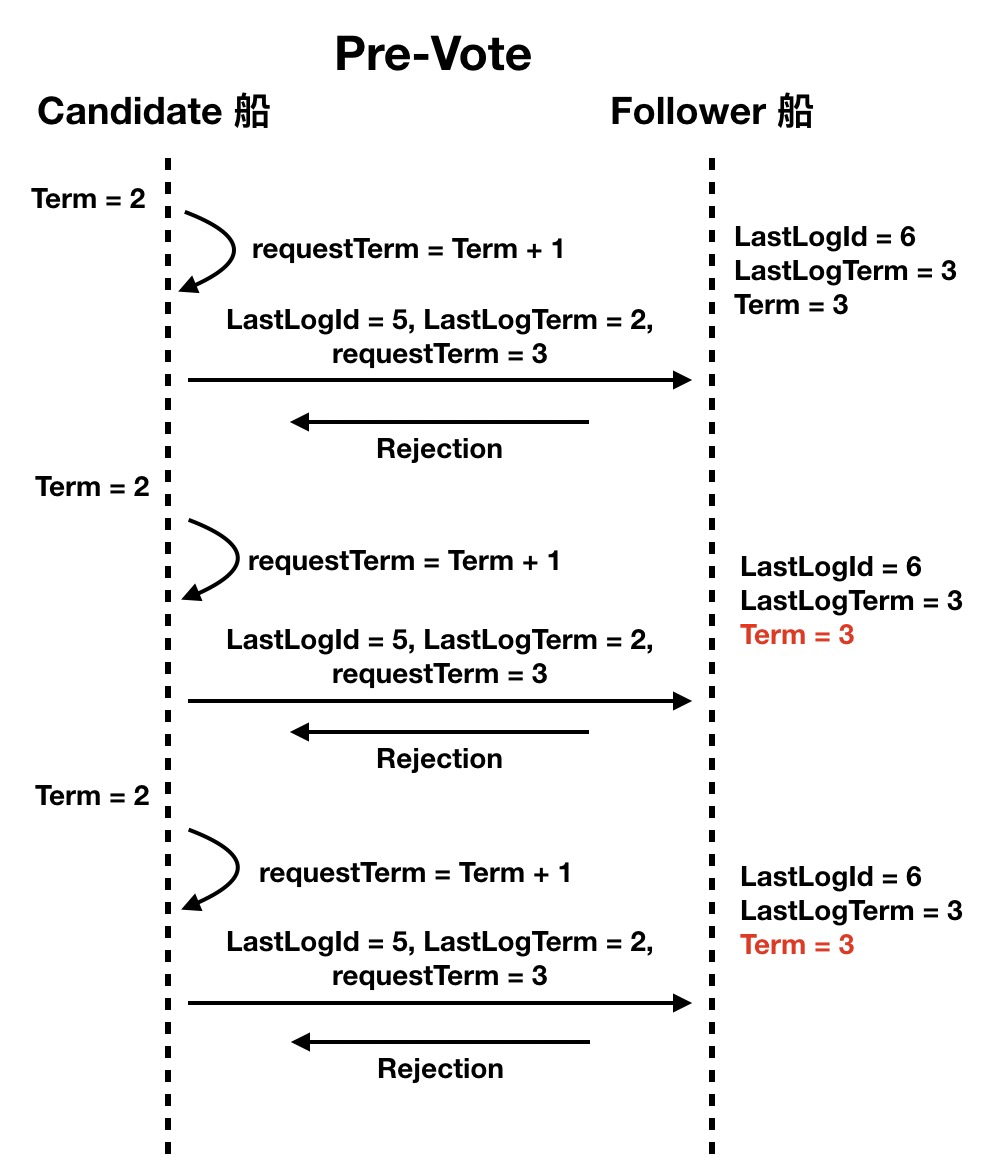
In the above analogy, we can see that the main tasks of the whole election operation are:
- Candidate is triggered by ET
- Candidate starts to try to initiate a pre-vote pre-vote
- Follower decides whether to approve the pre-vote request
- Candidate decides whether to send RequestVoteRequest based on the pre-vote response
- Follower determines whether to approve the RequestVoteRequest
- Candidate decides if he is elected based on the response
Log replication
-
Leaders provide services to the public
Once a leader has been elected, it begins servicing client requests. Each client request contains a command to be executed by the replicated state machines.
-
leader execution log replication
The leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry.
-
Log replication success
When the entry has been safely replicated (as described below), the leader applies the entry to its state machine and returns the result of that execution to the client.
-
Log replication failure
Another situation in which Follower fails is the following.
If followers crash or run slowly, or if network packets are lost, the leader retries AppendEntries RPCs indefinitely (even after it has responded to the client) until all followers eventually store all log entries.
LogEntry
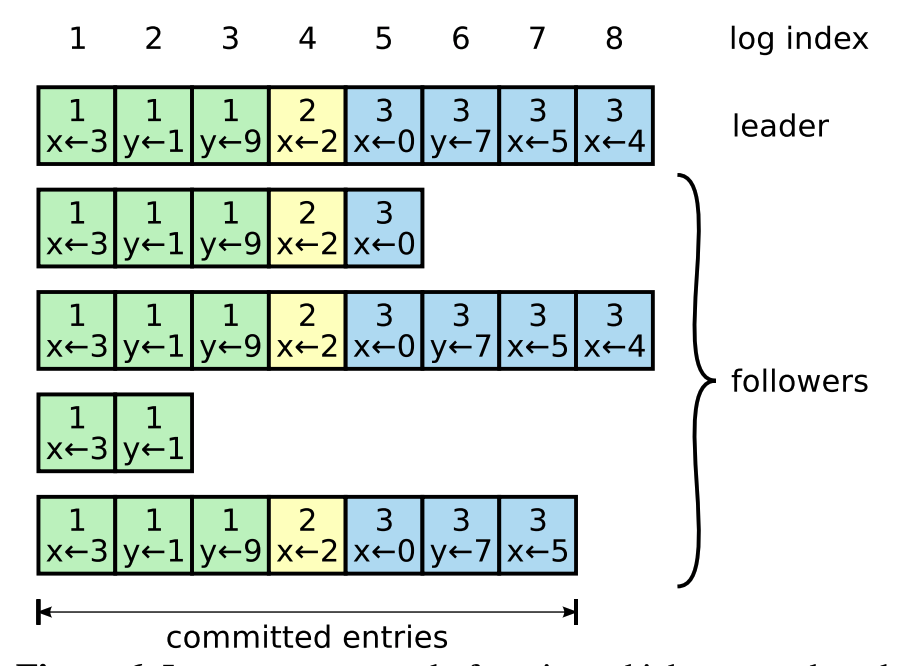
As shown in the figure above, each square represents a LogEntry, you can see that Log is composed of one LogEntry, ideally the array is consistent on all instances. log elements are further divided into uncommitted and committed depending on their status. Only the committed LogEntry will return a successful client write.
The top row is the log index, which is the subscript value, monotonically increasing and continuous. The number in the square represents the term term.
committed entry:A log entry is committed once the leader that created the entry has replicated it on a majority of the servers
This means that a log is only considered a committed log if it is replicated to most of the nodes.
Once a follower learns that a log entry is committed, it applies the entry to its local state machine (in log order).
Once Follower learns that this LogEntry has been committed, then it will put this LogEntry into the state machine for execution.
Follower log inconsistency
In general, the logs of the Leader and Follower are consistent, but in reality the Leader is not guaranteed not to crash, so the logs may be inconsistent as shown below.
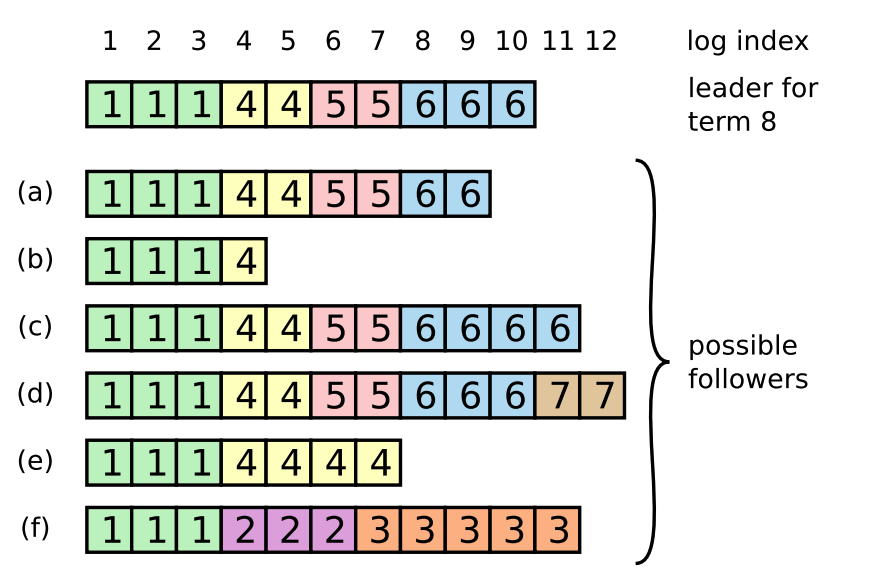
As shown above, Follower may have less logs than Leader, may have redundant logs, and may both lose logs and have redundant logs.
So Raft needs to do these things with the consistency of the logs.
-
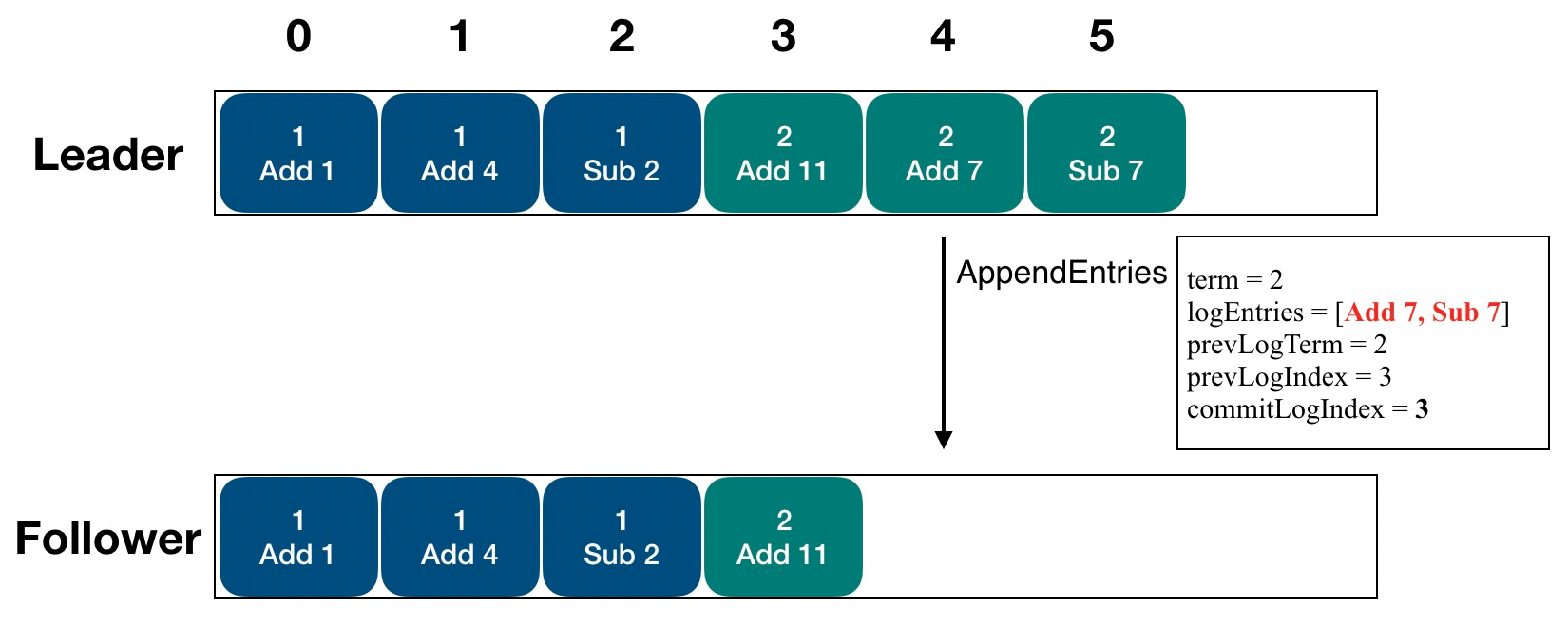
consistency check
Since the leader will bring index and term when sending LogEntry, Follower has to check whether this LogEntry is continuous with the previous log after receiving it, so Follower will reject the replication request that cannot be continuous with the existing local log. In this case, we need to go through the Log recovery process.
-
find the latest log entry
If it is not consistent, then you need to find the log that is recognized by both Leader and Follower, which must be continuous in Follower and exist in Leader, as follows.
- The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower.
- When a leader first comes to power, it initializes all nextIndex values to the index just after the last one in its log.
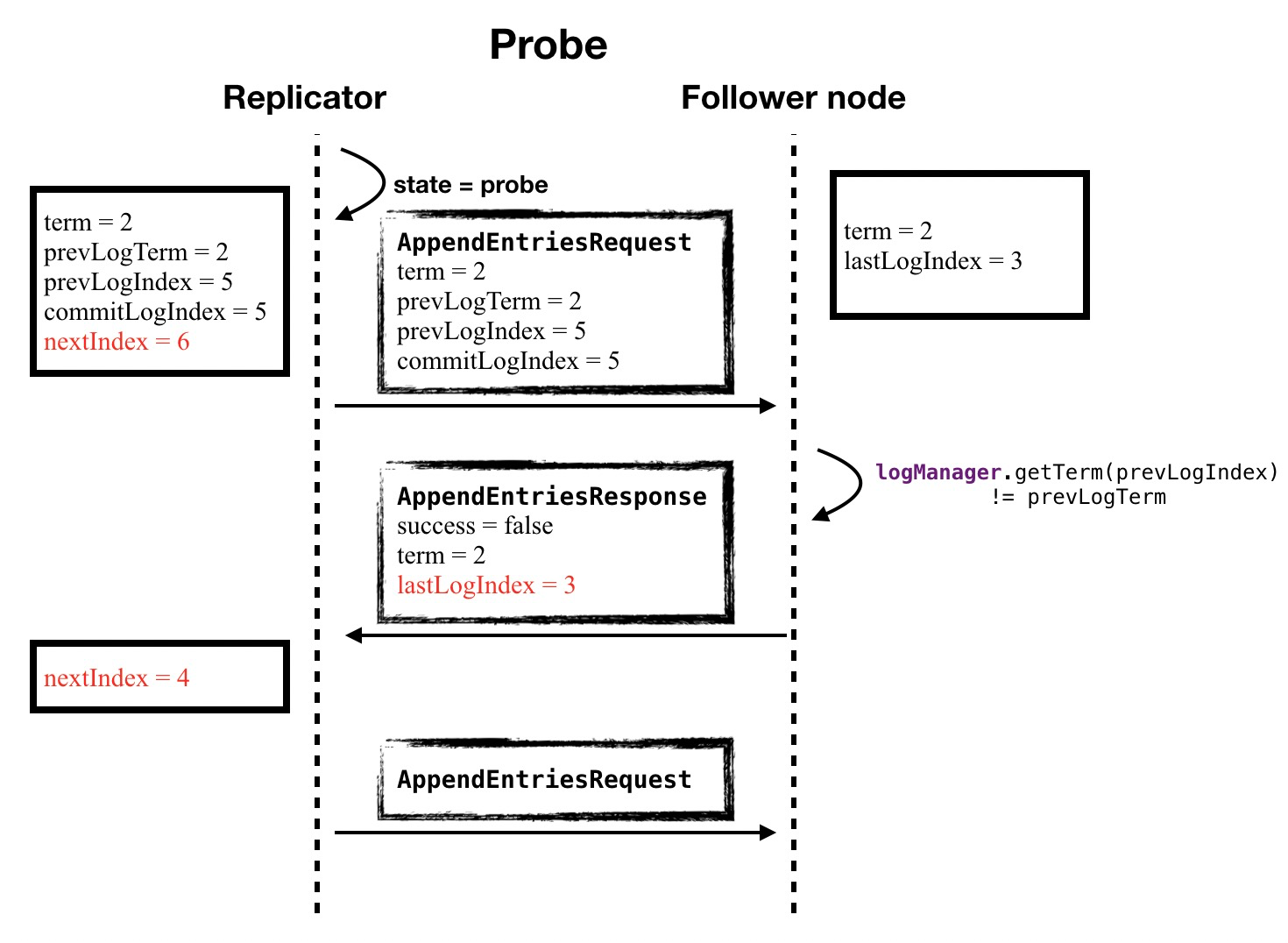
- After the Leader node establishes a connection with Follower via Replicator, it sends a Probe request of type Probe to know the location of the logs already owned by Follower.
- If a follower’s log is inconsistent with the leader’s, the AppendEntries consistency check will fail in the next AppendEntries RPC. After a rejection, the leader decrements nextIndex and retries the AppendEntries RPC. Eventually nextIndex will reach a point where the leader and follower logs match.
- Eventually nextIndex will reach a point where the leader and follower logs match. When this happens, AppendEntries will succeed, which removes any conflicting entries in the follower’s log and appends entries from the leader’s log
Here are the details of log replication in JRaft
The replicated logs are ordered and continuous
When SOFAJRaft replicates logs, the order of log transfers must be strictly sequential, and all logs must not be out of order or have gaps (i.e. they cannot be missed).
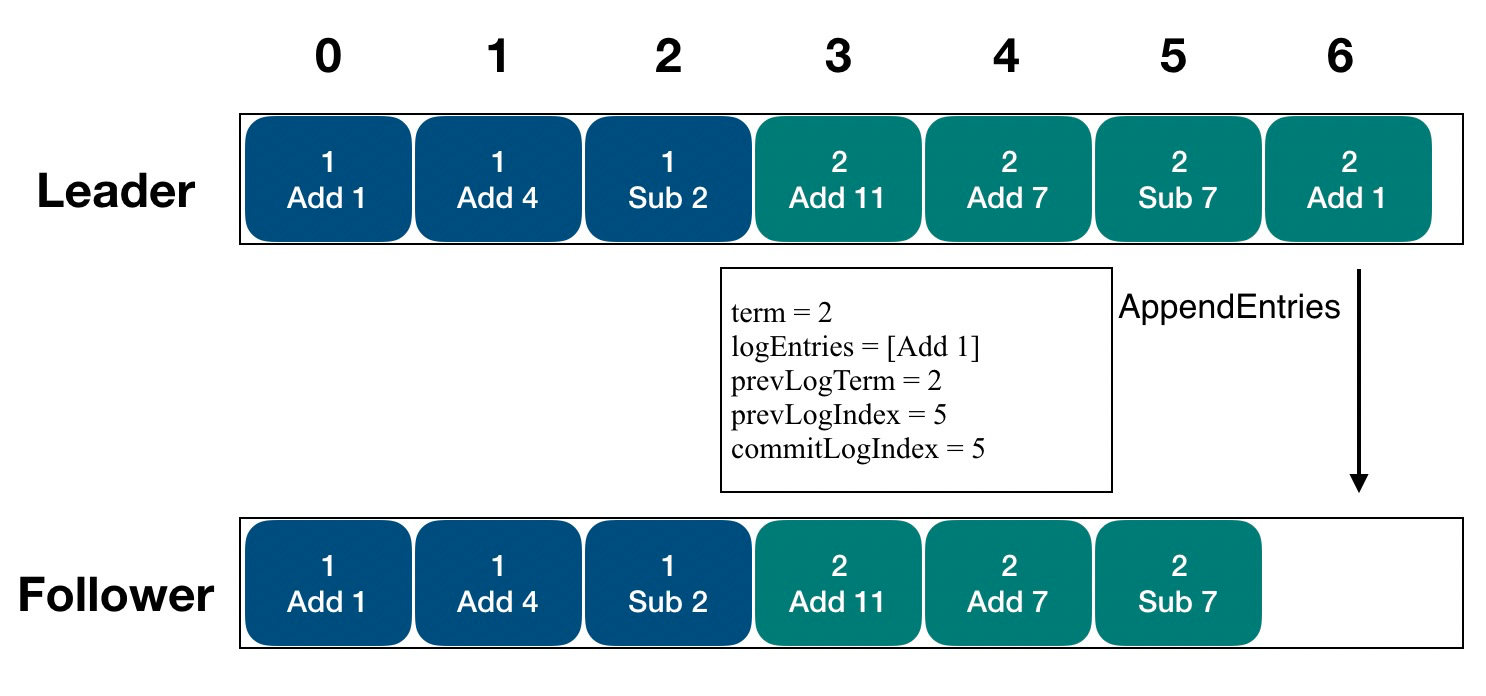
Replicated logs are concurrent
The Leader node in SOFAJRaft replicates logs to multiple Follower nodes simultaneously, and a Replicator is assigned to each Follower in the Leader to handle the replication log task exclusively.
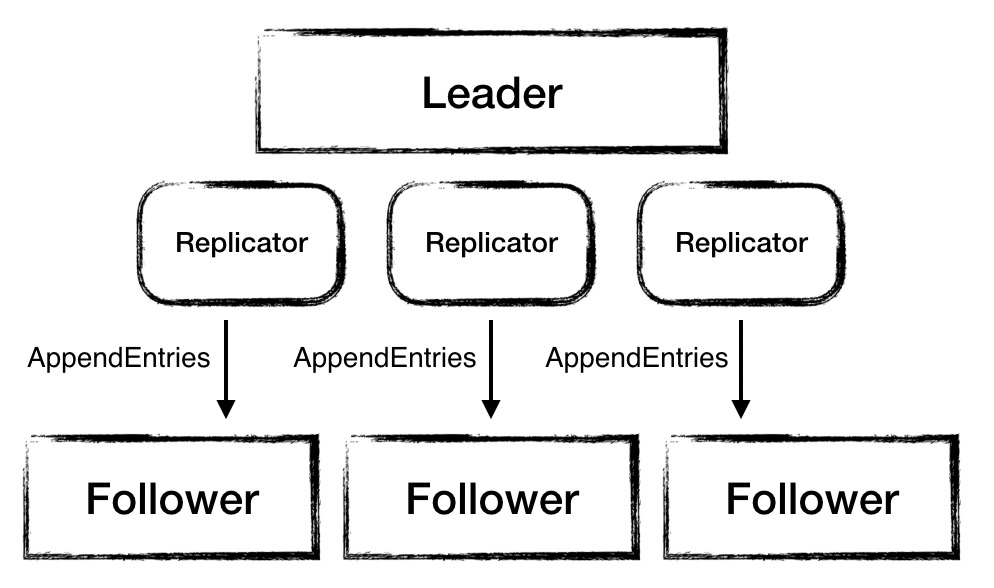
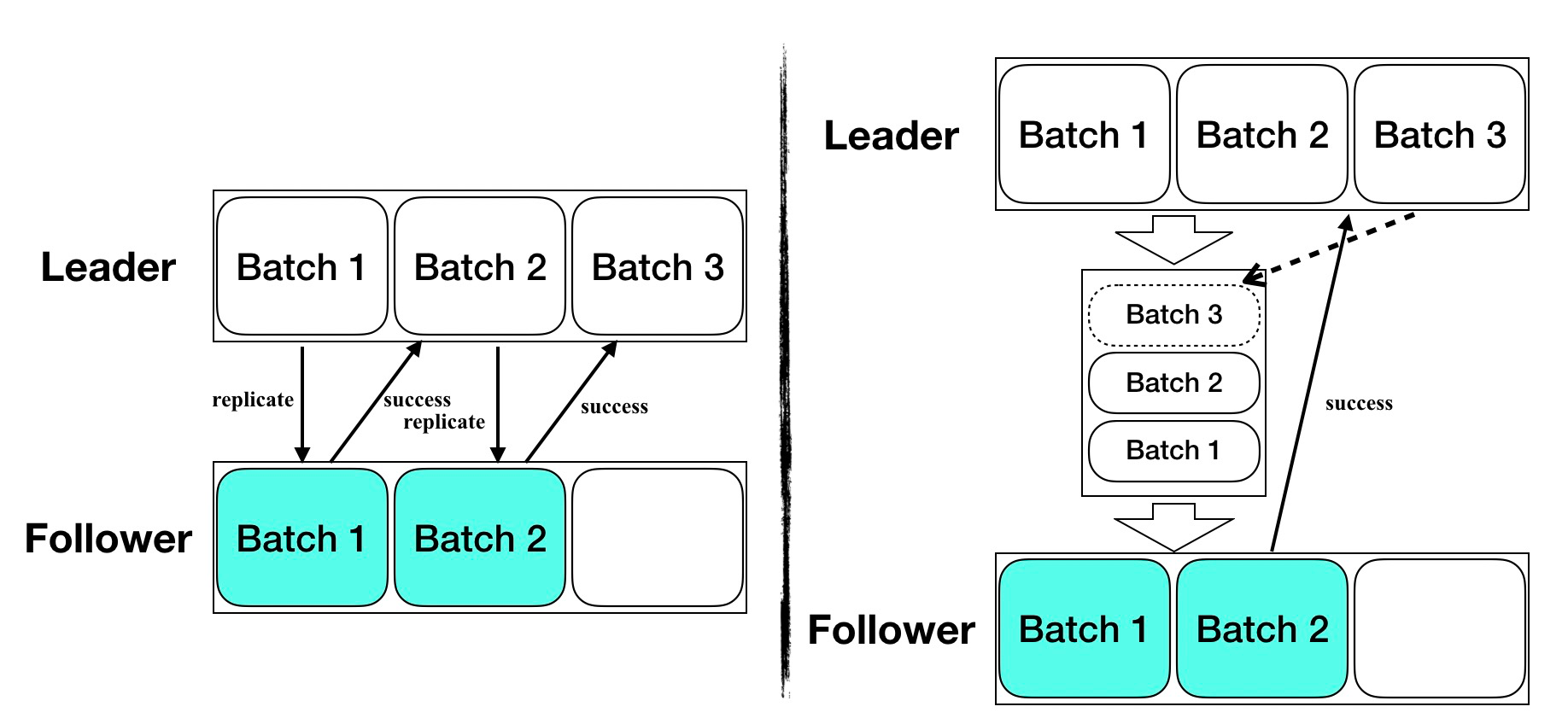
Copy logs are batch
Snapshot in Log Replication
Snapshot allows Follower to quickly keep up with the Leader’s log progress and not replay log messages from long ago, which eases network throughput and improves log synchronization efficiency.
Pipeline mechanism for replicating logs
Pipeline enables Leader and Follower to no longer strictly follow the “Request -Response - Request” interaction pattern, and Leader can continuously Append the replicated logs without receiving a Response. The Leader can continuously send the AppendEntriesRequest of the replicated log to the Follower without receiving a Response.
The Leader only needs to maintain a queue for each Follower to record the copied logs and resend the subsequent logs to the Follower in case of log copy failure.
Replication log details
-
detect Follower log statusLeader node, after establishing a connection with Follower via Replicator, sends a probe request of type Probe in order to know the location of the logs already owned by Follower so that it can send subsequent logs to Follower.
-
Use Inflight to help implement the pipeline
Inflight is an abstraction of the logEntry sent out in bulk, which indicates which logEntry has been encapsulated as a log replication request and sent out.
The Leader maintains a queue, and adds an Inflight to the queue for each batch of logEntry, so that when it knows that a batch of logEntry has failed to replicate, it can rely on the Inflight in the queue to replicate that batch of logEntry and all subsequent logs to the follower. This ensures that the log replication is completed and that the order of the replicated logs remains unchanged.
Linear Consistent Reads
A simple example of a linearly consistent read is that if we write a value at t1, we must be able to read that value after t1, and cannot read the old value before t1.
When a Client initiates a write request to the cluster and receives a successful response, the result of the write operation is visible to all subsequent read requests.
Raft Log read
The most conventional way to achieve a linear consistent read is to use the Raft protocol, where the read request is also processed according to the Log, and the read result is obtained through Log replication and state machine execution, and then the read result is returned to the Client. It is very convenient to implement linear read through Raft, which means that any read request will go through the Raft Log once, and then read the value from the state machine when applying after the log is committed, which will ensure that the read value is linear.
Of course, because every Read needs to go through the Raft process, Raft Log storage and replication bring about the overhead of disk swiping, storage overhead, and network overhead, and going through Raft Log not only has the overhead of log drop, but also the network overhead of log replication, in addition to a bunch of Raft “read log” caused by the disk occupation The performance of Read operations is very inefficient, so it has a great impact on performance in scenarios with many read operations, and is unacceptable in systems with a large proportion of reads, and is usually not used.
In Raft, nodes have three states: Leader, Candidate and Follower. Any Raft write operation must go through Leader, and only Leader will copy the corresponding Raft log to Majority’s node to consider the write as successful. So if the current Leader can be sure that it is the Leader, then it can directly read the data on this Leader, because for the Leader, if it confirms that a Log has been submitted to most nodes and applies to the state machine at t1, then the Read after t1 must be able to read the newly written data.
In other words, compared to Raft Log read, there is less process of Log copy, instead, as long as you confirm your leader identity, you can read data directly from the leader, so that the data must be accurate.
Then how to confirm that the Leader must be the Leader when processing this Read? In the Raft paper, two methods are mentioned:
- ReadIndex Read
- Lease Read
ReadIndex Read
The first type is ReadIndex Read, when the Leader needs to process a Read request, the Leader can provide a linear consistent read after exchanging heartbeat information with more than half of the machines to make sure he is still the Leader:
- the Leader records the commitIndex of its current Log into a Local variable ReadIndex.
- then launch a round of Heartbeat to Followers nodes, if more than half of the nodes return the corresponding Heartbeat Response, then the Leader can determine that it is still the Leader;
- the Leader waits for its StateMachine state machine to execute, and applies at least to the Log recorded in ReadIndex, until applyIndex exceeds ReadIndex, so that it can safely provide Linearizable Read, and does not care if the Leader has drifted away at the time of reading.
- The Leader executes the Read request and returns the result to the Client.
Using ReadIndex Read to provide Follower Read function, it is easy to provide Linearizable Read on top of Followers node, after Follower receives Read request.
- the Follower node requests the latest ReadIndex from the Leader.
- the Leader still goes through the same process as before, executing the first 3 steps (to make sure it is really the Leader), and returns the ReadIndex to the Follower.
- Follower waits for the applyIndex of the current state machine to exceed the ReadIndex.
- Follower executes the Read request and returns the result to Client.
ReadIndex Read uses the Heartbeat method instead of log replication, eliminating the Raft Log process. Compared to the Raft Log method, ReadIndex Read eliminates the disk overhead and can significantly increase throughput. There is still network overhead, but Heartbeat is already small, so performance is still very good.
Lease Read
Although ReadIndex Read is much faster than the original Raft Log Read, there is still a Heartbeat network overhead, so we consider to do further optimization.
The Raft paper mentions a Lease Read optimization method through Clock + Heartbeat, which means that the Leader first records a time point Start when sending a Heartbeat, and when most nodes in the system reply to the Heartbeat Response, due to Raft’s election mechanism, the Follower will be at the Election Timeout. Follower will re-elect after the Election Timeout time, and the next Leader election time is guaranteed to be greater than Start+Election Timeout/Clock Drift Bound, so we can assume that the Leader’s Lease validity period can be up to Start+Election Timeout/Clock Drift. Lease Read is similar to ReadIndex but further optimized, not only saving Log, but also eliminating network interaction, significantly improving read throughput and significantly reducing latency.
The basic idea of Lease Read is that the Leader takes a smaller lease period than the Election Timeout (preferably one order of magnitude smaller), and no election occurs during the lease period to ensure that the Leader does not change, so the ReadIndex step of sending Heartbeat is skipped, which also reduces the latency.
It can be seen that the correctness of Lease Read is linked to the time and depends on the accuracy of the local clock, so although the Lease Read approach is very efficient, it still faces the problem of risk, that is, there is a preset premise that the time of each server’s CPU Clock is accurate, even if there is an error, it will be in a very small Bound range, the time of If the clock drift is serious, and the frequency of the clock goes differently among servers, this Lease mechanism may go wrong.