Merging is a very common operation in Git: you can merge changes between branches, or perform pull and push operations on remote branches.
However, the git merge command can be a bit daunting for newcomers, because you can get different results from running merge in different situations. This uncertainty about the results has kept me from actively using it for a long time, and I’ve relied on visual interfaces like GitHub’s Pull Request or GitLab’s Merge Request to merge manually.
Today we’re going to take a look at merge.
Understanding Merge
In a version control system, a merge is a basic operation that consolidates the changes that have occurred in a group of files. Typically, when we use Git, we create different branches, and different people add and edit the same files.
The merge is usually done automatically by Git’s algorithm, but if there’s a conflict, such as a change to the same file in the same place, you’ll need to merge it manually.
Recursive Three-Way Merge Algorithm
Git uses the “Recursive Three-way Merge” algorithm when it automatically merges files, so let’s take a quick look at that. algorithm.
Let’s start with the “three-way merge” algorithm, assuming we have the following commit history.
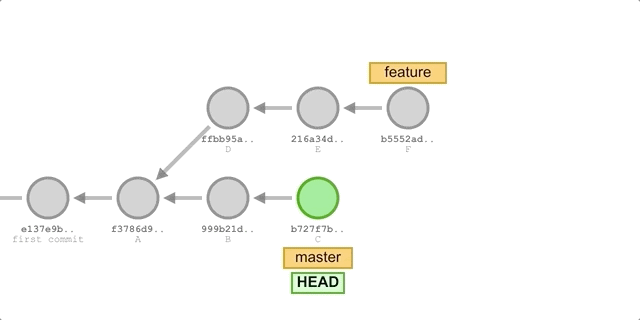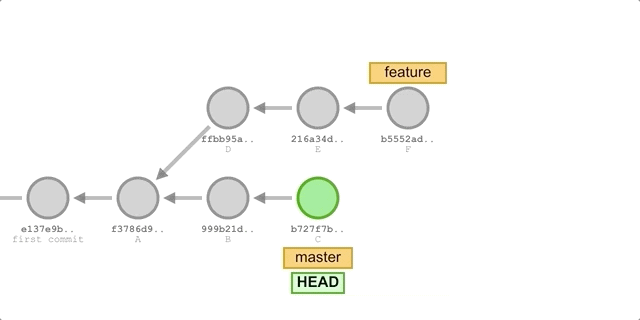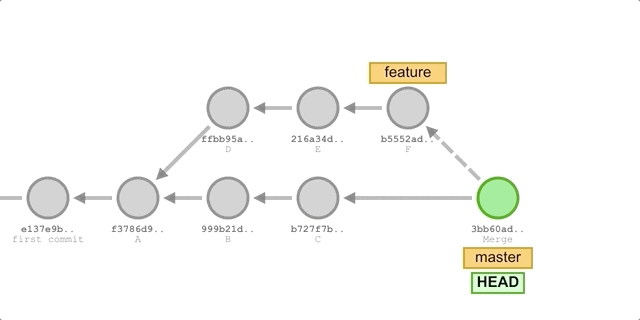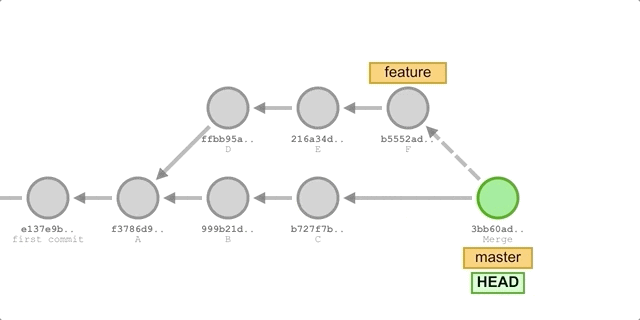
In the diagram above, we merged the feature branch at master, so let’s backtrack the merge process.
At this point, master is pointing to commit C. Git first finds the only common ancestor of the two branches, commit A, and then compares the snapshots of the A, C, and F commits, which we’ll call the A, C, and F files. Next, Git compares the contents of the three files “line by line” and if two of the three files have the same line, it discards the line in file A and puts the line in the result file if it differs from file A.
Specifically, if the contents of A and C are the same, it means that this is the content changed in F and needs to be kept; if the contents of A and F are the same, the same; if the contents of C and F are the same, it means that both C and F have made the same change relative to A and needs to be kept. If A, C, and F are all the same, nothing happened; if C and F are not the same, there’s a conflict and we need to manually merge and select what we want to keep.
After you finish comparing, Git creates a new Merge commit with a snapshot of the final result file and points to it.
The three-way merge algorithm is based on finding the common ancestor of the files being merged, which works fine in some simple scenarios, but in the case of criss-cross merge, there is no unique nearest common ancestor, as shown below.
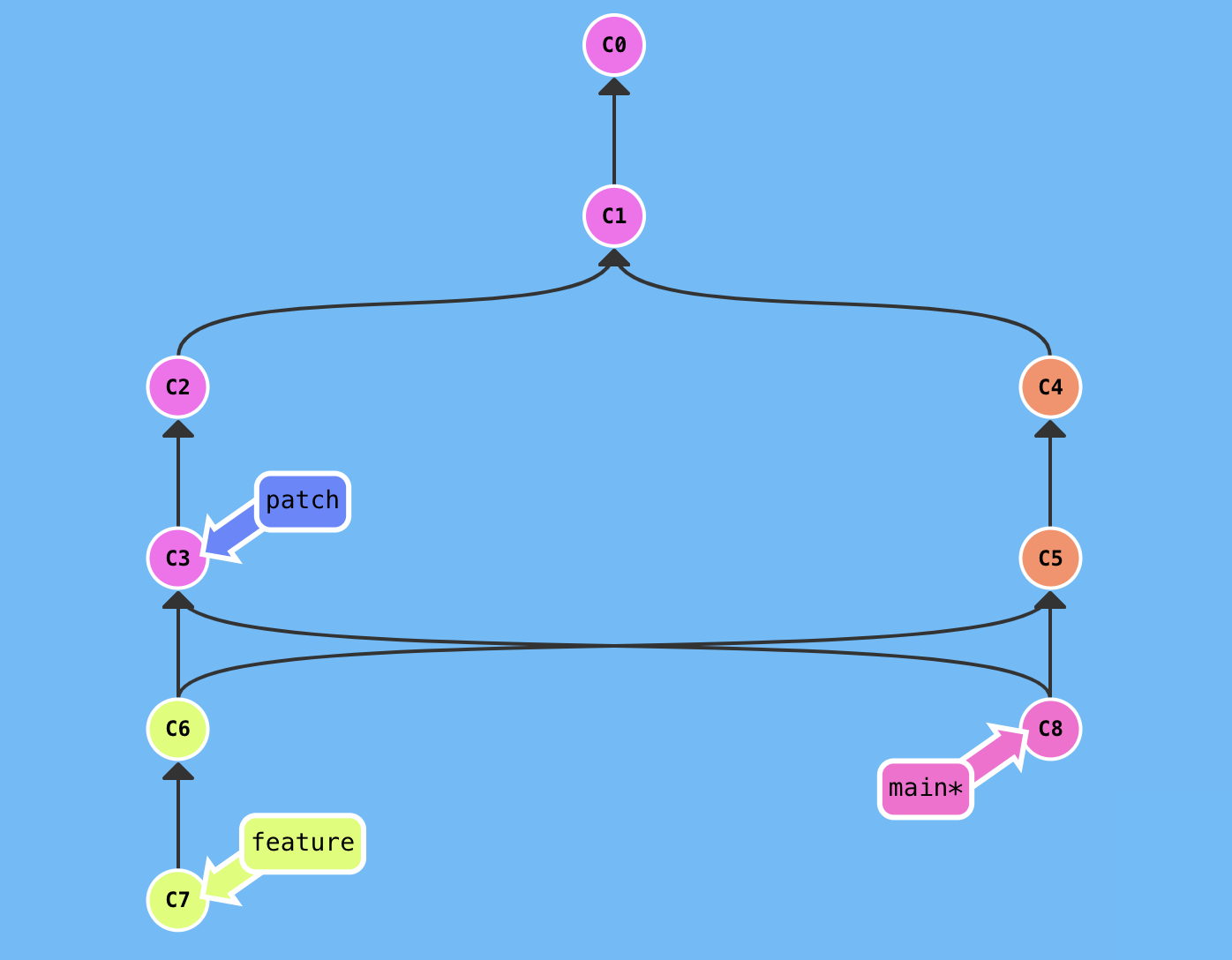
Now we need to merge the feature branch from the main branch, i.e. merge C7 into C8, and we find that C8 and C7 have two common ancestors, so what do we do? (If there is no unique common ancestor in the process of merging C3 and C5, the process will be performed recursively.
That’s all we need to know about the recursive three-way merge algorithm.
Merging conflicts
If you make different changes to the same part of the same file in two different branches, Git will not be able to merge them automatically, but will pause the merge process and wait for you to resolve the conflicts manually.
First we need to find the files that need to be resolved, and use git status to see the files that are unmerged because they contain merge conflicts.
Manual conflict resolution is similar to a two-for-one process, where Git adds special markers to conflicting files that look like the following.
Split by =======, the upper part marked by <<<<<<< HEAD:main.py as the upper bound is the changes made by the current branch master, and the lower part marked by >>>>>>> feature:main.py as the lower bound is the different changes made to the same content by the feature to be merged. We need to edit the file to remove these marks and keep only what we need.
|
|
Of course, it is also possible to not select from it, but to replace it with a completely new paragraph.
After you have resolved the conflicts in all the files, you need to mark them as resolved by staging them with git add. Then you can run git commit to merge the commits. Git will add the resolved conflicts to the new Merge commit mentioned above.
Fast-forwarding Merges
There are times when you do a merge and then you don’t add a new Merge commit. This is called a fast-forward merge.
Suppose we created a feature branch based on master and added some new commits. Now we merge the changes from feature into the master branch.
The process is illustrated as follows.
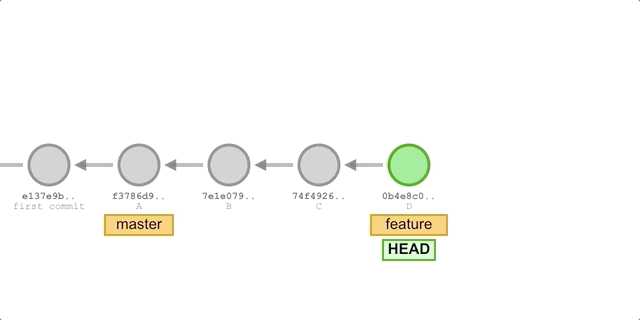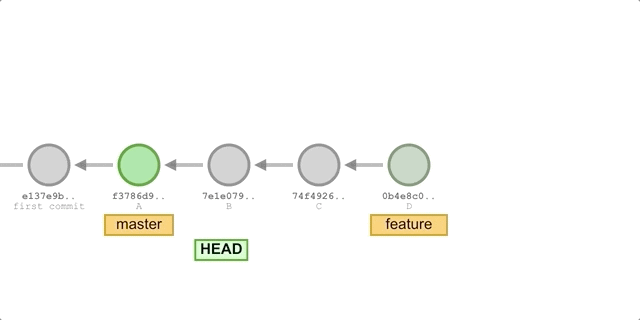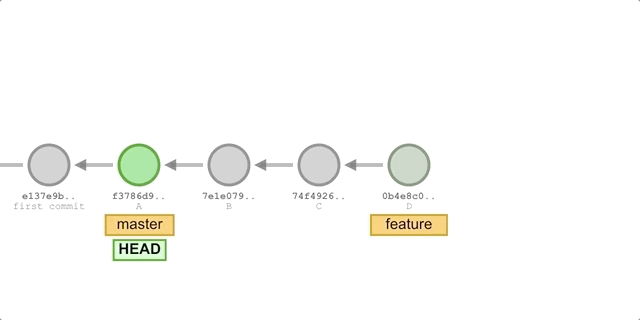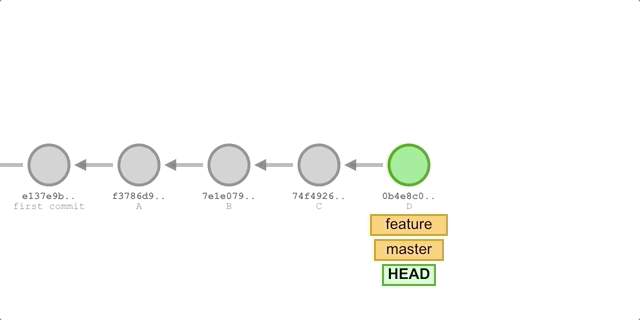
The process is illustrated below because the commit D pointed to by the branch we want to merge, feature, is a direct successor to master, so Git will simply move the HEAD pointer forward. In other words, if you can follow one branch to the other, then Git will simply move the pointer forward (to the right) when merging the two, because there are no differences to resolve in this case - it’s called fast-forward.
Git’s Different Merge Strategies
When we use Git, we usually pull out a number of feature branches based on the main branch and merge them into the main branch when we’re done. There are different branch merging strategies.
- Merge explicitly via
merge. - implicit merge via
rebaseorfast-forward squashpost-implicit merge
Explicit merge via merge
This is the most common and straightforward way to merge, and is the default implementation for code hosting platforms like GitHub and GitLab.
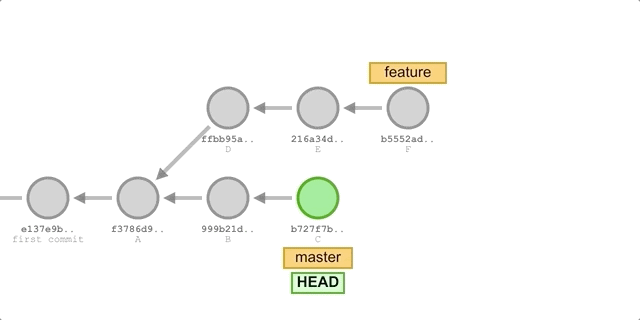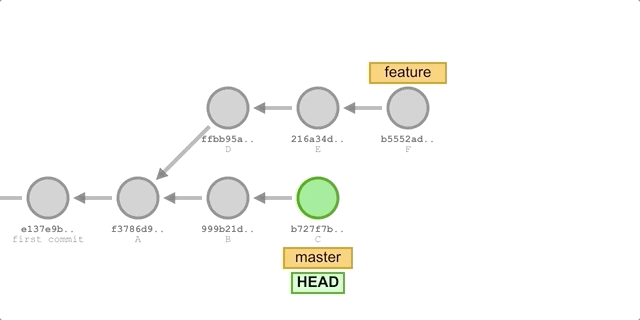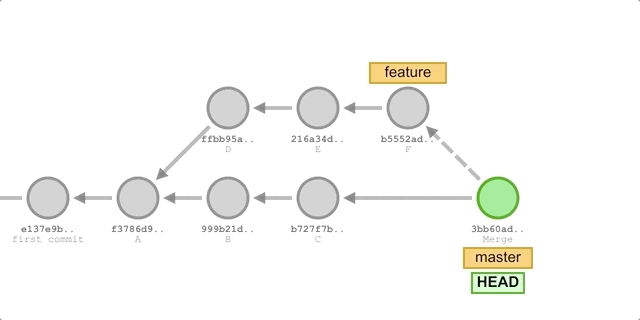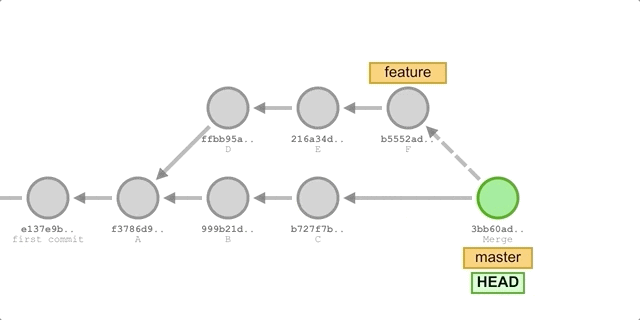
When we merge a feature branch into the master branch, Git does a recursive three-way merge of the two branches and creates a new Merge commit with the merge result. This Merge commit is essentially the same as a normal commit, but it has two parents.
|
|
We can see what merges have happened based on Merge commits very clearly in the commit history. On the other hand, a large number of Merge commits can make your commit history very divergent and even messy, and some developers or teams may want a more linear commit history that looks cleaner.
It’s important to note that by default Git doesn’t create separate Merge commits in the case of a fast-forward merge. If you want to create a Merge commit in all cases, you need to add the -no-ff option to the git merge command.
Implicit merge via rebase or fast-forward
We can replace merge with rebase for merging. I have described the principle and usage of rebase in detail in a previous article git-rebase: A Brief Analysis, simply put rebase finds the most recent ancestor commits for both branches and reapplies the changes to the current branch in order based on the target branch after the ancestor commit. Suppose we have two branches, master and feature, as shown below, and we perform the following actions.
The process is shown in the following figure.
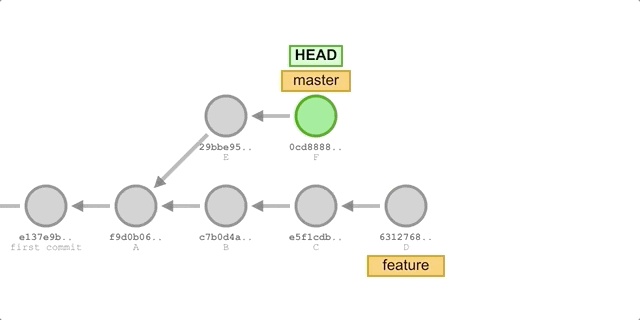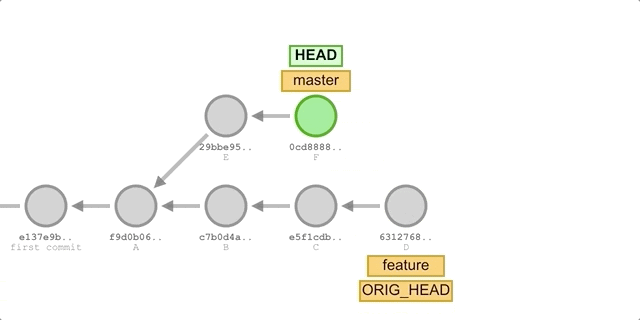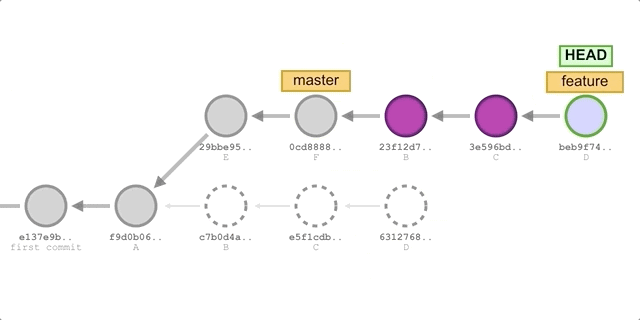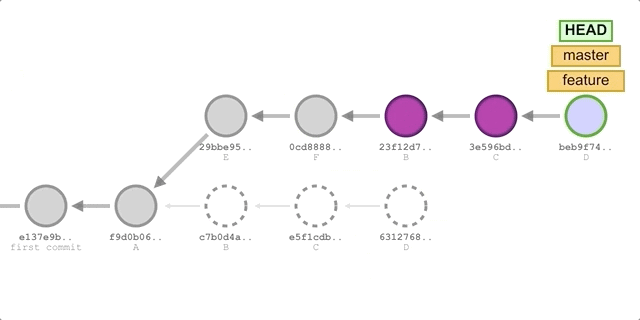
We first merged master into feature using rebase, which gave us a fully linear feature branch with no additional merge commits, even though both branches had different commits.
Then we switch to the master branch and merge feature. On the feature branch after rebase, all commits are successor commits to master, so we will perform a fast-forward merge directly. A fast-forward merge will only occur if there are no commits newer than feature in the master branch (using rebase ensures this result), in which case HEAD of master can be moved right to the latest commit in the feature branch. This merge also does not create a separate Merge commit, it just quickly points the branch label to the new commit.
With a rebase or fast-forward implicit merge, we can get a neat linear commit history, but we also lose the contextual information that these commits used to have.
squash post-implicit merge
Another strategy for merging changes is to compress all feature branch commits into a single commit using the squash command in rebase interactive mode before performing a fast-forward merge or rebase. This further keeps the commit history of the master branch linear and tidy. It keeps a complete feature in a single commit, but it also loses the documentation and detail of the entire feature branch development process.
All three strategies have distinct advantages and disadvantages, and we can choose based on the specific scenario and our own needs.