I had no idea about the use of git rebase -i, but once I needed to merge multiple commits, I almost lost all my commits, but luckily I was able to recover them later. So let’s document the process of learning the rebase command.
Understanding the Rebase Command
The documentation for the git rebase command is Reapply commits on top of another base tip, which literally means reapply commits on top of another base tip, which sounds a bit abstract. Put another way, it means “change the base of a branch from one commit to another, making it look like a branch was created from another commit”, as shown below.
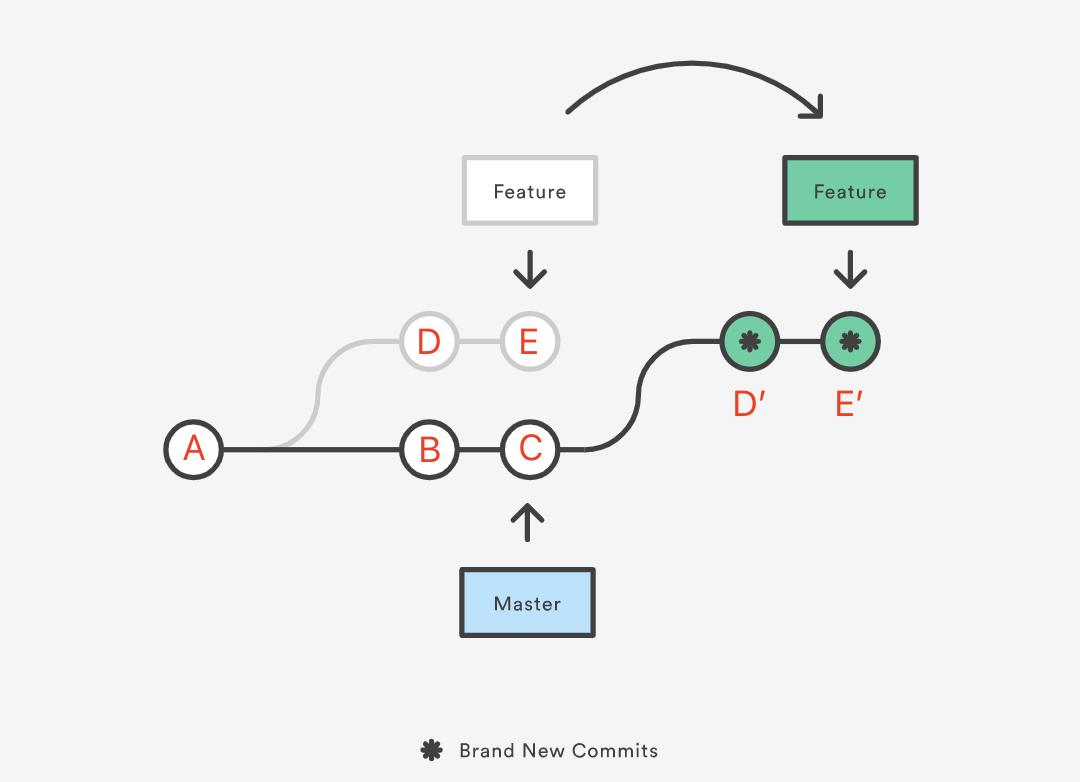
Suppose we create a Feature branch for new feature development from commit A of Master, where A is the base of Feature. Then Matser adds two commits B and C, and Feature adds two commits D and E. Now we need to integrate the two new commits from Master into the Feature branch for some reason, such as new feature development relying on commits B and C. To keep the commit history tidy, we can switch to the Feature branch to perform a rebase operation.
|
|
The process of rebase is to first find the most recent common ancestor commit A of both branches (i.e., the current branch Feature and the target base branch Master of the rebase operation), then compare the previous commits (D and E) of the current branch with respect to the ancestor commit, extract the corresponding changes and save them to a temporary file, then point the current branch to the commit C pointed to by the target base Master, and finally use this as the new base to apply the changes saved to the temporary file in order.
You can also read the above as changing the base of the Feature branch from commit A to commit C. It looks like you created the branch from commit C and committed D and E. But in reality, it just “looks” like Git internally copies commits D and E, creates new commits D’ and E’, and applies them to a specific base (A→B→C). Although the new Feature branch looks the same as before, it’s made up of completely new commits.
The essence of the rebase operation is to discard some existing commits and create some new ones accordingly that are the same but actually different.
Main Uses
rebase is typically used to rewrite the commit history. The following usage scenario is very common in most Git workflows.
- We pull a
featurebranch from amasterbranch to do feature development locally - The remote
masterbranch merges in some new commits later - We want to integrate the latest changes from
masterin thefeaturebranch
The difference between rebase and merge
The above scenario can also be accomplished using merge, but using rebase allows us to keep a linear and more tidy commit history. Suppose we have the following branches.
Now we will integrate commits B and C from the master branch into the feature branch using merge and rebase respectively, and add a new commit F to the feature branch, then merge the feature branch into master, and finally compare the difference between the commit histories created by the two methods.
Using merge
-
switch to the
featurebranch:git checkout feature. -
merge updates from the
masterbranch:git merge master. -
Add a commit to F:
git add . && git commit -m "commit F". -
Cut back to the
masterbranch and perform a fast-forward merge:git chekcout master && git merge feature.Execute the process as shown below.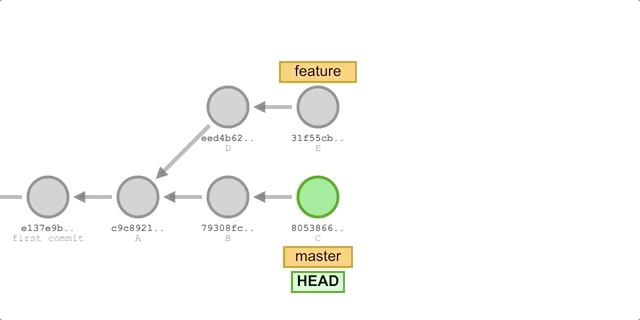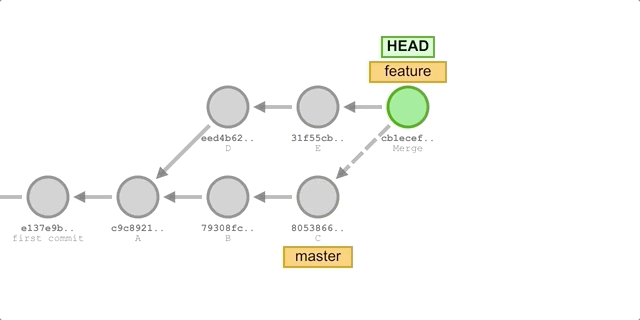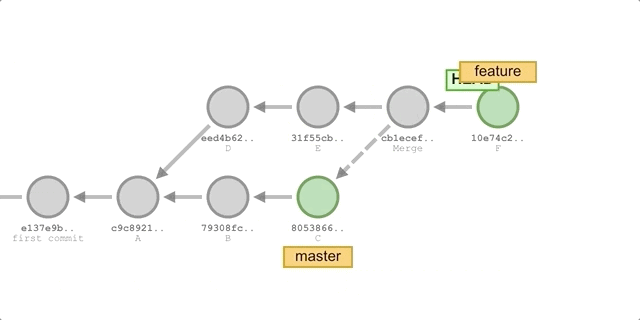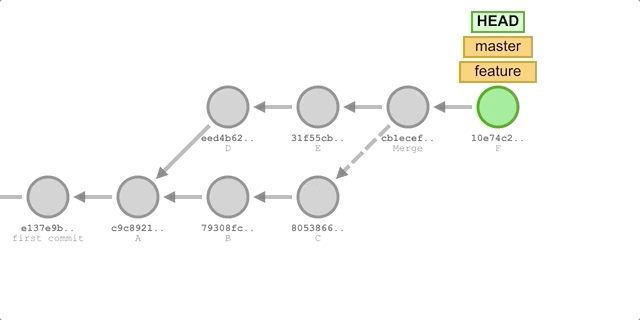
We will get the following submission history.
Using rebase
The steps are basically the same as using merge, the only difference is that the command in step 2 is replaced with: git rebase master.
The execution process is shown in the following diagram.
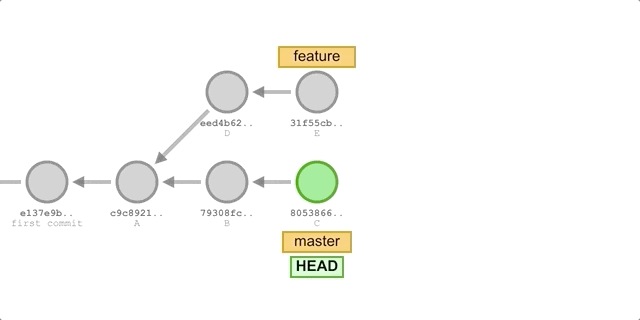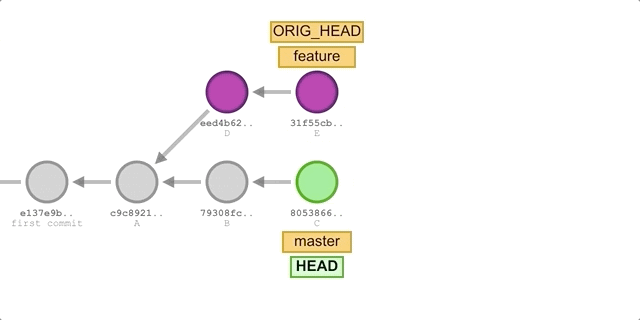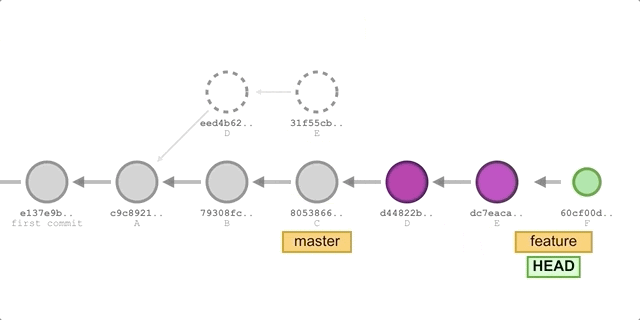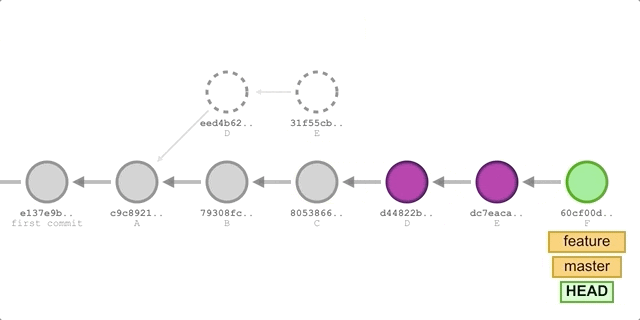
We will get the following submission history.
You can see that the commit history formed using the rebase method is completely linear, and also looks neater with one less merge commit than the merge method.
Why keep the commit history tidy
What are the benefits of a neater looking commit history?
- to satisfy some developers’ cleanliness.
- When you need to go back in the commit history for some bug, it is easier to locate the commit from which the bug was introduced. This is especially true if you need to troubleshoot hundreds of commits with
git bisect, or if you have a large feature branch that needs to pull frequent updates from a remote master branch.
Using rebase to consolidate remote changes into the local repository is a better option. Pulling remote changes with merge results in a redundant merge commit every time you want to get an update on your project. The result of using rebase is more in line with our intent: I want to build on other people’s completed work to make my changes.
Other ways to rewrite the commit history
When we just want to modify the most recent commit, it is easier to use git commit --amend.
It works for the following scenarios.
- We’ve just finished a commit, but haven’t pushed it to the public branch yet.
- Suddenly we realize that we left some small loose ends on the last commit, like a comment we forgot to delete or a tiny typo that we can fix very quickly but don’t want to add a separate commit.
- Or we just feel that the commit message of the last commit is not written well enough and we want to make some changes.
At this point we can add the new changes (or skip them) and use the git commit --amend command to execute the commit, which will bring us to a new editor window where we can make changes to the commit message of the previous commit, save it, and then apply those changes to the previous commit.
If we have already pushed the last commit to a remote branch and the push is now rejected with an error, we can use git push --force to force the push if we want to make sure the branch is not a public branch.
Note that like rebase, Git doesn’t actually modify and replace the previous commit internally, but rather creates a new commit and redirects to it.
Rewriting the commit history using rebase’s interactive mode
The git rebase command has two modes, standard and interactive. The previous examples we used the default standard mode, add the -i or -interactive option to the end of the command to use the interactive mode.
The difference between the two modes
As we mentioned earlier, rebase is “reapplying commits on top of another base”, and during the reapplication process, these commits are recreated and can naturally be modified. In the standard mode of rebase, commits from the current working branch are applied directly to the top of the incoming branch, while in the interactive mode, we are allowed to merge, reorder, and delete commits via the editor and specific command rules before reapplying them.
The most common usage scenarios for the two differ as a result.
- standard mode is often used to integrate the latest changes from other branches in the current branch.
- Interaction mode is often used to edit the commit history of the current branch, such as merging multiple small commits into one large commit.
More than just branches
While our previous examples all performed rebase operations between two different branches, the rebase command is in fact not limited to branches.
Any commit reference can be treated as a valid rebase base object, including a commit ID, branch name, tag name, or a relative reference like HEAD~1.
Naturally, if we execute rebase on a historical commit of the current branch, the result will be that all commits after this commit will be reapplied to the current branch, which in interactive mode allows us to make changes to those commits.
Rewriting commit history
Finally, as mentioned earlier, if we execute rebase in interactive mode on a commit of the current branch, we are (indirectly) rewriting all commits after this one. This is described in more detail in the following example.
Suppose we have the following commits in the feature branch.
|
|
The next action we will perform is.
- merge B and C into a new commit and keep only the commit information of the original commit C
- Delete commit D
- Move commit E after commit F and rename it (i.e., change the commit information) to commit H
- Add a new file change to commit F and rename it commit G
Since the commits we need to modify are B→C→D→E, we need to use commit A as the new “base” and all commits after commit A will be reapplied.
|
|
You will then be taken to the following editor screen.
|
|
(Note that the commit messages after the commit ID above only serve a descriptive purpose, and modifying them here will have no effect.)
The specific commands are explained in considerable detail in the editor comments, so let’s proceed directly as follows.
-
make the following changes to commits B and C.
Since commit B is the first of these commits, we cannot execute the
squashorfixupcommands on it (there is no previous commit), and we do not need to execute therewordcommand on commit B to modify its commit information, because we will be allowed to modify the fused commit information later when we fuse commit C into commit B.Note that commits in this interface are displayed in top-down order, so changing the command for commit C to
s (or squash)orf (or fixup)will fuse it to the previous commit B (above), the difference between the two commands being whether or not the commit information for C is retained. -
Delete the submission D.
1d d9623b0 commit D -
Move commit E to after commit F and modify its commit information.
-
Add a new document change to commit F.
1e 74199ce commit F -
Save and then exit.
The commands that we modify or retain for each commit are then executed in order from top to bottom.
-
The
pickcommand for commit B will be executed automatically, so no interaction is required. -
Next, execute the
squashcommand for commit C. This brings us to a new editor screen that allows us to modify the commit information after merging B and C.We delete the line
commit Band save it to exit. Subsequent commits will usecommit Cas the commit message. -
the
dropoperation for commit D will also be executed automatically without any interactive steps. -
Conflicts may occur during the execution of
rebase, whererebaseis temporarily suspended and we need to edit the conflicting files to merge the conflicts manually. After resolving the conflict, you can mark it as resolved withgit add/rm <conflicted_files>and then rungit rebase --continueto continue with therebasestep, or you can rungit rebase --abortto abort therebaseoperation and revert to the to the state before the operation. -
Since we moved up commit F, we will then perform an
editoperation on F. This will enter a new shell session.We add a new code file and run
git commit --amendto merge it into the current previous commit (i.e. F), then change its commit information tocommit Gin the editor screen, and finally rungit rebase--continueto continue therebaseoperation. -
Finally, perform a
rewordoperation on commit E and change its commit information tocommit Hin the editor screen.
Done! Finally, let’s confirm the commit history after rebase.
This is exactly as expected, and you can see that all the commit IDs after commit A have changed, which confirms what we said earlier about Git re-creating these commits.
Advanced Uses of Rebase
Rebase before merging
Another common scenario for using rebase is to execute rebase before pushing to a remote for merging, typically to ensure a tidy commit history.
We first develop in our own feature branch, and when development is complete, we need to rebase the current feature branch to the latest master branch to resolve any potential conflicts before committing changes to the remote. In this case, the maintainer of the master branch of the remote repository no longer needs to integrate and create an additional merge commit, but only needs to perform a fast-forward merge. This results in a completely linear commit history, even in cases where multiple branches are developed in parallel.
rebase to other branch
We can use rebase to compare two branches, take out the corresponding changes, and apply them to the other branch. For example.
Suppose we created a branch patch based on commit D of the feature branch and added commits F and G. Now we want to merge the changes made by patch into master and publish it, but we don’t want to merge feature yet, in which case we can use the -onto <branch> option of rebase.
|
|
This will take the patch branch, compare the changes it made based on feature, and then reapply those changes to the master branch, making patch look like it made the changes directly based on master. The executed patch looks like this.
|
|
We can then switch to the master branch and perform a fast-forward merge on patch.
Running git pull with a rebase policy
If you run git pull directly after a recent release of Git, you will get the following message.
It turns out that git pull can also be merged with rebase, because git pull is actually equivalent to git fetch + git merge, and we can replace git merge with git rebase in the second step to merge the changes fetched by fetch, again to avoid additional merge commits and maintain a linear commit history.
We can think of the Matser branch in the comparison example as a remote branch and the Feature branch as a local branch, and when we do a local git pull, we are actually pulling changes from Master and merging them into the Feature branch. If both branches have different commits, the default git merge method will generate a separate merge commit to consolidate those commits; using git rebase is equivalent to re-creating the local branch based on the latest commits from the remote branch and then reapplying the local commits.
There are several ways to use this.
- Add a specific option each time you run the pull command:
git pull --rebase. - Set a configuration entry for the current repository:
git config pull.rebase true, and add the-globaloption togit configto make it effective for all repositories.
Potential drawbacks and objections
From the above scenario rebase is very powerful, but we also need to realize that it is not foolproof and even a bit dangerous for newbies, who may find that a commit is missing from git log or get stuck in a step of rebase and don’t know how to recover.
We’ve mentioned above that rebase has the advantage of keeping a neat linear commit history, but it’s also important to realize that it has the potential disadvantages of.
- If it involves commits that have already been pushed, you need to force a push in order to push the commits after the local
rebaseto the remote. So never runrebaseon a public branch (i.e. one that other people are working on), or else someone else runninggit pulllater will merge a confusing local commit history, and pushing further back to the remote branch will mess up the remote commit history (see Rebase and the golden rule explained), which in more severe cases may pose a risk to your safety. - Unfriendly to newcomers, who are likely to “lose” some commits by mistake in interactive mode (but can actually retrieve them).
- If you frequently use
rebaseto integrate master branch updates, one potential consequence is that you will encounter more and more conflicts that need to be merged. While you can handle these conflicts in therebaseprocess, this is not a long-term solution, and it is more advisable to merge into the master branch frequently and then create a new feature branch, rather than using a long-standing feature branch.
There are also some arguments that we should try to avoid rewriting the commit history.
There is a view that the commit history of a repository is a record of what actually happened. It is a document that is specific to the history and has value in itself, and cannot be changed indiscriminately. From this perspective, changing the commit history is blasphemy; you are using a lie to hide what actually happened. What if the commit history generated by the merge is a mess? Since that is what happened, the traces should be preserved for future generations to access.
As well, frequent use of rebase may make it more difficult to locate bugs from the commit history, as described in Why you should stop using Git rebase.
Retrieving lost commits
Doing a rebase in interactive mode and executing a command like squash or drop on a commit will delete the commit directly from the branch’s git log. If you accidentally make a mistake, you’ll break out in a cold sweat thinking that these commits are gone for good.
But these commits aren’t really deleted. As mentioned above, Git doesn’t modify (or delete) the original commits, but rather it re-creates a new batch of commits and points the top of the current branch to the new commits. So we can use git reflog to find and redirect to the original commits to restore them, which undoes the entire rebase. Thanks to Git, it doesn’t really lose any commits even if you do something like rebase or commit --amend that rewrites the commit history.
The git reflog command
reflogs is a mechanism that Git uses to keep track of updates to the top of the local repository branch. It keeps track of all the commits that the top of the branch has ever pointed to, so reflogs allows us to find and switch to a commit that is not currently referenced by any branch or tag.
Whenever the top of a branch is updated for any reason (by switching branches, pulling new changes, rewriting history, or adding new commits), a new record will be added to reflogs. In this way, every commit we have created locally must be logged in reflogs. Even after the commit history is rewritten, reflogs will contain information about the old state of the branch and allow us to revert to that state if needed.
Note that reflogs is not kept forever, it has an expiration time of 90 days.
Restoring Commit History
Let’s continue from the previous example. Suppose we want to restore the commit history of feature branch A→B→C→D→E→F before rebase, but at this point there are no more commits in git log for the last 5 commits, so we need to look for them in reflogs, and run git reflog with the following result:
|
|
The reflogs document the entire process of switching branches and doing a rebase, and continuing down the list, we find the commit F that disappeared from the git log.
|
|
Next, we redirect the top of the feature branch to the original commit F via git reset.
Run git log again and you’ll see that everything is back to where it was before.
|
|