Anyone familiar with the Go language should be familiar with interfaces and methods such as io.Copy()/io.CopyN()/io.CopyBuffer()/io.ReaderFrom. They are APIs that are often used to transfer data using Go to manipulate various types of I/O. The TCP-based socket makes use of Linux’s zero-copy technologies sendfile and splice when transferring data using these interfaces and methods.
splice
After looking through Linux zero-copy techniques, splice is more suitable as a general-purpose zero-copy method than other techniques such as mmap, sendfile and MSG_ZEROCOPY in terms of cost, performance and applicability.
The splice() system call function is defined as follows.
fd_in and fd_out also represent the input and output file descriptors, respectively, and one of these two file descriptors must point to a pipeline device, which is a less friendly restriction.
off_in and off_out are pointers to the offsets of fd_in and fd_out respectively, indicating where the kernel reads and writes data from, len indicates the number of bytes the call wishes to transfer, and finally flags is the system call’s flag option bitmask, which sets the behavior of the system call, and is a combination of 0 or more of the following values via the ‘or’ operation .
- SPLICE_F_MOVE: instructs
splice()to try to just move memory pages instead of copying them; setting this value does not necessarily mean that memory pages will not be copied; whether they are copied or moved depends on whether the kernel can move memory pages from the pipeline, or whether the memory pages in the pipeline are intact; the initial implementation of this flag had a lot of bugs, so it has been in place since Linux version 2.6.21, but it has been retained because it may be reimplemented in a future version. - SPLICE_F_NONBLOCK: instructs
splice()not to block I/O, i.e. makes thesplice()call a non-blocking call that can be used to implement asynchronous data transfers, but note that it is also best to pre-mark the two file descriptors for data transfers as non-blocking I/O with O_NONBLOCK, otherwise Otherwise, thesplice()call may still be blocked. - SPLICE_F_MORE: informs the kernel that more data will be transferred with the next
splice()system call, this flag is useful for scenarios where the output side is a socket.
splice() is based on Linux’s pipe buffer mechanism, so the two incoming file descriptors of splice() require that one of them be a pipe device, and a typical use of splice() is as follows.
Diagram of the data transfer process.
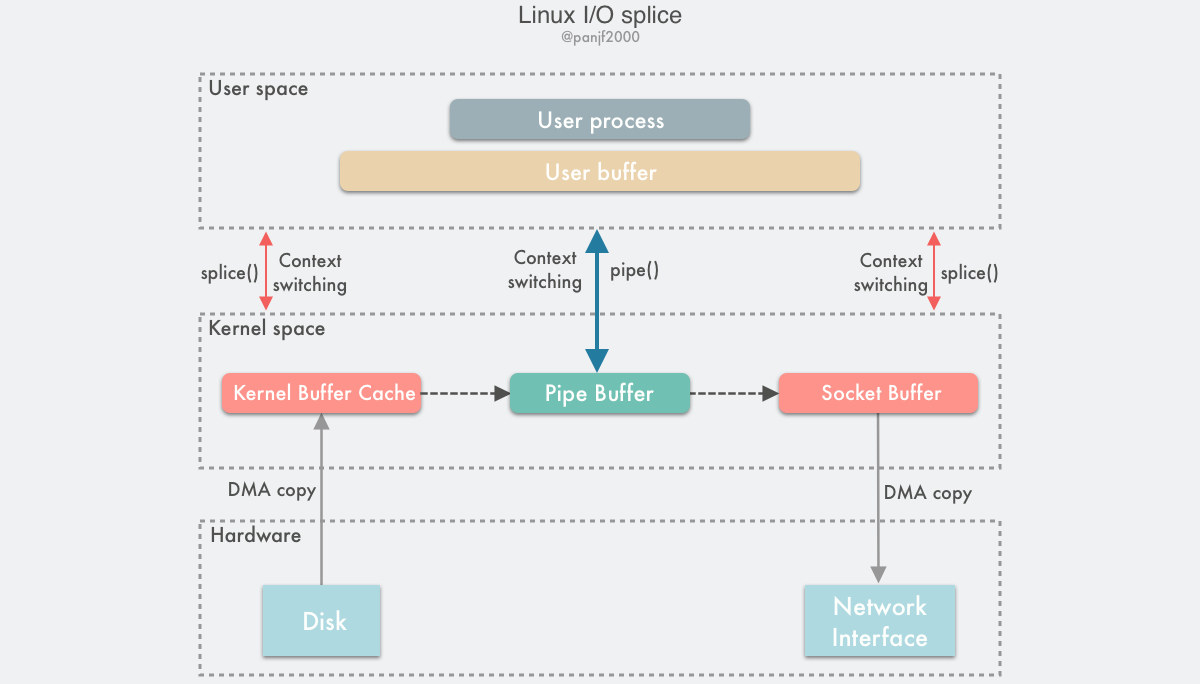
Using splice() to complete a read/write from a disk file to a NIC is as follows.
- the user process calls
pipe(), which plunges from the user state into the kernel state, creates an anonymous one-way pipe,pipe()returns, and the context switches from the kernel state back to the user state. - the user process calls
splice()to fall from the user state to the kernel state. - the DMA controller copies the data from the hard disk to the kernel buffer, “copies” it from the write side of the pipe into the pipe,
splice()returns, and the context returns from the kernel state to the user state. - the user process calls
splice()again, plunging from the user state into the kernel state. - the kernel `copies’ the data from the read side of the pipe to the socket buffer, and the DMA controller copies the data from the socket buffer to the NIC.
splice()returns and the context switches from kernel state back to user state.
The above is the basic workflow and principle of splice, which is simply to pass the memory page pointer instead of the actual data during data transfer to achieve zero copy.
pipe pool for splice
pipe pool in HAProxy
As you can see from the introduction of splice above, the implementation of zero-copy data through it requires the use of a medium - pipe (introduced by Linus in 2005), probably because the application of pipe in the Linux IPC mechanism is relatively mature, so the use of pipe to implement splice, although the Linux Although the Linux Kernel team said at the beginning of splice that the pipe limitation could be removed in the future, it has not been implemented for more than a decade, so splice is still tied to pipe.
The problem is that if splice is used only for a single bulk data transfer, the overhead of creating and destroying pipe is almost negligible, but if splice is used frequently for data transfer, for example, in scenarios where a large number of network sockets need to be forwarded, the frequency of creating and destroying pipe also Each call to splice creates a pair of pipe pipe descriptors and destroys them later, which is a huge drain on a network system.
The natural solution to this problem is to think of “reuse”, such as the famous HAProxy.
HAProxy is a free and open source software written in C language that provides high availability, load balancing, and TCP and HTTP based application proxying. HAProxy is used by well-known sites such as GitHub, Bitbucket, Stack Overflow, Reddit, Tumblr, Twitter, and Tuenti, as well as Amazon Web Services.
Because of the need to do traffic forwarding, it can be imagined that HAProxy inevitably has to use splice in high frequency, so the overhead of creating and destroying pipe buffers brought by splice can’t be tolerated, so we need to implement a pipe pool to reduce the consumption of system calls by reusing pipe buffers, let’s analyze it in detail Let’s take a closer look at the design of the HAProxy pipe pool.
First of all, let’s think about how a simple pipe pool should be implemented, the most direct and simple implementation is undoubtedly: a single linkedlist + a mutual exclusion lock. Arrays can make better use of CPU cache to speed up access because of the continuity of data allocation in memory, but first of all, for a thread running on a CPU, only one pipe buffer needs to be taken at a time, so the role of cache is not very obvious here; secondly, arrays are not only Second, arrays are not only contiguous but also fixed-size memory areas, which require pre-allocation of a fixed size of memory and dynamic scaling of this memory area, during which the data needs to be relocated and other operations, adding additional management costs. A linked table is a more suitable choice because as a pool all the resources are equivalent and there is no need to access randomly to get a particular resource, and a linked table is naturally dynamically scalable and can be discarded as it is taken.
Early implementations of locks on Linux were based entirely on kernel sleep-waiting, where the kernel maintains a shared resource object mutex that is visible to all processes/threads, and locking and unlocking by multiple threads/processes is actually a competition for this object. If there are two processes/threads AB, A first enters the kernel space to check the mutex to see if another process/thread is occupying it, and then enters the critical zone directly after the mutex is successfully occupied. Then the kernel will wake up the waiting process/thread and switch the CPU to that process/thread at the right time. Since the original mutex was a fully kernel-state implementation of mutual exclusion, which generated a lot of system calls and context switching overhead in case of high concurrency, after Linux kernel 2.6.x, futexes (Fast Userspace Mutexes) are used, which is a mixed implementation of user and kernel states, by sharing a section of memory in the user state and using The semaphore is stored in private memory within the process as a thread lock, and in shared memory created by mmap or shmat as a process lock.
Even for futex-based mutual exclusion locks, if it is a global lock, this simplest pool + mutex implementation has predictable performance bottlenecks in competitive scenarios, so further optimization is needed, by two means: reducing the granularity of the lock or reducing the frequency of robbing (global) locks. Since the resources in the pipe pool are originally shared globally, it is impossible to downgrade the granularity of locks, so the only way to minimize the frequency of multi-threaded lock grabbing is to introduce a local resource pool in addition to the global resource pool to stagger the operations of multi-threaded access to resources.
As for the optimization of the lock itself, since mutex is a kind of dormant waiting lock, even after futex-based optimization in the lock competition still needs to involve the kernel state overhead, you can consider the use of spin lock (Spin Lock), that is, the user state lock, shared resource objects exist in the memory of the user process, to avoid the lock competition into the kernel state waiting, spin lock is more suitable for Spin Lock is more suitable for scenarios where the critical area is very small, while pipe pool’s critical area is only for adding and deleting operations to the linkedlist, which is a good match.
The pipe pool implemented by HAProxy is designed based on the above idea, splitting a single global resource pool into a global resource pool + a local resource pool.
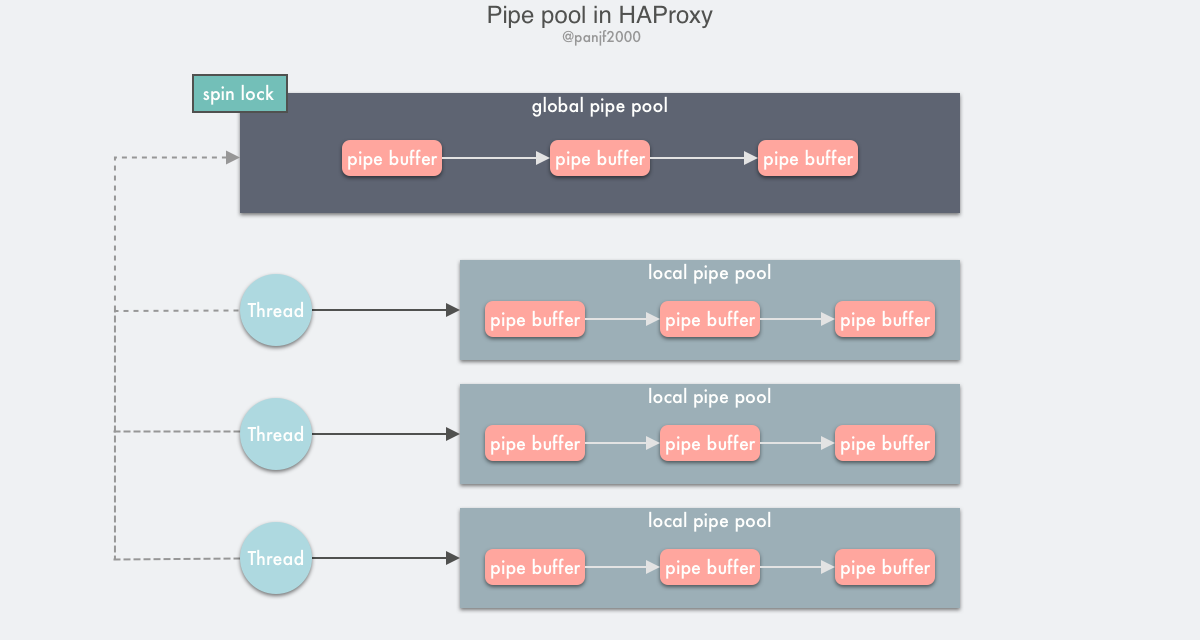
Global resource pools are implemented using single-linked tables and spin locks, while local resource pools are implemented based on Thread Local Storage (TLS), a private thread variable whose main purpose is to avoid the overhead of lock contention in multi-threaded programming. TLS is supported by the compiler, and we know that the obj of a compiled C program or the exe of a linked program has a .text segment to store code text, a .data segment to store initialized global variables and initialized static variables, and a .bss segment to store uninitialized global variables and uninitialized local static variables.
Unlike .data and .bss, these segments are not directly accessed by the runtime program, but are dynamically initialized by the dynamic linker after the program starts (if TLS is declared), after which they are not changed again. They are saved as the initial image of TLS. Each time a new thread is started, the TLS block is allocated as part of the thread stack and the initial TLS image is copied over, which means that eventually the contents of the TLS block will be the same for every thread started.
The principle of HAProxy’s pipe pool implementation.
- declare a
thread_local-modified single-linked table with nodes that are the two pipe descriptors of the pipe buffer, then each thread that needs to use the pipe buffer initializes aTLS-based single-linked table to store pipe buffers. - set a global pipe pool, protected by a spinlock.
Each thread will first try to get the pipe from its own TLS, and if it cannot get it, it will lock the global pipe pool to find it; after using the pipe buffer, it will put it back: first try to put it back to the TLS, and according to a certain policy, it will calculate whether there are too many nodes in the local pipe pool chain of the current TLS, and if so, it will be put into the global pipe pool. If so, it is put into the global pipe pool; otherwise, it is put back into the local pipe pool directly.
Although the pipe pool implementation of HAProxy is only 100 lines of code, the design ideas contained in it contain many classic multi-threaded optimization ideas, which is worth reading carefully.
pipe pool in Go
Inspired by HAProxy’s pipe pool, I tried to implement a pipe pool for the underlying splice in Golang’s io standard library, but students familiar with Go should know that Go has a GMP concurrent scheduler that provides powerful concurrent scheduling capabilities while blocking OS-level threads, so Go does not provide a mechanism similar to TLS. Instead, there are some open source third-party libraries that provide similar functionality, such as gls, but although the implementation is very sophisticated, it is not an official standard library and will directly manipulate the underlying stack, so it is not really recommended for online use.
At the beginning, because Go lacks the TLS mechanism, the first version of go pipe pool I submitted was a very rudimentary implementation of a single linked table + global mutex lock, because this solution does not release the pipe buffers in the resource pool during the life of the process (in fact, HAProxy’s pipe pool also has this problem), which means that those This is obviously not a convincing solution, and it was unexpectedly rejected by Ian, a core member of the Go team, so I I immediately came up with two new solutions.
- based on this existing scheme plus a separate goroutine that scans the pipe pool at regular intervals, closing and releasing pipe buffers.
- implement pipe pools based on the
sync.Poolstandard library and useruntime.SetFinalizerto solve the problem of releasing pipe buffers periodically.
The first solution requires the introduction of an additional goroutine, and the goroutine adds uncertainty to the design, while the second solution is more elegant, firstly because it is based on `sync. The second is that it uses Go’s runtime to solve the problem of releasing pipe buffers at regular intervals, which is much more elegant, so soon I and other Go reviewers agreed on the second option.
sync.Pool is a temporary object cache pool provided by the Go language, which is generally used to reuse resource objects and reduce GC pressure, and can be used wisely to significantly improve program performance. Many top Go open source libraries make heavy use of sync.Pool to improve performance, for example, the most popular third-party HTTP framework in Go fasthttp makes heavy use of sync. Pool in the source code, and reaped a performance improvement of nearly 10x over the Go standard HTTP library (not just by this one optimization, of course, but many others). fasthttp’s author Aliaksandr Valialkin, a Go contributor who has contributed a lot of code to Go and optimized sync. Pool in fasthttp’s best practices, so Go’s pipe pool using sync.Pool for Go’s pipe pool is a natural fit.
sync.Pool is simply: private variables + shared bidirectional chains.
Google has a diagram to show the underlying implementation of sync.Pool.
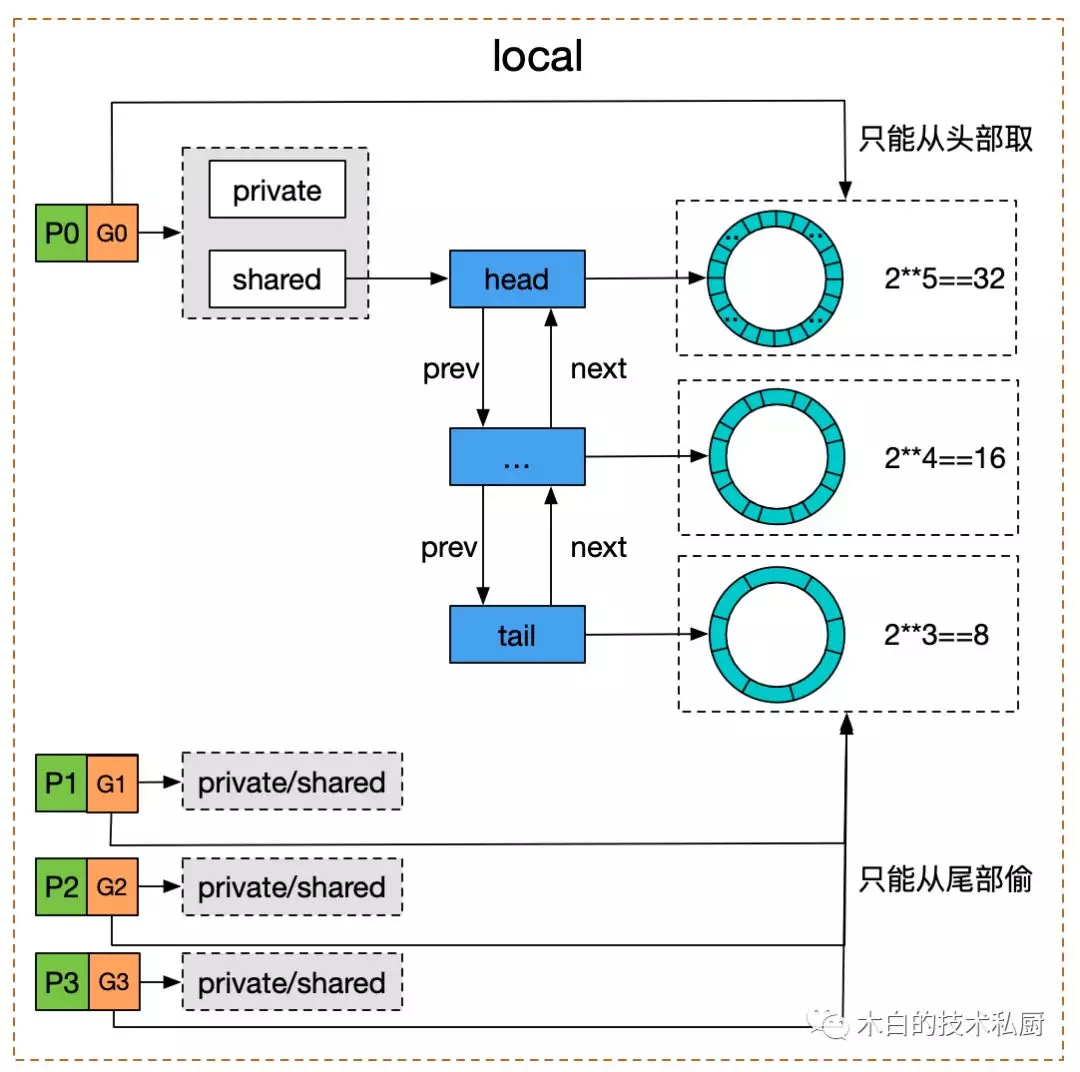
-
When fetching an object. When a goroutine on some P tries to fetch a cached object from
sync.Pool, it needs to lock the current goroutine on P first to prevent it from being dispatched suddenly during the operation, then try to fetch the local private variableprivatefirst, and if it is not there, go to the head of thesharedtwo-way table, which can be consumed by other P (or “steal”). steal"), if thesharedon the current P is empty then go “steal” the end of thesharedtwo-way linked table on the other P, finally unlock it, and if the cached object is still not fetched, then directly callNewto create a return. -
When putting back the object: first lock the current goroutine on P, if the local
privateis empty, the object is directly deposited, otherwise it is deposited in the head of thesharedtwo-way linked table, and finally unlocked.
Each node of a shared two-way linked table is a ring queue. Mutex before Go 1.13, and atomic CAS after Go 1.13 for lock-free concurrency. Atomic concurrency is suitable for scenarios where the critical area is very small, and the performance is much better with mutexes, which fits the sync. Pool. Because accessing temporary objects is very fast, if we use mutex, we need to hang the goroutines that failed to grab the lock to the wait queue when competing, and then wake up and put them into the run queue after the subsequent unlocking, waiting for the scheduling execution, rather than just busy polling and waiting, we can grab the critical area soon anyway.
sync.Pool is also designed with some TLS in mind, so in a sense it is a TLS mechanism for the Go language.
sync.Pool is based on the victim cache which guarantees that resource objects cached in it will be recycled in no more than two GC cycles.
So I used sync.Pool to implement Go’s pipe pool, storing the pipe’s file descriptor pairs in it, reusing them when concurrent, and automatically recycling them periodically, but there is one problem: when the objects in `sync. It does not shut down the pipe at the OS level.
Therefore, there is a method to close the pipe, which can be done with runtime.SetFinalizer. When Go’s tri-color tagging GC algorithm detects that an object in sync.Pool has become white (unreachable, i.e. garbage) and is ready to be recycled, if the white object has an associated callback function bound to it, the GC will first unbind the callback function and start If the white object is bound to a callback function, the GC will first unbind the callback function and start a separate goroutine to execute the callback function, because the callback function uses the object as a function reference, that is, it will refer to the object, then it will cause the object to become a reachable object again, so it will not be recycled in the current round of GC, so that the life of the object can continue for one GC cycle.
SetFinalizer` to specify a callback function before each pipe buffer is put back into the pipe pool, and use the system call in the function to close the pipe, then you can use Go’s GC mechanism to actually recycle the pipe buffers periodically, thus achieving an elegant pipe pool in Go, the relevant commits are as follows.
- internal/poll: implement a pipe pool for splice() call
- internal/poll: fix the intermittent build failures with pipe pool
- internal/poll: ensure that newPoolPipe doesn’t return a nil pointer
- internal/poll: cast off the last reference of SplicePipe in test
The introduction of pipe pools for Go’s splice has had the following performance improvements.
|
|
Compared to creating & destroying pipe buffers directly, pipe pool-based multiplexing reduces time consumption by more than 99% and memory usage by 100%.
Of course, this benchmark is a pure access operation without any specific business logic, so it is a very idealized test and not fully representative of the production environment, but the introduction of pipe pools will definitely improve the performance of high-frequency zero-copy operations based on splice using Go’s io standard library by orders of magnitude.
Summary
By implementing a pipe pool for Go, there are various concurrency and synchronization optimization ideas involved, so let’s summarize them.
- Resource reuse, the most effective means of improving concurrent programming performance must be resource reuse, which is also the most immediate optimization.
- Data structure selection, arrays support O(1) random access and better use of CPU cache, but these advantages are not obvious in the pool scenario, because the resources in the pool have equivalence and single access (non-batch) operations, arrays require pre-allocation of fixed memory and additional memory management burden when scaling, chains are discarded as they are taken, and naturally support dynamic Scaling.
- There are two ways of thinking about the optimization of global locks. One is to try to downgrade the granularity of locks based on the characteristics of the resource, and the other is to try to stagger access to the resource by introducing local caches to reduce the frequency of competing global locks, and to choose user state locks appropriately based on the actual scenario.
- Take advantage of the language runtime. Languages like Go and Java, which come with a huge GC, are generally no match for GC-free languages like C/C++/Rust in terms of performance, but there are pros and cons to everything, and languages that come with runtime also have unique advantages. For example, HAProxy’s pipe pool is a C implementation, and the pipe buffers created during the life of the process will always be there to consume resources (unless they are actively closed, but it is difficult to control the timing accurately), while Go’s pipe pool can use its own runtime to clean up periodically and further reduce resource consumption.