Containerized applications managed by cloud-native platforms have no control over their lifecycle, and to be good cloud-native , they must listen to events issued by the management platform and adjust their lifecycle accordingly. The hosted lifecycle model describes how applications can and should react to these lifecycle events.
Existence of problems
health probes we explain why containers provide APIs for different health checks. health check APIs are read-only endpoints that the platform constantly probes to gain insight into the application. it is a mechanism for the platform to extract information from the application.
In addition to monitoring the state of the container, the platform may sometimes issue commands and expect the application to react to them. Driven by policy and external factors, the cloud-native platform may decide to start or stop its managed applications at any given moment. It is up to the containerized application to decide which events are important to react to and how to react. But in reality, this is an API that the platform is using to communicate with the application and send commands. Also, if the application does not need this service, they are free to benefit from lifecycle management or ignore it.
Solution
We see that checking only the process state does not give a good indication of the health of the application. That’s why there are different APIs to monitor the health of containers. Similarly, just using the process model to run and stop a process is not good enough. Real-world applications need more fine-grained interaction and lifecycle management capabilities. Some applications need help warming up, and some applications need to shut down processes gracefully and without caching. For this and other use cases, some events, as shown in Figure 1-1, are emitted by the platform and the container can listen and react when needed.
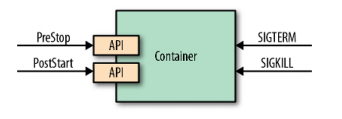
The deployment unit of an application is a Pod. as you already know, a Pod consists of one or more containers. At the Pod level, there are other constructs, such as init containers, init Containers (and defer-containers, which are still in the proposal stage as of this writing), that can help manage the lifecycle of a container. The events and hooks we describe in this chapter are applied at the individual container level rather than the Pod level.
SIGTERM Signal
Whenever Kubernetes decides to shut down a container, either because the Pod it belongs to is shutting down or simply because a failed liveness probe caused the container to restart, the container receives a SIGTERM signal. SIGTERM is a gentle poke before Kubernetes sends a more abrupt SIGKILL signal to the container, allowing it to shut down cleanly. Applications should shut down as soon as they receive a SIGTERM signal. For some applications, this may be a quick termination, while others may have to finish their in-flight requests, release open connections, and clean up temporary files, which may take slightly longer. In all cases, reacting to SIGTERM is the right moment and clean way to close the container.
SIGKILL Signal
If a container process is not shut down after the SIGTERM signal is issued, it is forced to shut down by the following SIGKILL signal Kubernetes does not send the SIGKILL signal immediately, but waits a default grace period of 30 seconds after the SIGTERM signal is issued. This grace period can be defined for each Pod using the .spec.terminalGracePeriodSeconds field, but is not guaranteed as it can be overridden when issuing commands to Kubernetes. The goal here should be to design and implement containerized applications with ephemeral and fast start-up and shutdown processes.
Poststart Hook
There are limitations to using only process signals to manage the lifecycle. That’s why Kubernetes provides additional lifecycle hooks such as postStart and preStop. The Pod manifest that contains the postStart hook looks like the one in Example 5-1.
|
|
The postStart command waits here for 30 seconds. sleep just simulates any lengthy startup code that might run here. Also, it uses a trigger file here to synchronize with the main application, which is started in parallel.
The postStart command is executed asynchronously with the main container’s processes after the container is created. Even though much of the application initialization and warm-up logic can be implemented as part of the container startup step, postStart still covers some use cases. postStart action is a blocking call and the container state remains as Waiting until the postStart handler completes, which in turn keeps the Pod state as Pending. This nature of postStart can be used to delay the start-up state of the container while giving time for the main container process to initialize.
Another use of postStart is to prevent the container from starting when the Pod does not meet certain prerequisites. For example, when the postStart hook indicates an error by returning a non-zero exit code, the main container process is killed by Kubernetes.
The postStart and preStophook calling mechanisms are similar to the health probes described and support these handler types.
- exec runs commands directly in the container
- httpGet performs an HTTP GET request to a port that the Pod container is listening on.
You must be very careful about executing the critical logic in the postStart hook, as its execution is not guaranteed. Since the hook is running in parallel with the container process, it is possible that the hook will be executed before the container starts. Also, the hook is intended to have semantics at least once, so the implementation must take care of repeated executions. Another aspect to note is that the platform does not perform any retry tries for failed HTTP requests that do not reach the handler.
Prestop Hook
The preStop hook is a blocking call sent to the container before it is terminated. It has the same semantics as the SIGTERM signal and should be used to gracefully close the container when it is not possible to respond to SIGTERM. It has the same semantics as the SIGTERM signal and should be used to initiate a graceful shutdown of the container when no response to SIGTERM is possible. The preStop action in Example 1-2 must be completed before the call to delete the container is sent to the container runtime, which triggers a SIGTERM notification.
Even though preStop is blocking, holding it down or returning an unsuccessful result does not prevent the container from being deleted and the process from being killed. preStop is just a convenient alternative to the elegant application of the SIGTERM signal, nothing more. It also provides the same types of handlers and guarantees as the postStart hooks we described earlier.
Other Lifecycle Controls
So far in this chapter, we have focused on hooks that allow commands to be executed when a container lifecycle event occurs. But another mechanism allows the execution of initialization commands not at the container level, but at the Pod level.
The Init container, in depth, but here we briefly introduce it, comparing it to lifecycle hooks. Unlike normal application containers, the init container runs sequentially, until it is finished, and before any of the application containers in the Pod are started. These guarantees allow the use of the init container for Pod-level initialization tasks. Both lifecycle hooks and init containers run at different granularities (at the container level and Pod level, respectively) and can be used interchangeably in some cases, or complement each other in others. Table 1-1 summarizes the main differences between the two.
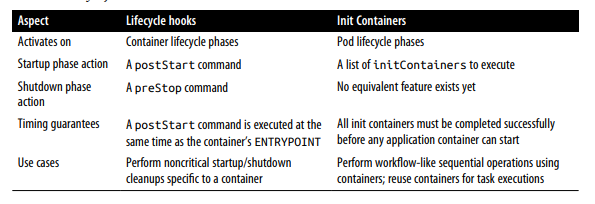
There are no strict rules about which mechanism to use, except when you need specific time guarantees. We could skip the lifecycle hooks and initialize the container altogether and use a bash script to perform specific actions as part of the container start or shutdown command. This is possible, but it would tightly couple the container to the script and turn it into a maintenance nightmare.
We could also use Kubernetes lifecycle hooks to perform some of the actions described in this chapter. Alternatively, we can go a step further and run containers that use the init container to perform individual actions. In this sequence, these options increasingly require more enhancements, but also provide stronger guarantees and enable reuse.
Understanding the phases of the container and Pod lifecycle and available hooks is critical to creating Kubernetes managed applications.
Discussion
One of the primary benefits provided by cloud-native platforms is the ability to reliably and predictably run and scale applications on top of potentially unreliable cloud infrastructure. These platforms provide a set of constraints and consensus for the applications running on them. To benefit the application, all of the functionality provided by the cloud-native platform adheres to these mechanisms. Handling and responding to these events ensures that your application can be launched and closed gracefully with minimal impact on the consuming service. Currently, in its basic form, this means that containers should behave like any well-designed POSIX process. In the future, there may be more events to give the application hints when it is about to be scaled up, or requests to free resources to prevent being shut down. It is important to get into the mindset that the lifecycle of an application is no longer controlled by a human, but fully automated by the platform.