What is a CRD
CRD itself is a Kubernetes built-in resource type, which stands for CustomResourceDefinition, and can be viewed with the kubectl get command to see the CRD resources defined within the cluster.
After talking to people about CRD, I found that there are some common misconceptions about CRD, so some concepts need to be clarified in advance:
- In Kubernetes, everything is called a Resource, as described in the Kind item in Yaml.
- But in addition to the usual built-in resources like Deployment, Kube allows user-defined resources, or CRs. 3.
- a CRD is not really a custom resource, but rather a definition of our custom resource (to describe what our defined resource looks like)
For a CRD, it is essentially an Open Api schema, and as a Kuber Blog post (https://kubernetes.io/blog/2019/06/20/crd-structural-schema/) says, both R and CR need Yaml to But how to ensure that the resources described by Yaml are canonical and legal is what the schema does, and the CRD, in its function, is to register a new resource with the cluster and tell the ApiServer how this resource is legally defined.
Controller Mode
Before we get into the specifics of CRD, let’s briefly explain the controller model. If you know anything about Kubernetes, you know that we can manage Pods by creating Deployment, but Deployment doesn’t create Pods directly, but Deployment manages RS, and RS manages Pods, which is actually the controller mode.

The controller pattern allows higher-order controllers to be defined based on existing resources to achieve more complex capabilities, but of course, the specifics have to be more complex.
What CRD can do
In general, the CR we define with CRD is a new controller, and we can customize the logic of the controller to do some functions that are not natively supported by Kubernetes clusters.
To take a concrete example, I created a simple CRD (https://github.com/Coderhypo/KubeService) with Kubebulder to try to build microservice management into a Kubernetes cluster.
I created two resources, one called App, which is responsible for managing the entire application lifecycle, and the other called MicroService, which is responsible for managing the lifecycle of microservices.
The specific logical structure can be understood as follows.
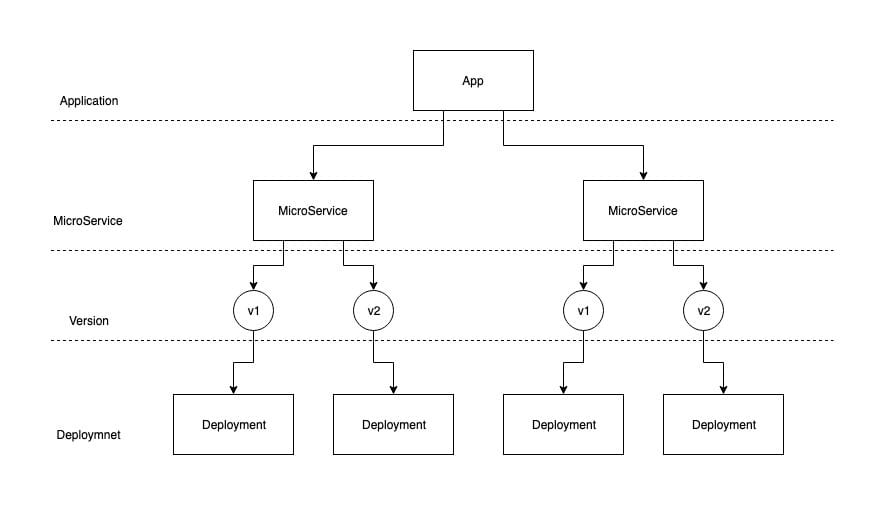
The App can directly manage multiple MicroServices, and each MicroService supports multiple versions, and thanks to the controller model, MicroService can create a Deployment for each version, allowing multiple versions to be deployed at the same time.
If managing application deployments is too simple, MicroService supports creating Service and Ingress for each microservice to enable four-tier load balancing and seven-tier load balancing.
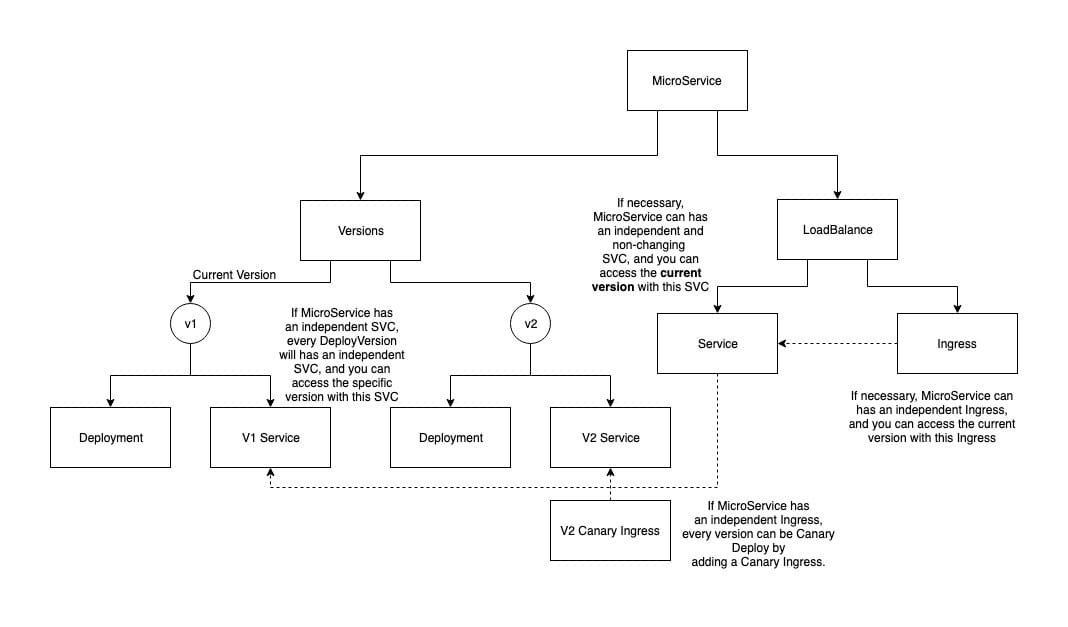
And, if load balancing is enabled, MicroService will create a Service for each version, so a service will have n + 1 SVCs, where n is one for each version and the extra 1 is an SVC that will not change (name and clusterIP) after the microservice is created, and the Selector of this SVC will always be the same as the CurrentVersion SVC.
In other words, there is a stable SVC that provides the current version of the service to other components, and other components have access to a specific version of the service. This SVC + CurrentVersion makes it very easy to implement the Blue-Green publishing capability.
In addition to SVC, MicroService also implements grayscale publishing based on the capabilities of the nginx ingress controller, and by modifying the canary configuration in LoadBalance, you can achieve grayscale publishing by scale/header/cookie.
In this example, App and MicroService do not create new capabilities, but implement new functionality just by combining resources already available in Kubernetes.
But is there any new value to App and MicroService beyond quickly bluegreening and graying out microservices? Another unseen value is the standardization of management, where any operation under the application previously needed to be translated into “Kube language”, i.e., to that Deployment or Ingress management, can now be managed with a unified entry point normalization.
Summary
It’s easy to generalize with a simple little demo to describe what CRD is. From my current thinking, I think CRD has two very important capabilities.
First, functionally, CRD turns the resources and capabilities already available in Kubernetes into Lego blocks that we can easily use to extend capabilities that Kubernetes does not have natively.
Secondly, products based on Kubernetes inevitably require us to align product terminology with Kube terminology, such as a service is a Deployment, an instance is a Pod, and so on. But CRD allows us to create our own concepts (or resources) based on the product and let Kube’s existing resources serve our concepts, which allows the product to be more focused on the scenario it solves rather than how to think about applying the scenario to Kubernetes.