This article is based on reading the source code of Kubernetes v1.22.1
Kubelet allows nodes to be evicted if they are under-resourced. I have recently studied Kubelet’s eviction mechanism and found a lot to learn from it, so I’ll share it with you.
Kubelet Configuration
Kubelet’s eviction feature needs to be turned on in the configuration, and the threshold value for eviction needs to be configured.
|
|
Among them, EvictionHard means hard eviction, once the threshold is reached, it will be evicted directly; EvictionSoft means soft eviction, i.e., you can set the soft eviction period, only after the soft eviction period is exceeded, the period is set with EvictionSoftGracePeriod; EvictionMinimumReclaim means setting the minimum available threshold, such as imagefs.
The eviction signals that can be set are.
- memory.available: node.status.capacity[memory] - node.stats.memory.workingSet, the node’s available memory.
- nodefs.available: node.stats.fs.available, the size of the available capacity of the file system used by Kubelet.
- nodefs.inodesFree: node.stats.fs.inodesFree, the number of inodes available on the file system used by Kubelet.
- imagefs.available: node.stats.runtime.imagefs.available, the available capacity of the filesystem used to store images and container writable layers during container runtime.
- imagefs.inodesFree: node.stats.runtime.imagefs.inodesFree, the available inodes capacity of the file system used to store images and container writable layers when the container is running.
- allocatableMemory.available: the amount of available memory reserved for allocating Pods.
- pid.available: node.stats.rlimit.maxpid - node.stats.rlimit.curproc, the available PID to allocate Pods with.
How Eviction Manager works
The main work of Eviction Manager is in the synchronize function. There are two places where the synchronize task is triggered, the monitor task, which is triggered every 10s, and the notifier task, which is started to listen for kernel events based on user-configured eviction signals.
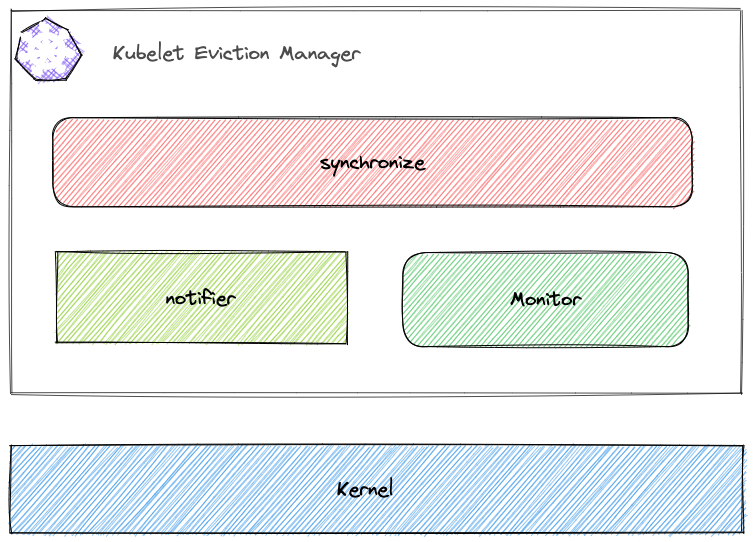
notifier
The notifier is started by the thresholdNotifier in the eviction manager, each eviction signal configured by the user corresponds to a thresholdNotifier, and the thresholdNotifier and notifier communicate through the channel When a notifier sends a message to the channel, the corresponding thresholdNotifier triggers a synchronize logic.
The notifier uses the kernel’s cgroups Memory thresholds. cgroups allows the user state process to set the kernel to send a notification to the application when memory.usage_in_bytes reaches a certain threshold via eventfd. This is done by writing "<event_fd> <fd of memory.usage_in_bytes> <threshold>" to cgroup.event_control.
The initialization code for notifier is as follows (some extraneous code has been removed for readability), mainly to find the file descriptor watchfd for memory.usage_in_bytes and controlfd for cgroup.event_control and to complete the cgroup memory thrsholds are registered.
|
|
The notifier also listens for the above eventfd via epoll at boot time, and sends a signal to the channel when it listens for an event sent by the kernel indicating that the memory used has exceeded the threshold.
|
|
The synchronize logic determines whether the notifier has been updated in 10s and restarts the notifier each time it is executed. The cgroup memory threshold is calculated by subtracting the total amount of memory from the user-set eviction threshold.
synchronize
Eviction Manager’s main logic synchronize is more detailed, so we won’t post the source code here, but we will sort out the following matters.
- constructing a sorting function for each signal.
- update
thresholdand restartnotifier. - get the current node’s resource usage (cgroup information) and all active pods.
- for each signal, determine separately whether the resource usage of the current node has reached the eviction threshold, and if none of them have, exit the current loop.
- prioritize all signals, with the priority being that memory-related signals are evicted first.
- send an eviction event to the apiserver.
- prioritize all active pods.
- evict the pods in the sorted order.
Calculate the eviction order
The order of eviction of pods depends on three main factors.
- whether the pod’s resource usage exceeds its requests.
- The priority value of the pod.
- the memory usage of the pod.
The order in which the three factors are judged is also based on the order in which they are registered into orderedBy. The multi-level ordering of the orderedBy function is also a worthwhile implementation in Kubernetes, so interested readers can check the source code for themselves.
|
|
Eviction Pod
Next is the implementation of eviction Pod. Eviction Manager evicts Pods with a clean kill, the specific implementation is not analyzed here, it is worth noting that there is a judgment before eviction, if IsCriticalPod returns true then no eviction.
|
|
Then look at the code for IsCriticalPod.
|
|
From the code, if the Pod is Static, Mirror, Critical Pod are not evicted. Static and Mirror are judged from the annotation of Pod; Critical is judged by the Priority value of Pod, if the Priority is system-cluster-critical / system-node-critical, it belongs to Critical Pod.
However, it is worth noting that the official documentation refers to Critical Pods as saying that if a non-Static Pod is marked as Critical, it is not completely guaranteed not to be evicted. Therefore, it is likely that the community has not thought through whether to evict in this case, and does not rule out changing this logic later, but it is also possible that the documentation is not up to date.
Summary
This article analyzed Kubelet’s Eviction Manager, including its listening to Linux CGroup events and determining Pod eviction priorities. Once we understand this, we can set the priority according to the importance of our application, even set it to Critical Pod.