The program itself doesn’t need to care where its data and code live, and memory appears to be contiguous and exclusive to the program. This is certainly not the case, and it is the operating system that is responsible for this - memory virtualization. This article describes how the operating system implements a virtual memory system.
Address Space
The operating system provides an easy-to-use abstraction of physical memory: the address space. The address space is the memory in the system that a running program sees.
A process’s address space contains all the memory state of a running program. Each time a memory reference is made, the hardware performs an address translation that redirects the application’s memory reference to an actual location in memory.
To perform the address translation, each CPU requires two hardware registers: the base register and the bound register. The starting address of the program is stored in the base address register. All memory references generated by the process are converted to physical addresses by the processor in the following way.
|
|
The purpose of the bounding register is to ensure that all addresses generated by the process are in the address “boundaries” of the process.
What the operating system does
The operating system and hardware support combine to implement virtual memory, and the work that the operating system needs to do in order to implement virtual memory is as follows.
- At process creation, the OS must find memory space for the process’s address space.
- When a process terminates, the OS must reclaim all its memory for use by other processes or the OS.
- At context switch, the operating system must save and restore the base address and boundary registers. Specifically, the operating system must save the contents of the current base address and boundary registers in memory in some sort of structure that is common to every process, such as a process structure or process control block; it must also set the correct values for the base address and boundary registers when the operating system resumes execution of a process.
- The operating system must provide exception handlers.
Segmentation
To solve the problem of wasted contiguous memory, the operating system introduces segmentation.
Specifically, more than one base address and boundary register pair is introduced in the MMU, but a pair for each logical segment in the address space. A segment is simply a contiguous area of fixed length in the address space, and in a typical address space there are 3 logically distinct segments: code, stack, and heap.
The segmentation mechanism allows the operating system to place different segments into different physical memory areas, thus avoiding unused parts of the virtual address space from taking up physical memory. This is shown in the following figure.
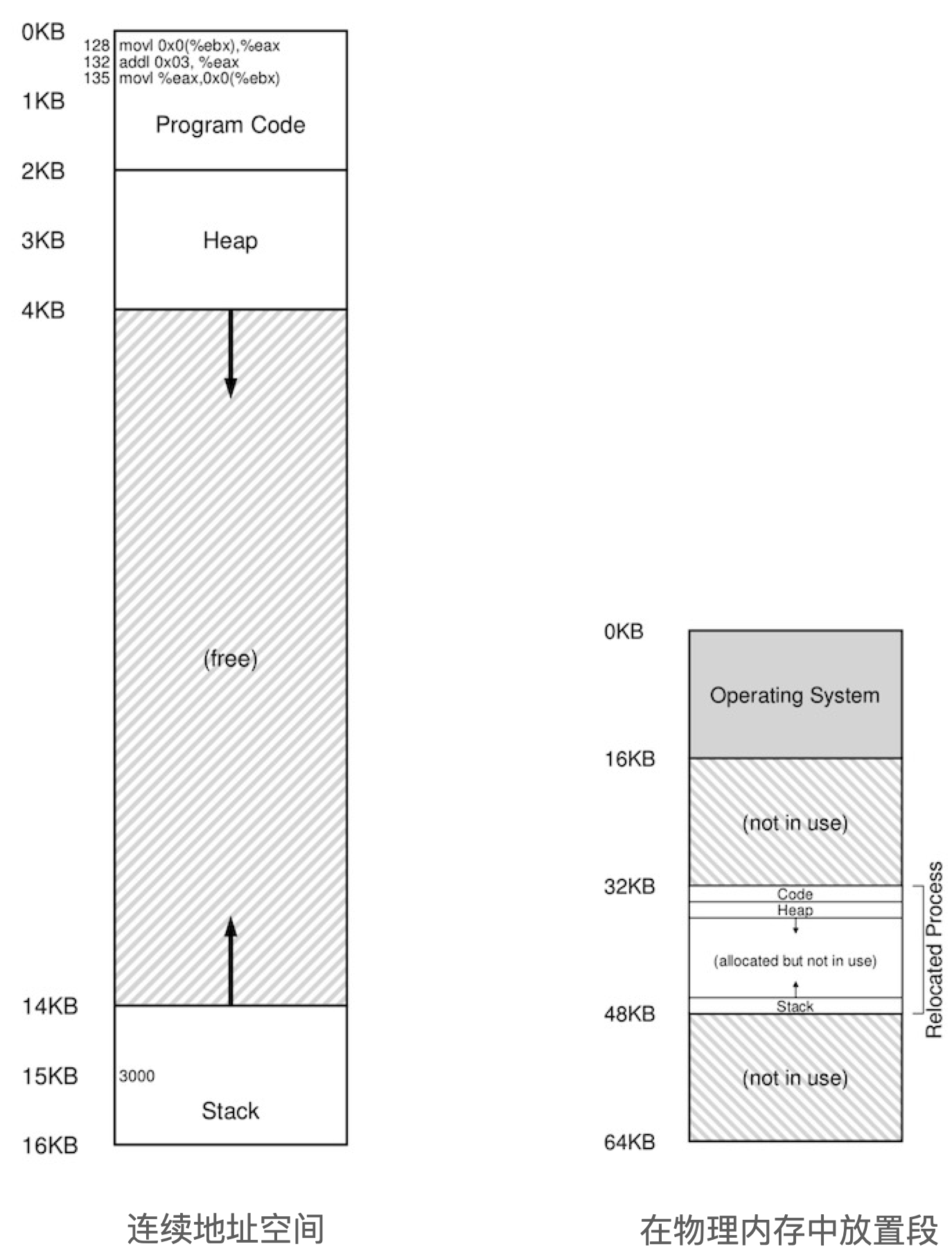
And there are two main methods to identify which segment corresponds to which from a virtual address.
- Explicit method: Use a few bits in the address to indicate which segment corresponds to this address. For example, the top 2 bits of a 14-bit virtual address are used to identify the type of segment.
- Implicit method: The hardware identifies the segment by the way the address is generated. If the address comes from the PC, then it is the access code segment, if it comes from the stack instruction it is the corresponding stack segment, everything else is considered the heap.
Operating system problems
Segmentation introduces some new problems.
The first is that the values of segment registers must be saved and restored. Each process has its own separate virtual address space, and the operating system must ensure that these registers are correctly assigned before the process can run.
The second and more important issue is that segmentation introduces external fragmentation. Free space is split into small pieces of different sizes that become fragmented, and subsequent requests may fail because there is not a large enough contiguous piece of free space, even if the total free space at that point exceeds the size of the request.
One way to address external fragmentation is to compact physical memory and rearrange the original segments, but memory compactness is costly; another simple approach is to use a free-list management algorithm that attempts to reserve large amounts of memory for allocation. Hundreds of approaches are available, including the following classical algorithms.
- best fit: first iterate through the entire free-list to find a free block of the same size as the request or larger, and then return the smallest block in the set of candidates. Traversing the free list only once is enough to find the correct block and return it. However, simple implementations pay a higher performance price when traversing to find the correct free block.
- Worst fit: In contrast to best fit, it tries to find the largest free block, split it and satisfy the user requirements, and then add the remaining blocks (which are very large) to the free list. Worst fit tries to keep the larger blocks in the free list instead of the many small blocks that may be left unused as in the case of best fit. However, worst matching also requires traversing the entire free list. Worse, most studies show that it performs very poorly and leads to excessive fragmentation with a high overhead.
- first fit: The first fit strategy is to find the first block large enough to return the requested space to the user. Again, the remaining free space is left for subsequent requests. First fit has a speed advantage, but sometimes leaves a lot of small blocks at the beginning of the free list.
- next match (next fit): Maintains one more pointer to the location where the last lookup ended. The idea is to spread the lookup operation on the free space to the whole list, avoiding frequent partitioning of the beginning of the list. It is very close to first match and also avoids traversing the lookup.
Some additional improvement strategies.
- Split the free list: If an application frequently requests memory space of one (or several) sizes, then use a separate list that manages only objects of such size. Requests for other sizes are given to a more general memory allocation program.
- Partner system: Free space is first conceptually viewed as a large space of size 2N. When a memory allocation request is made, the free space is recursively divided in half until it is just the right size for the request (any further division will not be possible); if the 8KB block is returned to the free list, the allocator checks to see if the “partner” 8KB is free. If so, it will be merged into one block of 16KB.
However, no matter how clever the algorithm is, external fragmentation still exists and cannot be completely eliminated. The only real solution is to avoid this problem altogether and never allocate blocks of different sizes, which is why paging was introduced.
Paging
Rather than partitioning a process’s address space into several logical segments of different lengths (i.e., code, heap, segments), paging divides it into fixed-size cells, each of which is called a page. Accordingly, we think of physical memory as an array of fixed-length slot blocks, called page frames. Each page frame contains one virtual memory page.
Page table
The operating system keeps a data structure for each process, called a page table. It is primarily used to hold address translations for each virtual page in the address space, thus allowing us to know where each page is located in physical memory.
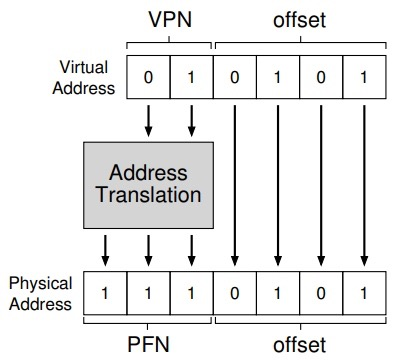
The virtual address is divided into two components: the virtual page number (VPN) and the offset within the page (offset)
With the virtual page number, we can now retrieve the page table and find the physical page where the virtual page is located. Therefore, we can convert this virtual address by replacing the virtual page number with the physical frame number and then send the load to physical memory. The offset stays the same, because the offset just tells us which byte in the page is the one we want. This is shown in the following figure.
In short, a page table is a data structure for mapping virtual addresses (or, in fact, virtual page numbers) to physical addresses (physical frame numbers). So any data structure can be used, and the simplest form becomes a linear page table, which is an array. The operating system retrieves this array by the virtual page number (VPN) and looks up the page table entry (PTE) at that index to find the desired physical frame number (PFN).
Bottlenecks for paging
For each memory reference, paging requires us to perform an additional memory reference in order to fetch the address translation from the page table in the first place. The overhead of the extra memory reference is significant and in this case can slow down the process by a factor of two or more.
While paging appears to be a good solution to the memory virtualization requirement, these two key issues must be overcome first.
Combination of paging and segmentation
To solve the problem of excessive page table memory overhead, the creators of Multics came up with the idea of combining paging and segmentation. The solution is to provide not a single page table for the entire address space of the process, but a page table for each logical segmentation.
In a segment, there is a base address register to hold the location of each segment in physical memory, and a bounds register to hold the size of that segment. These structures are still used here, but instead of pointing to the segment itself, the base address holds the physical address of the segment’s page table; the bounds register is used to indicate the end of the page table (i.e., how many valid bits it has).
The key difference in this heterogeneous scheme is that each segment has bounds registers, and each bounds register holds the value of the largest valid page in the segment. For example, if the segment uses the first 3 pages, the segment page table will have only 3 entries allocated to it and the bounds register will be set to 3. Compared to linear page tables, the promiscuous approach achieves significant memory savings in that unallocated pages between the stack and heap no longer occupy space in the page table (only marking them as invalid).
The disadvantages of this approach are, first, that it still requires the use of segments, which can still lead to significant page table waste if there is a large and sparse heap, and second, that external fragmentation reappears, and although most memory is managed in page table size units, page tables can now be of arbitrary size (multiples of PTEs).
Multi-level page tables
Multilevel page tables are also used to solve the problem of page tables taking up too much memory by removing all the invalid areas of the page table instead of keeping them all in memory. Multilevel page tables turn a linear page table into a tree.
First, the page table is divided into page-sized cells; then, if an entire page’s page table entry (PTE) is invalid, no page table is allocated for that page at all. To keep track of whether the page table is also valid (and, if so, where it is in memory), a new structure called a page catalog is used. The page catalog can tell you where the pages of the page table are, or if the entire page of the page table does not contain a valid page.
The figure below shows an example of a classical linear page table on the left, where we need to allocate page table space for most of the middle regions of the address space even if they are not valid (i.e., the middle two pages of the page table), and a multilevel page table on the right, where the page directory allocates page table space to only those regions (i.e., the first and last) and those two pages of the page table reside in memory. Thus, we can visualize how a multilevel page table works: just let a part of the linear page table disappear (freeing these frames for other uses) and use the page directory to record which pages of the page table are also allocated.
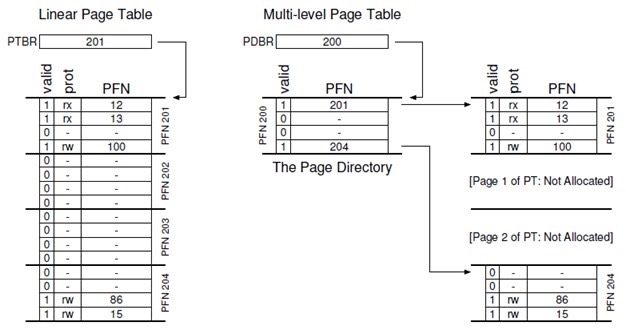
In a simple two-level page table, the page directory contains one item for each page table. A PDE consists of multiple page directory entries (PDEs) that have at least a valid bit and a page frame number (PFN), similar to a PTE, but the meaning of the valid bit is slightly different: if the PDE entry is valid, it means that at least one page in the page table (via the PTE) to which the entry refers is valid, i.e., at least one PTE in the page to which the PDE refers, with its valid bit set to 1. If the PDE entry is invalid, the rest of the PDE is undefined.
Benefits of Multilevel Page Tables
Multilevel page tables allocate page table space in proportion to the amount of address space memory you are using, so they are typically compact and support sparse address spaces.
If carefully constructed, each part of the page table can fit neatly into a page, making it easier to manage memory. With multilevel page tables, we add an indirection layer that uses a page directory that points to the various parts of the page table, an indirection that allows us to place page table pages anywhere in physical memory.
Disadvantages of multilevel page table
Multi-level page tables come at a cost, requiring two loads from memory to get the correct address translation information from the page table when the TLB is not hit (one for the page directory and the other for the PTE itself), whereas with a linear page table only one load is required.
Another obvious disadvantage is the complexity. Whether it is the hardware or the operating system that handles page table lookups, doing so is undoubtedly more complex than a simple linear page table lookup.
TLB
To solve the problem of extra memory accesses caused by paging, the operating system needs some extra help, hence the introduction of the address translation bypass buffer register (TLB), the hardware cache for the frequently occurring virtual-to-physical address translation.
Basic algorithm
first extracts the page number (VPN) from the virtual address, then checks if the TLB has a translation map for that VPN.
If so, we have a TLB hit, meaning that the TLB has a translation mapping for that page and the page consultation number (PFN) can be extracted from the associated TLB entry and combined with the offset in the original virtual address to form the desired physical address.
If not (TLB not hit), it behaves differently in different systems:.
- Hardware-managed TLB (older architectures, such as x86): When a miss occurs, the hardware traverses the page table, finds the correct page table entry, takes out the desired translation map, and updates the TLB with it.
- Software-managed TLB (more modern architectures): In case of a miss, the hardware system throws an exception, suspends the current instruction flow, raises the privilege level to kernel mode, and jumps to a trap handler (a piece of OS code). This trap handler then looks for a translation map in the page table, updates the TLB with a special “privileged” instruction, and returns from the trap. At this point, the hardware retries the instruction (resulting in a TLB hit).
Handling of TLBs during context switches
The virtual-to-physical address mapping contained in the TLB is only valid for the current process and has no meaning for other processes. Therefore, there are two ways to manage the TLB during context switch.
simply clears the TLB
In the case of a software-managed TLB system, this can be done with an explicit instruction when a context switch occurs; in the case of a hardware-managed TLB system, the TLB can be cleared when the contents of the page table base address register change. in either case, the case operation is to set all valid locations to 0, essentially clearing the TLB.
However, this method has some overhead: every time a process runs, it triggers a TLB miss when it accesses data and code pages, which can be high if the OS switches processes frequently.
TLB sharing for cross-context switching
Add hardware support to implement TLB sharing across context switches. For example, some systems add an address space identifier (ASID) to the TLB, which can be thought of as a process identifier, but usually with one less bit than the PID. the TLB can thus cache address space mappings of different processes at the same time without any conflicts.
Swap space
In order to support a larger address space, the operating system needs to find a place to store the portion of address space that is not currently in use. Hard disks usually meet this need, and in our storage hierarchy, large, slow hard disks sit at the bottom, above memory. Adding swap space gives the operating system the illusion of huge address space for multiple concurrently running processes.
Opening up a portion of space on the hard disk for physical pages to be moved in and out is called swap space in the operating system, as we swap pages from memory into it and back out again when needed. Therefore, we will assume that the operating system can read or write to the swap space in units of page size, for this purpose.
Presence Bits
The hardware uses the presence bit in the page table to determine if it is in memory. If the presence bit is set to 1, the page exists in physical memory and all content is proceeding normally; if the presence bit is set to 0, the page is not in memory, but on the hard disk.
Page error
The behavior of accessing a page that is not in physical memory is often referred to as a page error. This is when the “Page Error Handler” is executed to handle page errors.
The process for handling page errors.
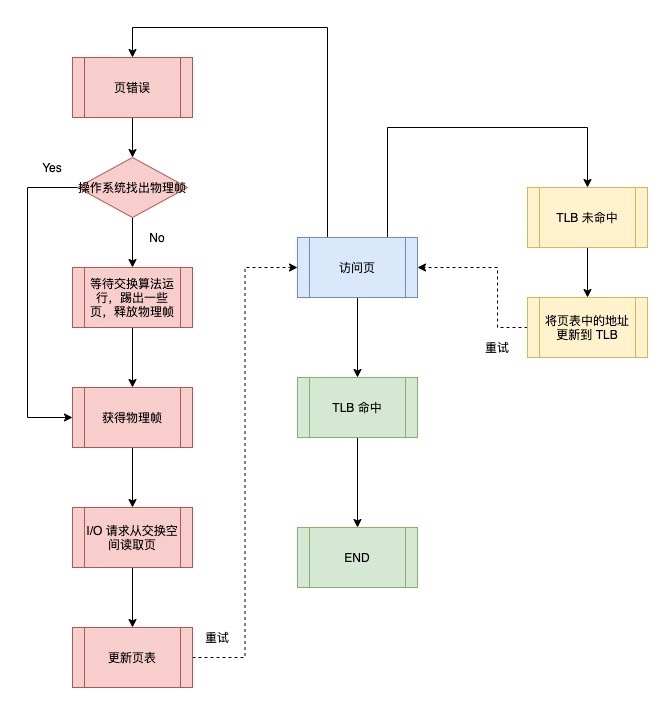
As shown above, when the OS receives a page error, it first looks for an available physical frame, and if it cannot find one, the OS performs a swap algorithm that kicks out some pages, frees the physical frame, and sends the request to the hard disk to read the page into memory.
When the hard disk I/O completes, the OS updates the page table, marks this page as present, updates the PFN field of the page table entry to record the memory location of the newly fetched page, and retries the command. The next re-access to the TLB is still a miss, however this time the address in the page table is updated to the TLB because the page is in memory.
The final retry operation finds the translation map in the TLB and fetches the desired data or instruction from the physical address of the converted memory.
Swap Occurrence Time
To ensure that there is a small amount of free memory, most operating systems set a high water mark (HW) and a low water mark (LW).
The principle is that when the OS finds less than LW pages available, a background thread responsible for freeing memory will start running until there are HW physical pages available. This background thread, sometimes called the swap daemon or page daemon, then goes to sleep.
Swap Policy
When there is not enough memory, as memory pressure forces the operating system to swap out some pages to make room for commonly used pages, determining which pages to kick out is encapsulated in the operating system’s replacement policy. There are many swap policies, as follows.
Optimal swap policy
The optimal replacement policy achieves the lowest number of overall misses, i.e., replacing pages in memory that will not be accessed until the furthest future, and can achieve the lowest cache miss rate. However, it is difficult to implement.
Simple Policy (FIFO)
The FIFO policy, where pages are simply put into a queue as they enter the system, and pages at the end of the queue are kicked out when a replacement occurs.
FIFO has one big advantage: it is fairly simple to implement. However, there is no way to determine the importance of a page, and FIFO will kick out page 0 even if it has been accessed multiple times. And FIFO causes a Belady exception.
Least Recently Used (LRU)
The LRU policy is to replace the least recently used pages.
LRU currently appears to outperform FIFO and random policies, but as the number of pages in the system grows, it is too costly to scan the time field of all pages just to find the most accurate least used page.
Clock Algorithm (Clock)
The Clock algorithm is an approximation to LRU and is the practice of many modern systems. The algorithm requires the hardware to add a usage bit.
Procedure.
- All pages in the system are placed in a circular list, with the clock pointer starting out pointing to a particular page.
- When a page replacement must be performed, the operating system checks the usage bit of the currently pointing page P.
- If it is 1, it means that page P has been used recently and is not suitable for replacement, then it is set to 0 and the clock pointer is incremented to the next page (P + 1).
- continues until a page with a usage bit of 0 is found.
- In the worst case, all pages are used, then all pages are set to 0 with the use bit.
The hardware adds a modification bit considering whether the page in memory has been modified. This bit is set each time a page is written, so it can be merged into the page replacement algorithm. If the page has been modified and is therefore dirty, the proposal has to write it back to disk, which is expensive; if it has not been modified, there is no cost for kicking it out. Therefore, some virtual systems prefer to kick out clean pages rather than dirty pages.
Summary
This article provides a brief summary of the memory virtualization part of the operating system, including segmentation, paging, TLB, and swap space. Through these, the operating system implements a virtual memory system, which ensures that memory is transparent to programs, that programs can access memory efficiently, and that processes are isolated from each other.