Apache Spark is one of the most widely used computational tools for big data analytics today. It excels at batch and real-time stream processing and supports machine learning, artificial intelligence, natural language processing, and data analytics applications. The narrowly defined Hadoop (MR) technology stack is shrinking as Spark becomes more popular and more heavily used. In addition, general opinion and practical experience has proven that Hadoop (YARN) does not have the flexibility to integrate with a broader enterprise technology stack, except for Big Data-related workloads. This is where Kubernetes (K8s) excels, for example, to host online businesses. In fact, the emergence of Kubernetes opens the door to a new world of opportunities to improve Spark. It would also be fascinating to run all online and offline jobs with a unified set of clusters.
Spark on Kubernetes was introduced in Spark 2.3 and by the time Spark 3.1 community marked GA, it was basically ready to be used at scale in production environments.

In the industry, companies such as Apple, Microsoft, Google, NetEase, Huawei, Drip, and Jingdong have all had classic success stories of large-scale internal implementations or external services.
Spark on Kubernetes Application Architecture
From the perspective of Spark’s overall computing framework, it only supports one more scheduler at the resource management level, and all other interfaces can be fully reused. On the one hand, the introduction of Kubernetes and Spark Standalone, YARN, Mesos and Local components form a richer resource management system.
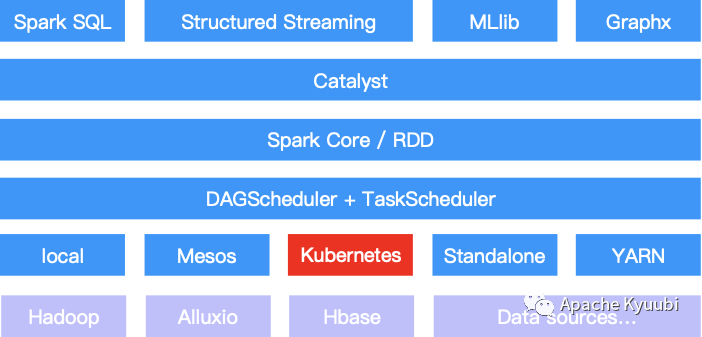
On the other hand, the Spark community supports Kubernetes features while retaining maximum compatibility with user APIs, which greatly facilitates user task migration. For example, for a traditional Spark job, we can switch between the two scheduling platforms by simply specifying the –master parameter as yarn or k8s://xxx. Other parameters such as mirror, queue, Shuffle local disk, etc. are isolated between yarn and k8s, and can be easily maintained in a single configuration file.
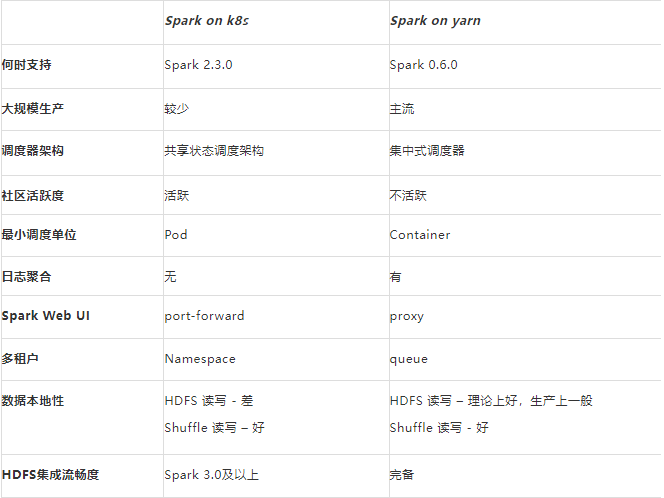
Spark on Kubernetes vs Spark on YARN
Ease of Use Analysis
Spark Native API.
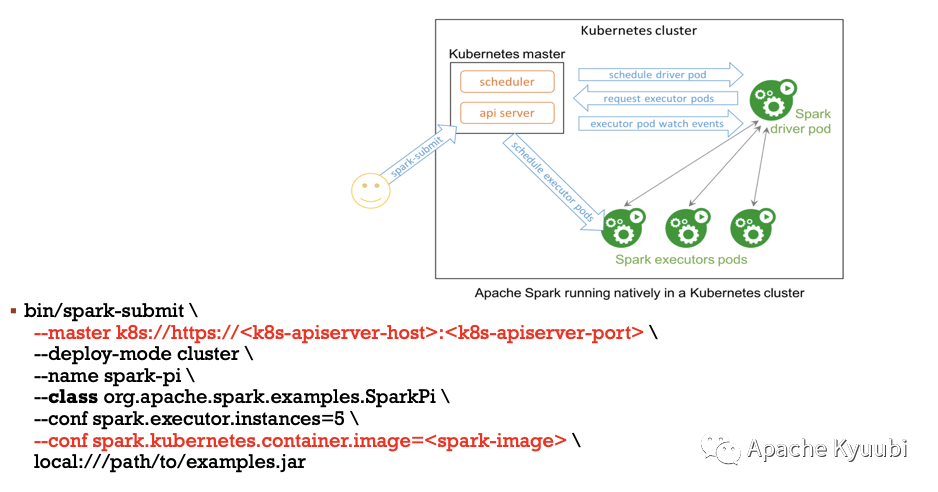
In terms of spark-submit, the traditional way of submitting jobs, as mentioned in the previous article, can be easily submitted to k8s or YARN clusters by configuring isolation, which is basically as simple and easy to use. This approach is very user-friendly for users familiar with the Spark API and ecosystem, and there are basically no hard requirements for the k8s technology stack.
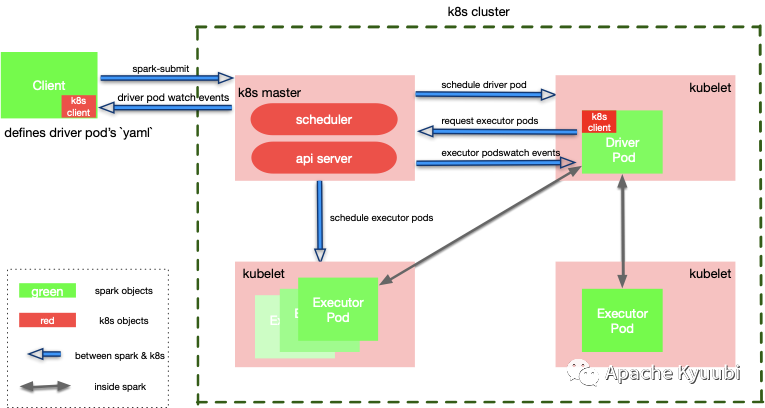
As you can see, if we ignore the underlying details of K8s or YARN, it’s basically the same familiar recipe with familiar flavors.
Spark Operator.
In addition, in addition to this approach, Kubernetes is much richer in terms of APIs. We can create and manage Spark on k8s applications by way of Spark Operator, such as kubectl apply -f. This approach is certainly the most elegant for the Kubernetes cluster itself and its users, while there is a learning cost for this segment of Spark users who have no experience with Kubernetes. Another advantage of this approach is that Spark-related libs can be deploy through Docker repository, and no separate Spark Client environment is needed to submit jobs. A separate Client environment can easily cause inconsistency between version and Docker, which increases the cost of operation and maintenance, and can also lead to some unnecessary online problems.
Serverless SQL.
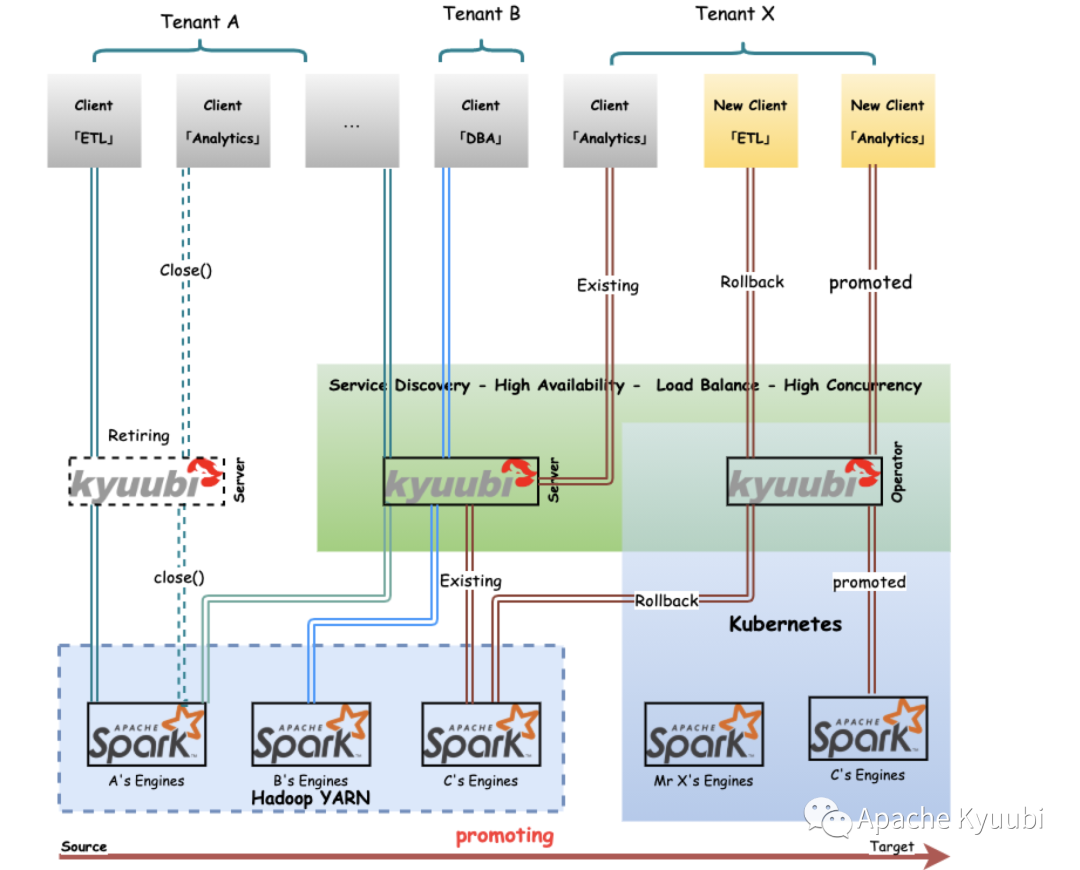
Of course, both the Spark native and Operator approaches are still too primitive for most users, and inevitably require some perception of the underlying details. In the Datalake/Lakehouse scenario, data becomes democratic, data applications become diverse, and it is hard to go to a large scale. To go a step further in terms of ease of use, consider using Apache Kyuubi (Incubating) to build Serverless Spark/SQL services. In most cases, users can just use BI tools or SQL to manipulate data directly.
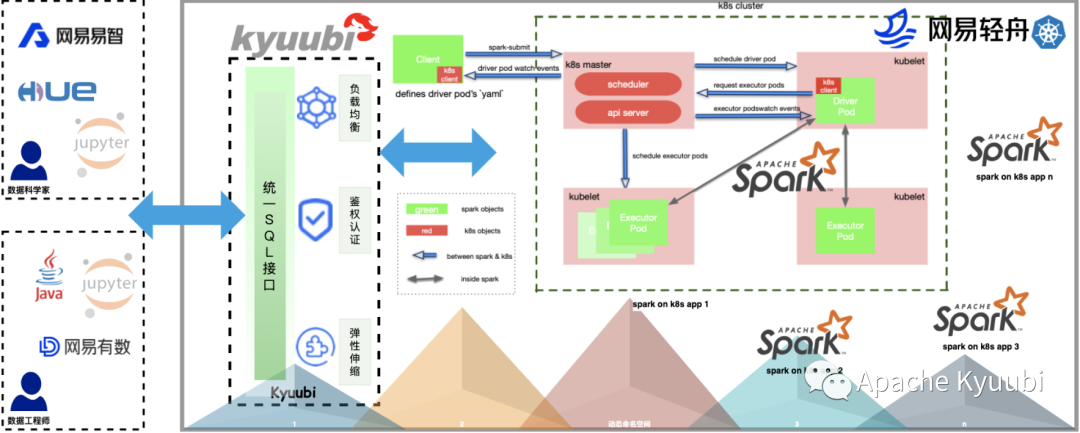
Kyuubi’s service-oriented solution can provide load balancing nodes through service discovery mechanism to smooth the transition on the basis of high service availability. For individual abnormal migration tasks, we can also easily Rollback to the old cluster to ensure the execution, also leaving us time and space to locate the problem.
Performance Comparison
In principle, both Kubernetes and YARN only play the role of resource scheduling and do not involve changes in the computation model and task scheduling, so the difference in performance should not be significant. In terms of deployment architecture, Spark on Kubernetes generally chooses the architecture of storage and computation separation, while YARN clusters are generally coupled with HDFS, and the former will lose “data locality” when reading and writing HDFS, which may affect performance due to network bandwidth factors. After about 10 years of development from the beginning of the store-and-calculate coupled architecture, with the growth of network performance, various efficient columnar storage formats and compression algorithms, this impact is minimal.
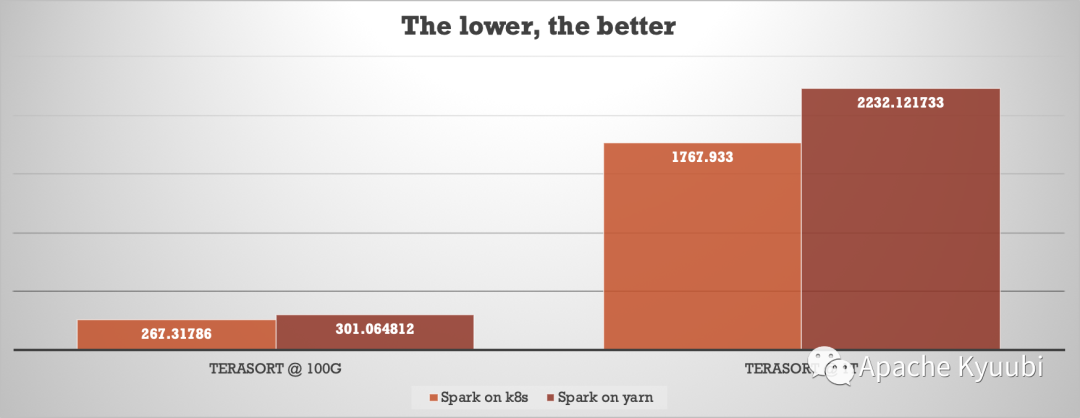
Terasort Benchmarking (By Myself).
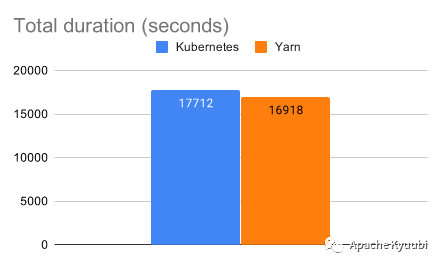
TPC-DS Benchmarking (By Data mechanics).
TPC-DS Benchmarking (By AWS).
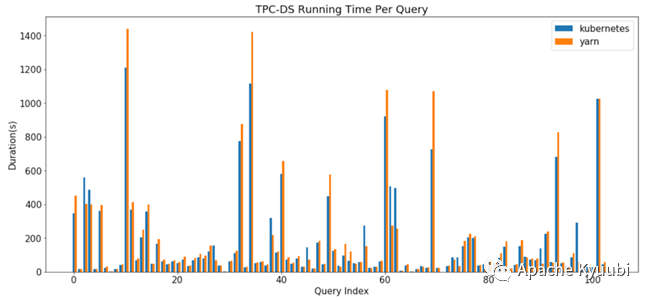
Although none of these test results are official data from the TPC-DS organization certification, there is enough convincing from the factor that the test results are from different organizations. The performance gap between the two can be said to be largely non-existent when we block out some deployment architecture effects.
Cost Comparison
By migrating Spark jobs to Kubernetes clusters, you can achieve mixed deployment of offline and online services, and take advantage of the tidal staggering effect of the two business characteristics on computing resources, which can achieve 50% savings in total useful cost of IT (TCO) just by “off/on mix”.
On the other hand, in different development periods of enterprise data platforms, the planned storage capacity ratio of clusters is different, which makes server selection difficult.
In addition, Spark on Kubernetes assigns Executor mode through Pod, and the number of execution threads (spark.executor.cores) and the request cpu of Pod are separated, which can be more fine-grained at the job level to control and improve the efficiency of using computational resources. In our actual practice in NetEase, the overall cpu of Spark on Kubernetes jobs can reach an overselling ratio of over 200% without affecting the overall computing performance.
Of course, the absence or imperfection of the feature of Dynamic Resource Allocation in Spark on Kubernetes may cause Spark to take up resources and not use them. Since this feature relies directly on the external Shuffle Service to implement, you may need to build Remote/External Shuffle Service service by yourself.
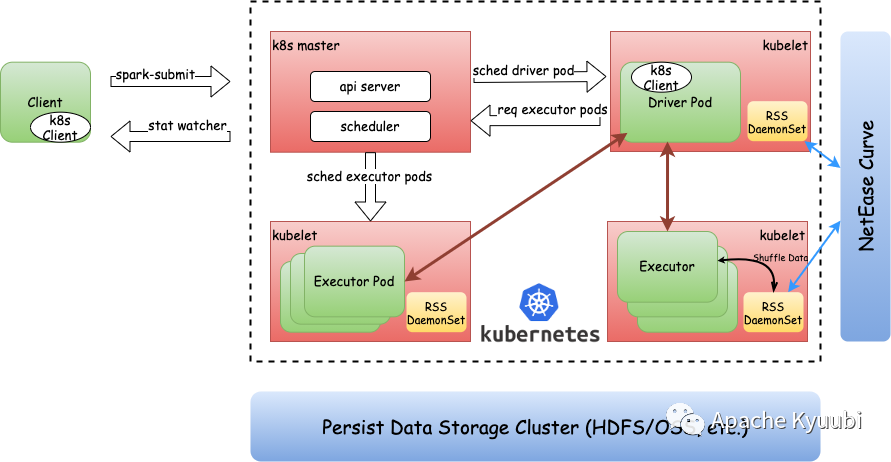
In the Spark on Kubernetes scenario, RSS/ESS-based temporary storage can be decoupled from the computational process. First, it eliminates local storage dependencies, allowing compute nodes to scale dynamically across heterogeneous nodes and to scale more flexibly in the face of complex physical or virtual environments. Second, discrete local storage is optimized to centralized service-oriented storage, and storage capacity is shared among all compute nodes to improve storage resource utilization. Third, reduce the disk failure rate and dynamically reduce the number of compute nodes marked as unavailable to improve the overall resource utilization of the compute cluster. Finally, the lineage of temporary storage is shifted so that it is no longer maintained by Executor Pod compute nodes, allowing idle Executor Pods to be released back to the resource pool in a timely manner and improving cluster resource utilization.
Other comparisons.
Summary
It’s been four years since Spark on Kubernetes was released in early 2018 with version 2.3.0, and now with version 3.2, it has gone through five major releases. It has become a very mature feature under the continuous polishing of the community and users.
As the Apache Spark open source ecosystem continues to evolve, such as Apache Kyuubi, the ease of use of either scheduling framework has improved dramatically.
The total cost of ownership (TCO) of IT infrastructure has been rising year by year, and the flexibility and cost effectiveness of the Spark + Kubernetes combination gives us more room for imagination.