For example, now I have an application with an update policy of Recreate, and then execute the delete command as follows.
1
2
3
4
5
|
☸ ➜ kubectl get pods
NAME READY STATUS RESTARTS AGE
minio-875749785-sv5ns 1/1 Running 1 (2m52s ago) 42h
☸ ➜ kubectl delete pod minio-875749785-sv5ns
pod "minio-875749785-sv5ns" deleted
|
Observe the application status on another terminal before deleting it.
1
2
3
4
5
6
7
8
9
10
11
12
|
☸ ➜ kubectl get pods -w
NAME READY STATUS RESTARTS AGE
minio-875749785-sv5ns 1/1 Running 1 (2m46s ago) 42h
minio-875749785-sv5ns 1/1 Terminating 1 (2m57s ago) 42h
minio-875749785-h2j2b 0/1 Pending 0 0s
minio-875749785-h2j2b 0/1 Pending 0 0s
minio-875749785-h2j2b 0/1 ContainerCreating 0 0s
minio-875749785-sv5ns 0/1 Terminating 1 (2m59s ago) 42h
minio-875749785-sv5ns 0/1 Terminating 1 (2m59s ago) 42h
minio-875749785-sv5ns 0/1 Terminating 1 (2m59s ago) 42h
minio-875749785-h2j2b 0/1 Running 0 17s
minio-875749785-h2j2b 1/1 Running 0 30s
|
As you can see from the above process, the Pod becomes Terminating after we execute the kubectl delete command, and then disappears. Next, we will describe the overall process of deleting a Pod from a code perspective.
Here we will use Kubernetes version v1.22.8 as an example. Other versions are not guaranteed to be identical, but the overall idea is the same.
Delete Status
We can track the status based on what we see after the kubectl operation, the formatting above is done with the code https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/printers/internalversion/printers.go#L88-L102. This is shown below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// TODO: handle errors from Handler
func AddHandlers(h printers.PrintHandler) {
podColumnDefinitions := []metav1.TableColumnDefinition{
{Name: "Name", Type: "string", Format: "name", Description: metav1.ObjectMeta{}.SwaggerDoc()["name"]},
{Name: "Ready", Type: "string", Description: "The aggregate readiness state of this pod for accepting traffic."},
{Name: "Status", Type: "string", Description: "The aggregate status of the containers in this pod."},
{Name: "Restarts", Type: "string", Description: "The number of times the containers in this pod have been restarted and when the last container in this pod has restarted."},
{Name: "Age", Type: "string", Description: metav1.ObjectMeta{}.SwaggerDoc()["creationTimestamp"]},
{Name: "IP", Type: "string", Priority: 1, Description: apiv1.PodStatus{}.SwaggerDoc()["podIP"]},
{Name: "Node", Type: "string", Priority: 1, Description: apiv1.PodSpec{}.SwaggerDoc()["nodeName"]},
{Name: "Nominated Node", Type: "string", Priority: 1, Description: apiv1.PodStatus{}.SwaggerDoc()["nominatedNodeName"]},
{Name: "Readiness Gates", Type: "string", Priority: 1, Description: apiv1.PodSpec{}.SwaggerDoc()["readinessGates"]},
}
h.TableHandler(podColumnDefinitions, printPodList)
h.TableHandler(podColumnDefinitions, printPod)
|
The output for the Pod is obtained using the printPod function, the code is located at: https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/printers/internalversion/printers.go#L756-L840, where there is a section of code that refers to the Terminating value, which is changed to that state if pod.DeletionTimestamp ! = nil. This is shown below.
1
2
3
4
5
|
if pod.DeletionTimestamp != nil && pod.Status.Reason == node.NodeUnreachablePodReason {
reason = "Unknown"
} else if pod.DeletionTimestamp != nil {
reason = "Terminating"
}
|
This means that when a delete operation is performed, the DeletionTimestamp property of the Pod is set, and the Terminating state is displayed at this time.
When the deletion operation is performed, a DELETE request is sent to the apiserver.
1
2
|
I0408 11:25:33.002155 42938 round_trippers.go:435] curl -v -XDELETE -H "Content-Type: application/json" -H "User-Agent: kubectl/v1.22.7 (darwin/amd64) kubernetes/b56e432" -H "Accept: application/json" 'https://192.168.0.111:6443/api/v1/namespaces/default/pods/minio-875749785-sv5ns'
I0408 11:25:33.037245 42938 round_trippers.go:454] DELETE https://192.168.0.111:6443/api/v1/namespaces/default/pods/minio-875749785-sv5ns 200 OK in 35 milliseconds
|
The processor that received the delete request is located at the code https://github.com/kubernetes/kubernetes/blob/v1.22.8/staging/src/k8s.io/apiserver/pkg/registry/generic/registry/store.go#L986. As shown below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func (e *Store) Delete(ctx context.Context, name string, deleteValidation rest.ValidateObjectFunc, options *metav1.DeleteOptions) (runtime.Object, bool, error) {
key, err := e.KeyFunc(ctx, name)
if err != nil {
return nil, false, err
}
obj := e.NewFunc()
qualifiedResource := e.qualifiedResourceFromContext(ctx)
if err = e.Storage.Get(ctx, key, storage.GetOptions{}, obj); err != nil {
return nil, false, storeerr.InterpretDeleteError(err, qualifiedResource, name)
}
// support older consumers of delete by treating "nil" as delete immediately
if options == nil {
options = metav1.NewDeleteOptions(0)
}
var preconditions storage.Preconditions
if options.Preconditions != nil {
preconditions.UID = options.Preconditions.UID
preconditions.ResourceVersion = options.Preconditions.ResourceVersion
}
graceful, pendingGraceful, err := rest.BeforeDelete(e.DeleteStrategy, ctx, obj, options)
if err != nil {
return nil, false, err
}
// this means finalizers cannot be updated via DeleteOptions if a deletion is already pending
if pendingGraceful {
out, err := e.finalizeDelete(ctx, obj, false, options)
return out, false, err
}
// check if obj has pending finalizers
|
In the BeforeDelete function to determine whether graceful deletion is needed, the criterion is whether the DeletionGracePeriodSeconds value is 0, not zero is considered graceful deletion, apiserver will not immediately delete the object from etcd, otherwise it is deleted directly. For Pods, the default DeletionGracePeriodSeconds is 30 seconds, so here it is not deleted immediately, but DeletionTimestamp is set to the current time and DeletionGracePeriodSeconds is set to the default value of 30 seconds. The code is located at https://github.com/kubernetes/kubernetes/blob/v1.22.8/staging/src/k8s.io/apiserver/pkg/registry/rest/delete.go#L93-L159 and in this function will sets the value of DeletionTimestamp. This is shown below.
1
2
3
4
5
6
7
8
9
10
11
12
|
// `CheckGracefulDelete` will be implemented by specific strategy
if !gracefulStrategy.CheckGracefulDelete(ctx, obj, options) {
return false, false, nil
}
if options.GracePeriodSeconds == nil {
return false, false, errors.NewInternalError(fmt.Errorf("options.GracePeriodSeconds should not be nil"))
}
now := metav1.NewTime(metav1.Now().Add(time.Second * time.Duration(*options.GracePeriodSeconds)))
objectMeta.SetDeletionTimestamp(&now)
objectMeta.SetDeletionGracePeriodSeconds(options.GracePeriodSeconds)
|
The above code verifies that when performing a deletion operation, apiserver will first set the DeletionTimestamp property of the Pod to the current time plus the time point of the graceful deletion graceful duration, and after setting this property, what our client sees after formatting is the Terminating state.
Elegant deletion
As Pods involve many other resources, such as sandbox containers, volume volumes, etc., they need to be recycled after deletion, and deleting a Pod is ultimately a matter of deleting the corresponding container, which requires the kubelet of the Pod’s node to complete the cleanup. kubelet will first keep watching our Pod, and when the Pod’s deletion When the Pod’s deletion time is updated, it will naturally receive the event and clean up accordingly.
The kubelet’s processing of Pods is mainly in the syncLoop function, which calls the event-related handler syncLoopIteration, the code of which is located in https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/kubelet.go#L2040-L2079. This is shown below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
klog.ErrorS(nil, "Update channel is closed, exiting the sync loop")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).InfoS("SyncLoop ADD", "source", u.Source, "pods", format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).InfoS("SyncLoop UPDATE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).InfoS("SyncLoop REMOVE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).InfoS("SyncLoop RECONCILE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).InfoS("SyncLoop DELETE", "source", u.Source, "pods", format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
klog.ErrorS(nil, "Kubelet does not support snapshot update")
default:
klog.ErrorS(nil, "Invalid operation type received", "operation", u.Op)
}
kl.sourcesReady.AddSource(u.Source)
|
When performing a delete operation, apiserver will first update the DeletionTimestamp property in the Pod. This change is an update operation for the kubelet, so it will correspond to the kubetypes.UPDATE operation and will call the HandlePodUpdates function to update it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// HandlePodUpdates is the callback in the SyncHandler interface for pods
// being updated from a config source.
func (kl *Kubelet) HandlePodUpdates(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
kl.podManager.UpdatePod(pod)
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodUpdate, mirrorPod, start)
}
}
|
In HandlePodUpdates, dispatchWork is called to assign the Pod deletion to a specific worker for processing, and the podWorker is the specific executor, i.e. every time the Pod needs to be updated, it is sent to the podWorker.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// dispatchWork starts the asynchronous sync of the pod in a pod worker.
// If the pod has completed termination, dispatchWork will perform no action.
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
// Run the sync in an async worker.
kl.podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
StartTime: start,
})
// Note the number of containers for new pods.
if syncType == kubetypes.SyncPodCreate {
metrics.ContainersPerPodCount.Observe(float64(len(pod.Spec.Containers)))
}
}
|
The dispatchWork method calls the UpdatePod function to delete the Pod, the code is located in https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/pod_workers.go#L540-L765, in which the Pod information is passed through a channel, and the managePodLoop function is called in a goroutine to process it, in which the syncTerminatingPod/syncPod method to perform the delete operation.
Eventually the killPod function will be called to perform the deletion of the Pod.
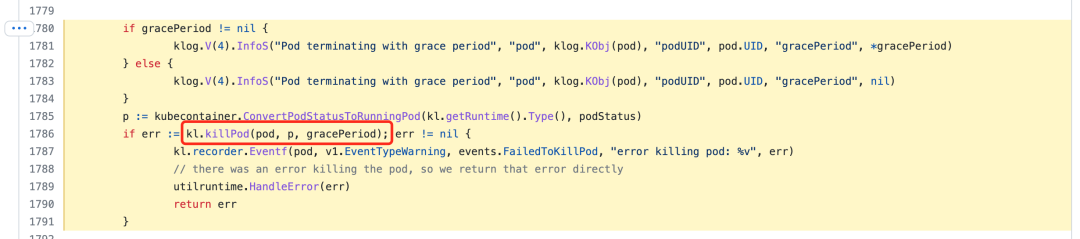
The killPod function calls the container runtime to stop the container in the Pod, and the code is located at https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/kubelet_pods.go#L856-L868.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// killPod instructs the container runtime to kill the pod. This method requires that
// the pod status contains the result of the last syncPod, otherwise it may fail to
// terminate newly created containers and sandboxes.
func (kl *Kubelet) killPod(pod *v1.Pod, p kubecontainer.Pod, gracePeriodOverride *int64) error {
// Call the container runtime KillPod method which stops all known running containers of the pod
if err := kl.containerRuntime.KillPod(pod, p, gracePeriodOverride); err != nil {
return err
}
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).InfoS("Failed to update QoS cgroups while killing pod", "err", err)
}
return nil
}
|
The KillPod method of the container runtime is located at https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/kuberuntime/kuberuntime_manager.go#L969-L998. The following shown below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// KillPod kills all the containers of a pod. Pod may be nil, running pod must not be.
// gracePeriodOverride if specified allows the caller to override the pod default grace period.
// only hard kill paths are allowed to specify a gracePeriodOverride in the kubelet in order to not corrupt user data.
// it is useful when doing SIGKILL for hard eviction scenarios, or max grace period during soft eviction scenarios.
func (m *kubeGenericRuntimeManager) KillPod(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) error {
err := m.killPodWithSyncResult(pod, runningPod, gracePeriodOverride)
return err.Error()
}
// killPodWithSyncResult kills a runningPod and returns SyncResult.
// Note: The pod passed in could be *nil* when kubelet restarted.
func (m *kubeGenericRuntimeManager) killPodWithSyncResult(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) (result kubecontainer.PodSyncResult) {
killContainerResults := m.killContainersWithSyncResult(pod, runningPod, gracePeriodOverride)
for _, containerResult := range killContainerResults {
result.AddSyncResult(containerResult)
}
// stop sandbox, the sandbox will be removed in GarbageCollect
killSandboxResult := kubecontainer.NewSyncResult(kubecontainer.KillPodSandbox, runningPod.ID)
result.AddSyncResult(killSandboxResult)
// Stop all sandboxes belongs to same pod
for _, podSandbox := range runningPod.Sandboxes {
if err := m.runtimeService.StopPodSandbox(podSandbox.ID.ID); err != nil && !crierror.IsNotFound(err) {
killSandboxResult.Fail(kubecontainer.ErrKillPodSandbox, err.Error())
klog.ErrorS(nil, "Failed to stop sandbox", "podSandboxID", podSandbox.ID)
}
}
return
}
|
The killPodWithSyncResult method first calls the function killContainersWithSyncResult to kill all the running containers and then delete the sandbox of the Pod.
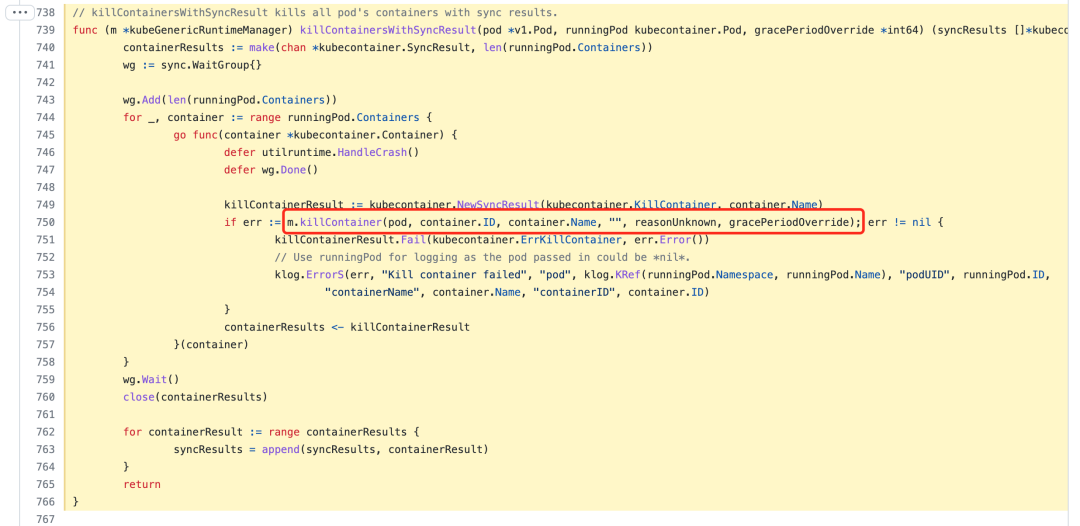
In this function, multiple goroutines are used to delete each container in the Pod. The method to delete the container is killContainer, where the hook pre-stop is executed first (if it exists) before stopping the container, the code is located at https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/kuberuntime/kuberuntime_container.go#L660-L736.
First get the graceful deletion grace time.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// From this point, pod and container must be non-nil.
gracePeriod := int64(minimumGracePeriodInSeconds)
switch {
case pod.DeletionGracePeriodSeconds != nil:
gracePeriod = *pod.DeletionGracePeriodSeconds
case pod.Spec.TerminationGracePeriodSeconds != nil:
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
switch reason {
case reasonStartupProbe:
if containerSpec.StartupProbe != nil && containerSpec.StartupProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.StartupProbe.TerminationGracePeriodSeconds
}
case reasonLivenessProbe:
if containerSpec.LivenessProbe != nil && containerSpec.LivenessProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.LivenessProbe.TerminationGracePeriodSeconds
}
}
}
|
Where TerminationGracePeriodSeconds can be set in the resource manifest file, the default is 30 seconds, this time is, after sending a shutdown command to Pod will send SIGTERM signal to the application, the program only needs to capture the SIGTERM signal and do the corresponding processing. This is the time that the application can gracefully shut down after the Pod receives the SIGTERM signal. This time is set by the apiserver, which was analyzed earlier.
If the pre-stop hook is configured and there is enough time left, the hook will be executed. The pre-stop is mainly for the business to stop gracefully before the container is deleted, such as resource recycling and other operations.
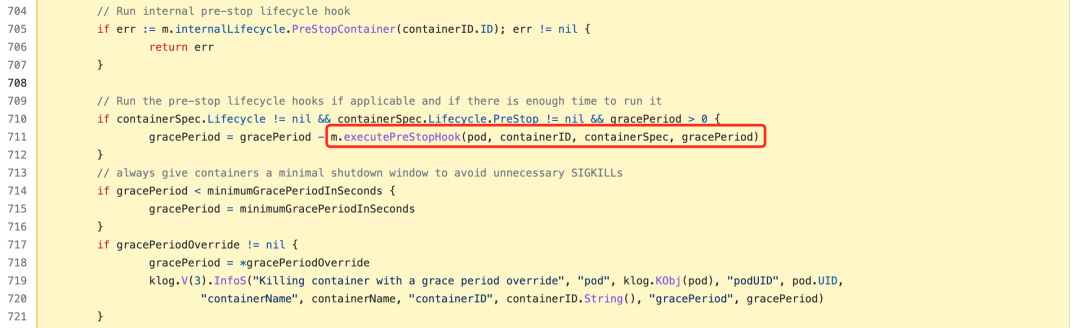
Finally it will actually go to call the underlying container runtime to stop the container.
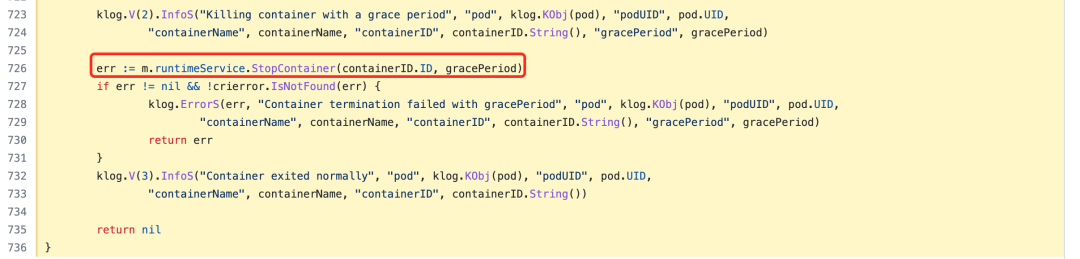
After the container is deleted and returned to the killPodWithSyncResult function, the next step is to call the StopPodSandbox function of the runtime service to stop the sandbox container, that is, the pause container.
1
2
3
4
5
6
7
|
// Stop all sandboxes belongs to same pod
for _, podSandbox := range runningPod.Sandboxes {
if err := m.runtimeService.StopPodSandbox(podSandbox.ID.ID); err != nil && !crierror.IsNotFound(err) {
killSandboxResult.Fail(kubecontainer.ErrKillPodSandbox, err.Error())
klog.ErrorS(nil, "Failed to stop sandbox", "podSandboxID", podSandbox.ID)
}
}
|
This is where the kubelet completes the graceful removal of the Pod, but it doesn’t end there.
Synchronization Status
For graceful deletion, at first the apiserver just set the DeletionTimestamp property to the Pod, and then the kubelet watch was updated to complete the graceful deletion of the Pod, but now there is still a record of the Pod on the server side, and it is not really deleted.
When the kubelet starts, it also starts a statusManager synchronization loop, which is the real source of the kubelet pod status and should be in sync with the latest `v1. manager to synchronize the status back to the apiserver.
The status manager will call the syncPod method underneath the manager to handle the status synchronization with the apiserver, which is located at https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/status/status_manager.go#L149-L181. As follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
func (m *manager) Start() {
// Don't start the status manager if we don't have a client. This will happen
// on the master, where the kubelet is responsible for bootstrapping the pods
// of the master components.
if m.kubeClient == nil {
klog.InfoS("Kubernetes client is nil, not starting status manager")
return
}
klog.InfoS("Starting to sync pod status with apiserver")
//lint:ignore SA1015 Ticker can link since this is only called once and doesn't handle termination.
syncTicker := time.Tick(syncPeriod)
// syncPod and syncBatch share the same go routine to avoid sync races.
go wait.Forever(func() {
for {
select {
case syncRequest := <-m.podStatusChannel:
klog.V(5).InfoS("Status Manager: syncing pod with status from podStatusChannel",
"podUID", syncRequest.podUID,
"statusVersion", syncRequest.status.version,
"status", syncRequest.status.status)
m.syncPod(syncRequest.podUID, syncRequest.status)
case <-syncTicker:
klog.V(5).InfoS("Status Manager: syncing batch")
// remove any entries in the status channel since the batch will handle them
for i := len(m.podStatusChannel); i > 0; i-- {
<-m.podStatusChannel
}
m.syncBatch()
}
}
}, 0)
}
|
The method determines whether the Pod has been gracefully stopped, and the code is located at https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/status/status_manager.go#L583-L652. as shown below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// We don't handle graceful deletion of mirror pods.
if m.canBeDeleted(pod, status.status) {
deleteOptions := metav1.DeleteOptions{
GracePeriodSeconds: new(int64),
// Use the pod UID as the precondition for deletion to prevent deleting a
// newly created pod with the same name and namespace.
Preconditions: metav1.NewUIDPreconditions(string(pod.UID)),
}
err = m.kubeClient.CoreV1().Pods(pod.Namespace).Delete(context.TODO(), pod.Name, deleteOptions)
if err != nil {
klog.InfoS("Failed to delete status for pod", "pod", klog.KObj(pod), "err", err)
return
}
klog.V(3).InfoS("Pod fully terminated and removed from etcd", "pod", klog.KObj(pod))
m.deletePodStatus(uid)
}
}
|
For example, it will determine if there are still containers running, if the volumes have not been cleaned, if the pod cgroup has not been emptied, and so on. If canBeDeleted returns true, then the pod has been gracefully stopped, so you can send a Delete request to the apiserver to delete the pod again.
However, this time the GracePeriodSeconds is set to 0, which means that the pod will be forcibly deleted, and the apiserver will receive a DELETE request again here. Unlike the first time, this time the Pod is forcibly deleted and the Pod object is deleted from etcd.
At this time, kubelet will receive the REMOVE event and call the HandlePodRemoves function to process it.
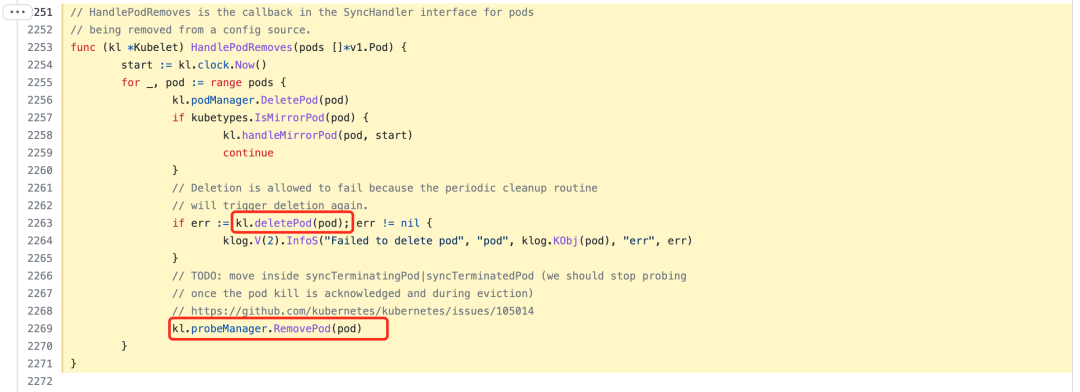
The deletePod function will be called first to stop the associated pod worker, and then probeManager will be called to remove the pod-related probe prober worker, which means that the pod is completely removed from the node.