
Introduction to IPFS
IPFS is known as InterPlanetary File System.
It is a network transport protocol designed to create persistent and distributed storage and shared files, a content-addressable peer-to-peer hypermedia distribution protocol. All the global nodes in the IPFS network will constitute one distributed file system, and everyone in the world will be able to store and access the files inside IPFS through the IPFS gateway.
Originally designed by Juan Benet and developed by Protocol Labs with the help of the open source community since 2014, this cool project is a fully open source project.
Benefits of IPFS
Comparison with existing Web
Existing Web technologies are inefficient and costly
HTTP downloads files from one computer at a time, rather than fetching them from multiple computers simultaneously. Peer-to-peer IPFS saves significant bandwidth , with video up to 60%, which makes it possible to efficiently distribute large amounts of data without duplication.

The existing web cannot preserve human history
The average lifespan of a web page is 100 days before it’s gone forever. The primary medium of our time is not vulnerable enough. IPFS preserves every version of a file and makes it simple to build resilient networks for mirrored data.
Existing networks are centralized, limiting opportunities
The Internet has driven innovation as one of the greatest equalizers in human history, but increasingly consolidated centralized control threatens this progress. IPFS avoids this through distributed technology.
Existing networks are deeply dependent on the backbone
IPFS supports the creation of diverse and resilient networks for persistent availability, with or without Internet backbone connectivity. This means that developing countries are better connected during natural disasters, or when on wi-fi in a coffee shop.
IPFS does it better
IPFS claims that no matter what you’re doing now with pre-existing Web technologies, IPFS can do it better.

- For archivists IPFS provides block de-duplication, high performance and cluster-based data persistence, which facilitates the storage of the world’s information for the benefit of future generations.
- For Service Providers IPFS provides secure P2P content delivery that can save service providers millions in bandwidth costs.
- For researchers If you use or distribute large data sets, IPFS can help you deliver fast performance and decentralized archiving.
- For World Development High latency networks are a major obstacle for those with poor Internet infrastructure. IPFS provides resilient access to data, independent of latency or backbone connectivity.
- For Blockchain With IPFS, you can process large volumes of data and place immutable, permanent link-timestamps and protected content in transactions without having to put the data itself on the chain.
- For Content Creators IPFS fully embodies the free and independent spirit of the web and can help you deliver content at a lower cost.
How it works
Let’s take a brief look at how IPFS works by going through the process of adding a file to IPFS.

IPFS cuts the file into multiple small blocks, each of 256KB in size, and the number of blocks is determined by the size of the file. Then the Hash of each block is calculated as the fingerprint of this block.

Because a lot of file data has duplicate parts, after cutting into smaller chunks, some of these chunks will be identical, which manifests itself as the same fingerprint hash. Blocks with the same fingerprint hash are considered the same block, so the same data all behave as the same block in IPFS, which eliminates the extra overhead of storing the same data.

Each node in an IPFS network stores only its own interest, i.e., the content that is frequently accessed by users of that IPFS node, or specified to be fixed.
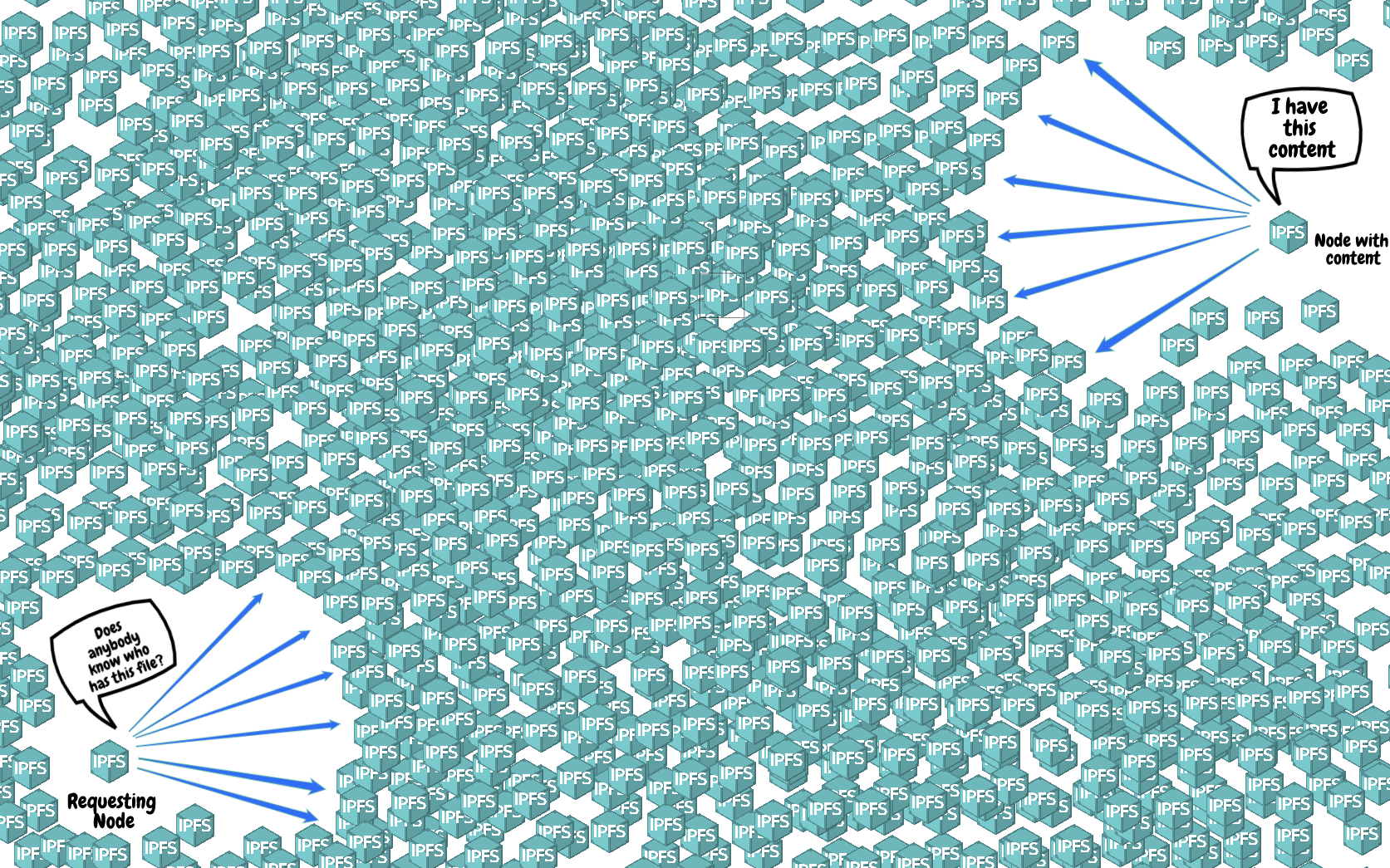
In addition to this, some additional index information is stored, which is used to help in the addressing of file lookups. When we need to access a block, the index information tells IPFS which nodes store that particular block.
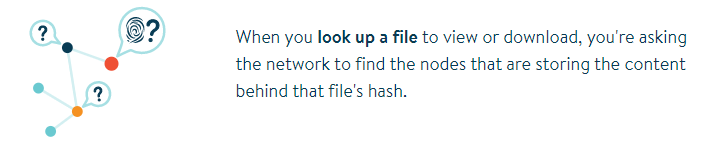
When we want to view or download a file from IPFS, IPFS then has to query the index information by changing the FingerprintHash of the file and asking the nodes it is connected to. This step requires finding which nodes in the IPFS network store the file data blocks you want.

If you can’t remember the fingerprint hash of a file stored in IPFS (which is a very long string), you don’t actually have to remember the hash, IPFS provides IPNS to provide a mapping between human readable names to fingerprint hashes, you just need to remember the human readable names you add to IPNS.
Basic usage
Installation
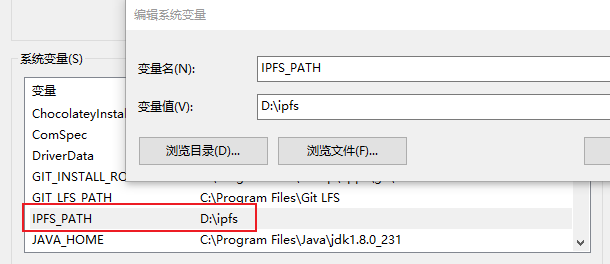
Set the environment variable IPFS_PATH, this directory will be used as the local repository for IPFS when initializing and using it later. If not set here, IPFS will use the .ipfs folder in the user directory as the local repository by default.
initialization
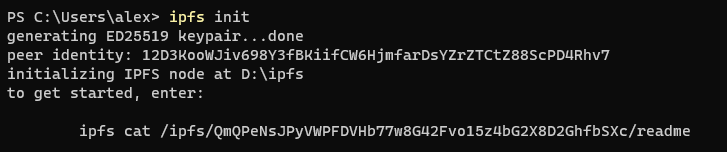
Run the command ipfs init to initialize the key pair and create the initial file in the IPFS_PATH directory just specified.
View Node ID Information
Run the command ipfs id to view your IPFS node ID information, which contains information such as node ID, public key, address, proxy version, protocol version, and supported protocols.
You can view other people’s node ID information by using ipfs id other people's ID.
Checking Availability
Check availability with the displayed command, here the ipfs cat command is used to see what the specified CID corresponds to.
Start the daemon
Run the following command to open the daemon.
|
|
Fetching files (folders)
IPFS fetches files implicitly, we can tell IPFS you are going to get the file I want by using commands like view, download, etc.
View text
Viewing text is done with the ipfs cat command, as used for checking availability earlier
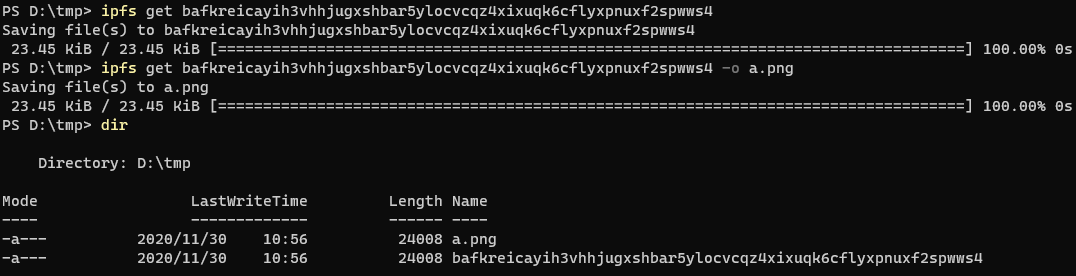
to download binary
For files such as images and videos, which cannot be viewed using the cat command (cat comes out as a bunch of gibberish), we can use the ipfs get cid method to download the file locally. However, this direct download of the file name will be the specified CID, a long string that is not recognizable, we can redirect to the specified file, ipfs get cid -o newname.png.
Listing directories
List a directory with the ipfs ls command.

Adding files (folders)
The ipfs add filename command is used to add files to IPFS.
If you need to add a folder, you need to add the -r argument to make it recursive.

Related Concepts
Before we go any further, let’s look at a few concepts that we must know about IPFS, which are fundamental components of IPFS and essential for subsequent use.
Peer
Peer is a peer node, because IPFS is based on P2P technology, so there is no such thing as a server-client, everyone is a server and a client at the same time, everyone for me, me for everyone.
CID
Content Identifier (CID) is a label used to point to content in IPFS. It does not indicate where the content is stored, but it forms a kind of address based on the content data itself. The CID is short, regardless of how large the content it points to is.
For details, see: Official IPFS documentation: Content addressing and CIDs
Online CID Inspector: CID Inspector
Gateway
- The official Gateway provided by IPFS: https://ipfs.io/
- IPFS Gateway service provided by Cloudflare: https://cf-ipfs.com
- Other publicly available Gateway list: https://ipfs.github.io/public-gateway-checker/
https://www.cloudflare.com/distributed-web-gateway/
For details see: IPFS Documentation: Gateway
IPNS
IPFS uses content-based addressing, which simply means that IPFS generates a CID based on the Hash of the file data, and this CID is only related to the content of the file, which leads to the fact that if we modify the content of this file, this CID will also change. If we share the file to someone via IPFS, we need to give this person a new link every time we update the content.
To solve this problem, the Interplanetary Name System (IPNS) solves this problem by creating an address that can be updated.
See: IPFS documentation: IPNS for details.
IPLD
https://docs.ipfs.io/concepts/ipld/
Deploying Websites on IPFS
Since IPFS claims to be able to build a new generation of distributed Web, we would like to deploy our website to IPFS and experience decentralized and distributed Web 3.0 technology together.
Adding files to IPFS
I’m using Hugo static site generator to generate my blog and the generated content is stored in the public directory, so first I need to add the public directory and all its contents to IPFS.
|
|
If you don’t want to see such a long rollup and just want the last Hash, you can add a Q (quiet) parameter.
Accessing through IPFS gateway
At the end of the add, the hash with the name public is the CID of the public directory, and we can now access the content we just added through the IPFS gateway with this CID.
Local Gateway Access
Let’s first access it through the local IPFS gateway to see if it was added successfully. Note that this step requires that you have the IPFS daemon enabled locally.
Visit: http://localhost:8080/ipfs/QmdoJ8BiuN8H7K68hJhk8ZrkFXjU8T9Wypi9xAyAzt2zoj
Then the browser will automatically make the jump and you can see that our page can be accessed normally.

You will find the URL in your browser’s address bar as another long string consisting of the domain name
long string.ipfs.localhost:8080The long string here is another concept in IPFS: IPLD
If your page is only able to display content, but the style is wrong, as shown below.
This is because absolute addresses are used and we need to use the form relative addresses. If you use Hugo as I do, then just add relativeURLs = true to your config file.
Remote Gateway Access
We have just successfully accessed the website in IPFS through the local IPFS gateway, now let’s find a publicly available other IPFS gateway to try it out.
Here I choose the official gateway maintained by IPFS: https://ipfs.io and visit: https://ipfs.io/ipfs/QmdoJ8BiuN8H7K68hJhk8ZrkFXjU8T9Wypi9xAyAzt2zoj.
It is important to note that at this time the website still exists only on our local machine, and it will take some time for other IPFS gateways to find our website files from the IPFS network. We need to make sure that the IPFS daemon is not closed and has connected to hundreds of other nodes at this time, so that the official IPFS Gateway can find us as soon as possible.
After many refreshes and anxious waits, it finally showed up.

Using IPNS for mapping
Use the command ipfs name publish CID to publish an IPNS, you may need to wait a while here.

By using IPNS mapping, we can keep the site content up to date. If we don’t use IPNS but publish the CID directly, then others won’t be able to access the latest version.
If IPNS is used, you need to back up the
private keyof the node and theKeythat was generated when the IPNS address was generated.They are stored in the
configfile and thekeystorefolder in the directory you show at init time, respectively.
Resolving domain names
IPNS is not the only way to create variable addresses on IPFS, we can also use DNSLink , which is currently much faster than IPNS and also uses human readable names.
For example, if I want to bind the domain name ipfs.lgf.im to a website I just published on IPFS, then I need to create a TXT record for _dnslink.ipfs.lgf.im.
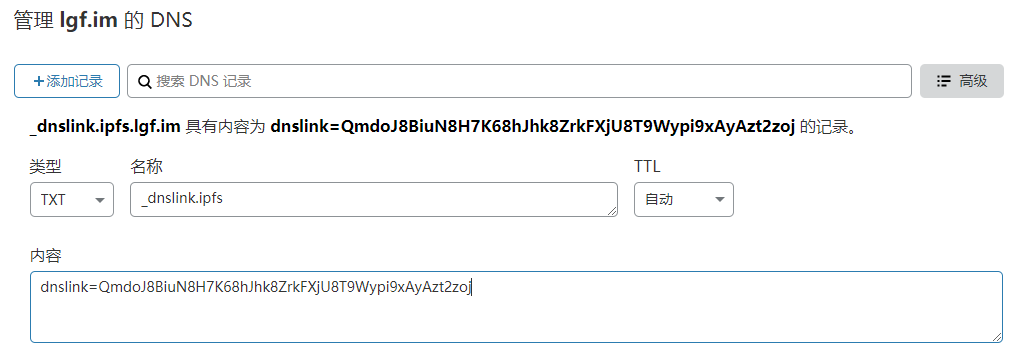
Then anyone can use /ipfs/ipfs.lgf.im to find my site now, by visiting http://localhost:8080/ipns/ipfs.lgf.im.

Detailed documentation is available at: IPFS Documentation: DNSLink.
Updating content
To update the content, just add it again and republish the IPNS. If you are using the DNSLink method, you also need to modify the DNS records.
Underlying technology
Merkle Directed Acyclic Graph (DAG)
Each Merkle is a directed acyclic graph , as each node is accessed by its name. Each Merkle branch is a hash of its local content, and their child nodes are named using their hash rather than their full content. Therefore, nodes will not be editable after creation. This prevents loops (assuming no hash collisions) because it is not possible to link the first created node to the last node and thus create the last reference.
For any Merkle, creating a new branch or verifying an existing branch usually requires the use of a hashing algorithm on some combination of local content (e.g. subhash of a list and other bytes). there are several hashing algorithms available in IPFS.
A description of the data entered into the hashing algorithm can be found at https://github.com/ipfs/go-ipfs/tree/master/merkledag.
See in particular: IPFS documentation: Merkle.
Distributed Hash Table DHT
See in particular: IPFS documentation: DHT.
Upper Layer Applications
IPFS as a file system is essentially used to store files, and based on some of the features of this file system, there are many upper layer applications that have sprung up.

Filecoin
Building applications based on IPFS
IPFS provides Golang and JavaScript implementations of the IPFS protocol, making it very easy to integrate IPFS into our applications and take full advantage of the various benefits of IPFS.
What to expect in the future
For P2P: https://t.lgf.im/post/618818179793371136/%E5%85%B3%E4%BA%8Eresilio-sync
Some questions
Can IPFS store files permanently?
Many people mistakenly believe that IPFS can store files permanently. In terms of the technology used it is indeed more conducive to storing content permanently, but there is a constant need for someone to access, pin, and propagate the content, otherwise the data will still be lost when all nodes across the network have GC’d the content data.
IPFS is anonymous?
Some people think P2P is anonymous, just like Tor, just like Ether. In fact the vast majority of P2P applications are not anonymous, and neither is IPFS, so you need to protect yourself when posting sensitive information. IPFS does not currently support the Tor network.
IPFS speed blocks with low latency?
In theory, as long as there are enough nodes, IPFS speed based on P2P technology can fully use your bandwidth and latency can potentially be lower than centralized Web. But in practice, as things stand, not many people use IPFS, you link up to about 1000 IPFS nodes (at least at this stage I’m up to even 1000 or less), so it does not reach the ideal state of theory, so now IPFS is not very fast, and few people access the cold data latency is very high, there is a high probability of not finding.
IPFS is a scam, Filecoin is a scam?
Indeed, there are many speculators who want to profit by selling the so-called IPFS miners (actually ordinary computers connected to large hard drives), so they deliberately go to confuse the concepts of IPFS, Filecoin, Bitcoin, blockchain, etc., playing the pseudo-concept of permanent storage, using the hot spot of blockchain to deceive the elderly who know nothing, this behavior is very shameless.
In fact, IPFS itself is not a scam, based on IPFS generated incentive layer Filecoin is also not a scam, from my use, anyone no need to purposely buy any so-called IPFS miner, just run an IPFS daemon in the background while your own computer is running. Don’t get carried away by the so called coins.