I’ve been using Go for a year now and am deeply immersed in its simplicity of design, as described on its website.
Go is expressive, concise, clean, and efficient. It’s a fast, statically typed, compiled language that feels like a dynamically typed, interpreted language.
Rob Pike in Simplicity is Complicated also mentions Go’s simplicity as an important reason for its popularity. Simplicity does not mean simplicity, and Go has a number of design features that ensure that complexity is hidden behind the scenes. In this article, I discuss the design philosophy and best practices of struct/interface in Go to help readers write robust and efficient Go programs.
Structures Struct
Go is designed to replace C/C++, so struct in Go is similar to C, and is a value type like int/float, which is memory compact, fixed size, and GC and memory access friendly.
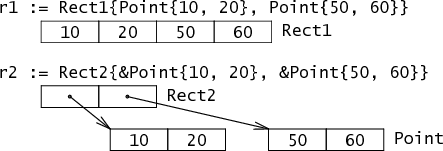
As you can see from the figure above, Point Rect1 Rect2 are all contiguous in memory. The value types need to be used with the following two points in mind.
-
When an assignment is made, a copy of the value is made, unlike the reference-based Object in Java.
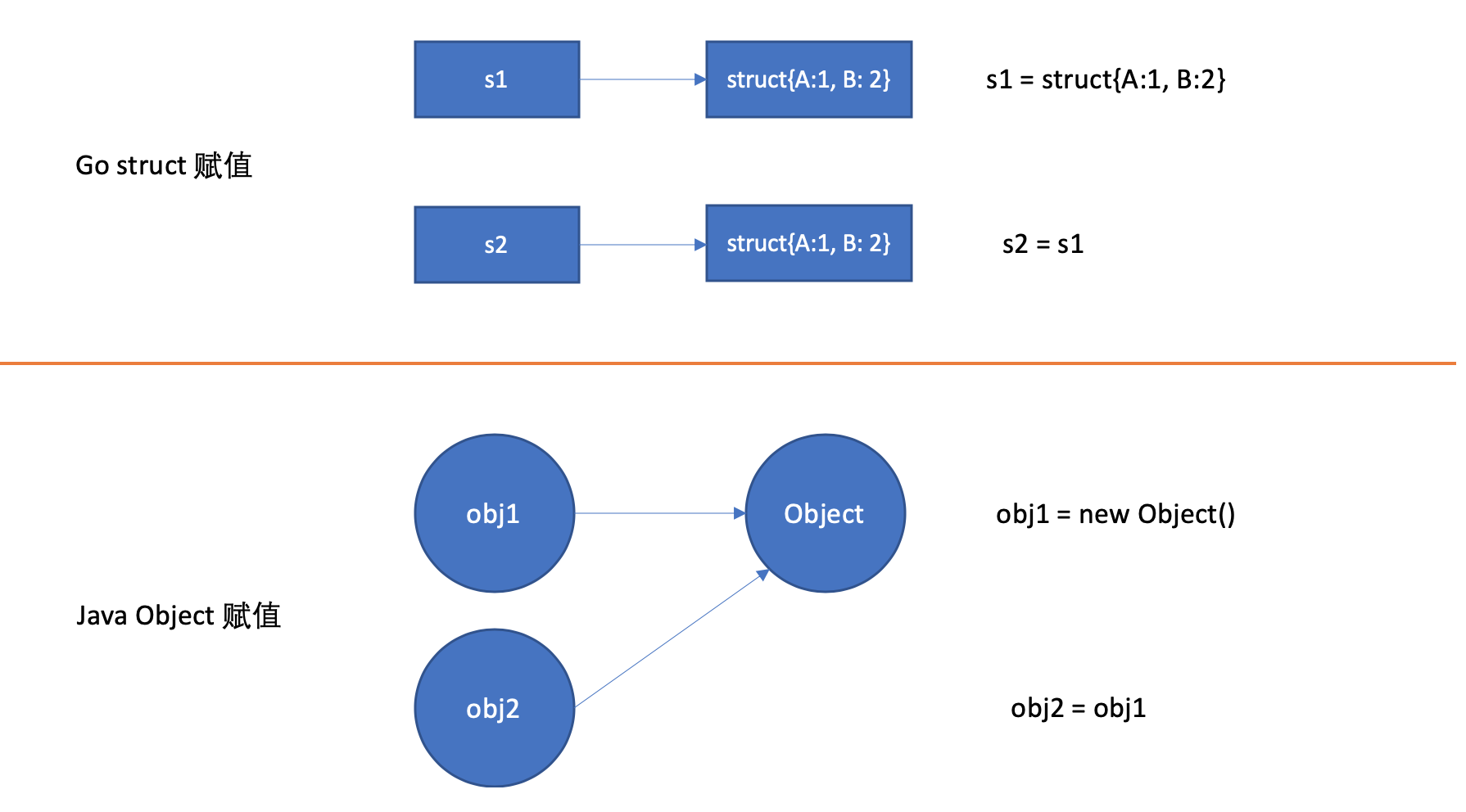
-
Because the assignment of a value type makes a copy, it needs to be defined as a pointer type when its value needs to be changed.
The above example is relatively simple, but it is easy to overlook when nesting structs within other structures, such as when using for range to traverse []struct, map[xx]struct. there are some pitfalls when using for range.
Also, in some cases, Go directly restricts the modification of structs at the language level. Here is an example.
As you can see, it is not possible to assign a value to the struct in map directly. This is because m[1] gets a copy of the original struct, and even if the compiler allows the assignment here, the value of the struct in the map will not change, so the compiler directly disallows it. Second, the assignment here is a read-modify-write operation, which makes it difficult to guarantee atomicity, as discussed in #3117. There are two ways to resolve this.
I have encountered this “trap” many times, so does it mean that all structs are defined as pointers? Here we need to understand Go’s escape analysis to answer this question.
Fugitive analysis
The main role of escape analysis is to determine where objects are allocated in memory, Go tries to allocate them on the stack, which has obvious benefits: easy recycling and less GC pressure. This can be seen with go build -gcflags -m xx.go.
As you can see, the return value of the returnByPointer method escapes and ends up on the heap. For more information on the performance difference between variables assigned on stack / heap, see: bench_test.go
Test results.
|
|
As you can see.
- When the method returns a pointer, there is a heap allocation
- When the method returns value, there is no heap allocation, which means that all variables are allocated on the stack
- There is little difference in performance between a receiver being a pointer or a value, because s has no escape in either case, and copying the struct itself costs about the same as copying a pointer (8 bytes)
This test also shows that the location of the variable allocation in memory is independent of whether it is a pointer or not. Combining the results of the above test, the following process can be followed to determine whether to use pointers.
- If you need to change the state (e.g. to include waitgroup/sync.Poll/sync.
- As a function return value,
unsafe.Sizeof(struct)is greater than a certain threshold, the time to copy is greater than the time to allocate on the heap, and the pointer is chosen - As a function parameter, for range objects (all will copy the value), if the object is large, use the pointer
- In addition, struct can be
To determine the threshold in 2, you can add an array to the struct (arrays are also value types) and run the above test. In my machine, the threshold is about 72K.
Few structs are of this magnitude, due to the fact that slice/map/string, which are commonly used in Go, are composite types, which are characterized by a fixed size, e.g. string takes up only 16 bytes (for 64-bit systems), similar to the structure below.
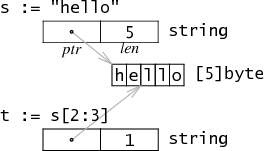
The following table summarizes the classification of data types in Go.
| value type | composite type |
|---|---|
| bool | slice |
| numeric | map |
| (unsafe)pointer | channel |
| struct | function |
| array | interface |
| string |
|
|
You can see that
- chan/func/map/ptr are all 8 bytes, i.e. one pointer to concrete data
- interface is 16, two pointers, one to a specific type and one to specific data. See Russ Cox’s Go Data Structures: Interfaces for details
- slice is 24, including a pointer to the underlying array, two integers, and the distributions cap, len
It was mentioned above that you can’t directly modify the struct in a map, so is the following procedure legal? Why?
Memory alignment
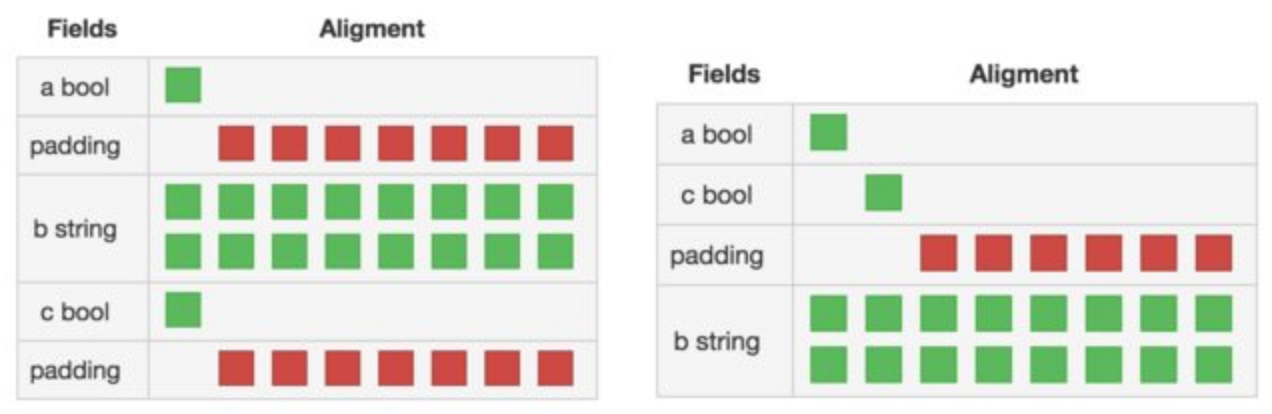
Fields in struct are aligned by machine word length, so where performance is critical, you can try to put fields of the same type together.
The above code will output 32 24 in sequence, and the following illustration clearly shows the layout of the two sequential structs in memory: (image source)
Finally, the reader can consider the results of the following code run.
Interface
If struct is the encapsulation of state, then interface is the encapsulation of behavior, and is the basis for constructing abstractions in Go. Since there is no concept of oop in Go, the integration of different components, such as Reader/Writer under the io package, is achieved through combination rather than inheritance. But there is no advantage to combination, which is also possible in Java, but the implicit “inheritance” in Go makes combination very flexible.
Embedded struct
This is illustrated by an example.
|
|
The above code snippet is a middleware in negroni to record the http code. The custom Writer implements the ResponseWriter interface by embedding the ResponseWriter and then The entire implementation is very simple and concise, as it uses the pointer type *RecordWriter as a receiver since it needs to change state.
New func type
The second example is about how to simplify err handling by customizing the type. In net/http, handlerFunc has no return value, which leads to a null return after each exception to abort the logic, which is not only tedious but also easy to miss.
|
|
The problem can then be solved by customizing the new type.
|
|
As you can see, the above example achieves the need to centralize err handling by defining a new function type for appHandler and implicitly “inheriting” from the http.Handler The nice thing about this implementation is that it adds new types to the functions and the function signatures are consistent with ServeHTTP, so that the parameters can be reused directly. For beginners, it may not occur to you to define methods for func types as well, but in Go, you can add methods to any type.
I’ve seen some frameworks on the web that use panic to simplify err handling, but I think this is a misuse of panic, not to mention the loss of performance, but mainly because it breaks the if err ! = nil processing. I hope readers will consider how to abstract new types to solve the problem when dealing with tedious logic in the future.
Summary
The subtle design of Go ensures that its features are simple and may be different from traditional oop, so it’s not wrong for readers who have switched from these languages to think in old ways. But as a good Go programmer, you need to think more in terms of Go’s own features, so that you don’t have to wonder “why are there no XX features in Go? You should know that the authors of Go are Rob Pike, Ken Thompson :-) If you have read/implemented the interface-based design, please feel free to share.