This article introduces the knowledge and concepts related to hard drive partitioning. I think the content related to this is difficult to understand because part of it is a hardware concept and part of it is software (file system), and a lot of information is introduced without putting it together for comparison, so the reader will be very vague about some concepts when he sees it. For example, hard disk partitions have partition types and file systems have types, what is the difference between these two types? What is the difference between a hard drive with sector size and a file system with block size? This article tries to go deeper, starting from the basic principles, introducing some concepts, what they do respectively and why they do it.
Understanding hard disks
A hard drive in Linux is a block device, which is used to store data. You enter data into the hard drive, and the hard drive stores it in a location for you. The next time you need it, you read it out from that location.
So given a location, how does a hard drive go about finding data in that location?
This starts with the structure of the hard drive (although most machines now use SSDs, much of the data is based on mechanical hard drives, so here is an example of how CHS addressing works.) . A hard drive is made up of several discs, each of which can hold data on both the front and back sides.
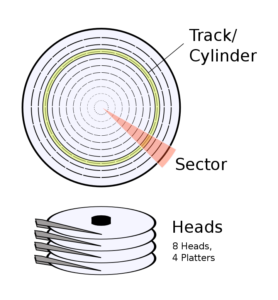
So the question is converted into: how to determine a position in several circular surfaces. First of all, how many parameters are needed to determine a position in a circle? Obviously 2, the distance from the center of the circle to determine a circle, plus an “angle” to determine a point on that circle. Then, in the structure of a hard disk, another parameter is added to determine the number of circular faces.
These parameters are called.
- Cylinder/Track: track, column surface, which determines the position from the center of the circle.
- Head: Head, this is the physical device that reads and writes data, in fact, when the hard disk is running, it is the platter that is spinning, the head is responsible for moving and adjusting the column surface that is read;.
- Sector: Sector. The above two parameters determine a circle, and Sector determines which sector is in this circle.
This is how CHS addressing works.
It is also clear from this that the unit of hard drive storage is “a sector”. In fact, when partitioning, (the partitioning software) also uses the term “sector to sector” and does not involve you in Track and Head, which is something that the hardware itself uses for addressing.
Using fdisk we can see how many sectors the drive has and how big a sector is. In fact almost all hard drive sectors since 1980 have been 512bytes in size.
|
|
Why do we need partitions?
Now we know that with sector locations, the drive can write or read data out. So why do we need partitioning? For the following reasons.
-
Isolating file system rot (eggs not in one basket). We have to create the file system on the device in order for the OS to use the file system for reading and writing. The file system is a plan of the storage device, recording what is stored in each block (inode, block). In case the metadata of the file system is wrong, then the whole file system data may not be read.
-
Improve storage utilization. A file will occupy a minimum of one block, and if the block is too large, a lot of space will be wasted. For example, if the block size is 4k, and all the files stored are 1k, then 3/4 of the space is wasted. If the block is too small, the performance is very low, because the kernel is copied in blocks; we can divide it into a partition and build a file system with a block size of 512bytes to store these small files exclusively.
-
Limit file growth. crontab writing too many logs causes all processes to hang, which is certainly not reasonable. But file growth does not cross the file system and run to another partition, so we can allocate write space to specific processes by partitioning.
Based on this, we can partition the system for different storage contents. For example, a separate partition for user programs /usr and a separate partition for /home.
What is the nature of partitioning?
Different partitions are still on one drive, which is equivalent to just managing different sectors in groups. So where is this grouping information stored?
The answer is on the first sector of the first hard drive. The first sector of the drive is also the first place the system reads when booting (BIOS-based boot process). As mentioned earlier, the size of a sector is 512bytes, what is in these 512bytes?
In Linux everything is a file, the hard disk is also a file, denoted by /dev/sda (this is the SCSI interface, the IDE interface would be /dev/hda, see here for naming and numbering (https://www.tldp.org/HOWTO/Partition/devices.html)). This way, we can copy the first 512bytes of the “file”.
You can then look at the contents of this file using the xxd command that comes with Vim.
|
|
The contents of this can be divided into 4 parts.
- 001-440bytes (440bytes in total): the code given to the BIOS to execute; this is actually very interesting and those who are interested can dump this into machine code and have a look. The boot system needs to load the code into memory, but we need the system to boot in order to load the code. So this process is also called boot, i.e. “pull oneself over a fence by one’s bootstraps “ .
- 441-446bytes (6bytes total): MBR Disk signature.
- 447-510 (64bytes total): partition table in 4 parts of 16 bytes each;
- the last 511 and 512 (2bytes in total): fixed to 0x55AA, indicating that the drive is available for booting.
From 00001be to the last 00001fd, the information of the partition table is recorded.
- Partition 1:
0004 0104 82fe c2ff 0008 0000 0048 4500 - Partition 2:
80fe c2ff 83bb c1bb 0050 4500 0000 e001 - Partition 3:
0000 0000 0000 0000 0000 0000 0000 0000 - Partition 4:
0000 0000 0000 0000 0000 0000 0000 0000
According to fdisk -l above, I only have two partitions on this machine, so partitions 3 and 4 are empty. What is recorded in these 16bytes? Let’s take one of the partitions, let’s use the 2nd one here.
|
|
0 bytes, 80, is a flag for.
80This partition can be used for system booting.00This partition cannot be used for system booting.
Bytes 1-3, fe c2ff This is represented by the CHS address we mentioned above, and the next 5-7 bytes, respectively, indicating that this partition starts at.
feCylinder location isfe;c2Head starts atc2;ffSector starts atff;
Accordingly, the end position of this partition is bb c1 bb.
The 4th byte between the beginning and the end is the partition type. In this case it is 83, which means the type is Linux.
All types can be listed in fdisk with the l command.
|
|
But actually, this partition type is not very useful in Linux, whether it’s ext2 or ext3 or other Linux partitions, it’s 83. This flag is interpreted differently by different operating systems, for example, Windows uses this flag to distinguish between different partition types, so you see in this table that FAT32 and NTFS, the common Windows partitions, each occupy a flag bit. In the end, this flag bit is actually a common flag, and how it is interpreted goes to the operating system, even if different operating systems installed on the same hard drive are also possible, for example 0x07 For example, OS/2 considers this flag bit to be an HPFS type partition and Windows considers it to be an NTFS type partition.
It is important to note that this flag bit is not intrinsically related to the file system. Since Linux doesn’t care about this flag bit, I can build a filesystem on this partition regardless of its type. I can even overwrite this flag bit while the system is running. For example, if I change this current partition to FAT12, there is no problem at all.
8-11 bytes: 0050 4500 Absolute address of the first sector of the logical block address.
11-15 bytes: 0000 e001 How many sectors this partition has in total.
Limit of MBR partition: From here, we can see that 4 bytes indicate the absolute address of the first sector and 4 bytes indicate how many sectors this partition has, so the maximum hard disk size that the MBR partition table can support is:
That is, 512 * (2^32 -1 ) * 2, which is 4TiB-1Kb.
However, with such partitioning, the last partition must be 2TiB in order to take advantage of 4Tib. If a user has a 4TiB hard drive and wants to divide it evenly into 4 partitions of 1TiB each, it won’t work. This will cause confusion to many users, so when it comes to commercial promotion, just say that MBR supports 2TiB.
Primary and extended partitions
As you can also see here, the partition data is 64bytes in total and each partition table needs 16bytes of information. So there can be 4 partitions in total. The first time I used a computer, it was Windows, and I never understood what “local disk CDEF” meant. Actually, it means that the fast partitioning mode of the partitioning software divides the hard disk into 4 partitions by default on average.
The partition table determines that we can only create 4 partitions, what if we want more partitions?
Remember what happens when block addressing in the file system exceeds the number of blocks that can be stored in an inode? The answer is that the actual content of the block stored in the inode is the address of the real block. The same principle is used here. We can create a primary partition of type Extended (with flag 5), and then each partition in this partition holds the address to the next partition at the end.
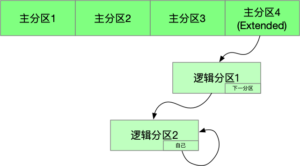
Logical partitions must be contiguous (obviously), but primary partitions can be non-contiguous. Other than that there is no difference in the use of logical and primary partitions. Logical partitions can also be used to boot the system.
This introduction should solve most of the reader’s problems (at least it answers many of my questions). For more in-depth questions, you may have to search for more detailed information based on this content.
Sector Size and Block Size
You should know something about this from reading this article. Sector is a concept of hard disk, almost all hard disk sectors are 512Bytes, if not, it may be a problem. And Block refers to a logical concept. But there may still be some confusion about them in some scenarios. I’ve done some research on the subject, so here’s more or less how to save some time for those who have the same questions as me in the future, and can find it here.
There is very little difference in the concept of sector size. But Block has different meanings in different scenarios.
The first is the block of the file system, where the block affects the size of the block used to store the file. The reason is simple: the file system is addressed in blocks, so if the block size is 4k, then even if the file is written to 1k, it will take 4k.
When a file system is created, the inode and block are automatically allocated:
|
|
Block in IO : IO is in blocks, this block is not necessarily the block size of the file system, nor the size of the sector, it can be smaller than the sector, but this is a waste, because the hard disk will write 512bytes per write, if the block of IO is 256bytes, then it is equivalent to writing the same sector, using two physical write operations. In addition, we have to write to disk through syscall, which copies data between user space and kernel space, also in blocks. We can use the madvice system call to suggest the IO block size to the Kernel.
Here is the impact on the speed when I use dd to copy the same data from the hard disk, using different block sizes.
|
|
But IO is actually a very complex issue, and it is not clear in a few words. We recommend a book Linux System Programming, which has four chapters on IO-related topics.
In addition, when you see a block, you have to pay attention to what context it is talking about. For example, the block shown by the ls -s command is shown with each block=1024bytes, while the block in stat is 512bytes.
|
|
It is recommended to practice partitioning with the relevant tools, and it is recommended to operate inside the virtual machine without worrying about messing up the host. Play with these commands.
- xxd (provided by vim)
- fdisk
- mount
- grub
- ss
- dd